An Organization-Scoped LLM Agent Runtime Architecture for Regulated Cybersecurity Operations
Pith reviewed 2026-06-29 06:23 UTC · model grok-4.3
The pith
A typed Security Context created at every entry point and enforced at every boundary organizes LLM agents for auditable regulated cybersecurity operations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
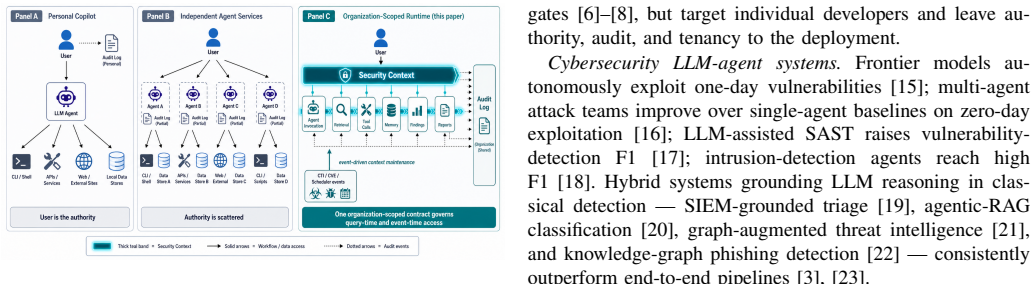
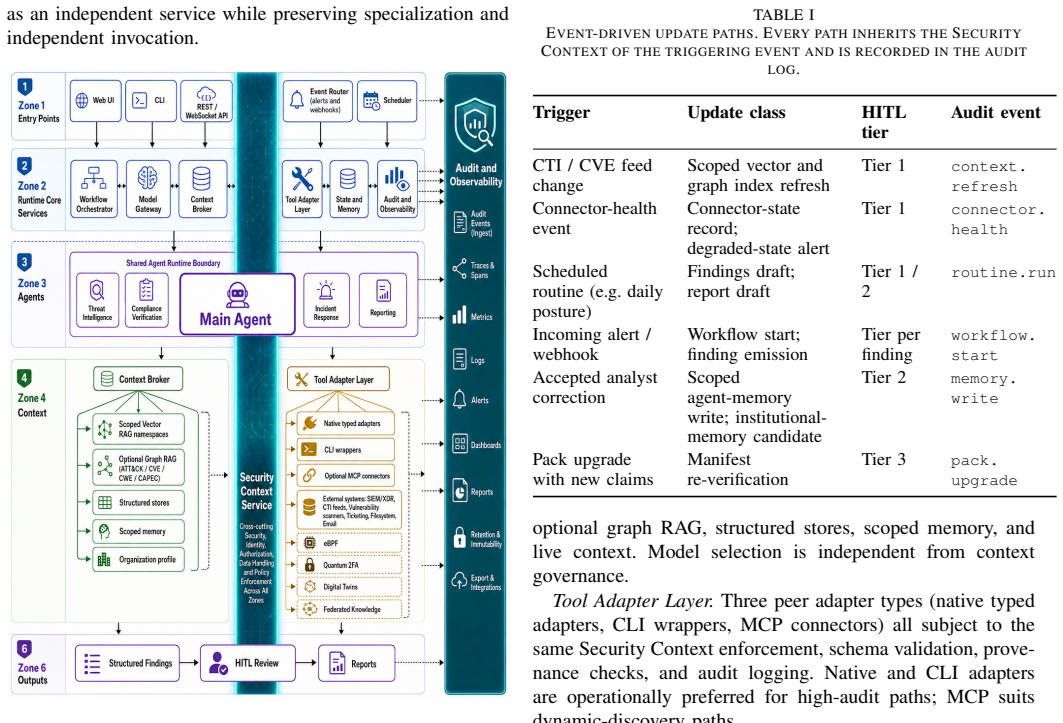
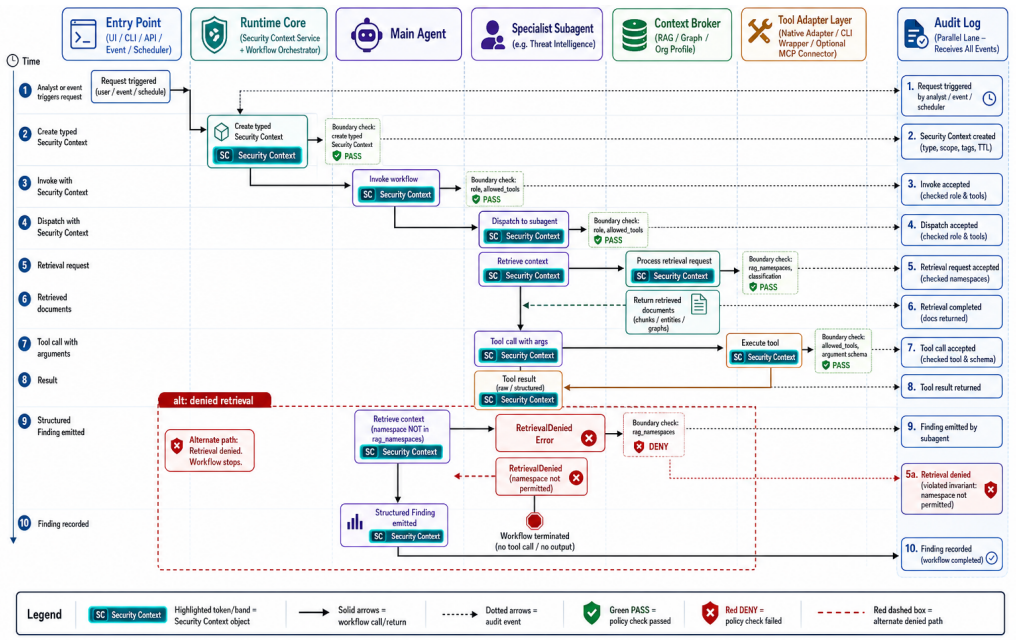
The central claim is that a typed Security Context instantiated at every entry point, including SIEM/XDR notifications as first-class triggers, and enforced at every component boundary, together with a shared Runtime Core, logical specialist subagents, a governed Tool Adapter Layer, structured findings with evidence references, tiered human-in-the-loop gates, and append-only audit, supplies the missing runtime substrate for organization-scoped, model-agnostic, locally deployable LLM agent operations in financial cybersecurity.
What carries the argument
The typed Security Context, which is created at entry points and carries organization scope and policy to be checked at every boundary and tool call.
If this is right
- SIEM and XDR notifications become direct triggers that start agent workflows under the same context rules as analyst-initiated tasks.
- All tool calls to query, enrich, or respond through SIEM or XDR systems occur only through a single governed adapter layer that applies uniform policy and logging.
- Findings are produced in structured form that always references the original evidence and can be traced through the audit trail.
- Tiered human review gates can be inserted at defined points without changing the underlying agent logic.
- The entire system remains usable with any LLM backend and can be deployed inside the organization's own infrastructure.
Where Pith is reading between the lines
- If the context enforcement works, organizations could treat the agent runtime as an additional controlled user of their existing security tools rather than a separate analytical layer.
- The same boundary checks might later support optional extensions such as graph-based retrieval or federated knowledge sharing without altering the core enforcement model.
- A working implementation would make it possible to measure policy compliance as a first-class metric alongside task accuracy.
Load-bearing premise
That this typed Security Context and its enforcement mechanisms can be implemented and kept consistent across different SIEM and XDR systems and different LLM backends without adding unacceptable delay or new ways for policy to be bypassed.
What would settle it
A test run in which an LLM agent action that violates the stated organization policy succeeds because the Security Context was not created or checked at one of the component boundaries.
Figures
read the original abstract
Regulated cybersecurity workflows lack a runtime substrate that enforces organization-level scope across retrieval, tool calls, memory, findings, reports, and audit while remaining model-agnostic and locally deployable. Recent large language model (LLM) agent systems report strong results on isolated cybersecurity tasks, yet they do not by themselves define an auditable platform architecture for regulated security operations centre (SOC) and compliance workflows, where a single analyst may trigger actions that bind the organization, and where the runtime must integrate with existing SIEM/XDR stacks as a primary source of context and alert-driven triggers rather than operate as a standalone analytical layer. This paper proposes an organization-scoped LLM agent runtime architecture for financial cybersecurity. The contribution is a typed Security Context that is created at every entry point, including SIEM/XDR notifications ingested as first-class triggers, and enforced at every component boundary, combined with a shared Runtime Core, logical specialist subagents, a governed Tool Adapter Layer exposing SIEM/XDR query, enrichment, and response primitives under uniform policy and audit, structured findings with evidence references, tiered human-in-the-loop (HITL) gates, and append-only audit. Model Context Protocol (MCP), extended telemetry, digital twins for pentesting, graph retrieval, and federated knowledge sharing are treated as optional extension paths rather than mandatory runtime assumptions. We describe an implementable slice as the architecture's testability surface, and we propose a falsifiable evaluation plan with metric-level pass criteria for architecture readiness, security-policy enforcement, evidence traceability, output quality, and operational observability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an organization-scoped LLM agent runtime architecture for regulated financial cybersecurity operations. The central contribution is a typed Security Context created at every entry point (including SIEM/XDR notifications as first-class triggers) and enforced at every component boundary. This is combined with a shared Runtime Core, logical specialist subagents, a governed Tool Adapter Layer exposing SIEM/XDR primitives under uniform policy and audit, structured findings with evidence references, tiered human-in-the-loop gates, and append-only audit. Model Context Protocol and other extensions are treated as optional. The paper describes an implementable slice as a testability surface and proposes a falsifiable evaluation plan with metric-level pass criteria for architecture readiness, security-policy enforcement, evidence traceability, output quality, and operational observability.
Significance. If the enforcement claims hold under implementation, the architecture would address a genuine gap by providing an auditable, model-agnostic substrate for LLM agents in regulated SOC environments that integrates directly with existing SIEM/XDR stacks rather than operating standalone. The proposal of a falsifiable evaluation plan with explicit pass criteria is a positive element that could support future verification. The model-agnostic and locally deployable emphasis is also a strength for practical adoption.
major comments (2)
- [Abstract] Abstract (contribution paragraph): The claim that a typed Security Context 'is created at every entry point... and enforced at every component boundary' is load-bearing for the organization-scoped guarantee, yet the architecture description provides no concrete enforcement primitives, isolation guarantees, or handling for LLM-specific risks such as prompt injection or tool misuse that could violate scope. This absence prevents assessment of whether the central claim can be realized across heterogeneous SIEM/XDR and LLM backends.
- [Abstract] Abstract: The manuscript presents only a high-level design proposal and evaluation plan with no implemented system, prototype data, formal invariants, or checked properties that could be used to verify internal consistency or correctness of the enforcement mechanisms.
minor comments (1)
- [Abstract] The abstract is information-dense; clearer enumeration or a diagram of the core components (Security Context, Runtime Core, Tool Adapter Layer) would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential of the proposed architecture to address gaps in regulated SOC environments. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (contribution paragraph): The claim that a typed Security Context 'is created at every entry point... and enforced at every component boundary' is load-bearing for the organization-scoped guarantee, yet the architecture description provides no concrete enforcement primitives, isolation guarantees, or handling for LLM-specific risks such as prompt injection or tool misuse that could violate scope. This absence prevents assessment of whether the central claim can be realized across heterogeneous SIEM/XDR and LLM backends.
Authors: We agree that the current description of enforcement remains at the architectural level without low-level primitives. In revision we will expand the Runtime Core and Tool Adapter Layer sections with concrete mechanisms, including typed context objects serialized with policy metadata, explicit boundary validation checks, context sanitization to mitigate prompt injection, and tool-call authorization lists derived from the Security Context. These additions will illustrate how the scoping guarantee can be realized across backends while preserving the model-agnostic stance. revision: yes
-
Referee: [Abstract] Abstract: The manuscript presents only a high-level design proposal and evaluation plan with no implemented system, prototype data, formal invariants, or checked properties that could be used to verify internal consistency or correctness of the enforcement mechanisms.
Authors: The manuscript is intentionally a design proposal that defines an organization-scoped runtime model together with a falsifiable evaluation plan and metric-level pass criteria. This scope is appropriate for establishing the substrate before implementation; the evaluation plan is provided precisely so that future prototypes can verify the claims. We therefore maintain the current contribution type and do not plan to add an implementation or formal proofs. revision: no
Circularity Check
No circularity in architecture design proposal
full rationale
The manuscript is a design proposal for an organization-scoped LLM agent runtime. It defines a typed Security Context created at entry points and enforced at boundaries, along with a Runtime Core, subagents, Tool Adapter Layer, HITL gates, and audit mechanisms. No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The contribution is presented as an architectural description rather than a reduction of outputs to prior inputs or self-citations. No load-bearing steps match the enumerated circularity patterns; the work is self-contained as a conceptual specification with a proposed evaluation plan.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Existing SIEM/XDR systems can expose query, enrichment, and response primitives under uniform policy without loss of fidelity or security.
- domain assumption A typed Security Context can be created and enforced at every boundary without introducing new vulnerabilities or unacceptable overhead.
invented entities (1)
-
typed Security Context
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y . Linet al., “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
2024
-
[2]
Market- senseai 2.0: Enhancing stock analysis through llm agents,
G. Fatouros, K. Metaxas, J. Soldatos, and M. Karathanassis, “Market- senseai 2.0: Enhancing stock analysis through llm agents,” in2025 IEEE International Conference on Data Mining Workshops (ICDMW), 2025, pp. 883–892
2025
-
[3]
A survey on agentic security: Applications, threats and defenses,
A. Shahriar, M. N. Rahman, S. Ahmed, F. Sadeque, and M. R. Parvez, “A survey on agentic security: Applications, threats and defenses,”arXiv preprint arXiv:2510.06445, 2025
-
[4]
CyberAId: AI-Driven Cybersecurity for Financial Service Providers
G. Fatouros, G. Makridis, J. Soldatos, D. Kyriazis, P. Malo, G. Kousiouris, G. Ledakis, L. Kachrimani, P. Rizomiliotis, B. Almeida et al., “Cyberaid: Ai-driven cybersecurity for financial service providers,”arXiv preprint arXiv:2605.01892, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[5]
Unrolling the codex agent loop,
OpenAI, “Unrolling the codex agent loop,” https://openai.com/index/ unrolling-the-codex-agent-loop, 2026, accessed 1 May 2026
2026
-
[6]
How claude code works,
Anthropic, “How claude code works,” https://docs.anthropic.com/en/ docs/agents-and-tools/claude-code/overview, 2026, accessed 1 May 2026
2026
-
[7]
Best practices for coding with agents,
Cursor, “Best practices for coding with agents,” https://www.cursor.com/ blog/agent-best-practices, 2026, accessed 1 May 2026
2026
-
[8]
Agent runtimes,
OpenClaw, “Agent runtimes,” https://docs.openclaw.ai/concepts/ agent-runtimes, 2026, accessed 1 May 2026
2026
-
[9]
Autogen: Enabling next-gen llm applications via multi-agent conversations,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “Autogen: Enabling next-gen llm applications via multi-agent conversations,” inFirst Conference on Language Modeling, 2024
2024
-
[10]
ReAct: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “ReAct: Synergizing reasoning and acting in language models,” inPro- ceedings of the International Conference on Learning Representations (ICLR 2023), Kigali, Rwanda, 2023
2023
-
[11]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in Neural Information Processing Systems, vol. 33, pp. 9459–9474, 2020
2020
-
[12]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022. TABLE VI FALSIFIABLE EVALUATION PLAN WITH METRIC-LEVEL PASS CRITERIA. Dimension Question Metric Pass criterion Archi...
2022
-
[13]
Can large language models beat wall street? evaluating gpt-4’s impact on financial decision-making with marketsenseai,
G. Fatouros, K. Metaxas, J. Soldatos, and D. Kyriazis, “Can large language models beat wall street? evaluating gpt-4’s impact on financial decision-making with marketsenseai,”Neural Computing and Applica- tions, vol. 37, no. 30, pp. 24 893–24 918, 2025
2025
-
[14]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dess `ı, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,”Advances in Neural Infor- mation Processing Systems, vol. 36, pp. 68 539–68 551, 2023
2023
-
[15]
LLM Agents can Autonomously Exploit One-day Vulnerabilities
R. Fang, R. Bindu, A. Gupta, and D. Kang, “LLM agents can autonomously exploit one-day vulnerabilities,”arXiv preprint arXiv:2404.08144, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Teams of llm agents can exploit zero-day vulnerabilities,
Y . Zhu, A. Kellermann, A. Gupta, P. Li, R. Fang, R. Bindu, and D. Kang, “Teams of llm agents can exploit zero-day vulnerabilities,” inProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), 2026, pp. 23–35
2026
-
[17]
IRIS: LLM-assisted static analysis for detecting security vulnerabilities,
Z. Li, S. Dutta, and M. Naik, “IRIS: LLM-assisted static analysis for detecting security vulnerabilities,”arXiv preprint arXiv:2405.17238, 2024, accepted at ICLR 2025
-
[18]
Ids-agent: An llm agent for explainable intrusion detection in iot networks,
Y . Li, Z. Xiang, N. D. Bastian, D. Song, and B. Li, “Ids-agent: An llm agent for explainable intrusion detection in iot networks,” inNeurIPS 2024 Workshop on Open-World Agents, 2024
2024
-
[19]
CORTEX: Collaborative LLM agents for high-stakes alert triage,
B. Wei, Y . S. Tay, H. Liu, J. Pan, K. Luo, Z. Zhu, and C. Jordan, “CORTEX: Collaborative LLM agents for high-stakes alert triage,”arXiv preprint arXiv:2510.00311, 2025
-
[20]
Cyberrag: An agentic rag cyber attack classification and reporting tool,
F. Blefari, C. Cosentino, F. A. Pironti, A. Furfaro, and F. Marozzo, “Cyberrag: An agentic rag cyber attack classification and reporting tool,” Future Generation Computer Systems, p. 108186, 2025
2025
-
[21]
CTIKG: LLM-powered knowledge graph construction from cyber threat intelligence,
L. Huang and X. Xiao, “CTIKG: LLM-powered knowledge graph construction from cyber threat intelligence,” inProceedings of the First Conference on Language Modeling (COLM 2024), Philadelphia, PA, USA, 2024
2024
-
[22]
KnowPhish: Large language models meet multimodal knowledge graphs for enhancing reference-based phishing detection,
Y . Li, C. Huang, S. Deng, M. L. Lock, T. Cao, N. Oo, H. W. Lim, and B. Hooi, “KnowPhish: Large language models meet multimodal knowledge graphs for enhancing reference-based phishing detection,” in 33rd USENIX Security Symposium (USENIX Security 24). USENIX Association, 2024, pp. 793–810
2024
-
[23]
Security of llm-based agents regarding attacks, defenses, and applications: A comprehensive survey,
Y . Tang, Y . Liu, J. Lan, Z. Yan, and E. Gelenbe, “Security of llm-based agents regarding attacks, defenses, and applications: A comprehensive survey,”Information Fusion, p. 103941, 2025
2025
-
[24]
From prompt injections to protocol exploits: Threats in llm-powered ai agents workflows,
M. A. Ferrag, N. Tihanyi, D. Hamouda, L. Maglaras, A. Lakas, and M. Debbah, “From prompt injections to protocol exploits: Threats in llm-powered ai agents workflows,”ICT Express, 2025
2025
-
[25]
The emerged security and privacy of LLM agent: A survey with case studies,
F. He, T. Zhu, D. Ye, B. Liu, W. Zhou, and P. S. Yu, “The emerged security and privacy of LLM agent: A survey with case studies,”ACM Computing Surveys, 2025
2025
-
[26]
Security best practices,
Model Context Protocol, “Security best practices,” https:// modelcontextprotocol.io/docs/tutorials/security/security best practices, 2026, accessed 1 May 2026
2026
-
[27]
Threatmodeling-llm: Automating threat modeling using large language models for banking system,
T. Wu, S. Yang, S. Liu, D. Nguyen, S. Jang, and A. Abuadbba, “Threatmodeling-llm: Automating threat modeling using large language models for banking system,”arXiv preprint arXiv:2411.17058, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.