TUX: Measuring Human--AI Tacit Understanding
Pith reviewed 2026-06-28 21:16 UTC · model grok-4.3
The pith
Human-AI pairs nearest in trait space achieve significantly higher tacit understanding on independent spectrum placements.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
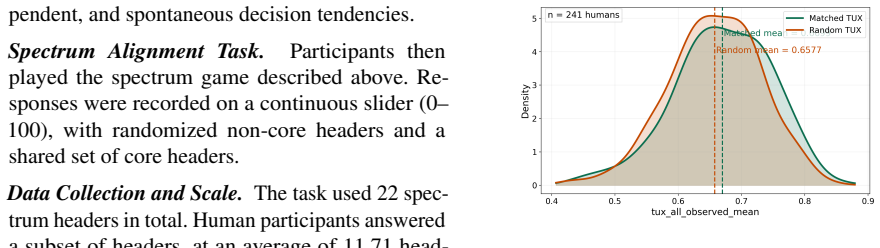
We operationalize tacit understanding as pairwise similarity in human and agent judgments on a spectrum-placement task performed without objectives, communication, or feedback. The resulting TUX measure is significantly higher for human-agent pairs nearest in trait space. Richer predictor sets that include individual traits, decision-making styles, and confidence explain more variance in TUX than baseline trait-distance models, while profile conditioning alone shows limits in capturing deeper representational alignment.
What carries the argument
The Tacit Understanding Index (TUX), computed as pairwise similarity between independent human and LLM placements of concepts along subjective spectra.
If this is right
- Tacit alignment between humans and LLMs is organized by person-level characteristics instead of random similarity.
- Richer sets of individual predictors improve explanation of TUX beyond aggregate trait distance.
- Profile conditioning on LLMs reaches limits in producing deeper representational alignment.
- TUX rises as matching incorporates traits, decision styles, and confidence.
Where Pith is reading between the lines
- Matching agents to humans on detailed trait profiles could raise tacit alignment in collaborative settings.
- The spectrum task might be adapted to measure unspoken alignment in creative or decision-making domains.
- Alternative conditioning methods beyond static profiles could be tested to close the observed gaps in TUX.
Load-bearing premise
The spectrum-placement task validly captures tacit understanding through similarity of judgments made without clear objectives, communication, or feedback.
What would settle it
Finding no reliable TUX advantage for nearest-trait human-agent pairs compared with random or distant pairs would falsify the claim that tacit alignment is structured by person-level traits.
Figures


read the original abstract
As large language models (LLMs) increasingly act as collaborative partners, human--AI alignment is often evaluated through explicit task success, accuracy, or reward optimization. Yet many collaborative settings depend on tacit understanding: whether an agent can align with a human's evaluative stance or representational priors without clear objectives, communication, or feedback. To study this capacity, we develop a spectrum-placement task inspired by the social party game Wavelength, in which humans and agents independently place concepts along subjective spectra. We operationalize the Tacit Understanding Index (TUX) as a pairwise measure of similarity between human and agent judgments, and evaluate it with 241 human participants and 200 profile-conditioned LLM agents across four models. We find that nearest human--agent pairs in trait space achieve significantly higher TUX, suggesting that tacit alignment is structured by person-level characteristics rather than random similarity. Regression analyses show that TUX becomes more explainable as predictor sets become richer, with individual traits, decision-making styles, and confidence improving over aggregate trait-distance baselines. These findings suggest that tacit understanding between humans and LLMs is measurable, while revealing the limits of profile-based conditioning for capturing deeper representational alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Tacit Understanding Index (TUX) as a pairwise similarity metric derived from independent concept placements on subjective spectra in a task inspired by the game Wavelength. With 241 human participants and 200 profile-conditioned LLM agents across four models, it reports that human-agent pairs nearest in trait space achieve significantly higher TUX, indicating that tacit alignment is structured by person-level traits rather than random similarity. Regression analyses further show that TUX becomes more explainable with richer predictor sets (individual traits, decision-making styles, and confidence) over aggregate trait-distance baselines.
Significance. If the results hold, the work supplies a concrete empirical proxy for tacit understanding in human-AI collaboration, showing that individual characteristics shape alignment beyond chance. The study scale (241 humans, 200 agents) and the demonstration that richer predictors improve regression fits constitute clear strengths, offering a foundation for more personalized LLM conditioning. The explicit framing of the task as a proxy and the acknowledgment of profile-conditioning limits add to its utility for the field.
major comments (1)
- [Abstract] Abstract: The claim of 'statistically significant differences' in TUX for nearest trait-space pairs provides no information on the exact statistical tests used, multiple-comparison corrections, data exclusion rules, or error bars/effect sizes. This information is load-bearing for evaluating the central empirical result.
Simulated Author's Rebuttal
We thank the referee for their careful review and for identifying the need for greater statistical transparency in the abstract. We address the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim of 'statistically significant differences' in TUX for nearest trait-space pairs provides no information on the exact statistical tests used, multiple-comparison corrections, data exclusion rules, or error bars/effect sizes. This information is load-bearing for evaluating the central empirical result.
Authors: We agree that the abstract's summary claim would be strengthened by explicit statistical details. The full manuscript describes the tests, corrections, exclusion criteria, and effect sizes in the Methods and Results sections. To make the abstract more self-contained while respecting length constraints, we will revise it in the next version to include a concise statement of the primary test, correction method, and effect size range. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper explicitly defines TUX as a pairwise similarity metric on the spectrum-placement task and then reports an empirical observation that nearest trait-space pairs show higher TUX values. This is a statistical comparison of measured quantities, not a quantity forced by the paper's own equations, fitted parameters, or self-citation chains. No load-bearing derivation reduces to its inputs by construction; the central claim remains an independent empirical result against the defined operationalization.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Tacit understanding can be operationalized as pairwise similarity between independent human and agent placements on subjective spectra without explicit objectives or feedback.
invented entities (1)
-
TUX (Tacit Understanding Index)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Elisa C. Baek and Carolyn Parkinson. 2022. https://doi.org/10.1111/spc3.12710 Shared understanding and social connection: Integrating approaches from social psychology, social network analysis, and neuroscience . Social and Personality Psychology Compass, 16(11):e12710
-
[2]
Gagan Bansal, Besmira Nushi, Ece Kamar, Walter S Lasecki, Daniel S Weld, and Eric Horvitz. 2019. Beyond accuracy: The role of mental models in human-ai team performance. In Proceedings of the AAAI conference on human computation and crowdsourcing, volume 7, pages 2--11
2019
-
[3]
Arnaud Carr \'e , Nicolas Stefaniak, Fanny D'Ambrosio, Le \" la Bensalah, and Chrystel Besche-Richard. 2013. https://doi.org/10.1037/a0032297 The basic empathy scale in adults (bes-a): Factor structure of a revised form . Psychological Assessment, 25(3):679--691
-
[4]
Jiangjie Chen, Xintao Wang, Rui Xu, Siyu Yuan, Yikai Zhang, Wei Shi, Jian Xie, Shuang Li, Ruihan Yang, Tinghui Zhu, Aili Chen, Nianqi Li, Lida Chen, Caiyu Hu, Siye Wu, Scott Ren, Ziquan Fu, and Yanghua Xiao. 2024. https://doi.org/10.48550/arXiv.2404.18231 From persona to personalization: A survey on role-playing language agents . arXiv preprint arXiv:2404.18231
-
[5]
Christiano, Jan Leike, Tom B
Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems, volume 30
2017
-
[6]
URL https://doi.org/10.1037/10096-006
Herbert H. Clark and Susan E. Brennan. 1991. https://doi.org/10.1037/10096-006 Grounding in communication . In Lauren B. Resnick, John M. Levine, and Stephanie D. Teasley, editors, Perspectives on Socially Shared Cognition, pages 127--149. American Psychological Association
-
[7]
P.L. Curseu, R.J.G. Jansen, and M.M.H. Chappin. 2013. https://doi.org/10.1371/journal.pone.0056454 Decision rules and group rationality: Cognitive gain or standstill? PLOS ONE, 8(2):e56454
-
[8]
Vedant Das Swain and Koustuv Saha. 2024. Teacher, trainer, counsel, spy: how generative ai can bridge or widen the gaps in worker-centric digital phenotyping of wellbeing. In Proceedings of the 3rd Annual Meeting of the Symposium on Human-Computer Interaction for Work, pages 1--13
2024
-
[9]
Vedant Das Swain, Qiuyue" Joy" Zhong, Jash Rajesh Parekh, Yechan Jeon, Roy Zimmermann, Mary P Czerwinski, Jina Suh, Varun Mishra, Koustuv Saha, and Javier Hernandez. 2025. Ai on my shoulder: Supporting emotional labor in front-office roles with an llm-based empathetic coworker. In Proceedings of the 2025 CHI Conference on Human Factors in Computing System...
2025
-
[10]
Xiaoqi Deng, Sarinasadat Hosseini, Yoshihiro Miyake, and Takayuki Nozawa. 2024. https://doi.org/10.3390/bs14110987 Cooperativeness as a personality trait and its impact on cooperative behavior in young east asian adults who synchronized in casual conversations . Behavioral Sciences, 14(11):987
-
[11]
Weihua Du, Qiushi Lyu, Jiaming Shan, Zhenting Qi, Hongxin Zhang, Sunli Chen, Andi Peng, Tianmin Shu, Kwonjoon Lee, Behzad Dariush, and Chuang Gan. 2024. Constrained human-ai cooperation: An inclusive embodied social intelligence challenge. In Advances in Neural Information Processing Systems, volume 37
2024
-
[12]
Veda Duddu, Jash Rajesh Parekh, Andy Mao, Hanyi Min, Ziang Xiao, Vedant Das Swain, and Koustuv Saha. 2026. Not my truce: Personality differences in ai-mediated workplace negotiation. arXiv preprint arXiv:2604.00464
arXiv 2026
-
[13]
Quentin Ehkirch and Akane Matsumae. 2024. https://doi.org/10.1017/dsj.2024.1 Understanding the influence of interpersonal factors on interactions in co-design through intersubjectivity: A systematic literature review . Design Science, 10:e4
-
[14]
George Fragiadakis, Christos Diou, George Kousiouris, and Mara Nikolaidou. 2024. Evaluating human-ai collaboration: A review and methodological framework. arXiv preprint arXiv:2407.19098
arXiv 2024
-
[15]
Shane Frederick. 2005. https://doi.org/10.1257/089533005775196732 Cognitive reflection and decision making . Journal of Economic Perspectives, 19(4):25--42
-
[16]
Tory Higgins, Maya Rossignac-Milon, and Gerald Echterhoff
E. Tory Higgins, Maya Rossignac-Milon, and Gerald Echterhoff. 2021. https://doi.org/10.1177/0963721421992027 Shared reality: From sharing-is-believing to merging minds . Current Directions in Psychological Science, 30(2):103--110
-
[17]
John and Sanjay Srivastava
Oliver P. John and Sanjay Srivastava. 1999. The big five trait taxonomy: History, measurement, and theoretical perspectives. In Lawrence A. Pervin and Oliver P. John, editors, Handbook of Personality: Theory and Research, 2 edition, pages 102--138. Guilford Press
1999
-
[18]
Daniel N. Jones and Delroy L. Paulhus. 2014. https://doi.org/10.1177/1073191113514105 Introducing the short dark triad (sd3): A brief measure of dark personality traits . Assessment, 21(1):28--41
-
[19]
Kahan, Hank Jenkins-Smith, and Donald Braman
Dan M. Kahan, Hank Jenkins-Smith, and Donald Braman. 2011. https://doi.org/10.1080/13669877.2010.511246 Cultural cognition of scientific consensus . Journal of Risk Research, 14(2):147--174
-
[20]
Susan L. Kichuk and Willi H. Wiesner. 1997. https://doi.org/10.1016/S0923-4748(97)00010-6 The big five personality factors and team performance: Implications for selecting successful product design teams . Journal of Engineering and Technology Management, 14(3--4):195--221
-
[21]
Jiwon Kim, Violeta J Rodriguez, Dong Whi Yoo, Eshwar Chandrasekharan, and Koustuv Saha. 2026. Pair-safe: A paired-agent approach for runtime auditing and refining ai-mediated mental health support. arXiv preprint arXiv:2601.12754
arXiv 2026
-
[22]
Sangwook Lee, Adnan Abbas, Yan Chen, Young-Ho Kim, and Sang Won Lee. 2026. Choir: A chatbot-mediated organizational memory leveraging communication in university research labs. In Proceedings of the 2026 CHI Conference on Human Factors in Computing Systems, pages 1--23
2026
-
[23]
Shunyu Liu, Wenkai Fang, Zetian Hu, Junjie Zhang, Yang Zhou, Kongcheng Zhang, Rongcheng Tu, Ting-En Lin, Fei Huang, Mingli Song, Yongbin Li, and Dacheng Tao. 2025. https://doi.org/10.48550/arXiv.2503.11701 A survey of direct preference optimization . arXiv preprint arXiv:2503.11701
-
[24]
Jennifer Lynch, Alexander McGregor, and Alex J. Benson. 2022. https://doi.org/10.1177/13684302211001944 My way or the highway: Narcissism and dysfunctional team conflict processes . Group Processes & Intergroup Relations, 25(4):1157--1171
-
[25]
Amogh Mannekote, Adam Davies, Guohao Li, Kristy Elizabeth Boyer, ChengXiang Zhai, Bonnie J. Dorr, and Francesco Pinto. 2025. https://doi.org/10.48550/arXiv.2507.02197 Do role-playing agents practice what they preach? belief-behavior consistency in llm-based simulations of human trust . arXiv preprint arXiv:2507.02197
-
[26]
Katelyn Morrison, Zahra Ashktorab, Gabriel Enrique Gonzalez, Djallel Bouneffouf, and Justin Weisz. 2025. Establishing the cooperative game wavelength as a testbed to explore mutual theory of mind. In Proceedings of the Workshop on Advancing AI Through Theory of Mind at AAAI 2025
2025
-
[27]
Sheshera Mysore, Debarati Das, Hancheng Cao, and Bahareh Sarrafzadeh. 2025. Prototypical human-ai collaboration behaviors from llm-assisted writing in the wild. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 16830--16857
2025
-
[28]
Rosemary Pacini and Seymour Epstein. 1999. https://doi.org/10.1037/0022-3514.76.6.972 The relation of rational and experiential information processing styles to personality, basic beliefs, and the ratio-bias phenomenon . Journal of Personality and Social Psychology, 76(6):972--987
-
[29]
URLhttps://doi.org/10.1145/3586183.3606763
Joon Sung Park, Joseph C. O'Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. https://doi.org/10.1145/3586183.3606763 Generative agents: Interactive simulacra of human behavior . In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1--22
-
[30]
Joon Sung Park, Carolyn Q. Zou, Jonne Kamphorst, Niles Egan, Aaron Shaw, Benjamin Mako Hill, Carrie Cai, Meredith Ringel Morris, Percy Liang, Robb Willer, and Michael S. Bernstein. 2026. https://arxiv.org/abs/2411.10109 Llm agents grounded in self-reports enable general-purpose simulation of individuals . Preprint, arXiv:2411.10109
Pith/arXiv arXiv 2026
-
[31]
Miranda A.G. Peeters, Harrie F.J.M. van Tuijl, Christel G. Rutte, and Isabelle Reymen. 2006. https://doi.org/10.1002/per.588 Personality and team performance: a meta analysis . European Journal of Personality, 20(5):377--396
-
[32]
Yifu Qiu, Zheng Zhao, Yftah Ziser, Anna Korhonen, Edoardo M Ponti, and Shay B Cohen. 2024. Spectral editing of activations for large language model alignment. Advances in Neural Information Processing Systems, 37:56958--56987
2024
-
[33]
Manning, and Chelsea Finn
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. In Advances in Neural Information Processing Systems, volume 36, pages 53728--53741
2023
-
[34]
Beatrice Rammstedt and Oliver P. John. 2007. https://doi.org/10.1016/j.jrp.2006.02.001 Measuring personality in one minute or less: A 10-item short version of the big five inventory in english and german . Journal of Research in Personality, 41(1):203--212
-
[35]
Schelling
Thomas C. Schelling. 1960. The Strategy of Conflict. Harvard University Press
1960
-
[36]
Schmutz, Neal Outland, Sophie Kerstan, Eleni Georganta, and Anna-Sophie Ulfert
Jan B. Schmutz, Neal Outland, Sophie Kerstan, Eleni Georganta, and Anna-Sophie Ulfert. 2024. https://doi.org/10.1016/j.copsyc.2024.101837 Ai-teaming: Redefining collaboration in the digital era . Current Opinion in Psychology, 58:101837
-
[37]
Susanne G. Scott and Reginald A. Bruce. 1995. https://doi.org/10.1177/0013164495055005017 Decision-making style: The development and assessment of a new measure . Educational and Psychological Measurement, 55(5):818--831
-
[38]
Julian Senoner, Simon Schallmoser, Bernhard Kratzwald, Stefan Feuerriegel, and Torbj rn Netland. 2024. Explainable ai improves task performance in human--ai collaboration. Scientific reports, 14(1):31150
2024
-
[39]
Soorya Ram Shimgekar, Vipin Gunda, Jiwon Kim, Violeta J Rodriguez, Hari Sundaram, and Koustuv Saha. 2026. Ai psychosis: Does conversational ai amplify delusion-related language? arXiv preprint arXiv:2603.19574
arXiv 2026
-
[40]
Matthew Sidji, Wally Smith, and Melissa J. Rogerson. 2024. https://doi.org/10.1145/3677081 Human-ai collaboration in cooperative games: A study of playing codenames with an llm assistant . Proceedings of the ACM on Human-Computer Interaction, 8(CHI PLAY):1--25
-
[41]
Chandler Smith, Marwa Abdulhai, Manfred Diaz, Marko Tesic, Rakshit Trivedi, Sasha Vezhnevets, Lewis Hammond, Jesse Clifton, Minsuk Chang, Edgar Duenez-Guzman, and 1 others. 2026. Evaluating generalization capabilities of llm-based agents in mixed-motive scenarios using concordia. Advances in neural information processing systems, 38
2026
-
[42]
Kihoon Son, DaEun Choi, Tae Soo Kim, and Juho Kim. 2024. Demystifying tacit knowledge in graphic design: Characteristics, instances, approaches, and guidelines. In Proceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1--18
2024
-
[43]
Yu-Min Tseng, Yu-Chao Huang, Teng-Yun Hsiao, Wei-Lin Chen, Chao-Wei Huang, Yu Meng, and Yun-Nung Chen. 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.969 Two tales of persona in llms: A survey of role-playing and personalization . In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 16525--16548
-
[44]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Juan J. Vazquez, Ulisse Mini, and Monte MacDiarmid. 2023. https://doi.org/10.48550/arXiv.2308.10248 Steering language models with activation engineering . arXiv preprint arXiv:2308.10248
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.10248 2023
-
[45]
Gaofeng Wang and Weiwei Hu. 2021. Peer relationships and college students’ cooperative tendencies: Roles of interpersonal trust and social value orientation. Frontiers in Psychology, 12:656412
2021
-
[46]
Qiaosi Wang, Koustuv Saha, Eric Gregori, David Joyner, and Ashok Goel. 2021. Towards mutual theory of mind in human-ai interaction: How language reflects what students perceive about a virtual teaching assistant. In Proceedings of the 2021 CHI conference on human factors in computing systems, pages 1--14
2021
-
[47]
Stanis aw Wo \'z niak, Bart omiej Koptyra, Arkadiusz Janz, Przemys aw Kazienko, and Jan Koco \'n . 2024. Personalized large language models. In 2024 IEEE International Conference on Data Mining Workshops (ICDMW), pages 511--520. IEEE
2024
-
[48]
Guande Wu, Chen Zhao, Claudio Silva, and He He. 2024. Your co-workers matter: Evaluating collaborative capabilities of language models in blocks world. In Findings of the Association for Computational Linguistics: ACL 2024, pages 4941--4957
2024
-
[49]
Jianzhu Yao, Kevin Wang, Ryan Hsieh, Haisu Zhou, Tianqing Zou, Zerui Cheng, Zhangyang Wang, and Pramod Viswanath. 2025. https://doi.org/10.48550/arXiv.2503.12349 Spin-bench: How well do llms plan strategically and reason socially? arXiv preprint arXiv:2503.12349
-
[50]
Dora Zhao, Diyi Yang, and Michael S Bernstein. 2025. Knoll: Creating a knowledge ecosystem for large language models. In Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology, pages 1--23
2025
-
[51]
Huiqi Zou, Pengda Wang, Zihan Yan, Tianjun Sun, and Ziang Xiao. 2025. https://openreview.net/forum?id=xqIwK9mNkj Can LLM ''self-report''?: Evaluating the validity of self-report scales in measuring personality design in LLM -based chatbots . In Second Conference on Language Modeling
2025
-
[52]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[53]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.