IDOL: Inverse-Dynamics-Guided Future Prediction for End-to-End Autonomous Driving
Pith reviewed 2026-06-28 22:21 UTC · model grok-4.3
The pith
Inverse dynamics applied to pairs of predicted latent future states converts world-model forecasts into optimized driving trajectories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
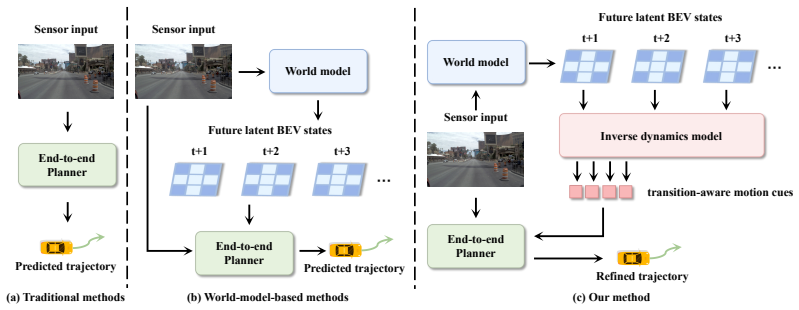
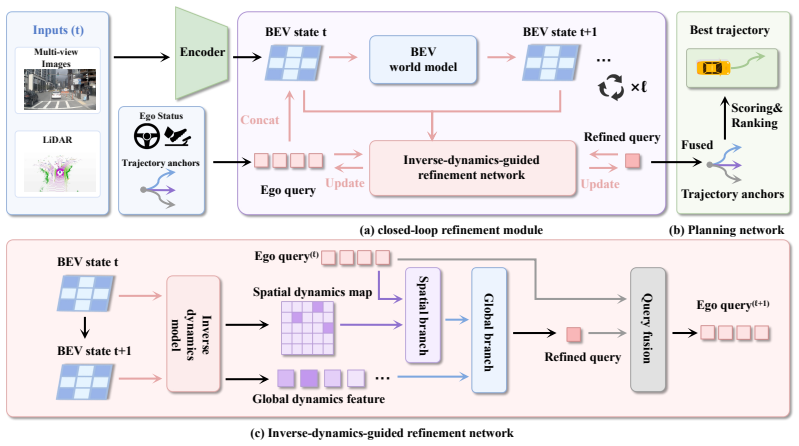
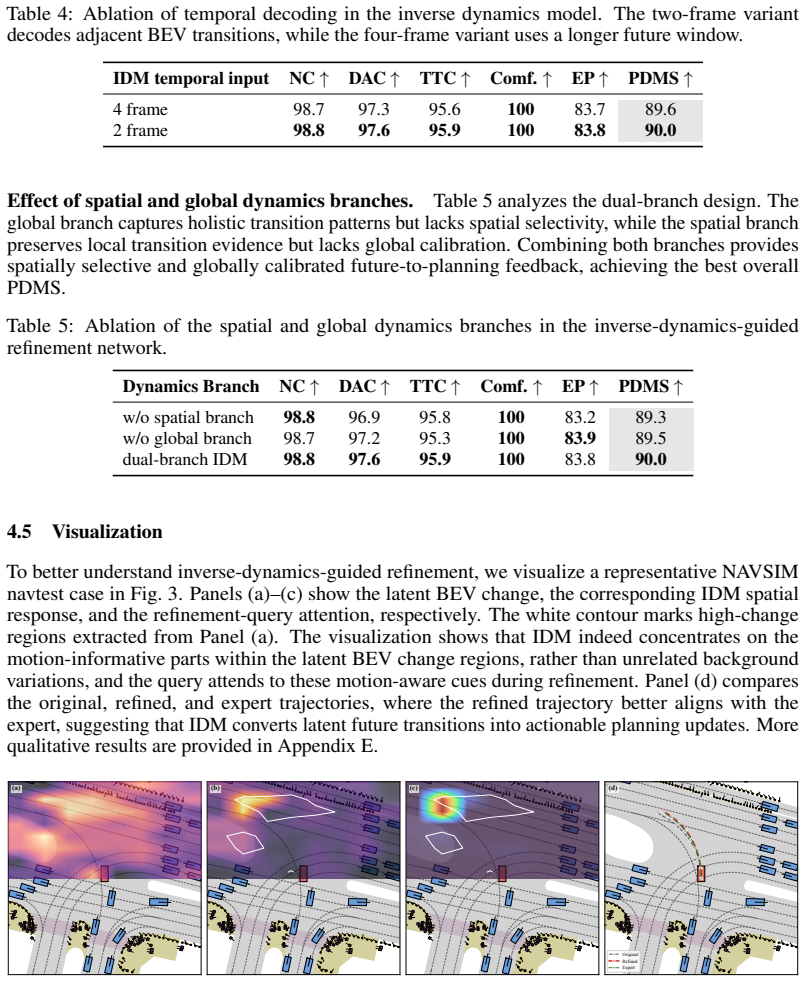
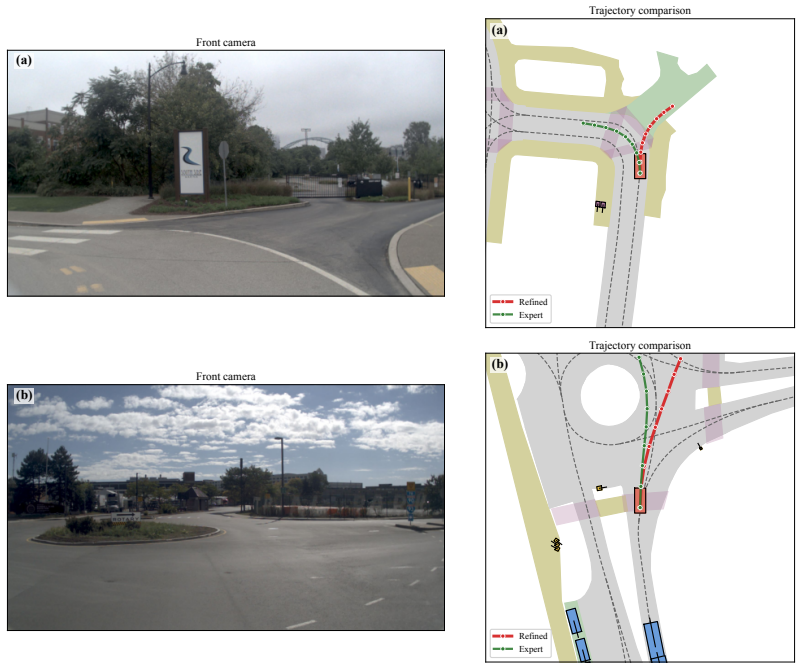
By inserting an inverse dynamics model between a BEV world model's predicted latent states and the trajectory optimizer, IDOL extracts transition-aware motion features from future forecasts and uses them to refine the planned path; this turns passive scene anticipation into explicit planning signals and is shown to raise performance on the NAVSIM benchmarks compared with prior comparable methods.
What carries the argument
An inverse dynamics model that takes adjacent predicted latent BEV states as input and outputs planning-relevant motion deltas to guide trajectory optimization.
If this is right
- Future scene predictions become direct inputs to trajectory updates instead of remaining separate from motion generation.
- A lightweight closed-loop refinement module re-applies future-aware reasoning to the optimized trajectory for better long-horizon consistency.
- World-model-based planning achieves state-of-the-art results among comparable methods on the NAVSIM v1 and NAVSIM v2 benchmarks.
- The overall coupling between latent world modeling and executable planning is tightened through the inverse-dynamics bridge.
Where Pith is reading between the lines
- The same inverse-dynamics decoding step could be tested on other latent world models outside driving to see whether it improves planning in different robotic settings.
- If the decoded motion deltas prove stable across diverse environments, they might reduce the need for separate motion-prediction heads in future end-to-end stacks.
- Extending the closed-loop refinement to multiple iterations might further reduce drift in very long-horizon forecasts, though the paper does not explore that regime.
Load-bearing premise
An inverse dynamics model applied to pairs of predicted latent future states will reliably decode transition-aware trajectory features whose use in optimization produces measurable planning improvements.
What would settle it
An ablation that removes the inverse dynamics decoding step, retrains or re-optimizes the planner on the same NAVSIM data, and checks whether the reported performance advantage disappears.
Figures
read the original abstract
End-to-end autonomous driving has emerged as a compelling paradigm for learning planning directly from sensor observations, while recent world-model-based approaches further enrich this paradigm by enabling explicit reasoning about how the scene may evolve in the future. Yet future prediction alone does not guarantee better planning unless the predicted evolution can be converted into planning-relevant trajectory updates. Many current methods still forecast future scene states without explicitly decoding the motion implications hidden in state transitions. As a result, future reasoning often remains descriptively useful but only weakly coupled to executable motion generation. To address this limitation, we propose \mathbf{IDOL}, an inverse-dynamics-guided future prediction framework for world-model-based end-to-end planning in latent BEV space, where inverse dynamics serves as the key bridge between future prediction and trajectory optimization. IDOL first predicts multiple future latent scene states with a BEV world model, then applies an inverse dynamics model to adjacent latent futures to decode transition-aware trajectory features and recover planning-relevant motion deltas that explain how the latent world evolves over time. These inverse-dynamics-derived signals are used to optimize the planned trajectory, turning future forecasting from passive scene anticipation into actionable planning guidance. A lightweight closed-loop refinement module further improves long-horizon consistency by reusing the optimized trajectory for another round of future-aware reasoning. By introducing inverse dynamics into latent future reasoning, IDOL tightens the coupling between world modeling and planning. Extensive experiments on the NAVSIM v1 and NAVSIM v2 benchmarks show that IDOL achieves state-of-the-art performance among comparable methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes IDOL, an inverse-dynamics-guided future prediction framework for world-model-based end-to-end autonomous driving in latent BEV space. The method first predicts multiple future latent scene states with a BEV world model, then applies an inverse dynamics model to adjacent latent futures to decode transition-aware trajectory features and recover planning-relevant motion deltas. These signals are used to optimize the planned trajectory, with an additional lightweight closed-loop refinement module for long-horizon consistency. The central claim is that this approach tightens the coupling between world modeling and planning, supported by state-of-the-art empirical results on the NAVSIM v1 and NAVSIM v2 benchmarks.
Significance. If the reported benchmark results hold under scrutiny, the explicit use of inverse dynamics to convert latent state transitions into actionable motion deltas for trajectory optimization would constitute a meaningful technical contribution to world-model-based planning. The framework directly targets the noted gap between descriptive future prediction and executable planning updates, and the empirical validation on established NAVSIM benchmarks provides a concrete basis for assessing impact.
Simulated Author's Rebuttal
We thank the referee for their review and for recognizing the potential contribution of using inverse dynamics to bridge future prediction and trajectory optimization in our IDOL framework. The report provides no specific major comments to address.
Circularity Check
No significant circularity
full rationale
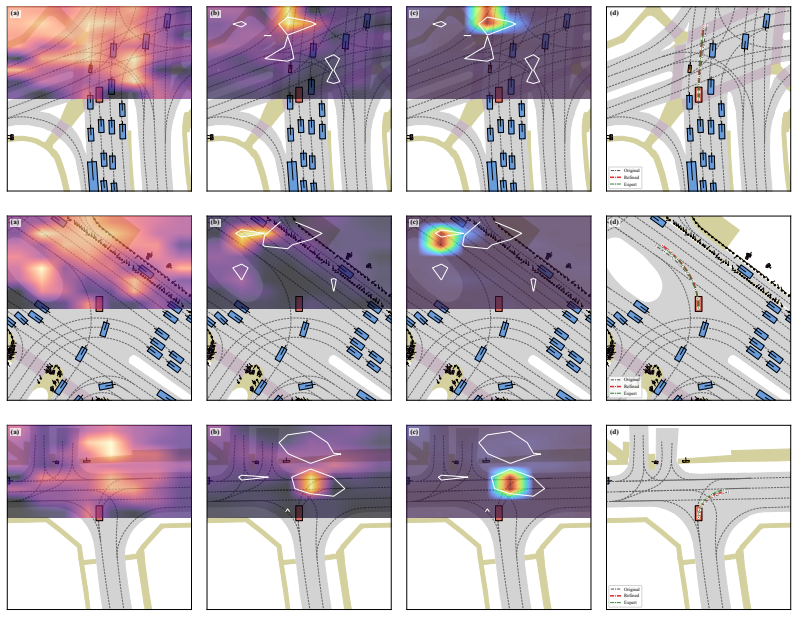
The paper describes an empirical ML framework for end-to-end driving that predicts latent future states via a BEV world model, applies an inverse-dynamics module to extract motion deltas, and uses those signals for trajectory optimization. No equations, parameter-fitting steps, or first-principles derivations are presented in the provided text that reduce a claimed prediction or result to its own inputs by construction. The central claims rest on benchmark performance (NAVSIM v1/v2) rather than any self-definitional loop, fitted-input-as-prediction, or self-citation chain. The inverse-dynamics component is introduced as an architectural choice whose value is demonstrated experimentally, not derived tautologically from the inputs it processes. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
An algorithm for the inverse dynamics of n-axis general manipulators using kane’s equations.Computers & Mathematics with Applications, 17(12):1545–1561, 1989
J Angeles, Ou Ma, and A Rojas. An algorithm for the inverse dynamics of n-axis general manipulators using kane’s equations.Computers & Mathematics with Applications, 17(12):1545–1561, 1989
1989
-
[2]
nuscenes: A multimodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020
2020
-
[3]
Pseudo-simulation for autonomous driving.arXiv preprint arXiv:2506.04218, 2025
Wei Cao, Marcel Hallgarten, Tianyu Li, Daniel Dauner, Xunjiang Gu, Caojun Wang, Yakov Miron, Marco Aiello, Hongyang Li, Igor Gilitschenski, et al. Pseudo-simulation for autonomous driving.arXiv preprint arXiv:2506.04218, 2025
-
[4]
End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10164–10183, 2024
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, Andreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(12):10164–10183, 2024
2024
-
[5]
VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Shaoyu Chen, Bo Jiang, Hao Gao, Bencheng Liao, Qing Xu, Qian Zhang, Chang Huang, Wenyu Liu, and Xinggang Wang. Vadv2: End-to-end vectorized autonomous driving via probabilistic planning.arXiv preprint arXiv:2402.13243, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Drivinggpt: Unifying driving world modeling and planning with multi-modal autoregressive transformers
Yuntao Chen, Yuqi Wang, and Zhaoxiang Zhang. Drivinggpt: Unifying driving world modeling and planning with multi-modal autoregressive transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26890–26900, 2025
2025
-
[7]
Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE transactions on pattern analysis and machine intelligence, 45(11):12878–12895, 2022
Kashyap Chitta, Aditya Prakash, Bernhard Jaeger, Zehao Yu, Katrin Renz, and Andreas Geiger. Transfuser: Imitation with transformer-based sensor fusion for autonomous driving.IEEE transactions on pattern analysis and machine intelligence, 45(11):12878–12895, 2022
2022
-
[8]
Parting with misconceptions about learning-based vehicle motion planning
Daniel Dauner, Marcel Hallgarten, Andreas Geiger, and Kashyap Chitta. Parting with misconceptions about learning-based vehicle motion planning. InConference on Robot Learning, pages 1268–1281. PMLR, 2023
2023
-
[9]
Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706– 28719, 2024
Daniel Dauner, Marcel Hallgarten, Tianyu Li, Xinshuo Weng, Zhiyu Huang, Zetong Yang, Hongyang Li, Igor Gilitschenski, Boris Ivanovic, Marco Pavone, et al. Navsim: Data-driven non-reactive autonomous vehicle simulation and benchmarking.Advances in Neural Information Processing Systems, 37:28706– 28719, 2024
2024
-
[10]
Rap: 3d rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333, 2025
Lan Feng, Yang Gao, Eloi Zablocki, Quanyi Li, Wuyang Li, Sichao Liu, Matthieu Cord, and Alexandre Alahi. Rap: 3d rasterization augmented end-to-end planning.arXiv preprint arXiv:2510.04333, 2025
-
[11]
Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving.IEEE Robotics and Automation Letters, 11(1):226–233, 2025
Renju Feng, Ning Xi, Duanfeng Chu, Rukang Wang, Zejian Deng, Anzheng Wang, Liping Lu, Jinxiang Wang, and Yanjun Huang. Artemis: Autoregressive end-to-end trajectory planning with mixture of experts for autonomous driving.IEEE Robotics and Automation Letters, 11(1):226–233, 2025
2025
-
[12]
Vista: A generalizable driving world model with high fidelity and versatile controllability
Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. Advances in Neural Information Processing Systems, 37:91560–91596, 2024
2024
-
[13]
ipad: Iterative proposal-centric end-to-end autonomous driving.arXiv preprint arXiv:2505.15111, 2025
Ke Guo, Haochen Liu, Xiaojun Wu, Jia Pan, and Chen Lv. ipad: Iterative proposal-centric end-to-end autonomous driving.arXiv preprint arXiv:2505.15111, 2025
-
[14]
Flowad: Ego-scene interactive modeling for autonomous driving.arXiv preprint arXiv:2603.13399, 2026
Mingzhe Guo, Yixiang Yang, Chuanrong Han, Rufeng Zhang, Shirui Li, Ji Wan, and Zhipeng Zhang. Flowad: Ego-scene interactive modeling for autonomous driving.arXiv preprint arXiv:2603.13399, 2026
-
[15]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[16]
Mastering Atari with Discrete World Models
Danijar Hafner, Timothy Lillicrap, Mohammad Norouzi, and Jimmy Ba. Mastering atari with discrete world models.arXiv preprint arXiv:2010.02193, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[17]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 10
2016
-
[19]
John M Hollerbach. A recursive lagrangian formulation of maniputator dynamics and a comparative study of dynamics formulation complexity.IEEE Transactions on Systems, Man, and Cybernetics, 10(11): 730–736, 2007
2007
-
[20]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
Planning-oriented autonomous driving
Yihan Hu, Jiazhi Yang, Li Chen, Keyu Li, Chonghao Sima, Xizhou Zhu, Siqi Chai, Senyao Du, Tianwei Lin, Wenhai Wang, et al. Planning-oriented autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17853–17862, 2023
2023
-
[22]
Occdriver: Future occupancy guided dual-branch trajectory planner in autonomous driving
Zhao Huang, Bowen Zhang, Zhongzhu Li, and Di Lin. Occdriver: Future occupancy guided dual-branch trajectory planner in autonomous driving. InThe Fourteenth International Conference on Learning Representations
-
[23]
Gen-drive: Enhancing diffusion generative driving policies with reward modeling and reinforcement learning fine-tuning
Zhiyu Huang, Xinshuo Weng, Maximilian Igl, Yuxiao Chen, Yulong Cao, Boris Ivanovic, Marco Pavone, and Chen Lv. Gen-drive: Enhancing diffusion generative driving policies with reward modeling and reinforcement learning fine-tuning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 3445–3451. IEEE, 2025
2025
-
[24]
EMMA: End-to-End Multimodal Model for Autonomous Driving
Jyh-Jing Hwang, Runsheng Xu, Hubert Lin, Wei-Chih Hung, Jingwei Ji, Kristy Choi, Di Huang, Tong He, Paul Covington, Benjamin Sapp, et al. Emma: End-to-end multimodal model for autonomous driving. arXiv preprint arXiv:2410.23262, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Diffvla: Vision-language guided diffusion planning for autonomous driving
Anqing Jiang, Yu Gao, Zhigang Sun, Yiru Wang, Jijun Wang, Jinghao Chai, Qian Cao, Yuweng Heng, Hao Jiang, Yunda Dong, et al. Diffvla: Vision-language guided diffusion planning for autonomous driving. arXiv preprint arXiv:2505.19381, 2025
-
[26]
Irl-vla: Training an vision-language-action policy via reward world model
Anqing Jiang, Yu Gao, Yiru Wang, Zhigang Sun, Shuo Wang, Yuwen Heng, Hao Sun, Shichen Tang, Lijuan Zhu, Jinhao Chai, et al. Irl-vla: Training an vision-language-action policy via reward world model. arXiv preprint arXiv:2508.06571, 2025
-
[27]
Vad: Vectorized scene representation for efficient autonomous driving
Bo Jiang, Shaoyu Chen, Qing Xu, Bencheng Liao, Jiajie Chen, Helong Zhou, Qian Zhang, Wenyu Liu, Chang Huang, and Xinggang Wang. Vad: Vectorized scene representation for efficient autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340–8350, 2023
2023
-
[28]
Guangfeng Jiang, Yueru Luo, Jun Liu, Yi Huang, Yiyao Zhu, Zhan Qu, Dave Zhenyu Chen, Bingbing Liu, and Xu Yan. Wpt: World-to-policy transfer via online world model distillation.arXiv preprint arXiv:2511.20095, 2025
-
[29]
Jungho Kim, Jiyong Oh, Seunghoon Yu, Hongjae Shin, Donghyuk Kwak, and Jun Won Choi. Safedrive: Fine-grained safety reasoning for end-to-end driving in a sparse world.arXiv preprint arXiv:2602.18887, 2026
-
[30]
An inverse dynamics model for the analysis, reconstruction and prediction of bipedal walking.Journal of biomechanics, 28(11):1369–1376, 1995
Bart Koopman, Henk J Grootenboer, and Henk J De Jongh. An inverse dynamics model for the analysis, reconstruction and prediction of bipedal walking.Journal of biomechanics, 28(11):1369–1376, 1995
1995
-
[31]
Jingyu Li, Bozhou Zhang, Xin Jin, Jiankang Deng, Xiatian Zhu, and Li Zhang. Imagidrive: A unified imagination-and-planning framework for autonomous driving.arXiv preprint arXiv:2508.11428, 2025
-
[32]
Jingyu Li, Junjie Wu, Dongnan Hu, Xiangkai Huang, Bin Sun, Zhihui Hao, Xianpeng Lang, Xiatian Zhu, and Li Zhang. Sgdrive: Scene-to-goal hierarchical world cognition for autonomous driving.arXiv preprint arXiv:2601.05640, 2026
-
[33]
arXiv preprint arXiv:2503.12820 (2025)
Kailin Li, Zhenxin Li, Shiyi Lan, Yuan Xie, Zhizhong Zhang, Jiayi Liu, Zuxuan Wu, Zhiding Yu, and Jose M Alvarez. Hydra-mdp++: Advancing end-to-end driving via expert-guided hydra-distillation.arXiv preprint arXiv:2503.12820, 2025
-
[34]
Peidong Li and Dixiao Cui. Navigation-guided sparse scene representation for end-to-end autonomous driving.arXiv preprint arXiv:2409.18341, 2024
-
[35]
Pengxiang Li, Yinan Zheng, Yue Wang, Huimin Wang, Hang Zhao, Jingjing Liu, Xianyuan Zhan, Kun Zhan, and Xianpeng Lang. Discrete diffusion for reflective vision-language-action models in autonomous driving.arXiv preprint arXiv:2509.20109, 2025
-
[36]
Enhancing End-to-End Autonomous Driving with Latent World Model
Yingyan Li, Lue Fan, Jiawei He, Yuqi Wang, Yuntao Chen, Zhaoxiang Zhang, and Tieniu Tan. Enhancing end-to-end autonomous driving with latent world model.arXiv preprint arXiv:2406.08481, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
DriveVLA-W0: World Models Amplify Data Scaling Law in Autonomous Driving
Yingyan Li, Shuyao Shang, Weisong Liu, Bing Zhan, Haochen Wang, Yuqi Wang, Yuntao Chen, Xiaoman Wang, Yasong An, Chufeng Tang, et al. Drivevla-w0: World models amplify data scaling law in autonomous driving.arXiv preprint arXiv:2510.12796, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
End-to-end driving with online trajectory evaluation via bev world model
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online trajectory evaluation via bev world model. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27137–27146, 2025
2025
-
[39]
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Yongkang Li, Kaixin Xiong, Xiangyu Guo, Fang Li, Sixu Yan, Gangwei Xu, Lijun Zhou, Long Chen, Haiyang Sun, Bing Wang, et al. Recogdrive: A reinforced cognitive framework for end-to-end autonomous driving.arXiv preprint arXiv:2506.08052, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Hydra-MDP: End-to-end Multimodal Planning with Multi-target Hydra-Distillation
Zhenxin Li, Kailin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Yishen Ji, Zhiqi Li, Ziyue Zhu, Jan Kautz, Zuxuan Wu, et al. Hydra-mdp: End-to-end multimodal planning with multi-target hydra-distillation.arXiv preprint arXiv:2406.06978, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Hydra-next: Robust closed-loop driving with open-loop training
Zhenxin Li, Shihao Wang, Shiyi Lan, Zhiding Yu, Zuxuan Wu, and Jose M Alvarez. Hydra-next: Robust closed-loop driving with open-loop training. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27305–27314, 2025
2025
-
[42]
Generalized trajectory scoring for end-to-end multimodal planning
Zhenxin Li, Wenhao Yao, Zi Wang, Xinglong Sun, Joshua Chen, Nadine Chang, Maying Shen, Zuxuan Wu, Shiyi Lan, and Jose M Alvarez. Generalized trajectory scoring for end-to-end multimodal planning. arXiv preprint arXiv:2506.06664, 2025
-
[43]
Is ego status all you need for open-loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14864–14873, 2024
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14864–14873, 2024
2024
-
[44]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving
Bencheng Liao, Shaoyu Chen, Haoran Yin, Bo Jiang, Cheng Wang, Sixu Yan, Xinbang Zhang, Xiangyu Li, Ying Zhang, Qian Zhang, et al. Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12037–12047, 2025
2025
-
[45]
Guideflow: Constraint-guided flow matching for planning in end-to-end autonomous driving
Lin Liu, Caiyan Jia, Guanyi Yu, Ziying Song, JunQiao Li, Feiyang Jia, Peiliang Wu, Xiaoshuai Hao, and Yadan Luo. Guideflow: Constraint-guided flow matching for planning in end-to-end autonomous driving. arXiv preprint arXiv:2511.18729, 2025
-
[46]
Shu Liu, Wenlin Chen, Weihao Li, Zheng Wang, Lijin Yang, Jianing Huang, Yipin Zhang, Zhongzhan Huang, Ze Cheng, and Hao Yang. Bridgedrive: Diffusion bridge policy for closed-loop trajectory planning in autonomous driving.arXiv preprint arXiv:2509.23589, 2025
-
[47]
Yuechen Luo, Fang Li, Shaoqing Xu, Zhiyi Lai, Lei Yang, Qimao Chen, Ziang Luo, Zixun Xie, Shengyin Jiang, Jiaxin Liu, et al. Adathinkdrive: Adaptive thinking via reinforcement learning for autonomous driving.arXiv preprint arXiv:2509.13769, 2025
-
[48]
LEAD: Minimizing Learner-Expert Asymmetry in End-to-End Driving
Long Nguyen, Micha Fauth, Bernhard Jaeger, Daniel Dauner, Maximilian Igl, Andreas Geiger, and Kashyap Chitta. Lead: Minimizing learner-expert asymmetry in end-to-end driving.arXiv preprint arXiv:2512.20563, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Inverse and forward dynamics: models of multi–body systems.Philosophical Transactions of the Royal Society of London
Egbert Otten. Inverse and forward dynamics: models of multi–body systems.Philosophical Transactions of the Royal Society of London. Series B: Biological Sciences, 358(1437):1493–1500, 2003
2003
-
[50]
Multi-modal fusion transformer for end-to-end autonomous driving
Aditya Prakash, Kashyap Chitta, and Andreas Geiger. Multi-modal fusion transformer for end-to-end autonomous driving. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7077–7087, 2021
2021
-
[51]
NoRD: A Data-Efficient Vision-Language-Action Model that Drives without Reasoning
Ishaan Rawal, Shubh Gupta, Yihan Hu, and Wei Zhan. Nord: A data-efficient vision-language-action model that drives without reasoning.arXiv preprint arXiv:2602.21172, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
Matthew Strong, Wei-Jer Chang, Quentin Herau, Jiezhi Yang, Yihan Hu, Chensheng Peng, and Wei Zhan. Learning to drive is a free gift: Large-scale label-free autonomy pretraining from unposed in-the-wild videos.arXiv preprint arXiv:2602.22091, 2026
-
[53]
Haisheng Su, Wei Wu, Feixiang Song, Junjie Zhang, Zhenjie Yang, and Junchi Yan. Drivemamba: Task-centric scalable state space model for efficient end-to-end autonomous driving.arXiv preprint arXiv:2602.13301, 2026. 12
-
[54]
Bin Sun, Yaoguang Cao, Yan Wang, Rui Wang, Jiachen Shang, Xiejie Feng, Jiayi Lu, Jia Shi, Shichun Yang, Xiaoyu Yan, et al. Minddrive: An all-in-one framework bridging world models and vision-language model for end-to-end autonomous driving.arXiv preprint arXiv:2512.04441, 2025
-
[55]
Sparsedrive: End- to-end autonomous driving via sparse scene representation
Wenchao Sun, Xuewu Lin, Yining Shi, Chuang Zhang, Haoran Wu, and Sifa Zheng. Sparsedrive: End- to-end autonomous driving via sparse scene representation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 8795–8801. IEEE, 2025
2025
-
[56]
Diffsemanticfusion: Semantic raster bev fusion for autonomous driving via online map diffusion.IEEE Robotics and Automation Letters, 11(3):2354–2361, 2026
Zhigang Sun, Yiru Wang, Anqing Jiang, Shuo Wang, Yu Gao, Yuwen Heng, Shouyi Zhang, An He, Hao Jiang, Jinhao Chai, et al. Diffsemanticfusion: Semantic raster bev fusion for autonomous driving via online map diffusion.IEEE Robotics and Automation Letters, 11(3):2354–2361, 2026
2026
-
[57]
CausalVAD: De-confounding End-to-End Autonomous Driving via Causal Intervention
Jiacheng Tang, Zhiyuan Zhou, Zhuolin He, Jia Zhang, Kai Zhang, and Jian Pu. Causalvad: De-confounding end-to-end autonomous driving via causal intervention.arXiv preprint arXiv:2603.18561, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[58]
Plan-R1: Safe and Feasible Trajectory Planning as Language Modeling
Xiaolong Tang, Meina Kan, Shiguang Shan, and Xilin Chen. Plan-r1: Safe and feasible trajectory planning as language modeling.arXiv preprint arXiv:2505.17659, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
SimScale: Learning to Drive via Real-World Simulation at Scale
Haochen Tian, Tianyu Li, Haochen Liu, Jiazhi Yang, Yihang Qiu, Guang Li, Junli Wang, Yinfeng Gao, Zhang Zhang, Liang Wang, et al. Simscale: Learning to drive via real-world simulation at scale.arXiv preprint arXiv:2511.23369, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Predictive Inverse Dynamics Models are Scalable Learners for Robotic Manipulation
Yang Tian, Sizhe Yang, Jia Zeng, Ping Wang, Dahua Lin, Hao Dong, and Jiangmiao Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation.arXiv preprint arXiv:2412.15109, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Jie Wang, Guang Li, Zhijian Huang, Chenxu Dang, Hangjun Ye, Yahong Han, and Long Chen. Vggdrive: Empowering vision-language models with cross-view geometric grounding for autonomous driving.arXiv preprint arXiv:2602.20794, 2026
-
[62]
Junli Wang, Yinan Zheng, Xueyi Liu, Zebin Xing, Pengfei Li, Guang Li, Kun Ma, Guang Chen, Hangjun Ye, Zhongpu Xia, et al. Meanfuser: Fast one-step multi-modal trajectory generation and adaptive reconstruction via meanflow for end-to-end autonomous driving.arXiv preprint arXiv:2602.20060, 2026
-
[63]
Exploring object-centric temporal modeling for efficient multi-view 3d object detection
Shihao Wang, Yingfei Liu, Tiancai Wang, Ying Li, and Xiangyu Zhang. Exploring object-centric temporal modeling for efficient multi-view 3d object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 3621–3631, 2023
2023
-
[64]
Drivedreamer: Towards real-world-drive world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jiagang Zhu, and Jiwen Lu. Drivedreamer: Towards real-world-drive world models for autonomous driving. InEuropean conference on computer vision, pages 55–72. Springer, 2024
2024
-
[65]
Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14749–14759, 2024
2024
-
[66]
Para-drive: Parallelized architecture for real-time autonomous driving
Xinshuo Weng, Boris Ivanovic, Yan Wang, Yue Wang, and Marco Pavone. Para-drive: Parallelized architecture for real-time autonomous driving. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15449–15458, 2024
2024
-
[67]
PRIX: Learning to Plan from Raw Pixels for End-to-End Autonomous Driving
Maciej K Wozniak, Lianhang Liu, Yixi Cai, and Patric Jensfelt. Prix: Learning to plan from raw pixels for end-to-end autonomous driving.arXiv preprint arXiv:2507.17596, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
DriveLaW:Unifying Planning and Video Generation in a Latent Driving World
Tianze Xia, Yongkang Li, Lijun Zhou, Jingfeng Yao, Kaixin Xiong, Haiyang Sun, Bing Wang, Kun Ma, Guang Chen, Hangjun Ye, et al. Drivelaw: Unifying planning and video generation in a latent driving world.arXiv preprint arXiv:2512.23421, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Goalflow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving
Zebin Xing, Xingyu Zhang, Yang Hu, Bo Jiang, Tong He, Qian Zhang, Xiaoxiao Long, and Wei Yin. Goalflow: Goal-driven flow matching for multimodal trajectories generation in end-to-end autonomous driving. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1602–1611, 2025
2025
-
[70]
Yifang Xu, Jiahao Cui, Feipeng Cai, Zhihao Zhu, Hanlin Shang, Shan Luan, Mingwang Xu, Neng Zhang, Yaoyi Li, Jia Cai, et al. Wam-flow: Parallel coarse-to-fine motion planning via discrete flow matching for autonomous driving.arXiv preprint arXiv:2512.06112, 2025
-
[71]
ReSim: Reliable World Simulation for Autonomous Driving
Jiazhi Yang, Kashyap Chitta, Shenyuan Gao, Long Chen, Yuqian Shao, Xiaosong Jia, Hongyang Li, Andreas Geiger, Xiangyu Yue, and Li Chen. Resim: Reliable world simulation for autonomous driving. arXiv preprint arXiv:2506.09981, 2025. 13
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[72]
Worldrft: Latent world model planning with reinforcement fine-tuning for autonomous driving
Pengxuan Yang, Ben Lu, Zhongpu Xia, Chao Han, Yinfeng Gao, Teng Zhang, Kun Zhan, XianPeng Lang, Yupeng Zheng, and Qichao Zhang. Worldrft: Latent world model planning with reinforcement fine-tuning for autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 11649–11657, 2026
2026
-
[73]
Drivesuprim: Towards precise trajectory selection for end-to-end planning
Wenhao Yao, Zhenxin Li, Shiyi Lan, Zi Wang, Xinglong Sun, Jose M Alvarez, and Zuxuan Wu. Drivesuprim: Towards precise trajectory selection for end-to-end planning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 11910–11918, 2026
2026
-
[74]
Diffrefiner: Coarse to fine trajectory planning via diffusion refinement with semantic interaction for end to end autonomous driving
Liuhan Yin, Runkun Ju, Guodong Guo, and Erkang Cheng. Diffrefiner: Coarse to fine trajectory planning via diffusion refinement with semantic interaction for end to end autonomous driving. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 12009–12017, 2026
2026
-
[75]
Zhenlong Yuan, Chengxuan Qian, Jing Tang, Rui Chen, Zijian Song, Lei Sun, Xiangxiang Chu, Yujun Cai, Dapeng Zhang, and Shuo Li. Autodrive-r2: Incentivizing reasoning and self-reflection capacity for vla model in autonomous driving.arXiv preprint arXiv:2509.01944, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
FutureSightDrive: Thinking Visually with Spatio-Temporal CoT for Autonomous Driving
Shuang Zeng, Xinyuan Chang, Mengwei Xie, Xinran Liu, Yifan Bai, Zheng Pan, Mu Xu, Xing Wei, and Ning Guo. Futuresightdrive: Thinking visually with spatio-temporal cot for autonomous driving.arXiv preprint arXiv:2505.17685, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Bozhou Zhang, Nan Song, Jingyu Li, Xiatian Zhu, Jiankang Deng, and Li Zhang. Future-aware end- to-end driving: Bidirectional modeling of trajectory planning and scene evolution.arXiv preprint arXiv:2510.11092, 2025
-
[78]
arXiv preprint arXiv:2602.10884 (2026)
Jinqing Zhang, Zehua Fu, Zelin Xu, Wenying Dai, Qingjie Liu, and Yunhong Wang. Resworld: Temporal residual world model for end-to-end autonomous driving.arXiv preprint arXiv:2602.10884, 2026
-
[79]
Epona: Autoregressive diffusion world model for autonomous driving
Kaiwen Zhang, Zhenyu Tang, Xiaotao Hu, Xingang Pan, Xiaoyang Guo, Yuan Liu, Jingwei Huang, Li Yuan, Qian Zhang, Xiao-Xiao Long, et al. Epona: Autoregressive diffusion world model for autonomous driving. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 27220–27230, 2025
2025
-
[80]
Diffe2e: Rethinking end-to-end driving with a hybrid diffusion-regression-classification policy
Rui Zhao, Yuze Fan, Ziguo Chen, Fei Gao, and Zhenhai Gao. Diffe2e: Rethinking end-to-end driving with a hybrid diffusion-regression-classification policy. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.