Reinforcement Learning with Robust Rubric Rewards
Pith reviewed 2026-06-29 07:37 UTC · model grok-4.3
The pith
Reinforcement learning with robust rubric rewards extends verifiable supervision from whole tasks to individual criteria in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
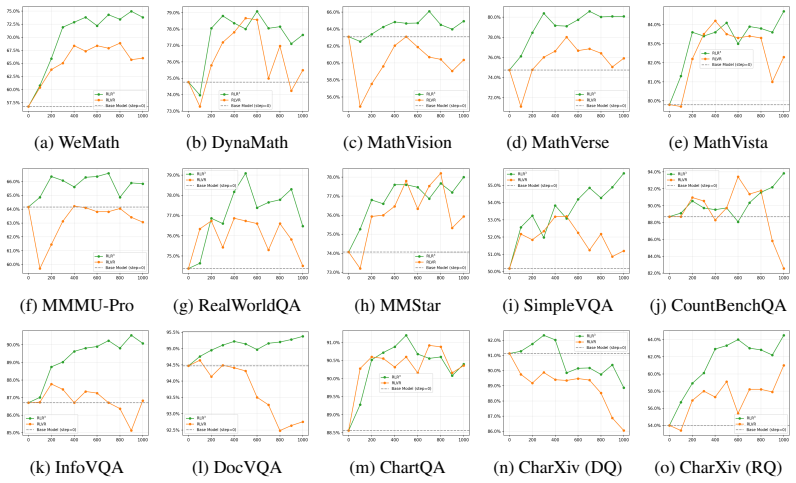
RLR³ extends RLVR from task-level verification to criterion-level verification by executing instance-specific rubrics along two protected paths—an LLM-as-extractor paired with a deterministic verifier, or an LLM-as-Judge—while enforcing minimal exposure masking of ground truths and images. Hierarchical aggregation prioritizes essential criteria and saturation mitigation prevents score collapse within rollout groups. The resulting rewards remain faithful enough that the method delivers consistent gains over RLVR baselines and the official model gap on the evaluated vision-language benchmarks.
What carries the argument
Dual rubric execution paths (LLM extractor plus deterministic verifier, or LLM judge) with minimal exposure masking, which together produce criterion-level scores that support online RL without introducing exploitable false positives.
If this is right
- RLVR can be extended from binary task success to graded multi-criteria supervision without losing deterministic guarantees on verifiable parts.
- Minimal exposure masking plus hierarchical aggregation together reduce score saturation and reward hacking in rubric-based training.
- The same rubric infrastructure yields measurable gains on 15 diverse vision-language benchmarks for a 30B-scale model.
- Controlled audits become a practical way to certify that the added LLM components do not increase false-positive exploitation.
Where Pith is reading between the lines
- The dual-path design may transfer to other partially verifiable domains such as code generation or mathematical proof steps where some sub-criteria admit deterministic checks.
- Minimal exposure could be tested as a general safeguard in any LLM-mediated reward pipeline to limit information leakage to the policy.
- If the audits hold, rubric rewards might become a scalable middle ground between pure outcome supervision and expensive human preference data.
Load-bearing premise
That routing rubrics through the extractor-verifier or judge paths plus minimal exposure masking produces faithful criterion scores that do not create new exploitable false positives beyond those checked in the audits.
What would settle it
A controlled audit or new benchmark run in which the policy achieves high rubric scores by exploiting patterns visible to the extractor or judge yet fails to satisfy the stated criteria when the ground truth is revealed.
Figures



read the original abstract
While Reinforcement Learning with Verifiable Rewards (RLVR) is effective for deterministically checkable tasks, many vision-language tasks are partially verifiable, demanding multi-criteria supervision (e.g., perceptual details, reasoning steps, and constraints). Rubrics provide a natural interface for this fine-grained supervision, but their effectiveness depends on the execution accuracy during online RL. We propose Reinforcement Learning with Robust Rubric Rewards ($\text{RLR}^3$), extending RLVR from task-level verification to criterion-level verification. $\text{RLR}^3$ routes instance-specific rubrics through two execution paths: an LLM-as-an-extractor paired with a deterministic verifier, or an LLM-as-a-Judge for non-verifiable criteria. To ensure faithful scoring, $\text{RLR}^3$ introduce a minimal exposure strategy that masks ground truths from extractors and images from judges. Furthermore, $\text{RLR}^3$ employs hierarchical aggregation to prioritize essential criteria over additional criteria, and mitigates score saturation within rollout groups. Evaluated on Qwen3-VL-30B-A3B across 15 benchmarks, $\text{RLR}^3$ consistently outperforms RLVR, yielding a 4.7-point improvement over the base model and exceeding the official instruct-to-thinking model gap. Controlled audits confirm our deterministic verification and minimal exposure significantly reduce exploitable false positives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Reinforcement Learning with Robust Rubric Rewards (RLR³) as an extension of RLVR for vision-language tasks. It routes instance-specific rubrics through an LLM-as-extractor with deterministic verifier or LLM-as-Judge paths, applies minimal exposure (masking ground truth from extractors and images from judges), uses hierarchical aggregation to prioritize criteria, and mitigates score saturation. The central claim is that RLR³ consistently outperforms RLVR on Qwen3-VL-30B-A3B across 15 benchmarks, delivering a 4.7-point average gain over the base model that exceeds the official instruct-to-thinking gap, with controlled audits showing reduced exploitable false positives.
Significance. If the empirical gains and audit results prove robust, the approach offers a practical route to criterion-level rewards for partially verifiable VL tasks, potentially improving upon task-level RLVR by reducing reward hacking while preserving fine-grained supervision. The minimal-exposure masking and hierarchical aggregation are concrete engineering contributions that could generalize beyond the evaluated model.
major comments (2)
- [Abstract] Abstract: The headline result of a 4.7-point improvement (and outperformance of the instruct-to-thinking gap) is reported without error bars, per-benchmark tables, or any statistical significance tests. This is load-bearing for the claim of consistent outperformance across 15 benchmarks.
- [Abstract] Abstract: The assertion that 'controlled audits confirm our deterministic verification and minimal exposure significantly reduce exploitable false positives' provides no quantitative details on audit scale, rubric diversity, or measured judge accuracy under image masking for perceptual or constraint criteria. This directly affects the central assumption that the routing paths produce faithful scores without introducing new leakage.
minor comments (1)
- [Abstract] Grammatical error in the abstract: 'RLR³ introduce a minimal exposure strategy' should read 'RLR³ introduces a minimal exposure strategy'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and agree to revisions that improve the transparency of the reported results and audit details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline result of a 4.7-point improvement (and outperformance of the instruct-to-thinking gap) is reported without error bars, per-benchmark tables, or any statistical significance tests. This is load-bearing for the claim of consistent outperformance across 15 benchmarks.
Authors: We agree that the abstract would benefit from explicit pointers to the supporting analyses. The full manuscript reports per-benchmark scores across all 15 benchmarks in Table 2 (showing gains on every benchmark) along with the average improvement. Standard deviations from multiple random seeds appear in the appendix, and paired statistical significance tests are summarized in Appendix B. We will revise the abstract to reference these elements directly after the headline claim. revision: yes
-
Referee: [Abstract] Abstract: The assertion that 'controlled audits confirm our deterministic verification and minimal exposure significantly reduce exploitable false positives' provides no quantitative details on audit scale, rubric diversity, or measured judge accuracy under image masking for perceptual or constraint criteria. This directly affects the central assumption that the routing paths produce faithful scores without introducing new leakage.
Authors: The manuscript already contains the requested quantitative details in Section 4.3 (audit scale, rubric diversity across criteria types, and judge accuracy under image masking). To make this evidence visible at the abstract level, we will revise the relevant sentence to incorporate a concise summary of those quantitative findings. revision: yes
Circularity Check
No circularity: procedural method with external benchmark results
full rationale
The paper describes a procedural extension of RLVR to rubric-based criterion verification using LLM extractors, deterministic verifiers, LLM judges, minimal exposure masking, and hierarchical aggregation. No equations, derivations, or fitted parameters appear in the provided text. Performance claims rest on direct evaluations across 15 benchmarks on Qwen3-VL-30B-A3B, which are independent external measurements rather than quantities defined by the method itself. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing manner. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- criterion priority weights
axioms (1)
- domain assumption LLM-as-extractor and LLM-as-Judge produce sufficiently accurate criterion scores when ground truth and images are masked
Reference graph
Works this paper leans on
-
[1]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
2025
-
[2]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Kimi K2: Open Agentic Intelligence
Kimi Team. Kimi K2: open agentic intelligence.CoRR, abs/2507.20534, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
GLM. GLM-4.5: agentic, reasoning, and coding (ARC) foundation models.CoRR, abs/2508.06471, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
VLM-R1: A Stable and Generalizable R1-style Large Vision-Language Model
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. VLM-R1: A stable and generalizable r1-style large vision-language model.CoRR, abs/2504.07615, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
VL-Rethinker: Incentivizing Self-Reflection of Vision-Language Models with Reinforcement Learning
Haozhe Wang, Chao Qu, Zuming Huang, Wei Chu, Fangzhen Lin, and Wenhu Chen. Vl- rethinker: Incentivizing self-reflection of vision-language models with reinforcement learning. CoRR, abs/2504.08837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team. Kimi K2.5: visual agentic intelligence.CoRR, abs/2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, Shuaiqi Duan, Weihan Wang, Yan Wang, Yean Cheng, Zehai He, Zhe Su, Zhen Yang, Ziyang Pan, Aohan Zeng, Baoxu Wang, Boyan Shi, Changyu Pang, Chenhui Zhang, Da Yin, Fan Yang, Guoqing Chen, Jiazheng Xu, Jiali Chen, Jing Chen, Jinhao Chen, Jingha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.CoRR, abs/2507.17746, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Checklists are better than reward models for aligning language models.CoRR, abs/2507.18624, 2025
Vijay Viswanathan, Yanchao Sun, Shuang Ma, Xiang Kong, Meng Cao, Graham Neubig, and Tongshuang Wu. Checklists are better than reward models for aligning language models.CoRR, abs/2507.18624, 2025
-
[11]
Zenan Huang, Yihong Zhuang, Guoshan Lu, Zeyu Qin, Haokai Xu, Tianyu Zhao, Ru Peng, Jiaqi Hu, Zhanming Shen, Xiaomeng Hu, Xijun Gu, Peiyi Tu, Jiaxin Liu, Wenyu Chen, Yuzhuo Fu, Zhiting Fan, Yanmei Gu, Yuanyuan Wang, Zhengkai Yang, Jianguo Li, and Junbo Zhao. Reinforcement learning with rubric anchors.CoRR, abs/2508.12790, 2025
-
[12]
Visual Preference Optimization with Rubric Rewards
Ya-Qi Yu, Fangyu Hong, Xiangyang Qu, Hao Wang, Gaojie Wu, Qiaoyu Luo, Nuo Xu, Huixin Wang, Wuheng Xu, Yongxin Liao, Zihao Chen, Haonan Li, Ziming Li, Dezhi Peng, Minghui Liao, Jihao Wu, Haoyu Ren, and Dandan Tu. Visual preference optimization with rubric rewards. CoRR, abs/2604.13029, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Shu Pu, Yaochen Wang, Dongping Chen, Yuhang Chen, Guohao Wang, Qi Qin, Zhongyi Zhang, Zhiyuan Zhang, Zetong Zhou, Shuang Gong, Yi Gui, Yao Wan, and Philip S. Yu. Judge anything: MLLM as a judge across any modality. In Luiza Antonie, Jian Pei, Xiaohui Yu, Flavio Chierichetti, Hady W. Lauw, Yizhou Sun, and Srinivasan Parthasarathy, editors,Proceedings of th...
2025
-
[14]
Tianyi Xiong, Yi Ge, Ming Li, Zuolong Zhang, Pranav Kulkarni, Kaishen Wang, Qi He, Zeying Zhu, Chenxi Liu, Ruibo Chen, Tong Zheng, Yanshuo Chen, Xiyao Wang, Renrui Zhang, Wenhu Chen, and Heng Huang. Multi-crit: Benchmarking multimodal judges on pluralistic criteria-following.CoRR, abs/2511.21662, 2025
-
[15]
Llm- rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts
Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. Llm- rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), A...
2024
-
[16]
Paperbench: Evaluating ai’s ability to replicate AI research
Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. Paperbench: Evaluating ai’s ability to replicate AI research. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, Tegan Mahara...
2025
-
[17]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. Healthbench: Evaluating large language models towards improved human health.CoRR, abs/2505.08775, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Zhilin Wang, Jaehun Jung, Ximing Lu, Shizhe Diao, Ellie Evans, Jiaqi Zeng, Pavlo Molchanov, Yejin Choi, Jan Kautz, and Yi Dong. Profbench: Multi-domain rubrics requiring professional knowledge to answer and judge.CoRR, abs/2510.18941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Afra Feyza Akyürek, Advait Gosai, Chen Bo Calvin Zhang, Vipul Gupta, Jaehwan Jeong, Anisha Gunjal, Tahseen Rabbani, Maria Mazzone, David Randolph, Mohammad Mahmoudi Meymand, Gurshaan Chattha, Paula Rodriguez, Diego Mares, Pavit Singh, Michael Liu, Subodh Chawla, Pete Cline, Lucy Ogaz, Ernesto Hernandez, Zihao Wang, Pavi Bhatter, Marcos Ayestaran, Bing Liu...
-
[20]
Yang Zhou, Sunzhu Li, Shunyu Liu, Wenkai Fang, Jiale Zhao, Jingwen Yang, Jianwei Lv, Kongcheng Zhang, Yihe Zhou, Hengtong Lu, Wei Chen, Yan Xie, and Mingli Song. Breaking the exploration bottleneck: Rubric-scaffolded reinforcement learning for general LLM reasoning. CoRR, abs/2508.16949, 2025
-
[21]
Ran Xu, Tianci Liu, Zihan Dong, Tony Yu, Ilgee Hong, Carl Yang, Linjun Zhang, Tao Zhao, and Haoyu Wang. Alternating reinforcement learning for rubric-based reward modeling in non-verifiable llm post-training.CoRR, abs/2602.01511, 2026
-
[22]
InInternational Con- ference on Learning Representations, volume 2024, pages 29927–29962
Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang, Tuo Zhao, and Haoyu Wang. Openrubrics: Towards scalable synthetic rubric generation for reward modeling and LLM alignment.CoRR, abs/2510.07743, 2025
-
[23]
Online rubrics elicitation from pairwise comparisons.arXiv preprint arXiv:2510.07284,
MohammadHossein Rezaei, Robert Vacareanu, Zihao Wang, Clinton Wang, Bing Liu, Yunzhong He, and Afra Feyza Akyürek. Online rubrics elicitation from pairwise comparisons.CoRR, abs/2510.07284, 2025
-
[24]
Lipeng Xie, Sen Huang, Zhuo Zhang, Anni Zou, Yunpeng Zhai, Dingchao Ren, Kezun Zhang, Haoyuan Hu, Boyin Liu, Haoran Chen, Zhaoyang Liu, and Bolin Ding. Auto-rubric: Learning to extract generalizable criteria for reward modeling.CoRR, abs/2510.17314, 2025
-
[25]
Sunzhu Li, Jiale Zhao, Miteto Wei, Huimin Ren, Yang Zhou, Jingwen Yang, Shunyu Liu, Kaike Zhang, and Wei Chen. Rubrichub: A comprehensive and highly discriminative rubric dataset via automated coarse-to-fine generation.CoRR, abs/2601.08430, 2026
-
[26]
Zicheng Kong, Dehua Ma, Zhenbo Xu, Alven Yang, Yiwei Ru, Haoran Wang, Zixuan Zhou, Fuqing Bie, Liuyu Xiang, Huijia Wu, Jian Zhao, and Zhaofeng He. Omni-rrm: Advancing omni reward modeling via automatic rubric-grounded preference synthesis.CoRR, abs/2602.00846, 2026
-
[27]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Weinan Dai, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Kaichen Zhang, Keming Wu, Zuhao Yang, Bo Li, Kairui Hu, Bin Wang, Ziwei Liu, Xingxuan Li, and Lidong Bing. Openmmreasoner: Pushing the frontiers for multimodal reasoning with an open and general recipe.CoRR, abs/2511.16334, 2025
-
[29]
Haoxiang Sun, Lizhen Xu, Bing Zhao, Wotao Yin, Wei Wang, Boyu Yang, Rui Wang, and Hu Wei. Deepvision-103k: A visually diverse, broad-coverage, and verifiable mathematical dataset for multimodal reasoning.CoRR, abs/2602.16742, 2026
-
[30]
Runqi Qiao, Qiuna Tan, Guanting Dong, Minhui Wu, Chong Sun, Xiaoshuai Song, Jiapeng Wang, Zhuoma Gongque, Shanglin Lei, Yifan Zhang, Zhe Wei, Miaoxuan Zhang, Runfeng Qiao, Xiao Zong, Yida Xu, Peiqing Yang, Zhimin Bao, Muxi Diao, Chen Li, and Honggang Zhang. We-math: Does your large multimodal model achieve human-like mathematical reasoning? In Wanxiang Ch...
2025
-
[31]
Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models
Chengke Zou, Xingang Guo, Rui Yang, Junyu Zhang, Bin Hu, and Huan Zhang. Dynamath: A dynamic visual benchmark for evaluating mathematical reasoning robustness of vision language models. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025
2025
-
[32]
Measuring multimodal mathematical reasoning with math-vision dataset
Ke Wang, Junting Pan, Weikang Shi, Zimu Lu, Houxing Ren, Aojun Zhou, Mingjie Zhan, and Hongsheng Li. Measuring multimodal mathematical reasoning with math-vision dataset. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information Processing Systems 38: 12 Annua...
2024
-
[33]
Renrui Zhang, Dongzhi Jiang, Yichi Zhang, Haokun Lin, Ziyu Guo, Pengshuo Qiu, Aojun Zhou, Pan Lu, Kai-Wei Chang, Yu Qiao, Peng Gao, and Hongsheng Li. MATHVERSE: does your multi-modal LLM truly see the diagrams in visual math problems? In Ales Leonardis, Elisa Ricci, Stefan Roth, Olga Russakovsky, Torsten Sattler, and Gül Varol, editors,Computer Vision - E...
2024
-
[34]
MathVista: Evaluating Mathematical Reasoning of Foundation Models in Visual Contexts
Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating math reasoning in visual contexts with gpt-4v, bard, and other large multimodal models.CoRR, abs/2310.02255, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, Yu Su, Wenhu Chen, and Graham Neubig. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meet...
2025
-
[36]
Grok-1.5 vision preview
xAI. Grok-1.5 vision preview. https://x.ai/news/grok-1.5v, 2024. Accessed: 2024-05- 20
2024
-
[37]
Are we on the right way for evaluating large vision-language models? In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Yu Qiao, Dahua Lin, and Feng Zhao. Are we on the right way for evaluating large vision-language models? In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and Cheng Zhang, editors,Advances in Neural Information P...
2024
-
[38]
Xianfu Cheng, Wei Zhang, Shiwei Zhang, Jian Yang, Xiangyuan Guan, Xianjie Wu, Xiang Li, Ge Zhang, Jiaheng Liu, Yuying Mai, Yutao Zeng, Zhoufutu Wen, Ke Jin, Baorui Wang, Weixiao Zhou, Yunhong Lu, Tongliang Li, Wenhao Huang, and Zhoujun Li. Simplevqa: Multimodal factuality evaluation for multimodal large language models.CoRR, abs/2502.13059, 2025
-
[39]
Lucas Beyer, Andreas Steiner, André Susano Pinto, Alexander Kolesnikov, Xiao Wang, Daniel Salz, Maxim Neumann, Ibrahim Alabdulmohsin, Michael Tschannen, Emanuele Bugliarello, Thomas Unterthiner, Daniel Keysers, Skanda Koppula, Fangyu Liu, Adam Grycner, Alexey A. Gritsenko, Neil Houlsby, Manoj Kumar, Keran Rong, Julian Eisenschlos, Rishabh Kabra, Matthias ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
Minesh Mathew, Viraj Bagal, Rubèn Tito, Dimosthenis Karatzas, Ernest Valveny, and C. V . Jawahar. Infographicvqa. InIEEE/CVF Winter Conference on Applications of Computer Vision, WACV 2022, Waikoloa, HI, USA, January 3-8, 2022, pages 2582–2591. IEEE, 2022
2022
-
[41]
Minesh Mathew, Dimosthenis Karatzas, R. Manmatha, and C. V . Jawahar. Docvqa: A dataset for VQA on document images.CoRR, abs/2007.00398, 2020
-
[42]
Joty, and Enamul Hoque
Ahmed Masry, Do Xuan Long, Jia Qing Tan, Shafiq R. Joty, and Enamul Hoque. Chartqa: A benchmark for question answering about charts with visual and logical reasoning. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio, editors,Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22-27, 2022, Findings of ACL, p...
2022
-
[43]
es se nt ia l
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, Alexis Chevalier, Sanjeev Arora, and Danqi Chen. 13 Charxiv: Charting gaps in realistic chart understanding in multimodal llms. In Amir Globersons, Lester Mackey, Danielle Belgrave, Angela Fan, Ulrich Paquet, Jakub M. Tomczak, and C...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.