PithTrain: A Compact and Agent-Native MoE Training System
Pith reviewed 2026-06-28 23:10 UTC · model grok-4.3
The pith
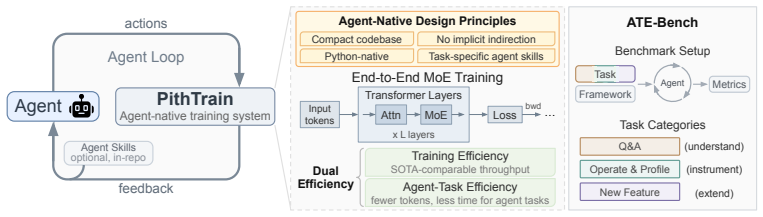
A compact MoE training system matches production throughput while requiring far fewer steps from coding agents to modify it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
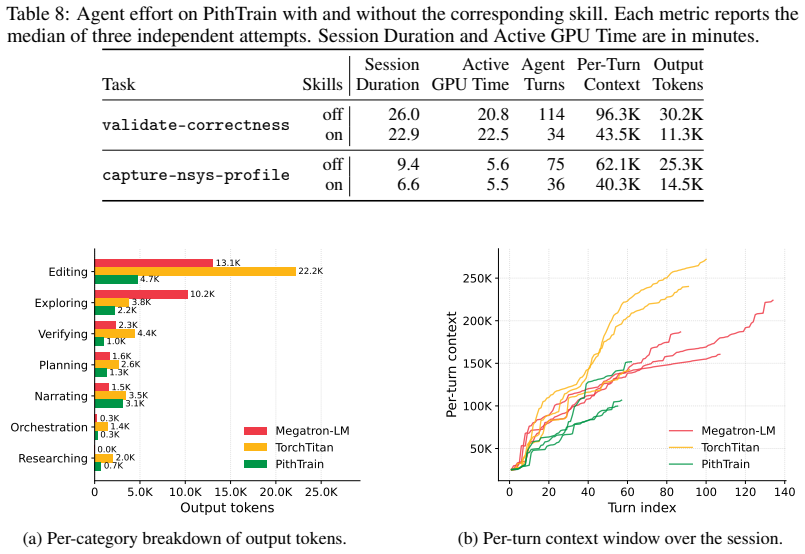
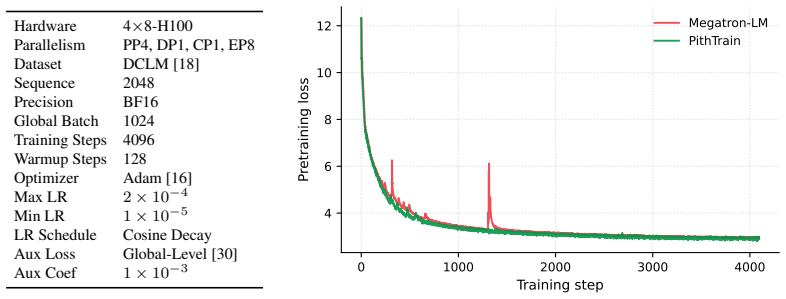
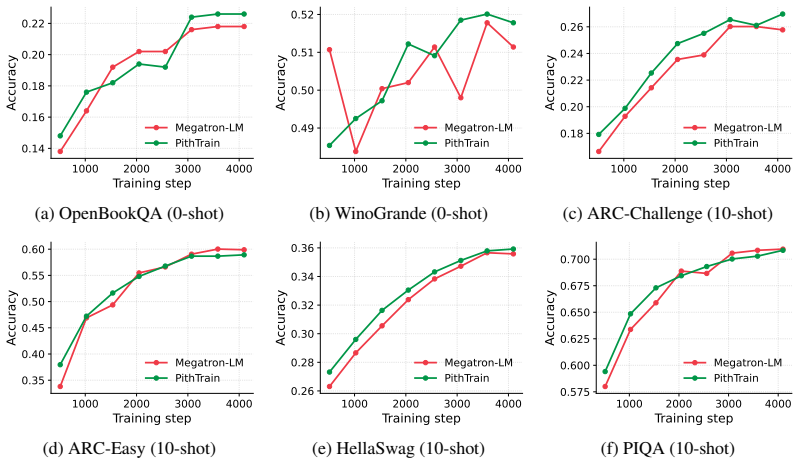
PithTrain, a compact MoE training framework grounded in four agent-native design principles, achieves throughput comparable to production frameworks while enabling higher agent-task efficiency on ATE-Bench, with up to 62% fewer Agent Turns and 64% less Active GPU Time.
What carries the argument
Agent-task efficiency (ATE), the measured cost in agent turns and active GPU time for coding agents to understand, operate, and extend a training framework.
If this is right
- MoE training frameworks can be made both high-throughput and low-cost for agent-driven changes at the same time.
- ATE-Bench supplies a concrete way to quantify and compare the agent usability of different training systems.
- Future framework development can treat agent-native design as a first-class requirement alongside raw speed.
- The gap between current production stacks and agent-friendly ones can be closed without sacrificing performance.
Where Pith is reading between the lines
- If ATE becomes a standard metric, framework authors may shift design priorities toward smaller codebases and clearer interfaces even before agent usage is widespread.
- The same principles used in PithTrain could be applied to other systems such as inference engines or data pipelines where agents are expected to perform maintenance.
- Wider adoption might reduce the engineering effort needed to test new MoE variants or hardware-specific optimizations.
Load-bearing premise
The four agent-native design principles are the main reason for the measured gains in agent-task efficiency, and the tasks in ATE-Bench represent the kind of work agents will actually do on training frameworks.
What would settle it
Running the identical ATE-Bench tasks with the same agents on a production framework such as Megatron-LM or DeepSpeed and recording no reduction or an increase in agent turns and active GPU time.
Figures


read the original abstract
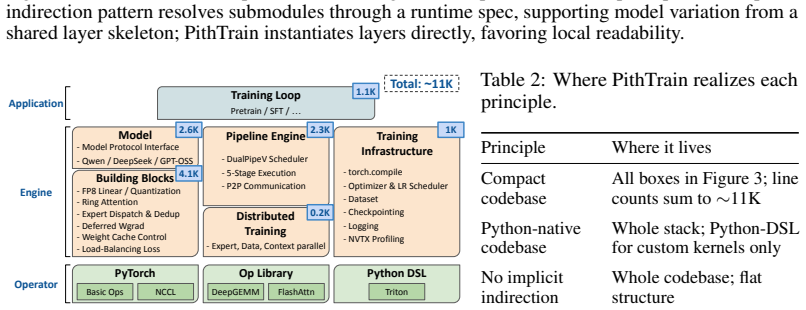
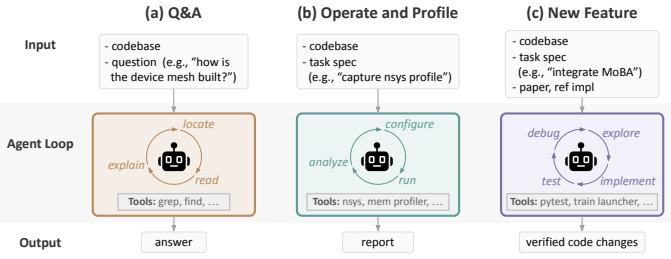
Mixture-of-Experts (MoE) has become the dominant architecture for frontier language models. To meet this demand, production frameworks have built optimized MoE training stacks over years of engineering effort. Yet evolving these stacks for new architectures and system optimizations remains expensive. With the rise of AI coding agents, they could automate parts of training-framework development and accelerate this evolution. But applying them to these existing frameworks carries hidden costs, invisible to today's throughput-only evaluations. We name this missing dimension agent-task efficiency (ATE): the cost of using coding agents to understand, operate, and extend a framework. Grounded in four agent-native design principles, we build PithTrain, a compact, agent-native MoE training framework. We further introduce ATE-Bench, covering real-world training-framework tasks. Our evaluation shows PithTrain matches the throughput of production frameworks, and on ATE-Bench, PithTrain enables higher agent-task efficiency, with up to 62% fewer Agent Turns and 64% less Active GPU Time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces agent-task efficiency (ATE) as a new evaluation dimension for MoE training frameworks beyond throughput. It presents four agent-native design principles, builds the compact PithTrain system around them, introduces the ATE-Bench benchmark covering real-world training-framework tasks, and reports that PithTrain matches production-framework throughput while achieving up to 62% fewer Agent Turns and 64% less Active GPU Time on ATE-Bench.
Significance. If the empirical results hold under scrutiny, the work could meaningfully expand how training systems are evaluated and designed, by incorporating agent usability as a first-class concern. The introduction of ATE and ATE-Bench represents a novel contribution that could influence future framework development for AI-assisted evolution, provided the benchmark tasks prove representative and the measurements are reproducible.
major comments (2)
- [Abstract] Abstract: The central claims of throughput parity and ATE gains (62% fewer Agent Turns, 64% less Active GPU Time) rest on new benchmark results, yet the abstract supplies no internal evidence such as ablation studies, controlled comparisons, task breakdowns, or statistical significance tests that would allow verification of the causal attribution to the four agent-native design principles or the representativeness of ATE-Bench tasks.
- [Evaluation] Evaluation section (inferred from claims): Exact definitions of the core metrics 'Agent Turns' and 'Active GPU Time', along with details on measurement methodology, baselines, and how ATE-Bench tasks map to real-world framework development, are not provided. This is load-bearing for assessing whether the reported efficiency gains are robust or artifactual.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript accordingly to improve clarity and verifiability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims of throughput parity and ATE gains (62% fewer Agent Turns, 64% less Active GPU Time) rest on new benchmark results, yet the abstract supplies no internal evidence such as ablation studies, controlled comparisons, task breakdowns, or statistical significance tests that would allow verification of the causal attribution to the four agent-native design principles or the representativeness of ATE-Bench tasks.
Authors: We agree that the abstract is high-level by design and does not contain the requested internal evidence. The full paper provides ablation studies, controlled comparisons against production baselines, task breakdowns on ATE-Bench, and methodology details in the Evaluation section. To strengthen the abstract without exceeding length constraints, we will add a brief clause referencing the four design principles and the real-world coverage of ATE-Bench tasks. This revision will better signal the grounding of the reported gains. revision: yes
-
Referee: [Evaluation] Evaluation section (inferred from claims): Exact definitions of the core metrics 'Agent Turns' and 'Active GPU Time', along with details on measurement methodology, baselines, and how ATE-Bench tasks map to real-world framework development, are not provided. This is load-bearing for assessing whether the reported efficiency gains are robust or artifactual.
Authors: We acknowledge this as a valid observation. The current manuscript introduces the metrics at a conceptual level but does not supply the precise operational definitions, instrumentation details, baseline configurations, or explicit task-to-real-world mappings that the referee requests. In the revised manuscript we will expand the Evaluation section with: (1) formal definitions and pseudocode for Agent Turns and Active GPU Time, (2) measurement methodology including logging hooks and statistical reporting, (3) explicit baseline descriptions, and (4) a table mapping each ATE-Bench task to representative framework-development activities. These additions will make the efficiency claims directly verifiable. revision: yes
Circularity Check
No significant circularity; claims rest on empirical benchmarks
full rationale
The paper describes an engineering artifact (PithTrain) constructed from four stated agent-native design principles and evaluated via a new benchmark (ATE-Bench) against throughput and agent-task metrics. No equations, fitted parameters, predictions, or derivation chains appear in the abstract or described claims. Results are presented as direct measurements rather than outputs derived from the inputs by construction. No self-citation load-bearing steps or uniqueness theorems are invoked. This is a standard non-circular systems paper whose central claims are externally falsifiable via the benchmark.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Agent-Task Efficiency (ATE)
no independent evidence
-
Four agent-native design principles
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Claude Code.https://www.anthropic.com/claude-code, 2025
Anthropic. Claude Code.https://www.anthropic.com/claude-code, 2025
2025
-
[2]
Equipping agents for the real world with Agent Skills
Anthropic. Equipping agents for the real world with Agent Skills. https://www.anthropic. com/engineering/equipping-agents-for-the-real-world-with-agent-skills , 2025
2025
-
[3]
Cursor: The AI code editor.https://www.cursor.com, 2023
Anysphere. Cursor: The AI code editor.https://www.cursor.com, 2023
2023
-
[4]
Program synthesis with large language models, 2021
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large language models, 2021
2021
-
[5]
PIQA: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le bras, Jianfeng Gao, and Yejin Choi. PIQA: Reasoning about physical commonsense in natural language. InProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2020
2020
-
[6]
MLE-bench: Evaluating machine learning agents on machine learning engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Aleksander Madry, and Lilian Weng. MLE-bench: Evaluating machine learning agents on machine learning engineering. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[7]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
2021
-
[8]
Palm: Scaling language modeling with pathways.Journal of machine learning research, 24(240):1– 113, 2023
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways.Journal of machine learning research, 24(240):1– 113, 2023
2023
-
[9]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Zhang, Hanwei Xu, Hao Yang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui 10 Qu, J
DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Hao Yang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui 10 Qu, J. L. Cai, Jia...
2024
-
[11]
Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Li, Hui Qu, J
DeepSeek-AI, Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Haowei Zhang, Honghui Ding, Huaj...
2025
-
[12]
GitHub Copilot.https://github.com/features/copilot, 2021
GitHub. GitHub Copilot.https://github.com/features/copilot, 2021
2021
-
[13]
Yongxin Guo, Zhenglin Cheng, Xiaoying Tang, Zhaopeng Tu, and Tao Lin. Dynamic mix- ture of experts: An auto-tuning approach for efficient transformer models.arXiv preprint arXiv:2405.14297, 2024
-
[14]
SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024. 11
2024
-
[15]
Moe++: Accelerating mixture-of-experts methods with zero-computation experts
Peng Jin, Bo Zhu, Li Yuan, and Shuicheng YAN. Moe++: Accelerating mixture-of-experts methods with zero-computation experts. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[16]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.Proceedings of the International Conference on Learning Representations (ICLR), 2015
2015
-
[17]
{GS}hard: Scaling giant models with conditional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. {GS}hard: Scaling giant models with conditional computation and automatic sharding. InInternational Conference on Learning Representations, 2021
2021
-
[18]
DataComp-LM: In search of the next generation of training sets for language models
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, et al. DataComp-LM: In search of the next generation of training sets for language models. arXiv preprint arXiv:2406.11794, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Torchtitan: One-stop pytorch native solution for production ready LLM pretraining
Wanchao Liang, Tianyu Liu, Less Wright, Will Constable, Andrew Gu, Chien-Chin Huang, Iris Zhang, Wei Feng, Howard Huang, Junjie Wang, Sanket Purandare, Gokul Nadathur, and Stratos Idreos. Torchtitan: One-stop pytorch native solution for production ready LLM pretraining. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[20]
Ringattention with blockwise transformers for near-infinite context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ringattention with blockwise transformers for near-infinite context. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[21]
MoBA: Mixture of Block Attention for Long-Context LLMs
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, et al. Moba: Mixture of block attention for long-context llms. arXiv preprint arXiv:2502.13189, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Fp8 formats for deep learning, 2022
Paulius Micikevicius, Dusan Stosic, Neil Burgess, Marius Cornea, Pradeep Dubey, Richard Grisenthwaite, Sangwon Ha, Alexander Heinecke, Patrick Judd, John Kamalu, Naveen Mellem- pudi, Stuart Oberman, Mohammad Shoeybi, Michael Siu, and Hao Wu. Fp8 formats for deep learning, 2022
2022
-
[23]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2018
2018
-
[24]
Efficient large-scale language model training on gpu clusters using megatron-lm
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. Efficient large-scale language model training on gpu clusters using megatron-lm. InProceedings of the International Conference for High Perform...
-
[25]
Association for Computing Machinery
-
[26]
TransformerEngine
NVIDIA. TransformerEngine. https://github.com/NVIDIA/TransformerEngine, 2022
2022
-
[27]
OpenAI, :, Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, Mark Chen, Enoch Cheung, Aidan Clark, Dan Cook, Marat Dukhan, Casey Dvorak, Kevin Fives, V...
2025
-
[28]
Codex CLI.https://github.com/openai/codex, 2025
OpenAI. Codex CLI.https://github.com/openai/codex, 2025
2025
-
[29]
Kernelbench: Can LLMs write efficient GPU kernels? InForty-second International Conference on Machine Learning, 2025
Anne Ouyang, Simon Guo, Simran Arora, Alex L Zhang, William Hu, Christopher Re, and Azalia Mirhoseini. Kernelbench: Can LLMs write efficient GPU kernels? InForty-second International Conference on Machine Learning, 2025
2025
-
[30]
Zero bubble (almost) pipeline parallelism
Penghui Qi, Xinyi Wan, Guangxing Huang, and Min Lin. Zero bubble (almost) pipeline parallelism. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[31]
Zihan Qiu, Zeyu Huang, Bo Zheng, Kaiyue Wen, Zekun Wang, Rui Men, Ivan Titov, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Demons in the detail: On implementing load balancing loss for training specialized mixture-of-expert models.arXiv preprint arXiv:2501.11873, 2025
-
[32]
Zero: memory optimiza- tions toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: memory optimiza- tions toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’20. IEEE Press, 2020
2020
-
[33]
Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters
Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD ’20, page 3505–3506, New York, NY , USA, 2020. Association for Computing Machinery
2020
-
[34]
Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2020
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2020
2020
-
[35]
Glu variants improve transformer, 2020
Noam Shazeer. Glu variants improve transformer, 2020
2020
-
[36]
Megatron-lm: Training multi-billion parameter language models using model parallelism, 2020
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism, 2020
2020
-
[37]
Kimi Team, Yifan Bai, Yiping Bao, Y . Charles, Cheng Chen, Guanduo Chen, Haiting Chen, Huarong Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Chenxiao Gao, Hongcheng Gao, Peizhong G...
2026
-
[38]
torch.distributed.checkpoint
The PyTorch Team. torch.distributed.checkpoint. https://docs.pytorch.org/docs/ stable/distributed.checkpoint.html, 2023
2023
-
[39]
Flashinfer-bench: Building the virtuous cycle for ai-driven llm systems, 2026
Shanli Xing, Yiyan Zhai, Alexander Jiang, Yixin Dong, Yong Wu, Zihao Ye, Charlie Ruan, Yingyi Huang, Yineng Zhang, Liangsheng Yin, Aksara Bayyapu, Luis Ceze, and Tianqi Chen. Flashinfer-bench: Building the virtuous cycle for ai-driven llm systems, 2026
2026
-
[40]
Qwen3 technical report, 2025
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
2025
-
[41]
SWE-agent: Agent-computer interfaces enable automated soft- ware engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik R Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated soft- ware engineering. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
2024
-
[42]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[43]
Differential transformer.arXiv preprint arXiv:2410.05258, 2024
Tianzhu Ye, Li Dong, Yuqing Xia, Yutao Sun, Yi Zhu, Gao Huang, and Furu Wei. Differential transformer.arXiv preprint arXiv:2410.05258, 2024
-
[44]
Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019
2019
-
[45]
Autocoderover: Au- tonomous program improvement
Yuntong Zhang, Haifeng Ruan, Zhiyu Fan, and Abhik Roychoudhury. Autocoderover: Au- tonomous program improvement. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, page 1592–1604, New York, NY , USA, 2024. Association for Computing Machinery
2024
-
[46]
absent, verified
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, Alban Desmaison, Can Balioglu, Pritam Damania, Bernard Nguyen, Geeta Chauhan, Yuchen Hao, Ajit Mathews, and Shen Li. Pytorch fsdp: Experiences on scaling fully sharded data parallel.Proc. VLDB Endow., 16(12):3848–3860, August 20...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.