LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis
Pith reviewed 2026-06-29 08:54 UTC · model grok-4.3
The pith
State-of-the-art agents reach only 48.45 percent accuracy on long-horizon data analysis tasks because they lose track of evolving analytical states.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
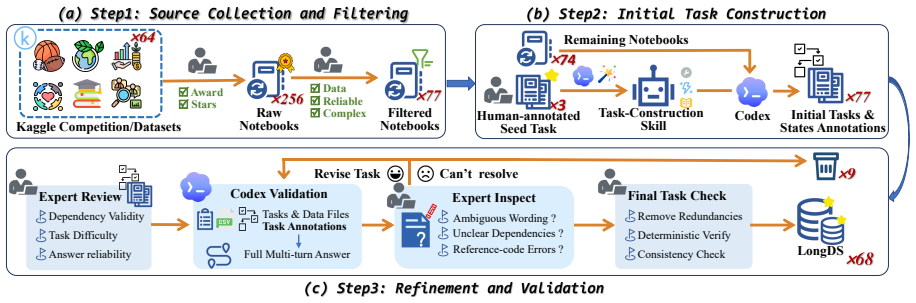
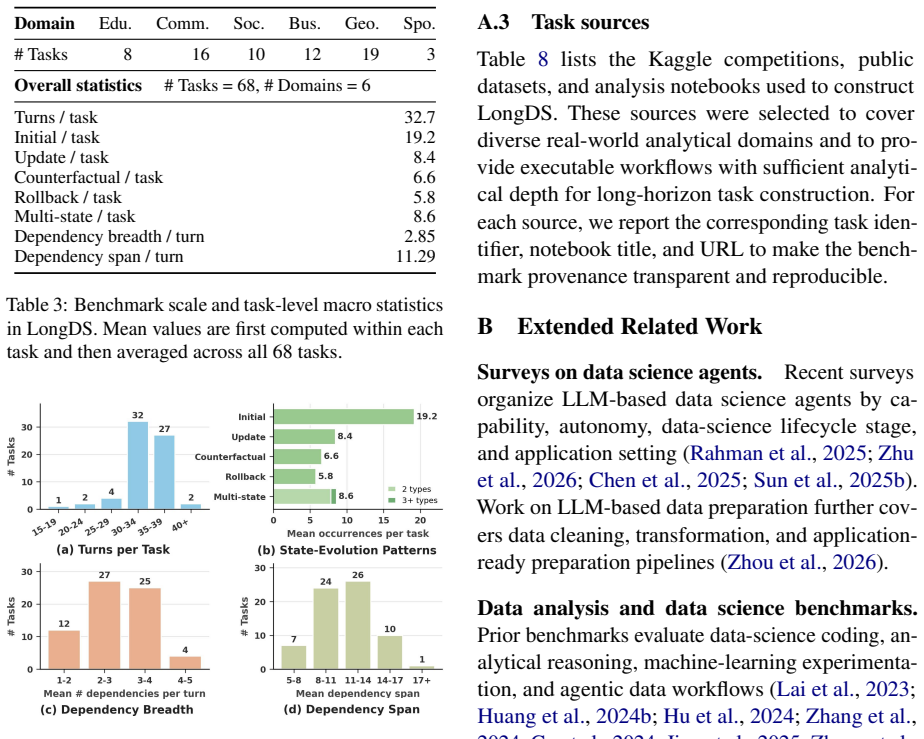
LongDS contains 68 tasks built from Kaggle notebooks across six domains and 2,225 total turns, organized around state-evolution patterns such as counterfactual perturbation, rollback, and multi-state composition. The best model achieves 48.45 percent average accuracy, performance falls nearly 47 points from early to late turns, and long-horizon errors account for 52 to 69 percent of failures. Additional agent steps do not raise performance, indicating the bottleneck lies in maintaining a correct analytical state rather than interaction budget.
What carries the argument
LongDS benchmark of 68 tasks built around state-evolution patterns with average dependency span of 11.3 turns.
If this is right
- Accuracy declines nearly 47 points from early turns to late turns.
- Long-horizon errors cause between 52 and 69 percent of all failures.
- Increasing the number of agent steps does not improve task success.
- The main limit is maintaining correct state rather than interaction length.
Where Pith is reading between the lines
- Benchmarks limited to short interactions likely overstate current agent reliability on iterative work.
- New mechanisms focused on explicit state restoration could reduce the observed error accumulation.
- Domains such as business and geoscience may see larger gaps until state-tracking improves.
Load-bearing premise
The 68 tasks from Kaggle notebooks, with their specific state-evolution patterns, represent the long-horizon challenges that arise in real-world iterative data analysis.
What would settle it
An experiment that measures whether models can correctly restore or compose analytical states after a sequence of perturbations without accumulating errors across 10 or more turns.
Figures






read the original abstract
Real-world data analysis is inherently iterative, yet existing benchmarks mostly evaluate isolated or short interactive tasks, leaving agents' ability to track evolving analytical context over long horizons untested. We introduce LongDS, a benchmark for long-horizon, multi-turn data analysis where agents must maintain, update, restore, and compose evolving analytical states. LongDS comprises 68 tasks constructed from real-world Kaggle notebooks, spanning 2,225 turns across six domains including Geoscience, Business, and Education. Tasks are designed around state-evolution patterns (e.g., counterfactual perturbation, rollback, multi-state composition), with an average dependency span of 11.3 turns. Evaluating five state-of-the-art models, we find that the best model reaches only 48.45% average accuracy, performance drops nearly 47 points from early to late turns, and long-horizon errors account for 52%--69% of failures. Further analysis shows that additional agent steps do not necessarily improve performance, suggesting that the key bottleneck is maintaining a correct analytical state rather than increasing interaction budget. We release LongDS to support research on reliable long-horizon agentic data analysis. Code and data will be released at https://github.com/zjunlp/DataMind.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LongDS-Bench, a benchmark for long-horizon agentic data analysis consisting of 68 tasks derived from real Kaggle notebooks across six domains (Geoscience, Business, Education, etc.). The tasks involve 2,225 turns with an average dependency span of 11.3 turns and are built around state-evolution patterns including counterfactual perturbation, rollback, and multi-state composition. Evaluation of five state-of-the-art models shows the best model achieving only 48.45% average accuracy, with performance dropping nearly 47 points from early to late turns and long-horizon errors accounting for 52--69% of failures. The authors conclude that the primary bottleneck is maintaining correct analytical state rather than interaction budget and release the benchmark to support further research.
Significance. If the 68 tasks and their state-evolution patterns prove representative of real-world iterative data analysis workflows, the results would demonstrate a clear limitation in current LLM-based agents for practical long-horizon tasks, providing a concrete benchmark to drive progress on state tracking and error recovery. The release of code and data strengthens the contribution by enabling reproducible follow-up work.
major comments (3)
- [§3] Benchmark construction (high-level description in abstract and §3): the claim that long-horizon errors are the dominant failure mode (52--69%) and that the 47-point early-to-late drop is representative rests on the assumption that the chosen state-evolution patterns and 11.3-turn dependency span match typical analyst workflows, yet no expert validation, inter-annotator agreement, or coverage statistics against other analysis traces are reported.
- [Results] Evaluation protocol (results section): headline numbers (48.45% accuracy, 47-point drop, 52--69% long-horizon errors) are presented without details on task validation, model prompting templates, exact definition of 'early' vs. 'late' turns, or statistical significance testing, making it impossible to assess whether the observed differences support the central claim about state-maintenance bottlenecks.
- [Discussion] Analysis of additional steps (discussion): the observation that extra agent steps do not improve performance is load-bearing for the conclusion that interaction budget is not the issue, but no ablation or per-task breakdown is supplied to rule out confounding factors such as prompt length or error accumulation.
minor comments (1)
- [Abstract] The abstract states 'Code and data will be released' but the manuscript should include a precise link or DOI in the camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional clarity and evidence would strengthen the paper. We address each major comment point-by-point below. Where the manuscript lacks sufficient detail, we will revise accordingly; where the construction choices reflect deliberate design decisions, we explain the rationale while acknowledging limitations.
read point-by-point responses
-
Referee: [§3] Benchmark construction (high-level description in abstract and §3): the claim that long-horizon errors are the dominant failure mode (52--69%) and that the 47-point early-to-late drop is representative rests on the assumption that the chosen state-evolution patterns and 11.3-turn dependency span match typical analyst workflows, yet no expert validation, inter-annotator agreement, or coverage statistics against other analysis traces are reported.
Authors: The 68 tasks were manually extracted and adapted from publicly available Kaggle notebooks chosen to exhibit iterative, multi-turn analytical patterns across six domains. Dependency spans and state-evolution patterns (counterfactual perturbation, rollback, multi-state composition) were identified directly from the notebook execution traces rather than invented. We acknowledge that no separate expert validation panel or inter-annotator agreement statistics were collected, and no quantitative coverage comparison against a broader corpus of analysis traces was performed. This is a genuine limitation of the current release. In revision we will expand §3 with a more detailed description of the notebook selection criteria, the exact procedure used to annotate state dependencies, and domain-level coverage statistics. We will also add a limitations paragraph noting the absence of external validation. revision: partial
-
Referee: [Results] Evaluation protocol (results section): headline numbers (48.45% accuracy, 47-point drop, 52--69% long-horizon errors) are presented without details on task validation, model prompting templates, exact definition of 'early' vs. 'late' turns, or statistical significance testing, making it impossible to assess whether the observed differences support the central claim about state-maintenance bottlenecks.
Authors: We agree that the main results section is too terse. The full manuscript contains task validation criteria in Appendix A, the exact prompting templates and system prompts in Appendix B, the definition of early turns (first three turns before any state dependency crosses the 11.3-turn average span) versus late turns (turns after the median dependency point), and paired t-tests with p-values for the early-to-late drop. These details were omitted from the main text for brevity. In the revised version we will move the key definitions and significance results into the main results section or add a dedicated evaluation-protocol subsection, and we will include a table summarizing per-model early/late accuracies with confidence intervals. revision: yes
-
Referee: [Discussion] Analysis of additional steps (discussion): the observation that extra agent steps do not improve performance is load-bearing for the conclusion that interaction budget is not the issue, but no ablation or per-task breakdown is supplied to rule out confounding factors such as prompt length or error accumulation.
Authors: The additional-steps experiment fixed the maximum interaction budget at 30 turns and compared performance when agents were allowed to continue versus when they were forced to stop at the ground-truth turn count; performance did not increase and in several cases degraded. We did not, however, provide a per-task breakdown or control for prompt-length growth and cumulative error. We accept this criticism. In revision we will add (i) a per-task scatter plot of accuracy versus allowed extra steps, (ii) an ablation that truncates history to keep prompt length constant, and (iii) error-type breakdowns conditioned on step count. These additions will be placed in the discussion or a new appendix. revision: yes
Circularity Check
No circularity; direct empirical evaluation on newly constructed benchmark.
full rationale
The paper introduces LongDS-Bench by constructing 68 tasks from Kaggle notebooks and reports model accuracies via direct evaluation. No equations, fitted parameters, predictions derived from inputs, or self-citation chains are present. Central claims (48.45% accuracy, performance drops, error breakdowns) are obtained by running models on the benchmark tasks themselves, with no reduction to prior fitted quantities or self-referential definitions. The representativeness assumption is an external validity concern, not a circularity in the derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
Workarena: How capable are web agents at solving common knowledge work tasks?Preprint, arXiv:2403.07718. Avik Dutta, Priyanshu Gupta, Hosein Hasanbeig, Rahul Pratap Singh, Harshit Nigam, Sumit Gulwani, Arjun Radhakrishna, Gustavo Soares, and Ashish Tiwari. 2025. Condabench: Interactive evaluation of language models for data analysis.Preprint, arXiv:2510.1...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Dabstep: Data agent benchmark for multi-step reasoning.Preprint, arXiv:2506.23719. Julia Elliott and Paul Mooney. 2021. 2021 kaggle ma- chine learning & data science survey. https://ka ggle.com/competitions/kaggle-survey-2021 . Kaggle. Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Gra- ham Neubig. 2023. Pal: Pro...
-
[3]
InfiAgent-DABench: Evaluating agents on data analysis tasks. InProceedings of the 41st Inter- national Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 19544–19572. PMLR. Qian Huang, Jian V ora, Percy Liang, and Jure Leskovec. 2024a. Mlagentbench: Evaluating language agents on machine learning experimentation.Pr...
-
[4]
GAIA: a benchmark for General AI Assistants
Gaia: a benchmark for general ai assistants. Preprint, arXiv:2311.12983. Paul Mooney. 2019. 2019 kaggle machine learning & data science survey. https://kaggle.com/compe titions/kaggle-survey-2019. Kaggle. Paul Mooney. 2020. 2020 kaggle machine learning & data science survey. https://kaggle.com/compe titions/kaggle-survey-2020. Kaggle. Paul Mooney. 2022. 2...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[5]
Jaehyun Nam, Jinsung Yoon, Jiefeng Chen, Raj Sinha, Jinwoo Shin, and Tomas Pfister
Mle-star: Machine learning engineering agent via search and targeted refinement.Preprint, arXiv:2506.15692. Jaehyun Nam, Jinsung Yoon, Jiefeng Chen, Raj Sinha, Jinwoo Shin, and Tomas Pfister. 2026. Ds-star: Data science agent for solving diverse tasks across hetero- geneous formats and open-ended queries.Preprint, arXiv:2509.21825. Fan Nie, Junlin Wang, H...
-
[6]
MemGPT: Towards LLMs as Operating Systems
Memgpt: Towards llms as operating systems. Preprint, arXiv:2310.08560. Joon Sung Park, Joseph O’Brien, Carrie Jun Cai, Mered- ith Ringel Morris, Percy Liang, and Michael S. Bern- stein. 2023. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th An- nual ACM Symposium on User Interface Software and Technology, UIST ’23, New...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language agents with verbal rein- forcement learning.Preprint, arXiv:2303.11366. Josefa Lia Stoisser, Marc Boubnovski Martell, Sidsel Boldsen, Kaspar Märtens, and Robert Kitchen. 2026. Ambig-ds: A benchmark for task-framing ambiguity in data-science agents.Preprint, arXiv:2605.09698. Ji Sun, Guoliang Li, Peiyao Zhou, Yihui Ma, Jingzhe Xu, and Y...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Can llms clean up your mess? a sur- vey of application-ready data preparation with llms. Preprint, arXiv:2601.17058. Yizhang Zhu, Liangwei Wang, Chenyu Yang, Xiaotian Lin, Boyan Li, Wei Zhou, Xinyu Liu, Zhangyang Peng, Tianqi Luo, Yu Li, Chengliang Chai, Chong Chen, Shimin Di, Ju Fan, Ji Sun, Nan Tang, Fugee Tsung, Jiannan Wang, Chenglin Wu, Yanwei Xu, Sh...
-
[9]
Understand the problem - interpret the question, data format, and expected output format
-
[10]
Explore and preprocess the data - load the datasets, perform data cleaning, feature engineering, and exploratory analysis where helpful
-
[11]
Change your plan if needed
Decompose the question and perform planning - break down the question into smaller steps and perform each step systematically. Change your plan if needed
-
[12]
Analyze the data - build appropriate statistical models, causal models, machine learning models, or other analyses to answer the research question
-
[13]
Generate final answer - provide a clear, specific answer to the question based on your analysis and the requirements
-
[14]
TASK: Tackle the given data science question by analyzing the provided data to generate a final answer
Explain reasoning - clearly communicate assumptions, methodology, and trade-offs at each step. TASK: Tackle the given data science question by analyzing the provided data to generate a final answer. Important rules: - Do not use plotting libraries (assume you cannot view plots). Use text-based summaries and statistics instead. - Your final answer should b...
-
[15]
You ONLY need to evaluate the fields in the `ground_truth`that directly answer the question
**Question-Driven Coverage** - First, analyze the`question`to determine which specific information is 23 requested. You ONLY need to evaluate the fields in the `ground_truth`that directly answer the question. Ignore extra fields in the `ground_truth`that are not requested. Ignore extra information in the solution as well, as long as all required informati...
-
[16]
- Compare numeric values exactly after normalizing trailing zeros after the decimal point
**Numeric values** - Numeric answers must match the ground truth exactly after ignoring insignificant trailing zeros. - Compare numeric values exactly after normalizing trailing zeros after the decimal point. - Trailing zeros after the decimal point are insignificant and should be ignored. - A decimal point followed only by zeros is equivalent to an integ...
-
[17]
- Trailing zeros may still be ignored unless the tolerance note explicitly requires fixed formatting
**Numeric tolerance** - If the ground truth explicitly includes a `tolerance`or`tolerance_note` field for a required numeric value: - Apply that tolerance **only** to the numeric value. - Trailing zeros may still be ignored unless the tolerance note explicitly requires fixed formatting
-
[18]
**Exception for ties:** If multiple items have the exact same numerical value, any order among those tied items is acceptable
**Rankings / ordered lists** - Verify both the items and their order. **Exception for ties:** If multiple items have the exact same numerical value, any order among those tied items is acceptable. Only evaluate rankings if the question actually asks for them
-
[19]
Do **not** consider variations in case, punctuation, spacing, apostrophes, typography, or shorthand forms when judging correctness
**Label normalization / aliases** - Ignore differences in labels entirely. Do **not** consider variations in case, punctuation, spacing, apostrophes, typography, or shorthand forms when judging correctness. Label names are **not** used as a criterion for correctness; only the associated values or required information are evaluated
-
[20]
Judge factual correctness only
**Formatting** - Ignore differences in wording, formatting, currency symbols, percent signs, or extra explanation. Judge factual correctness only
-
[21]
None"</error> <score>0 or 1</score>
**Scoring is binary** - Score **1** only if ALL required fields are correct. Score **0** if ANY required field is wrong or missing. --- ### Output Format Reply in EXACTLY this format: <reasoning> Step 1: Identify which fields in the ground truth are actually requested by the question. Step 2: Brief analysis of each required ground truth field vs. the solu...
-
[22]
Whether the error was newly introduced in the current task or propagated from previous tasks
-
[23]
results are listed from strongest to weakest unless otherwise specified
Whether the error is an ordinary data-analysis error or a long-horizon / multi-round error. Analyze tasks where`judge.score == 0` as incorrect. Do not rely on `success`alone:`success=True`can still be semantically wrong, and `success=False`often means the agent failed to produce a valid final answer. Error types must be selected only from the following ca...
-
[24]
Read`results_eval.json`first and identify all tasks with`judge.score == 0`
-
[25]
For each incorrect task, inspect the current question, context, reference answer, agent answer, trajectory, and evaluation reasoning
-
[26]
Compare`ground_code.py`and `code.py`to determine whether the discrepancy comes from output format, filtering scope, sorting, formula, join, aggregation, modeling pipeline, state inheritance, context memory, statistical/domain semantics, or upstream cascading
-
[27]
If needed, review previous tasks in `task.ipynb`to determine whether a missed condition was stated in the current task or only established earlier
-
[28]
If the task depends on a previous result, check whether the previous artifact was already wrong and whether the current task actually used it
-
[29]
Do not infer only from final numerical differences
Explain the concrete mechanism causing the mismatch. Do not infer only from final numerical differences
-
[30]
summary": {
When multiple error types overlap, choose the most direct current cause as`primary_error_type`and include other relevant types in `all_error_types`. ## Required Output Return a valid JSON object only. Do not output Markdown or explanatory prose. Use this format: { "summary": { "total_incorrect_tasks": 0, "primary_error_type_counts": { "Statistical / Domai...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.