Decomposed On-Policy Distillation for Vision-Language Reasoning: Steering Gradients for Visual Grounding
Pith reviewed 2026-06-28 19:24 UTC · model grok-4.3
The pith
Decomposing the distillation loss shows language and visual gradients are nearly orthogonal, so reorienting updates toward the visual subspace improves grounding in vision-language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
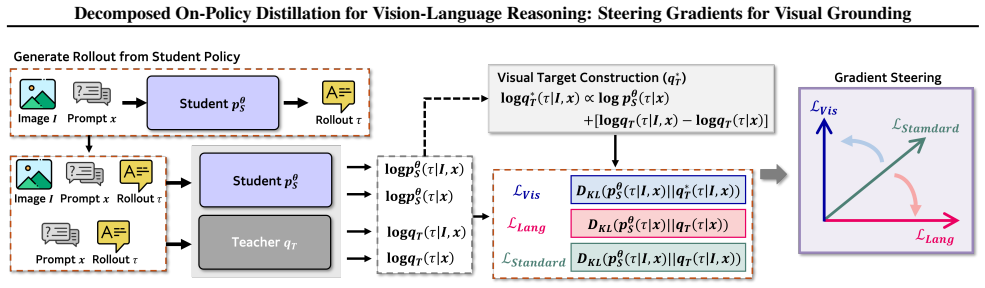
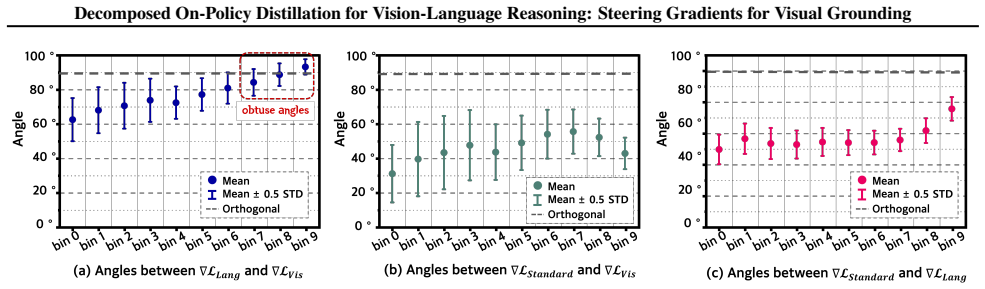
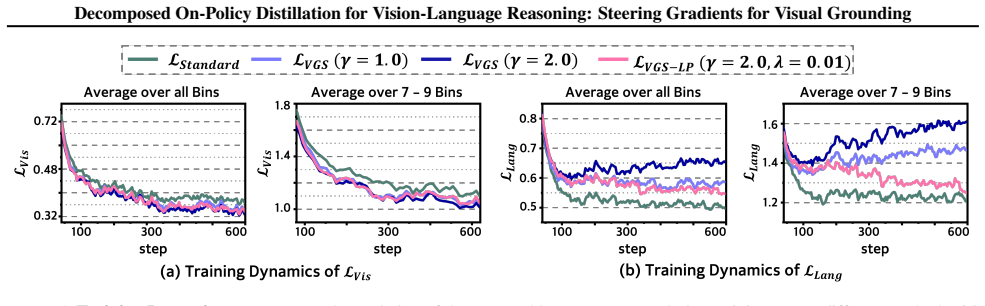
The gradient vectors for the language prior and visual grounding components of the distillation loss are nearly orthogonal. Standard optimization therefore follows a suboptimal compromise trajectory, whereas Visual Gradient Steering dynamically reorients the update vector to prioritize the visual subspace and yields superior grounding on complex multimodal benchmarks.
What carries the argument
Visual Gradient Steering (VGS), which computes the two gradient components separately and then rotates the combined update direction to favor the visual component over the language-prior component.
If this is right
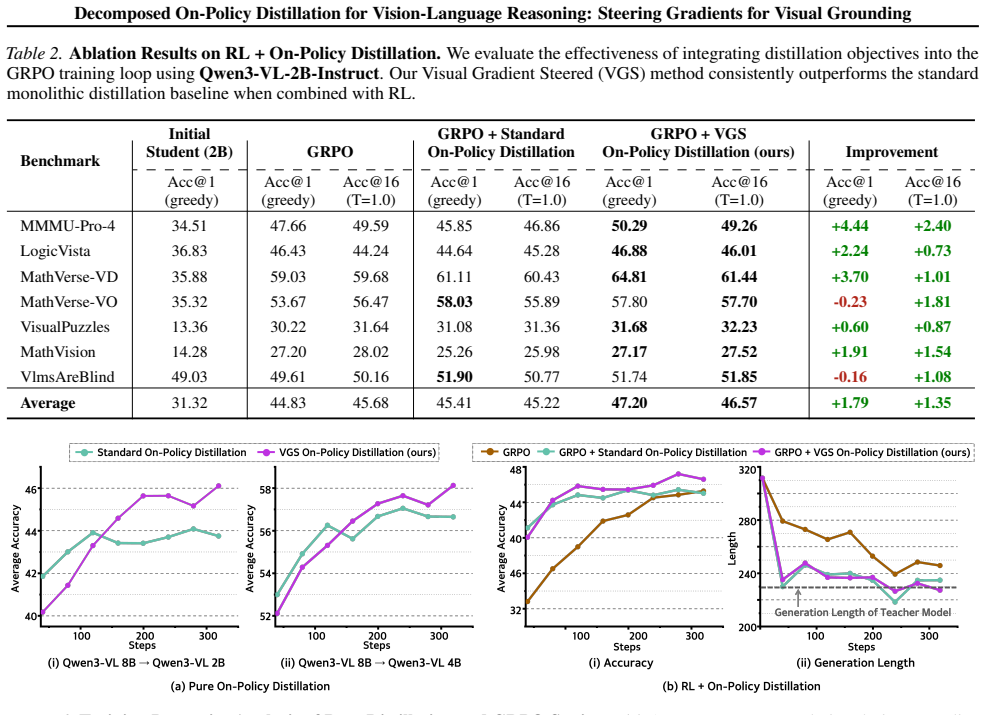
- VGS delivers higher visual grounding accuracy than monolithic on-policy distillation across multiple teacher-student pairs and benchmark suites.
- The language-alignment and visual-perception objectives remain geometrically independent throughout training.
- The added steering step incurs only minimal extra computation while improving final model quality.
- The same loss decomposition can be applied to any on-policy distillation setting that separates linguistic and perceptual signals.
Where Pith is reading between the lines
- If similar orthogonality appears in other multimodal domains such as audio-language or video-language, the same steering tactic could be reused without redesign.
- The method might allow smaller student models to close more of the gap to their teachers by removing the implicit language bias that currently limits visual fidelity.
- Measuring the angle between gradient subspaces on new tasks could serve as a quick diagnostic for whether visual grounding is the dominant bottleneck in a given architecture.
Load-bearing premise
Visual grounding is the primary bottleneck limiting vision-language reasoning performance.
What would settle it
A controlled run in which the measured angle between language-prior and visual-grounding gradients deviates substantially from orthogonality, or in which VGS produces no gain on the reported benchmarks, would falsify the central geometric claim.
Figures


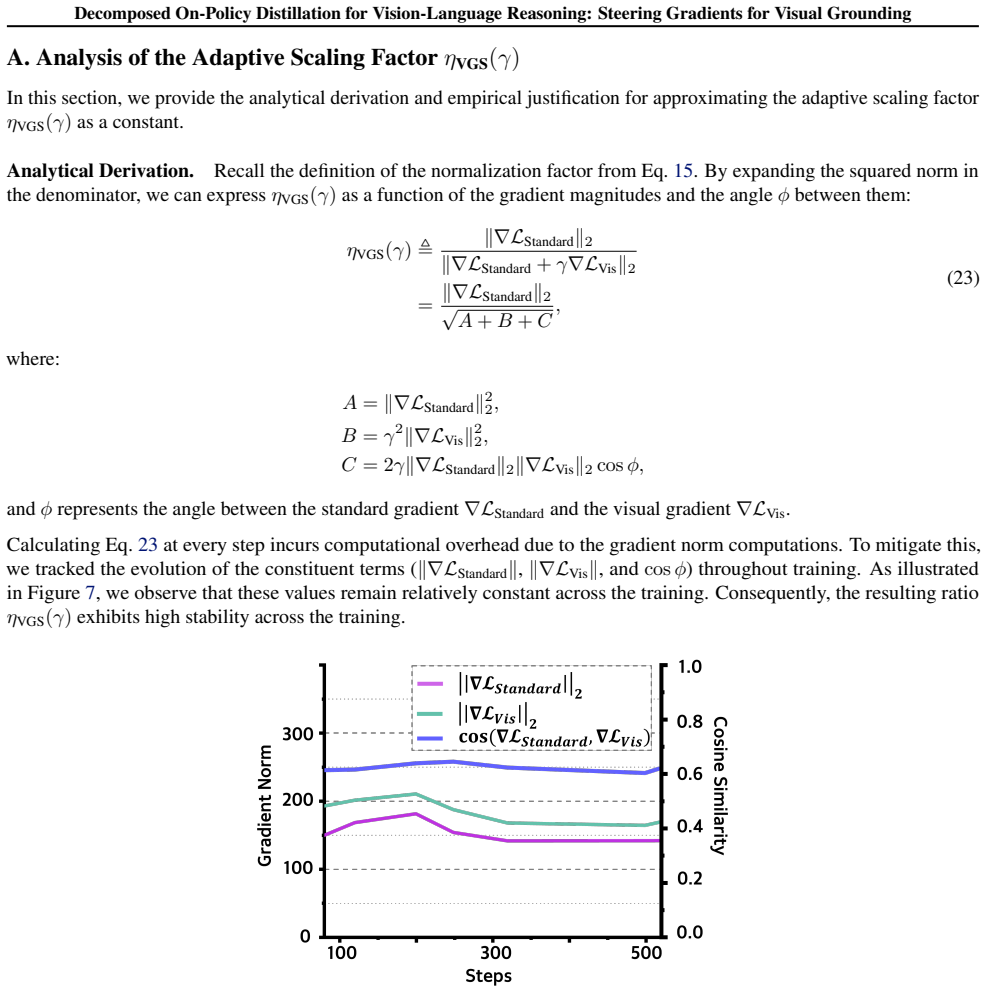
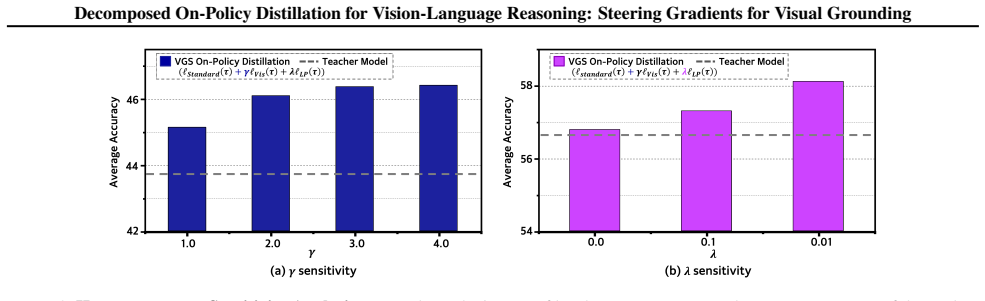
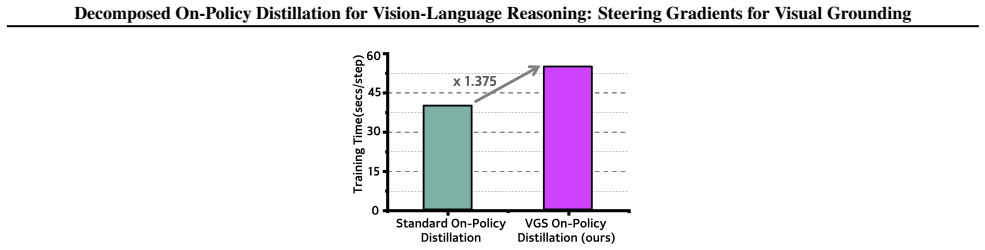
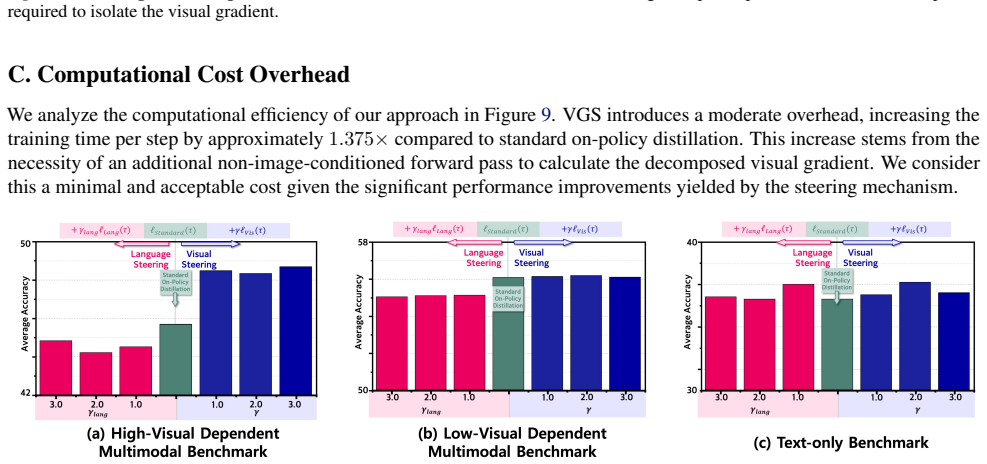
read the original abstract
While on-policy distillation offers dense supervision for training small reasoning models, its optimization dynamics in the multimodal domain remain under-explored. In this work, we challenge the standard monolithic view of Vision-Language Model (VLM) distillation by mathematically decomposing the loss into two distinct components: the language prior and visual grounding. Our analysis uncovers that gradient vectors for these components are nearly orthogonal, indicating that the objective of aligning with the teacher's language distribution is geometrically independent from the objective of matching its visual perception. Consequently, standard optimization passively follows a suboptimal compromise trajectory that implicitly balances the two objectives. Hypothesizing that visual grounding constitutes the primary bottleneck for vision-language reasoning, we introduce Visual Gradient Steering (VGS), a method that dynamically reorients the update vector to prioritize the visual subspace. Experimental results on multiple distillation settings and complex multimodal benchmarks demonstrate that VGS significantly outperforms the standard monolithic formulation of on-policy distillation, achieving superior grounding with minimal training overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper decomposes the on-policy distillation loss for vision-language models into language-prior and visual-grounding components, claims that the associated gradient vectors are nearly orthogonal, and introduces Visual Gradient Steering (VGS) to reorient updates toward the visual subspace under the hypothesis that visual grounding is the primary bottleneck. It reports that VGS outperforms standard monolithic distillation across multiple settings and complex multimodal benchmarks with minimal overhead.
Significance. If the decomposition is mathematically rigorous and the orthogonality result is substantiated with explicit derivations or measurements, the geometric separation of objectives could provide a useful lens for multi-objective optimization in VLMs. Demonstrating consistent gains from VGS would strengthen the case for targeted steering in distillation, though the overall significance depends on whether the visual-grounding bottleneck hypothesis receives independent support beyond the method's empirical performance.
major comments (2)
- [Abstract] Abstract: the mathematical decomposition into language-prior and visual-grounding terms and the orthogonality claim are asserted without any equations, proof sketch, or quantitative evidence (e.g., reported cosine similarities between gradients) visible even in the full abstract; the central geometric claim requires the explicit loss decomposition and supporting analysis (presumably in the method section) to be verifiable.
- [Abstract] Abstract: the hypothesis that visual grounding is the primary bottleneck is stated without independent justification such as per-component ablation on downstream error, separate loss curves for each term, or a measurement of relative contribution to task performance; the decision to steer specifically toward the visual subspace therefore rests on this hypothesis, whose support appears to derive from VGS success and risks circularity.
minor comments (1)
- All experimental claims of superiority should include concrete quantitative metrics, controls, and statistical details rather than qualitative assertions of outperformance.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. Below we respond point-by-point to the major comments, clarifying the role of the abstract versus the body of the paper and outlining planned revisions to strengthen the presentation of our hypothesis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the mathematical decomposition into language-prior and visual-grounding terms and the orthogonality claim are asserted without any equations, proof sketch, or quantitative evidence (e.g., reported cosine similarities between gradients) visible even in the full abstract; the central geometric claim requires the explicit loss decomposition and supporting analysis (presumably in the method section) to be verifiable.
Authors: We agree that the abstract, due to length constraints, does not contain equations or quantitative details. The manuscript provides the explicit loss decomposition, orthogonality derivation, and cosine-similarity measurements in the method section. To make the abstract more informative while remaining concise, we will revise it to briefly reference the decomposition and the reported near-orthogonality result. revision: yes
-
Referee: [Abstract] Abstract: the hypothesis that visual grounding is the primary bottleneck is stated without independent justification such as per-component ablation on downstream error, separate loss curves for each term, or a measurement of relative contribution to task performance; the decision to steer specifically toward the visual subspace therefore rests on this hypothesis, whose support appears to derive from VGS success and risks circularity.
Authors: The hypothesis is grounded in the geometric near-orthogonality result, which is established independently of VGS performance, together with existing literature on language-prior dominance in VLMs. The empirical gains of VGS provide corroborating evidence rather than the sole support. To further reduce any appearance of circularity, we will add independent analyses (separate component loss curves and relative contribution measurements) in the revised manuscript. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper mathematically decomposes the distillation loss into language-prior and visual-grounding terms, reports an empirical observation that the resulting gradient vectors are nearly orthogonal, states an explicit hypothesis that visual grounding is the primary bottleneck, and introduces VGS as a method to act on that hypothesis. The orthogonality finding follows directly from the decomposition (no fitted parameters renamed as predictions), the hypothesis is labeled as such rather than derived, and performance claims rest on external benchmark experiments rather than reducing to the inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the provided derivation chain to close any loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The distillation loss decomposes additively into language prior and visual grounding terms whose gradients are nearly orthogonal.
invented entities (1)
-
Visual Gradient Steering (VGS)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2016 , eprint=
Sequence-Level Knowledge Distillation , author=. 2016 , eprint=
2016
-
[2]
Hashimoto , title =
Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto , title =. GitHub repository , howpublished =. 2023 , publisher =
2023
-
[3]
The twelfth international conference on learning representations , year=
On-policy distillation of language models: Learning from self-generated mistakes , author=. The twelfth international conference on learning representations , year=
-
[4]
Yuxian Gu and Li Dong and Furu Wei and Minlie Huang , booktitle=. Mini. 2024 , url=
2024
-
[5]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
QwQ-32B: Embracing the Power of Reinforcement Learning , url =
Qwen Team , month =. QwQ-32B: Embracing the Power of Reinforcement Learning , url =
-
[8]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Advances in Neural Information Processing Systems , volume=
Compact language models via pruning and knowledge distillation , author=. Advances in Neural Information Processing Systems , volume=
-
[11]
CompoDistill: Attention Distillation for Compositional Reasoning in Multimodal LLMs
Compodistill: Attention distillation for compositional reasoning in multimodal llms , author=. arXiv preprint arXiv:2510.12184 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Elevating Visual Perception in Multimodal LLMs with Visual Embedding Distillation , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[13]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Llava-kd: A framework of distilling multimodal large language models , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[14]
arXiv preprint arXiv:2505.12081 , year=
VisionReasoner: Unified Visual Perception and Reasoning via Reinforcement Learning , author=. arXiv preprint arXiv:2505.12081 , year=
-
[15]
arXiv preprint arXiv:2509.24776 , year=
VTPerception-R1: Enhancing Multimodal Reasoning via Explicit Visual and Textual Perceptual Grounding , author=. arXiv preprint arXiv:2509.24776 , year=
-
[16]
Self-Rewarding Vision-Language Model via Reasoning Decomposition
Self-rewarding vision-language model via reasoning decomposition , author=. arXiv preprint arXiv:2508.19652 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Perception-Aware Policy Optimization for Multimodal Reasoning
Perception-aware policy optimization for multimodal reasoning , author=. arXiv preprint arXiv:2507.06448 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
2025 , eprint=
Qwen3-VL Technical Report , author=. 2025 , eprint=
2025
-
[20]
The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
Measuring Multimodal Mathematical Reasoning with MATH-Vision Dataset , author=. The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year=
-
[21]
European Conference on Computer Vision , pages=
Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[22]
2024 , eprint=
LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts , author=. 2024 , eprint=
2024
-
[23]
2025 , journal =
VisualPuzzles: Decoupling Multimodal Reasoning Evaluation from Domain Knowledge , author =. 2025 , journal =
2025
-
[24]
arXiv preprint arXiv:2407.06581 , year=
Vision language models are blind: Failing to translate detailed visual features into words , author=. arXiv preprint arXiv:2407.06581 , year=
-
[25]
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark , author=. arXiv preprint arXiv:2409.02813 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
International conference on machine learning , pages=
Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks , author=. International conference on machine learning , pages=. 2018 , organization=
2018
-
[27]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Qwen2. 5-math technical report: Toward mathematical expert model via self-improvement , author=. arXiv preprint arXiv:2409.12122 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Vision-r1: Incentivizing reasoning capability in multimodal large language models , author=. arXiv preprint arXiv:2503.06749 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
arXiv preprint arXiv:2505.14677 , year=
Visionary-r1: Mitigating shortcuts in visual reasoning with reinforcement learning , author=. arXiv preprint arXiv:2505.14677 , year=
-
[30]
arXiv preprint arXiv:2510.25992 , year=
Supervised reinforcement learning: From expert trajectories to step-wise reasoning , author=. arXiv preprint arXiv:2510.25992 , year=
-
[31]
arXiv preprint arXiv:2402.05808 , year=
Training large language models for reasoning through reverse curriculum reinforcement learning , author=. arXiv preprint arXiv:2402.05808 , year=
-
[32]
arXiv preprint arXiv:2510.22255 , year=
PACR: Progressively Ascending Confidence Reward for LLM Reasoning , author=. arXiv preprint arXiv:2510.22255 , year=
-
[33]
PDCR: Perception-Decomposed Confidence Reward for Vision-Language Reasoning
PDCR: Perception-Decomposed Confidence Reward for Vision-Language Reasoning , author=. arXiv preprint arXiv:2605.13467 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Tlcr: Token-level continuous reward for fine-grained reinforcement learning from human feedback , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[35]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[36]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[38]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[39]
Hasegawa-Johnson and Sungwoong Kim and Chang D
Hee Suk Yoon and Eunseop Yoon and Mark A. Hasegawa-Johnson and Sungwoong Kim and Chang D. Yoo , booktitle=. Conf. 2025 , url=
2025
-
[40]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Kimi k1. 5: Scaling reinforcement learning with llms , author=. arXiv preprint arXiv:2501.12599 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Tulu 3: Pushing frontiers in open language model post-training , author=. arXiv preprint arXiv:2411.15124 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
International Conference on Learning Representations , volume=
Process reward model with q-value rankings , author=. International Conference on Learning Representations , volume=
-
[43]
Advances in Neural Information Processing Systems , volume=
Stop summation: Min-form credit assignment is all process reward model needs for reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[44]
arXiv preprint arXiv:2505.18121 , year=
Progrm: Build better gui agents with progress rewards , author=. arXiv preprint arXiv:2505.18121 , year=
-
[45]
arXiv preprint arXiv:2510.00492 , year=
Rethinking Reward Models for Multi-Domain Test-Time Scaling , author=. arXiv preprint arXiv:2510.00492 , year=
-
[46]
OpenThoughts: Data Recipes for Reasoning Models
Openthoughts: Data recipes for reasoning models , author=. arXiv preprint arXiv:2506.04178 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.