Relational Rank Geometry in Transformers: Detecting and Steering Hidden-State Relation Frames
Pith reviewed 2026-06-29 08:22 UTC · model grok-4.3
The pith
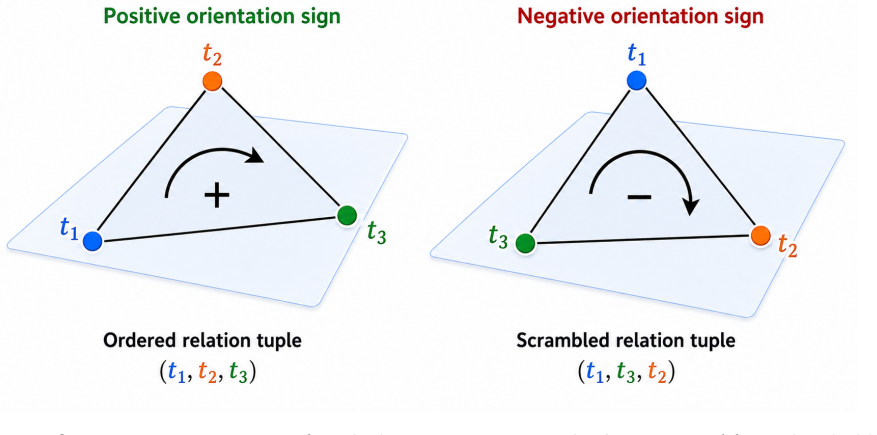
Transformer hidden states encode r-ary relations as rank-specific orientation signatures detectable by Plucker sign entropy and steerable by clean-frame patching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
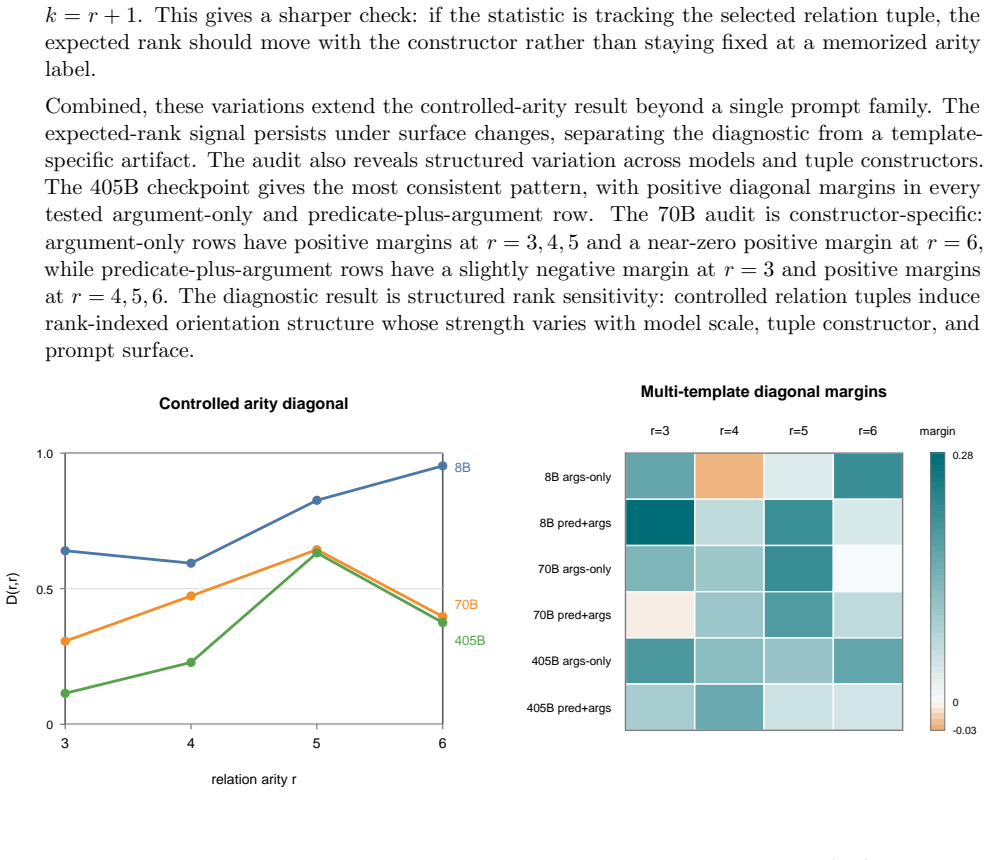
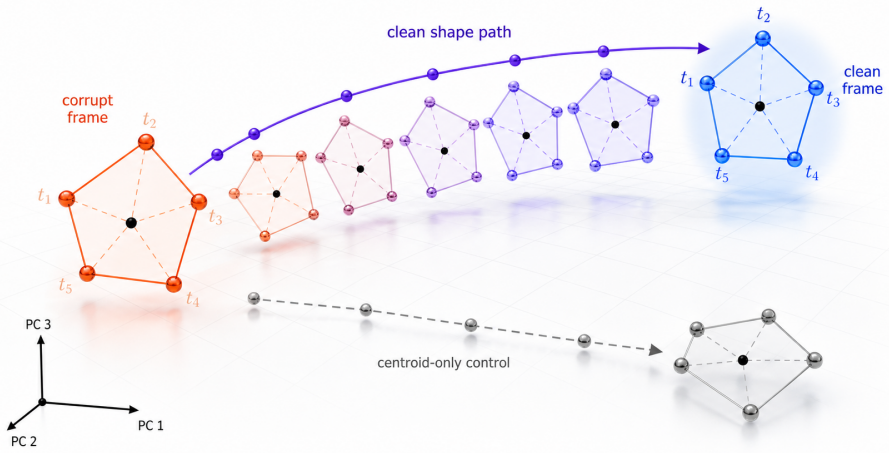
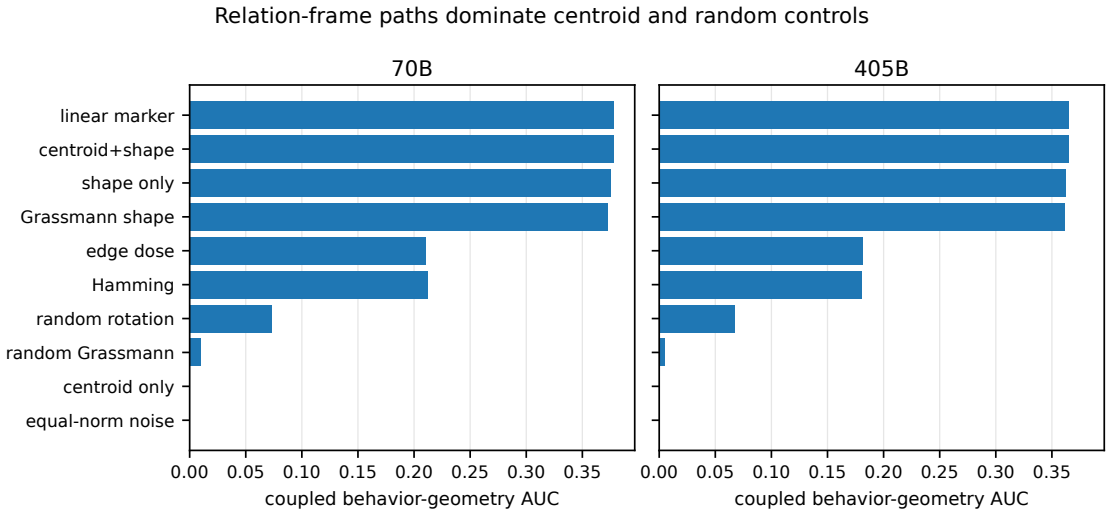
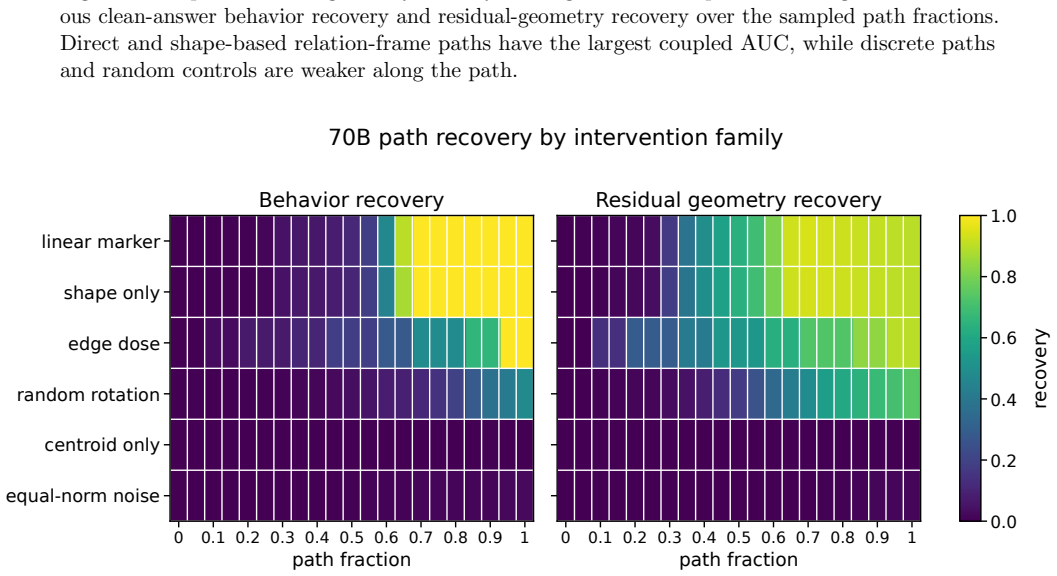
Across Llama-family models, true relation tuples exhibit stronger Plucker sign consistency at the expected rank than scrambled tuples under matched audits, and clean-targeted relation-frame paths in an edge-grid assay recover clean-answer behavior plus residual geometry while multiple controls fail.
What carries the argument
Plucker sign entropy to measure arity-matched orientation signatures, paired with edge-grid clean/corrupt patching to steer relation frames.
If this is right
- True tuples outperform scrambled controls at ranks 3 through 6 in all tested model sizes.
- Clean-targeted paths recover both behavior and residual geometry in 70B and 405B while controls do not.
- Multi-template variation leaves the positive expected-rank margins intact.
- Site and order controls separate ordered clean-frame geometry from marker-site effects.
Where Pith is reading between the lines
- The same rank geometry might be measurable in non-Llama architectures if the entropy measure is architecture-agnostic.
- Relation-frame steering could be tested on tasks beyond yes/no relations, such as multi-hop inference chains.
- If the geometry survives further surface controls, it might serve as a target for editing stored relational knowledge.
Load-bearing premise
The Plucker sign entropy and edge-grid assay isolate arity-matched relation geometry rather than surface lexical or positional artifacts.
What would settle it
If scrambled tuples produced equal or higher expected-rank margins than true tuples, or if clean-frame patches failed to outperform centroid-only and site-permuted controls in answer recovery.
Figures




read the original abstract
Transformer hidden states are often interpreted through local or low-order objects: neurons, sparse features, attention heads, residual-stream directions, or activation patches. This paper studies a complementary object: the rank-indexed geometry of relations among token tuples. I use Plucker sign entropy to test whether r-argument relations leave arity-matched orientation signatures in hidden-state space. Across Llama-family 8B, 70B, and 405B checkpoints, true relation tuples show stronger orientation-sign consistency at the expected rank k=r for r=3,...,6 than scrambled tuples under matched random-control audits. Multi-template audits show that the effects survive surface variation, with all tested 405B rows retaining positive expected-rank margins and 8B/70B retaining positive rows with constructor-specific mixed cells. I then ask whether the same relation geometry can be steered. In an edge-grid clean/corrupt intervention assay over 32 prompts, the row/column scaffold and answer format stay fixed while the YES/NO relation map changes, and the corrupt hidden-state relation frame is patched toward clean or placebo targets. In 70B and 405B, clean-targeted relation-frame paths recover clean-answer behavior and residual relation geometry, while centroid-only and equal-norm controls show negligible recovery. Site/order controls further separate marker-site importance from ordered clean-frame geometry: target clean shape and cross-prompt clean shape recover behavior and residual geometry at the marker interface, whereas corrupt-donor transfer, same-site permutation/reflection, wrong-site clean deltas, centroid-only motion, and equal-norm noise fail or remain far below clean-frame paths. The result is a controlled bridge from relation probing to relation-frame intervention: relation rank geometry can be detected, targeted, and behaviorally validated in transformer hidden states.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that transformer hidden states encode rank-indexed geometry of r-argument relations, detectable via Plucker sign entropy as stronger orientation-sign consistency at expected rank k=r (for r=3..6) in true tuples versus scrambled controls across Llama 8B/70B/405B models, with effects surviving multi-template surface variation. It further claims this geometry is steerable: in an edge-grid clean/corrupt intervention assay over 32 prompts, clean-targeted relation-frame patching recovers clean-answer behavior and residual geometry in 70B/405B while centroid-only, equal-norm, permutation, and site/order controls fail or underperform, separating ordered relation frames from marker-site or norm artifacts.
Significance. If the central claims hold after addressing control-matching details, the work supplies a new, arity-specific geometric primitive for interpretability that moves beyond local features or attention heads toward relational structure. The combination of detection via sign entropy, multi-model scale, and controlled intervention with multiple placebo conditions (including site/order ablations) offers a falsifiable bridge from probing to behavioral steering, which could inform analyses of compositional reasoning if the isolation from lexical/positional confounds is secured.
major comments (3)
- [Abstract] Abstract and control-audit description: the central attribution of positive expected-rank margins to arity-matched relation geometry rests on scrambled tuples serving as matched random-control audits. No quantitative breakdown (e.g., variance partitioning, Kolmogorov-Smirnov statistics on token-position or co-occurrence marginals, or explicit matching procedure) is supplied showing that scrambling equates the surface statistics of true tuples; without this, residual lexical or positional correlations remain a viable alternative explanation for the sign-consistency differences at k=r.
- [Abstract (intervention assay)] Intervention assay paragraph: the claim that clean-targeted relation-frame paths recover behavior and residual geometry while centroid-only/equal-norm controls show negligible recovery is load-bearing for the steering result. The description of the 32-prompt edge-grid assay does not report effect sizes, error bars, or a statistical test confirming that the differential recovery survives after equating site-specific and norm-based contributions; this leaves open whether the ordered clean-frame component, rather than marker-site importance, drives the outcome.
- [Abstract (multi-template audits)] Model-size results: the statement that 'all tested 405B rows retain positive expected-rank margins' while 8B/70B show constructor-specific mixed cells is presented without the number of templates, prompts, or variance estimates. This makes it impossible to evaluate whether the reported pattern reflects stable rank-indexed geometry or sampling variability, directly affecting the cross-scale generality claim.
minor comments (2)
- [Abstract] The abstract introduces 'Plucker sign entropy' without a one-sentence definition or pointer to the coordinate construction used; adding this would improve accessibility for readers outside algebraic geometry.
- [Abstract] The phrase 'site/order controls further separate marker-site importance from ordered clean-frame geometry' is used without an accompanying table or figure reference showing the quantitative separation; a cross-reference would clarify the evidential basis.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and commit to revisions that add the requested quantitative details, statistical tests, and clarifications to strengthen the control audits and result reporting.
read point-by-point responses
-
Referee: [Abstract] Abstract and control-audit description: the central attribution of positive expected-rank margins to arity-matched relation geometry rests on scrambled tuples serving as matched random-control audits. No quantitative breakdown (e.g., variance partitioning, Kolmogorov-Smirnov statistics on token-position or co-occurrence marginals, or explicit matching procedure) is supplied showing that scrambling equates the surface statistics of true tuples; without this, residual lexical or positional correlations remain a viable alternative explanation for the sign-consistency differences at k=r.
Authors: We agree that an explicit quantitative audit of surface statistics would further secure the interpretation. The scrambling procedure randomizes argument order within fixed templates to preserve positional structure and token co-occurrence marginals as closely as possible, but the current version does not report variance partitioning or KS tests on those marginals. We will add these analyses (including explicit matching statistics and any residual differences) to the supplementary materials and reference them from the main text and abstract. revision: yes
-
Referee: [Abstract (intervention assay)] Intervention assay paragraph: the claim that clean-targeted relation-frame paths recover behavior and residual geometry while centroid-only/equal-norm controls show negligible recovery is load-bearing for the steering result. The description of the 32-prompt edge-grid assay does not report effect sizes, error bars, or a statistical test confirming that the differential recovery survives after equating site-specific and norm-based contributions; this leaves open whether the ordered clean-frame component, rather than marker-site importance, drives the outcome.
Authors: The 32-prompt edge-grid assay demonstrates differential recovery for clean-frame patching over multiple placebo controls, including site and norm ablations. However, the abstract and main-text description do not include effect sizes, error bars, or formal statistical tests. We will revise to report effect sizes (e.g., standardized mean differences), bootstrap or per-prompt error bars, and appropriate tests (paired comparisons between clean-frame and control conditions) to quantify the ordered-geometry contribution beyond site/norm factors. revision: yes
-
Referee: [Abstract (multi-template audits)] Model-size results: the statement that 'all tested 405B rows retain positive expected-rank margins' while 8B/70B show constructor-specific mixed cells is presented without the number of templates, prompts, or variance estimates. This makes it impossible to evaluate whether the reported pattern reflects stable rank-indexed geometry or sampling variability, directly affecting the cross-scale generality claim.
Authors: The full manuscript uses multiple templates per relation arity and reports the cross-scale pattern, but the abstract omits exact counts and variance. We will update the abstract and results section to state the number of templates (typically 4–8 per arity), total prompts evaluated per model, and variance estimates (standard deviations or ranges across templates) so readers can assess stability directly. revision: yes
Circularity Check
No circularity: empirical claims rest on independent controls and audits
full rationale
The paper reports empirical measurements of Plucker sign entropy on hidden states for true vs. scrambled relation tuples, plus clean/corrupt patching interventions with multiple controls (scrambled tuples, centroid-only, equal-norm, site/order permutations). No equations, derivations, or predictions are shown that reduce by construction to fitted inputs or self-citations. The abstract explicitly frames the controls as matched random audits and site/order separations that are independent of the target geometry. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Plucker sign entropy on hidden-state tuples measures arity-matched orientation signatures independent of lexical surface form
- domain assumption The edge-grid intervention assay holds answer format and row/column scaffold fixed while only the relation map changes
Reference graph
Works this paper leans on
-
[1]
L., Chen, B., Citro, C., and others
Ameisen, E., Lindsey, J., Pearce, A., Gurnee, W., Turner, N. L., Chen, B., Citro, C., and others. Circuit tracing: revealing computational graphs in language models.Transformer Circuits Thread, 2025
2025
-
[2]
Y., Sheth, P., Muralidharan, B., Elamaran, N., Kinra, A., Morgan, J., and Batniji, R
Basu, S., Patel, S. Y., Sheth, P., Muralidharan, B., Elamaran, N., Kinra, A., Morgan, J., and Batniji, R. Interpretability without actionability: mechanistic methods cannot correct language model errors despite near-perfect internal representations.arXiv preprint arXiv:2603.18353, 2026
-
[3]
Networks beyond pairwise interactions: structure and dynamics.Physics Reports, 874:1–92, 2020
Battiston, F., Cencetti, G., Iacopini, I., Latora, V., Lucas, M., Patania, A., Young, J.-G., and Petri, G. Networks beyond pairwise interactions: structure and dynamics.Physics Reports, 874:1–92, 2020
2020
-
[4]
R., Abebe, R., Schaub, M
Benson, A. R., Abebe, R., Schaub, M. T., Jadbabaie, A., and Kleinberg, J. Simplicial closure and higher-order link prediction.Proceedings of the National Academy of Sciences, 115(48):E11221–E11230, 2018
2018
-
[5]
Bhalla, U., Fel, T., Rager, C., Feucht, S., Haklay, T., Wurgaft, D., Boppana, S., Kowal, M., Shyam, V., Merullo, J., Geiger, A., and Lubana, E. S. Do sparse autoencoders capture concept manifolds?arXiv preprint arXiv:2604.28119, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
M.Oriented Matroids
Bj¨ orner, A., Las Vergnas, M., Sturmfels, B., White, N., and Ziegler, G. M.Oriented Matroids. Cambridge University Press, 2nd edition, 1999
1999
-
[7]
L., and others
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N. L., and others. Towards monosemanticity: decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
2023
-
[8]
N., Lynch, A., Heimersheim, S., and Garriga-Alonso, A
Conmy, A., Mavor-Parker, A. N., Lynch, A., Heimersheim, S., and Garriga-Alonso, A. Towards automated circuit discovery for mechanistic interpretability.Advances in Neural Information Processing Systems, 2023
2023
-
[9]
R., Ewart, A., and Sharkey, L
Huben, R., Cunningham, H., Smith, L. R., Ewart, A., and Sharkey, L. Sparse autoencoders find highly interpretable features in language models.International Conference on Learning Representations, 2024
2024
-
[10]
Cell-Based Representation of Relational Binding in Language Models
Dai, Q., Heinzerling, B., and Inui, K. Cell-based representation of relational binding in language models. arXiv preprint arXiv:2604.19052, 2026. 31
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
Diego-Sim´ on, P., D’Ascoli, S., Chemla, E., Lakretz, Y., and King, J.-R. A polar coordinate system represents syntax in large language models.arXiv preprint arXiv:2412.05571, 2024
-
[12]
A mathematical framework for transformer circuits.Transformer Circuits Thread, 2021
Elhage, N., Nanda, N., Olsson, C., Henighan, T., Joseph, N., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., and others. A mathematical framework for transformer circuits.Transformer Circuits Thread, 2021
2021
-
[13]
Evaluating Relational Reasoning in LLMs with REL
Fesser, L., Ektefaie, Y., Fang, A., Kakade, S. M., and Zitnik, M. Evaluating relational reasoning in LLMs with REL.arXiv preprint arXiv:2604.12176, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Arithmetic in the Wild: Llama uses Base-10 Addition to Reason About Cyclic Concepts
Feucht, S., Haklay, T., Bhalla, U., Wurgaft, D., Rager, C., Sarfati, R., Merullo, J., McGrath, T., Lewis, O., Lubana, E. S., Fel, T., and Geiger, A. Arithmetic in the wild: Llama uses base-10 addition to reason about cyclic concepts.arXiv preprint arXiv:2605.01148, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Feng, J. and Steinhardt, J. How do language models bind entities in context?arXiv preprint arXiv:2310.17191, 2024
-
[16]
Causal abstractions of neural networks.Advances in Neural Information Processing Systems, 2021
Geiger, A., Lu, H., Icard, T., and Potts, C. Causal abstractions of neural networks.Advances in Neural Information Processing Systems, 2021
2021
-
[17]
Structure-mapping: a theoretical framework for analogy.Cognitive Science, 7(2):155–170, 1983
Gentner, D. Structure-mapping: a theoretical framework for analogy.Cognitive Science, 7(2):155–170, 1983
1983
-
[18]
S., Wilson, W
Halford, G. S., Wilson, W. H., and Phillips, S. Processing capacity defined by relational complexity. Behavioral and Brain Sciences, 21(6):803–831, 1998
1998
-
[19]
Linearity of relation decoding in transformer language models.International Conference on Learning Representations, 2024
Hernandez, E., Sen Sharma, A., Haklay, T., Meng, K., Wattenberg, M., Andreas, J., Belinkov, Y., and Bau, D. Linearity of relation decoding in transformer language models.International Conference on Learning Representations, 2024
2024
-
[20]
L., Citro, C., and others
Lindsey, J., Gurnee, W., Ameisen, E., Chen, B., Pearce, A., Turner, N. L., Citro, C., and others. On the biology of a large language model.Transformer Circuits Thread, 2025
2025
-
[21]
Locating and editing factual associations in GPT
Meng, K., Bau, D., Andonian, A., and Belinkov, Y. Locating and editing factual associations in GPT. Advances in Neural Information Processing Systems, 2022
2022
-
[22]
J., and Veitch, V
Park, K., Choe, Y. J., and Veitch, V. The linear representation hypothesis and the geometry of large language models.Proceedings of the 41st International Conference on Machine Learning, 2024
2024
-
[23]
Attribution patching outperforms automated circuit discovery
Syed, A., Rager, C., and Conmy, A. Attribution patching outperforms automated circuit discovery. arXiv preprint arXiv:2310.10348, 2023
-
[24]
Sarfati, R., Bigelow, E., Wurgaft, D., Boppana, S., Merullo, J., Geiger, A., Lewis, O., McGrath, T., and Lubana, E. S. The shape of beliefs: geometry, dynamics, and interventions along representation manifolds of language models’ posteriors.arXiv preprint arXiv:2602.02315, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Hypothesis-driven feature manifold analysis in LLMs via supervised multi-dimensional scaling.Transactions on Machine Learning Research,
Tiblias, F., Bigoulaeva, I., Niu, J., Balloccu, S., and Gurevych, I. Hypothesis-driven feature manifold analysis in LLMs via supervised multi-dimensional scaling.Transactions on Machine Learning Research,
-
[26]
R., Variengien, A., Conmy, A., Shlegeris, B., and Steinhardt, J
Wang, K. R., Variengien, A., Conmy, A., Shlegeris, B., and Steinhardt, J. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small.International Conference on Learning Representations, 2023
2023
-
[27]
Wurgaft, D., Rager, C., Kowal, M., Shyam, V., Feucht, S., Bhalla, U., Haklay, T., Bigelow, E., Sarfati, R., McGrath, T., Lewis, O., Merullo, J., Goodman, N., Fel, T., Geiger, A., and Lubana, E. S. Manifold steering reveals the shared geometry of neural network representation and behavior.arXiv preprint arXiv:2605.05115, 2026. 32
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.