MESA: Improving MoE Safety Alignment via Decentralized Expertise
Pith reviewed 2026-06-28 18:49 UTC · model grok-4.3
The pith
MESA uses optimal transport to spread safety duties across multiple experts in MoE LLMs, reducing bypass vulnerability while keeping helpfulness intact.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
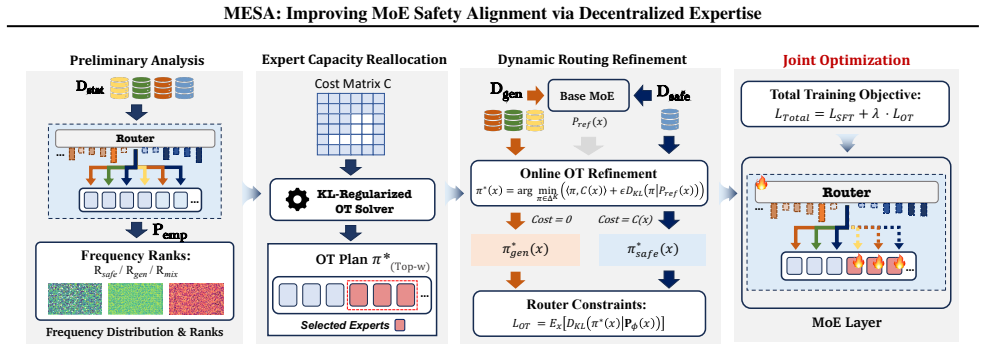
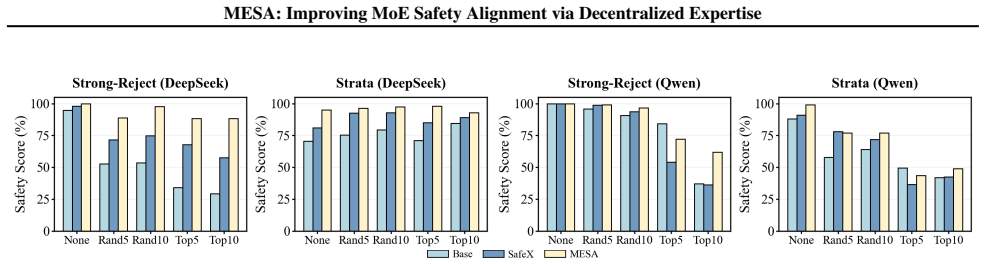
MESA is a targeted alignment framework for MoE-based LLMs that strategically decentralizes safety responsibility to maximize coverage while minimizing interference with utility. Based on Optimal Transport theory, it operates through two mechanisms: Expert Capacity Reallocation uses a transport cost matrix to distribute safety duties to the most cost-effective experts, and Dynamic Routing Refinement constrains the router to precisely activate these decentralized modules. Experiments show that MESA achieves robust defensive performance against varied harmful benchmarks while preserving helpfulness.
What carries the argument
Expert Capacity Reallocation via a transport cost matrix combined with Dynamic Routing Refinement, both derived from Optimal Transport theory, to assign and activate safety duties across experts.
If this is right
- Safety capabilities become distributed rather than sparse, reducing the chance that a single expert attack succeeds.
- The alignment process avoids uniform parameter changes that would interfere with utility-focused experts.
- The router learns to activate the reallocated safety modules on relevant inputs.
- Defensive performance improves across multiple harmful benchmarks while helpfulness metrics remain stable.
Where Pith is reading between the lines
- The same cost-matrix approach could be tested for decentralizing other specialized behaviors such as factual recall or domain expertise.
- If the cost matrix is poorly calibrated on a new model, the reallocation step itself might introduce unintended routing patterns.
- Scaling experiments on larger MoE models would test whether the two mechanisms remain effective when the number of experts grows.
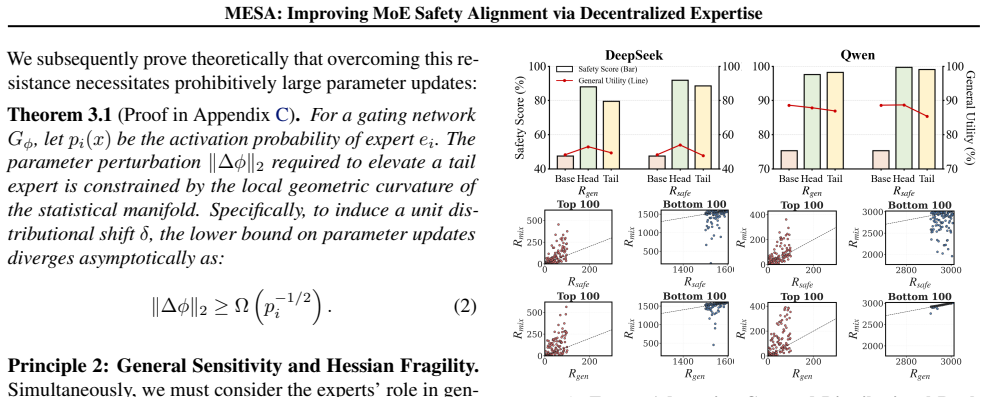
Load-bearing premise
The optimal transport cost matrix can identify experts that will reliably carry decentralized safety duties without degrading utility or creating new bypass routes.
What would settle it
Demonstrating that after MESA, an adversary can still bypass safety by targeting the newly assigned experts or that helpfulness scores on standard benchmarks drop substantially.
Figures


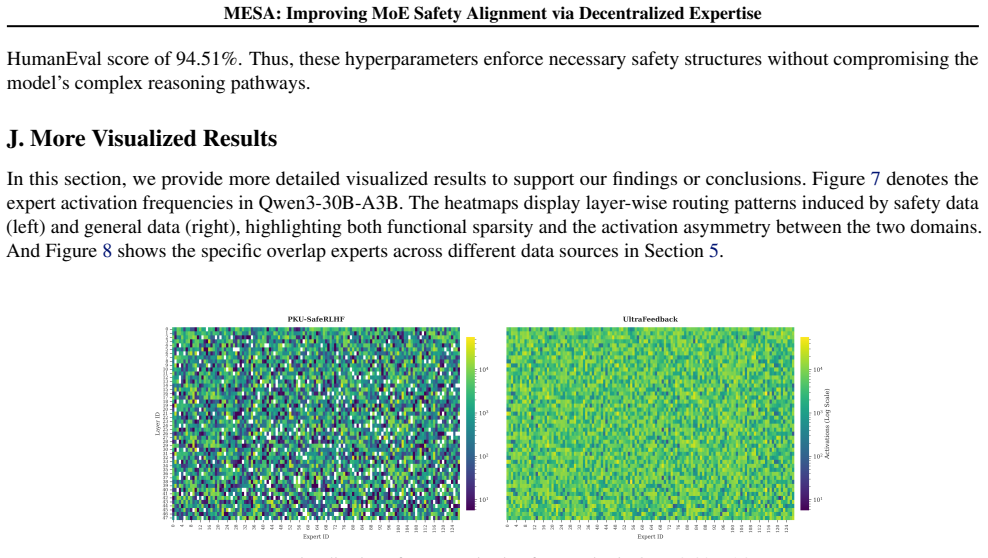

read the original abstract
Mixture-of-Experts (MoE) architectures scale Large Language Models (LLMs) efficiently, enabling greater capacity with reduced computational cost by dynamically routing inputs to relevant experts, yet introduce a critical vulnerability: Safety Sparsity, where safety capabilities concentrate in few experts, making them susceptible to adversarial bypassing. Meanwhile, conventional alignment methods uniformly adapt all parameters, ignoring their functional differences and inadvertently degrading performances. To address these challenges, we propose MESA (MoE Safety Alignment), a targeted alignment framework for MoE-based LLMs that strategically decentralizes safety responsibility to maximize coverage while minimizing interference with utility. Based on Optimal Transport (OT) theory, MESA operates through two mechanisms: (1) Expert Capacity Reallocation uses a transport cost matrix to distribute safety duties to the most cost-effective experts, and (2) Dynamic Routing Refinement constrains the router to precisely activate these decentralized modules. Experiments show that MESA achieves robust defensive performance against varied harmful benchmarks while preserving helpfulness. Code is available at https://github.com/lorraine021/MESA.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MESA, a targeted safety alignment framework for Mixture-of-Experts LLMs that uses Optimal Transport to decentralize safety responsibilities across experts via Expert Capacity Reallocation (based on a transport cost matrix) and Dynamic Routing Refinement (to constrain the router). The central claim is that this approach mitigates Safety Sparsity, yielding robust defense on harmful benchmarks while preserving helpfulness, unlike uniform alignment methods.
Significance. If the empirical results hold, the work is significant for addressing safety vulnerabilities specific to MoE scaling, where safety concentrates in few experts. The OT-based decentralization is a principled alternative to full-parameter adaptation and could inform efficient alignment techniques. Reproducibility is strengthened by the public code release.
minor comments (3)
- [Abstract] Abstract: the phrase 'varied harmful benchmarks' is vague; the introduction or §4 should explicitly list the benchmarks (e.g., specific datasets or attack types) and report quantitative deltas versus baselines to support the 'robust defensive performance' claim.
- [§3] The definition of the transport cost matrix and 'cost-effective experts' should be stated with explicit formulas (ideally in §3) so readers can verify how the OT objective avoids creating new bypass routes.
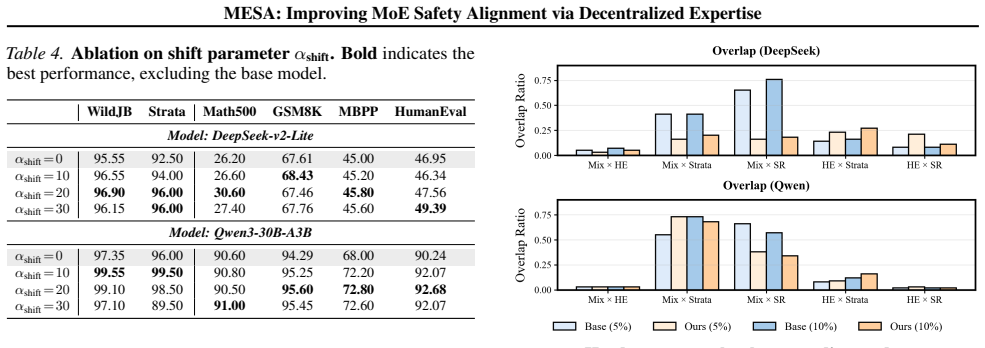
- [Experiments] Figure or table captions in the experiments section should include error bars or statistical significance tests for the helpfulness vs. safety trade-off to strengthen the 'preserving helpfulness' result.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of MESA and for recommending minor revision. The referee's summary correctly captures our central claim regarding safety sparsity in MoE models and the use of optimal transport for decentralized alignment. No major comments were raised in the report.
Circularity Check
No significant circularity
full rationale
The abstract and available description frame MESA as applying external Optimal Transport theory to construct a cost matrix for expert reallocation and router constraints. No equations, self-citations, or fitted parameters are shown that reduce the safety/utility outcomes to quantities defined by the method itself. The derivation chain relies on OT as an independent input and reports external benchmark results, making the central claim self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[2]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model , author=. arXiv preprint arXiv:2405.04434 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
arXiv preprint arXiv:2410.10630 , year=
Thinking llms: General instruction following with thought generation , author=. arXiv preprint arXiv:2410.10630 , year=
-
[7]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Ministral 3 , author=. arXiv preprint arXiv:2601.08584 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation , author=
-
[10]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Advances in neural information processing systems , volume=
Sinkhorn distances: Lightspeed computation of optimal transport , author=. Advances in neural information processing systems , volume=
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[14]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[16]
Proceedings of the ACM on Software Engineering , volume=
S-Eval: Towards Automated and Comprehensive Safety Evaluation for Large Language Models , author=. Proceedings of the ACM on Software Engineering , volume=. 2025 , publisher=
2025
-
[17]
arXiv preprint arXiv:2406.05946 , year=
Safety alignment should be made more than just a few tokens deep , author=. arXiv preprint arXiv:2406.05946 , year=
-
[18]
arXiv preprint arXiv:2401.06373 , year=
How johnny can persuade llms to jailbreak them: Rethinking persuasion to challenge ai safety by humanizing llms , author=. arXiv preprint arXiv:2401.06373 , year=
-
[19]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Breaking the ceiling: Exploring the potential of jailbreak attacks through expanding strategy space , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[20]
Advances in neural information processing systems , volume=
Deceptionbench: A comprehensive benchmark for ai deception behaviors in real-world scenarios , author=. Advances in neural information processing systems , volume=
-
[21]
Jailbreaking Black Box Large Language Models in Twenty Queries
Jailbreaking black box large language models in twenty queries , author=. arXiv preprint arXiv:2310.08419 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
2019 , publisher=
Computational optimal transport: With applications to data science , author=. 2019 , publisher=
2019
-
[23]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[24]
arXiv preprint arXiv:2602.08621 , year=
Sparse Models, Sparse Safety: Unsafe Routes in Mixture-of-Experts LLMs , author=. arXiv preprint arXiv:2602.08621 , year=
-
[25]
Advances in Neural Information Processing Systems , volume=
Jailbreakbench: An open robustness benchmark for jailbreaking large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Safe RLHF: Safe Reinforcement Learning from Human Feedback
Safe rlhf: Safe reinforcement learning from human feedback , author=. arXiv preprint arXiv:2310.12773 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
UltraFeedback: Boosting Language Models with Scaled AI Feedback
Ultrafeedback: Boosting language models with scaled ai feedback , author=. arXiv preprint arXiv:2310.01377 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
von Werra, Leandro and Belkada, Younes and Tunstall, Lewis and Beeching, Edward and Thrush, Tristan and Lambert, Nathan and Huang, Shengyi and Rasul, Kashif and Gallouédec, Quentin , license =
-
[29]
arXiv preprint arXiv:2502.02384 , year=
STAIR: Improving Safety Alignment with Introspective Reasoning , author=. arXiv preprint arXiv:2502.02384 , year=
-
[30]
2025 , eprint=
SAFEx: Analyzing Vulnerabilities of MoE-Based LLMs via Stable Safety-critical Expert Identification , author=. 2025 , eprint=
2025
-
[31]
A Strong
Souly, Alexandra and Lu, Qingyuan and Bowen, Dillon and Trinh, Tu and Hsieh, Elvis and Pandey, Sana and Abbeel, Pieter and Svegliato, Justin and Emmons, Scott and Watkins, Olivia and Toyer, Sam , booktitle=. A Strong
-
[32]
2024 , eprint=
WildTeaming at Scale: From In-the-Wild Jailbreaks to (Adversarially) Safer Language Models , author=. 2024 , eprint=
2024
-
[33]
arXiv preprint arXiv:2509.01444 , year=
Strata-sword: A hierarchical safety evaluation towards llms based on reasoning complexity of jailbreak instructions , author=. arXiv preprint arXiv:2509.01444 , year=
-
[34]
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[36]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
Program Synthesis with Large Language Models
Program synthesis with large language models , author=. arXiv preprint arXiv:2108.07732 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
First Conference on Language Modeling , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. First Conference on Language Modeling , year=
-
[39]
arXiv preprint arXiv:2504.18598 , year=
BadMoE: Backdooring Mixture-of-Experts LLMs via Optimizing Routing Triggers and Infecting Dormant Experts , author=. arXiv preprint arXiv:2504.18598 , year=
-
[40]
arXiv preprint arXiv:2509.09660 , year=
Steering moe llms via expert (de) activation , author=. arXiv preprint arXiv:2509.09660 , year=
-
[41]
, author=
DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models. , author=. NeurIPS , year=
-
[42]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
TrustLLM: Trustworthiness in Large Language Models
Trustllm: Trustworthiness in large language models , author=. arXiv preprint arXiv:2401.05561 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
arXiv preprint arXiv:2509.01909 , year=
Oyster-I: Beyond Refusal--Constructive Safety Alignment for Responsible Language Models , author=. arXiv preprint arXiv:2509.01909 , year=
-
[45]
The Thirteenth International Conference on Learning Representations , year=
Safety Alignment Should be Made More Than Just a Few Tokens Deep , author=. The Thirteenth International Conference on Learning Representations , year=
-
[46]
arXiv preprint arXiv:2503.00555 , year=
Safety tax: Safety alignment makes your large reasoning models less reasonable , author=. arXiv preprint arXiv:2503.00555 , year=
-
[47]
arXiv preprint arXiv:2503.18991 , year=
Inverse reinforcement learning with dynamic reward scaling for llm alignment , author=. arXiv preprint arXiv:2503.18991 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.