What Makes LVLMs Hallucinate Less? Unveiling the Architectural Factors Behind Hallucination Robustness
Pith reviewed 2026-06-28 23:20 UTC · model grok-4.3
The pith
Architectural design in LVLMs affects three hallucination types differently, with parameter scaling showing only limited benefits overall.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
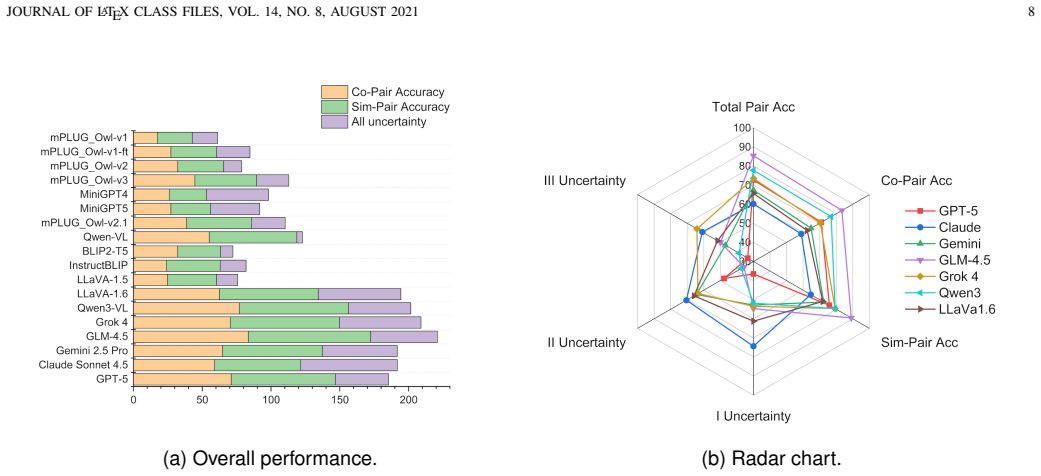
Factorizing LVLM architecture into Linguistic Foundation, Visual Representation, and Semantic Alignment dimensions, and hallucinations into Co-occurrence, Similarity, and Uncertainty types, reveals that parameter scaling has limited effect on all three hallucination kinds; larger and better-trained language foundations reduce co-occurrence errors; stronger visual encoders and higher resolutions reduce similarity errors; effective alignment strategies reduce uncertainty errors; and jointly improving visual fidelity with alignment produces the broadest gains.
What carries the argument
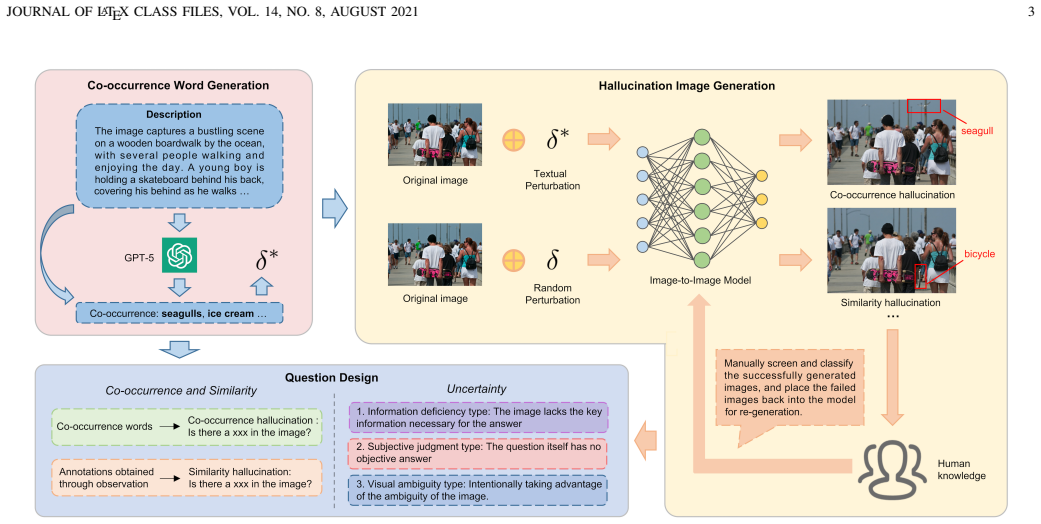
The three-dimensional factorization of architecture (Linguistic Foundation, Visual Representation, Semantic Alignment) together with the CoSimUE benchmark that uses controlled textual and random perturbations to isolate hallucination behaviors.
If this is right
- Developers should prioritize stronger language foundations when targeting co-occurrence hallucinations rather than uniform scaling.
- Investments in visual encoder strength and input resolution will primarily address similarity-based errors.
- Alignment techniques become the main lever for reducing uncertainty hallucinations.
- Simultaneous upgrades to visual representation and alignment deliver improvements across more hallucination categories than single-dimension changes.
- Future LVLM design can move away from blanket parameter increases toward dimension-specific optimizations.
Where Pith is reading between the lines
- The same factorization approach could be applied to other reliability issues such as bias or safety failures in multimodal models.
- Training curricula might be redesigned to emphasize the dimension that most affects the dominant error type in a given application domain.
- Hardware or data efficiency trade-offs could be re-evaluated once the relative value of each dimension is quantified.
Load-bearing premise
The benchmark's perturbations successfully isolate the effects of each architectural dimension on each hallucination type without major interference from training data or unmodeled interactions.
What would settle it
A controlled test in which a new LVLM varies only one dimension (for example, alignment strategy) while holding the others fixed and shows no corresponding change in the mapped hallucination type on the benchmark.
Figures


read the original abstract
Hallucination remains one of the key challenges undermining the reliability of Large Vision-Language Models (LVLMs). But what makes an LVLM hallucinate less? Many existing efforts focus on improving internal components of the model. We argue that hallucination fundamentally stems from how the model architecture is designed. To investigate this, we factor the architecture design into three dimensions: Linguistic Foundation (LF), Visual Representation (VR), and Semantic Alignment (SA), and categorize hallucinations into Co-occurrence, Similarity, and previously overlooked Uncertainty types. Building on this formulation, we propose CoSimUE, a benchmark that creates fine-grained hallucination scenarios through controlled textual perturbations and random perturbations, enabling mapping between design choices and hallucination behaviors. Experiments across 7 design aspects show that: 1) the widely emphasized scaling of model parameters has only limited impact on reducing all three types of hallucinations; 2) larger and better-trained language foundations can reduce co-occurrence hallucinations; 3) stronger visual encoders and higher resolutions mitigate similarity errors; 4) effective alignment strategies alleviate uncertainty hallucinations. 5) Furthermore, cross-dimensional analysis reveals that jointly enhancing visual fidelity and alignment quality yields the most comprehensive improvements. This study provides the first systematic exploration linking architecture-level design to hallucination robustness, offering practical guidance for developing reliable and efficient LVLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that hallucination in LVLMs fundamentally stems from architectural design, which it factors into three dimensions—Linguistic Foundation (LF), Visual Representation (VR), and Semantic Alignment (SA)—while categorizing hallucinations into Co-occurrence, Similarity, and Uncertainty types. It introduces the CoSimUE benchmark, which generates fine-grained scenarios via controlled textual perturbations and random perturbations to map design choices to hallucination behaviors. Experiments across 7 design aspects conclude that parameter scaling has limited impact on all three hallucination types, larger/better-trained LFs reduce co-occurrence hallucinations, stronger visual encoders and higher resolutions mitigate similarity errors, effective alignment strategies alleviate uncertainty hallucinations, and jointly enhancing VR and SA yields the most comprehensive improvements. The work positions itself as the first systematic exploration linking architecture-level design to hallucination robustness.
Significance. If the isolation of effects holds, the result would be significant for the field: it supplies the first explicit mapping from the three architectural dimensions to distinct hallucination types and offers concrete, actionable guidance on design choices (e.g., prioritizing visual fidelity plus alignment over raw parameter scaling). The CoSimUE benchmark and the three-way hallucination taxonomy are reusable contributions that could shape subsequent LVLM robustness studies.
major comments (2)
- [Abstract / experimental results section] Abstract and experimental results section: the headline attributions (larger LF reduces co-occurrence hallucinations; stronger VR mitigates similarity errors; effective SA alleviates uncertainty hallucinations) rest on the premise that the 7 design aspects and CoSimUE perturbations cleanly vary only the targeted factor. The manuscript provides no details on model selection criteria, statistical tests, controls for training-data or optimization confounds, or exact perturbation implementations, leaving open the possibility that observed differences arise from correlated model differences rather than the claimed architectural dimensions.
- [CoSimUE benchmark description (likely §3)] CoSimUE benchmark description (likely §3): the controlled textual and random perturbations are asserted to isolate LF/VR/SA effects on the three hallucination types. Because publicly available LVLMs differ simultaneously in multiple components, training corpora, and optimization procedures, residual correlations may remain; without explicit ablation or sensitivity analysis showing that perturbation artifacts do not introduce new failure modes absent from natural inputs, the mapping from design dimension to hallucination type is not yet load-bearing.
minor comments (1)
- [Introduction / taxonomy section] The three hallucination categories are introduced without a formal definition or illustrative examples in the abstract; a short table or figure in the main text would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments below by clarifying our experimental controls and committing to additions that strengthen the isolation of effects.
read point-by-point responses
-
Referee: [Abstract / experimental results section] Abstract and experimental results section: the headline attributions (larger LF reduces co-occurrence hallucinations; stronger VR mitigates similarity errors; effective SA alleviates uncertainty hallucinations) rest on the premise that the 7 design aspects and CoSimUE perturbations cleanly vary only the targeted factor. The manuscript provides no details on model selection criteria, statistical tests, controls for training-data or optimization confounds, or exact perturbation implementations, leaving open the possibility that observed differences arise from correlated model differences rather than the claimed architectural dimensions.
Authors: We agree that the manuscript would benefit from greater transparency on these points. In the revision we will add a new subsection detailing model selection criteria, including the specific checkpoints chosen to hold VR and SA fixed while varying LF (and analogously for the other dimensions). We will also report statistical tests (paired t-tests and effect sizes) for all headline comparisons. On training-data and optimization confounds, we will explicitly discuss that the selected public models share comparable pre-training corpora and that we controlled for parameter count where possible; any residual correlations will be acknowledged as a limitation. Exact perturbation code and hyper-parameters will be moved to the appendix with pseudocode. revision: yes
-
Referee: [CoSimUE benchmark description (likely §3)] CoSimUE benchmark description (likely §3): the controlled textual and random perturbations are asserted to isolate LF/VR/SA effects on the three hallucination types. Because publicly available LVLMs differ simultaneously in multiple components, training corpora, and optimization procedures, residual correlations may remain; without explicit ablation or sensitivity analysis showing that perturbation artifacts do not introduce new failure modes absent from natural inputs, the mapping from design dimension to hallucination type is not yet load-bearing.
Authors: We acknowledge the difficulty of perfect isolation with public checkpoints. In the revision we will insert an ablation subsection that (i) compares CoSimUE outputs against unmodified natural-image captions to quantify any introduced failure modes and (ii) performs sensitivity sweeps over perturbation strength. These analyses will be used to argue that the observed mappings are not artifacts of the benchmark construction. While we cannot retroactively retrain models to eliminate all correlations, the added controls and ablations will make the current evidence load-bearing. revision: yes
Circularity Check
No circularity: empirical benchmarking of existing models
full rationale
This is a purely empirical study that selects publicly available LVLMs, varies their architectural dimensions (LF, VR, SA) via existing checkpoints, applies the CoSimUE benchmark, and reports observed differences in hallucination rates. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the load-bearing claims. The mapping from design choices to hallucination types rests on experimental variation rather than any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LVLMs can be factored into Linguistic Foundation (LF), Visual Representation (VR), and Semantic Alignment (SA) dimensions.
- domain assumption Hallucinations in LVLMs fall into Co-occurrence, Similarity, and Uncertainty types.
invented entities (1)
-
CoSimUE benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Unveiling hallucination in text, image, video, and audio foundation models: A comprehensive survey,
P. Sahoo, P. Meharia, A. Ghosh, S. Saha, V . Jain, and A. Chadha, “Unveiling hallucination in text, image, video, and audio foundation models: A comprehensive survey,”CoRR, vol. abs/2405.09589, 2024
-
[2]
Palm: Scal- ing language modeling with pathways,
A. Chowdhery, S. Narang, J. Devlin, M. Bosma, G. Mishra, A. Roberts, P. Barham, H. W. Chung, C. Sutton, S. Gehrmannet al., “Palm: Scal- ing language modeling with pathways,”Journal of Machine Learning Research, pp. 1–113, 2023
2023
-
[3]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Language mod- els are few-shot learners,
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language mod- els are few-shot learners,”Advances in neural information processing systems, vol. 33, pp. 1877–1901, 2020
1901
-
[5]
Visual instruction tuning,
H. Liu, C. Li, Q. Wu, and Y . J. Lee, “Visual instruction tuning,” Advances in neural information processing systems, vol. 36, pp. 34 892– 34 916, 2023
2023
-
[6]
Llava-next: Improved reasoning, ocr, and world knowledge,
H. Liu, C. Li, Y . Li, B. Li, Y . Zhang, S. Shen, and Y . J. Lee, “Llava-next: Improved reasoning, ocr, and world knowledge,” January 2024
2024
-
[7]
BLIP-2: bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “BLIP-2: bootstrapping language- image pre-training with frozen image encoders and large language models,” inICML, 2023
2023
-
[8]
Instructblip: Towards general-purpose vision- language models with instruction tuning,
W. Dai, J. Li, D. Li, A. M. H. Tiong, J. Zhao, W. Wang, B. Li, P. Fung, and S. Hoi, “Instructblip: Towards general-purpose vision- language models with instruction tuning,” 2023
2023
-
[9]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, S. Bai, S. Yang, S. Wang, S. Tan, P. Wang, J. Lin, C. Zhou, and J. Zhou, “Qwen-vl: A versatile vision-language model for un- derstanding, localization, text reading, and beyond,”arXiv preprint arXiv:2308.12966, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,”arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Minigpt-5: Interleaved vision-and- language generation via generative vokens,
K. Zheng, X. He, and X. E. Wang, “Minigpt-5: Interleaved vision-and- language generation via generative vokens,” 2023
2023
-
[12]
mplug-owl: Modularization empowers large language models with multimodality,
Q. Ye, H. Xu, G. Xu, J. Ye, M. Yan, Y . Zhou, J. Wang, A. Hu, P. Shi, Y . Shi, C. Jiang, C. Li, Y . Xu, H. Chen, J. Tian, Q. Qi, J. Zhang, and F. Huang, “mplug-owl: Modularization empowers large language models with multimodality,” 2023
2023
-
[13]
mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration,
Q. Ye, H. Xu, J. Ye, M. Yan, A. Hu, H. Liu, Q. Qian, J. Zhang, F. Huang, and J. Zhou, “mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration,” 2023
2023
-
[14]
mplug-owl3: Towards long image-sequence understanding in multi-modal large language models,
J. Ye, H. Xu, H. Liu, A. Hu, M. Yan, Q. Qian, J. Zhang, F. Huang, and J. Zhou, “mplug-owl3: Towards long image-sequence understanding in multi-modal large language models,” 2024
2024
-
[15]
Q. Team, “Qwen3 technical report,”arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Introducing gpt-5,
OpenAI, “Introducing gpt-5,” 2025
2025
-
[17]
Introducing claude sonnet 4.5,
anthropic Team, “Introducing claude sonnet 4.5,” 2025
2025
-
[18]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,
G. Gemini Team, “Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities,” 2025
2025
-
[19]
Glm-4.5: Agentic, reasoning, and coding (arc) foundation models,
G.-. Team, “Glm-4.5: Agentic, reasoning, and coding (arc) foundation models,” 2025
2025
-
[20]
Nullu: Mitigating object hallucinations in large vision-language models via halluspace projection,
L. Yang, Z. Zheng, B. Chen, Z. Zhao, C. Lin, and C. Shen, “Nullu: Mitigating object hallucinations in large vision-language models via halluspace projection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 14 635–14 645
2025
-
[21]
Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection- allocation,
Q. Huang, X. Dong, P. Zhang, B. Wang, C. He, J. Wang, D. Lin, W. Zhang, and N. Yu, “Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection- allocation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2024, pp. 13 418–13 427
2024
-
[22]
W. An, F. Tian, S. Leng, J. Nie, H. Lin, Q. Wang, G. Dai, P. Chen, and S. Lu, “Agla: Mitigating object hallucinations in large vision-language models with assembly of global and local attention,”arXiv preprint arXiv:2406.12718, 2024
-
[23]
R. S. Pressman,Software engineering: a practitioner’s approach. Pal- grave macmillan, 2005
2005
-
[24]
A review on large language models: Architectures, applications, taxonomies, open issues and challenges,
M. A. K. Raiaan, M. S. H. Mukta, K. Fatema, N. M. Fahad, S. Sakib, M. M. J. Mim, J. Ahmad, M. E. Ali, and S. Azam, “A review on large language models: Architectures, applications, taxonomies, open issues and challenges,”IEEE access, vol. 12, pp. 26 839–26 874, 2024
2024
-
[25]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[26]
Vision-language models for vision tasks: A survey,
J. Zhang, J. Huang, S. Jin, and S. Lu, “Vision-language models for vision tasks: A survey,”IEEE transactions on pattern analysis and machine intelligence, pp. 5625–5644, 2024
2024
-
[27]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 26 296–26 306
2024
-
[28]
S. Leng, H. Zhang, G. Chen, X. Li, S. Lu, C. Miao, and L. Bing, “Mit- igating object hallucinations in large vision-language models through visual contrastive decoding,”arXiv preprint arXiv:2311.16922, 2023
-
[29]
Why language models hallucinate,
A. T. Kalai, O. Nachum, S. S. Vempala, and E. Zhang, “Why language models hallucinate,” 2025
2025
-
[30]
Analyzing and mitigating object hallucination in large vision- language models,
Y . Zhou, C. Cui, J. Yoon, L. Zhang, Z. Deng, C. Finn, M. Bansal, and H. Yao, “Analyzing and mitigating object hallucination in large vision- language models,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[31]
Evaluating object hallucination in large vision-language models,
Y . Li, Y . Du, K. Zhou, J. Wang, W. X. Zhao, and J.-R. Wen, “Evaluating object hallucination in large vision-language models,” 2023
2023
-
[32]
Detecting and preventing hallucinations in large vision language models,
A. Gunjal, J. Yin, and E. Bas, “Detecting and preventing hallucinations in large vision language models,” inProceedings of the AAAI Conference on Artificial Intelligence, 2024, pp. 18 135–18 143
2024
-
[33]
Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data,
Q. Yu, J. Li, L. Wei, L. Pang, W. Ye, B. Qin, S. Tang, Q. Tian, and Y . Zhuang, “Hallucidoctor: Mitigating hallucinatory toxicity in visual instruction data,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 12 944–12 953
2024
-
[34]
Mitigating object hallucination in large vision-language models via image-grounded guidance,
L. Zhao, Y . Deng, W. Zhang, and Q. Gu, “Mitigating object hallucination in large vision-language models via image-grounded guidance,”arXiv preprint arXiv:2402.08680, 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 11
-
[35]
Eyes wide shut? exploring the visual shortcomings of multimodal llms,
S. Tong, Z. Liu, Y . Zhai, Y . Ma, Y . LeCun, and S. Xie, “Eyes wide shut? exploring the visual shortcomings of multimodal llms,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9568–9578
2024
-
[36]
Why Language Models Hallucinate
A. T. Kalai, O. Nachum, S. S. Vempala, and E. Zhang, “Why language models hallucinate,”arXiv preprint arXiv:2509.04664, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Estimating the hallucination rate of generative ai,
A. Jesson, N. Beltran-Velez, Q. Chu, S. Karlekar, J. Kossen, Y . Gal, J. P. Cunningham, and D. Blei, “Estimating the hallucination rate of generative ai,”Advances in Neural Information Processing Systems, vol. 37, pp. 31 154–31 201, 2024
2024
-
[38]
Deep compositional captioning: Describing novel object categories without paired training data,
L. A. Hendricks, S. Venugopalan, M. Rohrbach, R. Mooney, K. Saenko, and T. Darrell, “Deep compositional captioning: Describing novel object categories without paired training data,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1–10
2016
-
[39]
Object Hallucination in Image Captioning
A. Rohrbach, L. A. Hendricks, K. Burns, T. Darrell, and K. Saenko, “Object hallucination in image captioning,”arXiv preprint arXiv:1809.02156, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[40]
Mme: A comprehensive evaluation benchmark for multimodal large language models,
C. Fu, P. Chen, Y . Shen, Y . Qin, M. Zhang, X. Lin, J. Yang, X. Zheng, K. Li, X. Sun, Y . Wu, and R. Ji, “Mme: A comprehensive evaluation benchmark for multimodal large language models,” 2024
2024
-
[41]
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning
F. Liu, K. Lin, L. Li, J. Wang, Y . Yacoob, and L. Wang, “Mitigating hallucination in large multi-modal models via robust instruction tuning,” arXiv preprint arXiv:2306.14565, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Visual hallucinations of multi-modal large language models,
W. Huang, H. Liu, M. Guo, and N. Z. Gong, “Visual hallucinations of multi-modal large language models,”arXiv preprint arXiv:2402.14683, 2024
-
[43]
Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models,
T. Guan, F. Liu, X. Wu, R. Xian, Z. Li, X. Liu, X. Wang, L. Chen, F. Huang, Y . Yacoobet al., “Hallusionbench: an advanced diagnostic suite for entangled language hallucination and visual illusion in large vision-language models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 14 375–14 385
2024
-
[44]
Autohallusion: Automatic generation of hallucination benchmarks for vision-language models,
X. Wu, T. Guan, D. Li, S. Huang, X. Liu, X. Wang, R. Xian, A. Shrivastava, F. Huang, J. L. Boyd-Graber, T. Zhou, and D. Manocha, “Autohallusion: Automatic generation of hallucination benchmarks for vision-language models,” 2024
2024
-
[45]
Holistic analysis of hallucination in gpt-4v (ision): Bias and interference chal- lenges,
C. Cui, Y . Zhou, X. Yang, S. Wu, L. Zhang, J. Zou, and H. Yao, “Holistic analysis of hallucination in gpt-4v (ision): Bias and interference chal- lenges,”arXiv preprint arXiv:2311.03287, 2023
-
[46]
Microsoft coco: Common objects in con- text,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll´ar, and C. L. Zitnick, “Microsoft coco: Common objects in con- text,” inComputer Vision – ECCV 2014, D. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, Eds. Cham: Springer International Publishing, 2014, pp. 740–755
2014
-
[47]
B. F. Labs, “Flux,” 2024
2024
-
[48]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[49]
Judging llm-as-a-judge with mt-bench and chatbot arena,
L. Zheng, W.-L. Chiang, Y . Sheng, S. Zhuang, Z. Wu, Y . Zhuang, Z. Lin, Z. Li, D. Li, E. Xinget al., “Judging llm-as-a-judge with mt-bench and chatbot arena,”Advances in neural information processing systems, vol. 36, pp. 46 595–46 623, 2023
2023
-
[50]
A. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. Chaplot, D. de Las Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnieret al., “Mistral 7b. corr, abs/2310.06825, 2023. doi: 10.48550,”arXiv preprint ARXIV .2310.06825, vol. 10, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.