Leyline: KV Cache Directives for Agentic Inference
Pith reviewed 2026-06-28 16:49 UTC · model grok-4.3
The pith
Leyline supplies a 4-tuple directive for policy-driven KV cache edits in agentic LLMs using RoPE correction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
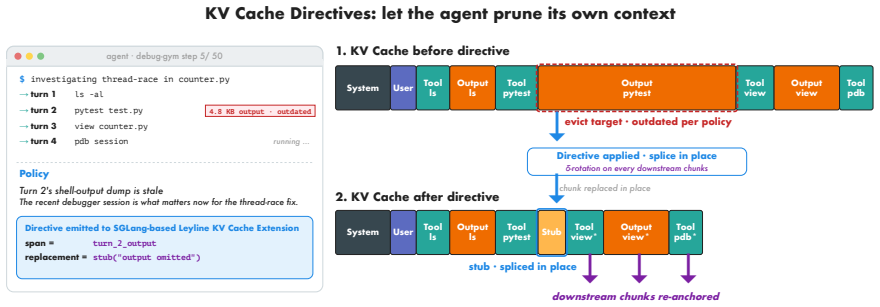
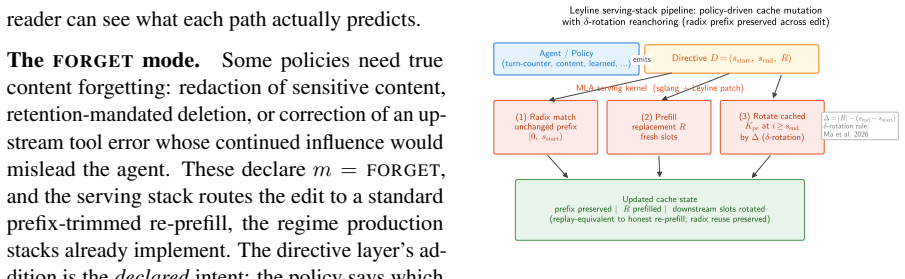
Leyline is a serving-side primitive that accepts a declarative 4-tuple directive to edit spans of the KV cache. The directive separates the edit target from the preservation mode, supporting in-place splice or prefix-trimmed re-prefill. An architecture-agnostic interface routes to per-architecture kernels that restore correct attention scores through a closed-form RoPE-rotation correction after the edit.
What carries the argument
The declarative directive 4-tuple that routes policy edits to splice kernels applying closed-form RoPE-rotation correction to preserve attention math.
Load-bearing premise
A closed-form RoPE-rotation correction applied after an in-place splice or prefix trim restores correct attention scores for subsequent tokens without side effects.
What would settle it
Compare model outputs or attention scores on a sequence after performing a splice edit with the correction versus recomputing the entire sequence from scratch.
Figures
read the original abstract
Modern KV cache management assumes the chatbot workload: prompts arrive once and the cache grows append-only, so prefix caching and forward-only eviction are correct by construction. Agentic LLMs break this assumption. Their conversations evolve through policy-driven editing: failed tool calls are retried, stale outputs dropped, trajectories pivoted. Two distinct cache problems result. First, identical content moves to new positions between turns, invalidating exact-prefix caches even though the underlying KV would still be valid; recent work on position-independent caching for MLA addresses this reuse problem. Second, and this paper's focus, a policy may need to direct the serving system to actively remove or replace a span of cached content and continue without re-prefilling everything that came after. No existing primitive offers this. Production agentic harnesses fall back to re-prefill on every edit, paying full prefix-recomputation cost; kernel-level eviction methods make their own decisions and cannot accept policy directives from outside the kernel. We introduce Leyline, a serving-side primitive that closes this gap. A declarative directive 4-tuple separates what to edit from how to preserve position correctness. The policy declares the edit and its mode (in-place splice or prefix-trimmed re-prefill for semantic forgetting); an architecture-agnostic interface routes to a per-architecture kernel that restores attention math via a closed-form RoPE-rotation correction. The splice kernel lifts replay cache-hit by +11.2 pp and cuts latency by up to 241 ms. A ten-line truncation rule routed through the same interface lifts agentic solve rate by +14.3 pp on debug-gym. The mechanism is open; the policy space it enables is the agenda.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Leyline, a serving-side primitive for KV cache management in agentic LLM inference. It proposes a declarative 4-tuple directive that allows external policies to specify edits such as in-place splices or prefix trims, routed through an architecture-agnostic interface to per-architecture kernels that apply closed-form RoPE-rotation corrections to preserve attention math. Reported results include a +11.2 pp lift in replay cache-hit rate, up to 241 ms latency reduction from the splice kernel, and a +14.3 pp improvement in agentic solve rate on debug-gym from a ten-line truncation rule.
Significance. If the RoPE correction is shown to be exact and the interface generalizes, this would address a practical gap in KV cache handling for non-append-only agentic workloads, reducing reliance on full re-prefills and enabling policy-driven edits. The open mechanism could support new serving primitives, though the significance depends on verification of the core correctness claim.
major comments (2)
- [Abstract] Abstract (description of the splice kernel and architecture-agnostic interface): The central claim that a closed-form RoPE-rotation correction restores exact attention scores for all subsequent tokens after an in-place splice or prefix-trim lacks the explicit formula, proof of equivalence to full re-prefill, or demonstration that relative rotary angles are preserved for arbitrary splice positions and lengths. This is load-bearing for the reported +11.2 pp cache-hit and +14.3 pp solve-rate gains.
- [Abstract] Abstract (performance claims): The deltas (+11.2 pp cache-hit lift, 241 ms latency cut, +14.3 pp solve rate) are reported without error bars, dataset details, baseline definitions, or explicit verification that the corrected KV cache produces numerically identical logits to a re-prefilled baseline across RoPE-using architectures.
minor comments (1)
- [Abstract] The abstract refers to a 'declarative directive 4-tuple' without enumerating its four components or their semantics; this should be clarified early for readability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the need for greater transparency on the core correctness claim and experimental reporting. We address each major comment below and will make the corresponding revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (description of the splice kernel and architecture-agnostic interface): The central claim that a closed-form RoPE-rotation correction restores exact attention scores for all subsequent tokens after an in-place splice or prefix-trim lacks the explicit formula, proof of equivalence to full re-prefill, or demonstration that relative rotary angles are preserved for arbitrary splice positions and lengths. This is load-bearing for the reported +11.2 pp cache-hit and +14.3 pp solve-rate gains.
Authors: We agree that the abstract and main text as currently written do not supply the explicit formula, a self-contained proof of equivalence, or an explicit demonstration for arbitrary splice positions. We will revise the manuscript to include the closed-form RoPE correction formula, a proof sketch establishing equivalence to full re-prefill (via preservation of relative rotary angles), and a short verification argument covering arbitrary splice locations and lengths. These additions will appear in Section 3 with a forward reference from the abstract. revision: yes
-
Referee: [Abstract] Abstract (performance claims): The deltas (+11.2 pp cache-hit lift, 241 ms latency cut, +14.3 pp solve rate) are reported without error bars, dataset details, baseline definitions, or explicit verification that the corrected KV cache produces numerically identical logits to a re-prefilled baseline across RoPE-using architectures.
Authors: We accept that the current reporting is insufficiently rigorous. The revised manuscript will add error bars computed over multiple runs, explicit dataset and baseline definitions, and a dedicated verification experiment confirming that the corrected KV cache yields numerically identical logits to a full re-prefill baseline on the RoPE-based models evaluated. revision: yes
Circularity Check
No significant circularity; new interface and kernel design are self-contained contributions.
full rationale
The paper presents Leyline as a new declarative 4-tuple directive and architecture-agnostic splice kernel that applies a closed-form RoPE correction after edits. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any claimed result (e.g., the +11.2 pp cache-hit lift or +14.3 pp solve-rate gain) to an input by construction. The central claims rest on the design of the interface and the empirical behavior of the kernel rather than on renaming, fitting, or self-referential uniqueness theorems. The RoPE correction is asserted to restore attention scores but is not shown to be derived from the paper's own prior fitted quantities.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A closed-form rotation of rotary position embeddings can restore exact attention scores after an in-place splice or prefix-trim of the KV cache.
invented entities (1)
-
Leyline directive 4-tuple
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Irminsul:
Bole Ma and Jan Eitzinger and Harald K. Irminsul:. 2026 , eprint =
2026
-
[2]
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. Proceedings of the 29th Symposium on Operating Systems Principles , pages =. 2023 , isbn =. doi:10.1145/3600006.3613165 , abstract =
-
[3]
and Barrett, Clark and Sheng, Ying , title =
Zheng, Lianmin and Yin, Liangsheng and Xie, Zhiqiang and Sun, Chuyue and Huang, Jeff and Yu, Cody Hao and Cao, Shiyi and Kozyrakis, Christos and Stoica, Ion and Gonzalez, Joseph E. and Barrett, Clark and Sheng, Ying , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[4]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Zhang, Zhenyu and Sheng, Ying and Zhou, Tianyi and Chen, Tianlong and Zheng, Lianmin and Cai, Ruisi and Song, Zhao and Tian, Yuandong and R\'. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[5]
Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =
Li, Yuhong and Huang, Yingbing and Yang, Bowen and Venkitesh, Bharat and Locatelli, Acyr and Ye, Hanchen and Cai, Tianle and Lewis, Patrick and Chen, Deming , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[6]
2024 , eprint=
Efficient Streaming Language Models with Attention Sinks , author=. 2024 , eprint=
2024
-
[7]
Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =
Liu, Zichang and Desai, Aditya and Liao, Fangshuo and Wang, Weitao and Xie, Victor and Xu, Zhaozhuo and Kyrillidis, Anastasios and Shrivastava, Anshumali , title =. Proceedings of the 37th International Conference on Neural Information Processing Systems , articleno =. 2023 , publisher =
2023
-
[8]
2024 , eprint=
Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs , author=. 2024 , eprint=
2024
-
[9]
Sanjay Kariyappa and G. Edward Suh , year=. 2602.22603 , archivePrefix=
-
[10]
LoopGuard: Breaking Self-Reinforcing Attention Loops via Dynamic KV Cache Intervention
Dongjie Xu and Hao Wu and Weijie Shi and Yue Cui and Yuanjun Liu and Jiawei Li and Haolun Ma and An Liu and Jia Zhu and Jiajie Xu , year=. 2604.10044 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
2025 , howpublished =
Context Editing:. 2025 , howpublished =
2025
-
[12]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao and Jeffrey Zhao and Dian Yu and Nan Du and Izhak Shafran and Karthik Narasimhan and Yuan Cao , year=. 2210.03629 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , title =
Yang, John and Jimenez, Carlos E. and Wettig, Alexander and Lieret, Kilian and Yao, Shunyu and Narasimhan, Karthik and Press, Ofir , title =. Proceedings of the 38th International Conference on Neural Information Processing Systems , articleno =. 2024 , isbn =
2024
-
[14]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez and John Yang and Alexander Wettig and Shunyu Yao and Kexin Pei and Ofir Press and Karthik Narasimhan , year=. 2310.06770 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Xingdi Yuan and Morgane M Moss and Charbel El Feghali and Chinmay Singh and Darya Moldavskaya and Drew MacPhee and Lucas Caccia and Matheus Pereira and Minseon Kim and Alessandro Sordoni and Marc-Alexandre Côté , year=. 2503.21557 , archivePrefix=
-
[16]
2023 , eprint=
Lost in the Middle: How Language Models Use Long Contexts , author=. 2023 , eprint=
2023
-
[17]
2024 , eprint=
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model , author=. 2024 , eprint=
2024
-
[18]
2024 , eprint=
DeepSeek-V3 Technical Report , author=. 2024 , eprint=
2024
-
[19]
2026 , howpublished =
2026
-
[20]
Su, Jianlin and Ahmed, Murtadha and Lu, Yu and Pan, Shengfeng and Bo, Wen and Liu, Yunfeng , title =. 2024 , issue_date =. doi:10.1016/j.neucom.2023.127063 , journal =
-
[21]
2023 , eprint=
GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints , author=. 2023 , eprint=
2023
-
[22]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[23]
2025 , howpublished=
2025
-
[24]
JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Aichen Cai and Anmeng Zhang and Anyu Li and others , year=. 2604.03044 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
2023 , eprint=
Active Retrieval Augmented Generation , author=. 2023 , eprint=
2023
-
[26]
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Akari Asai and Zeqiu Wu and Yizhong Wang and Avirup Sil and Hannaneh Hajishirzi , year=. 2310.11511 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
2025 , eprint=
Optimizing Agentic Language Model Inference via Speculative Tool Calls , author=. 2025 , eprint=
2025
-
[28]
I Found a Hidden Feature in
Pete Spano , year =. I Found a Hidden Feature in
-
[29]
2024 , howpublished =
2024
-
[30]
2025 , howpublished =
2025
-
[31]
How to Stop
Cole, Nathan , year =. How to Stop
-
[32]
Yuhan Liu and Yihua Cheng and Jiayi Yao and Yuwei An and Xiaokun Chen and Shaoting Feng and Yuyang Huang and Samuel Shen and Rui Zhang and Kuntai Du and Junchen Jiang , year=. 2510.09665 , archivePrefix=
-
[33]
Jiayi Yao and Hanchen Li and Yuhan Liu and Siddhant Ray and Yihua Cheng and Qizheng Zhang and Kuntai Du and Shan Lu and Junchen Jiang , year=. 2405.16444 , archivePrefix=
-
[34]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , eprint=
Junhao Hu and Wenrui Huang and Weidong Wang and Haoyi Wang and Tiancheng Hu and Qin Zhang and Hao Feng and Xusheng Chen and Yizhou Shan and Tao Xie , year=. Proceedings of the 42nd International Conference on Machine Learning (ICML) , eprint=
-
[35]
Mellette, Alex Forencich, Rukshani Athapathu, Alex C
Liu, Yuhan and Li, Hanchen and Cheng, Yihua and Ray, Siddhant and Huang, Yuyang and Zhang, Qizheng and Du, Kuntai and Yao, Jiayi and Lu, Shan and Ananthanarayanan, Ganesh and Maire, Michael and Hoffmann, Henry and Holtzman, Ari and Jiang, Junchen , title =. Proceedings of the ACM SIGCOMM 2024 Conference , pages =. 2024 , isbn =. doi:10.1145/3651890.367227...
-
[36]
Proceedings of the 41st International Conference on Machine Learning , articleno =
Liu, Zirui and Yuan, Jiayi and Jin, Hongye and Zhong, Shaochen (Henry) and Xu, Zhaozhuo and Braverman, Vladimir and Chen, Beidi and Hu, Xia , title =. Proceedings of the 41st International Conference on Machine Learning , articleno =. 2024 , publisher =
2024
-
[37]
2024 , howpublished =
Prompt Caching , author =. 2024 , howpublished =
2024
-
[38]
MemGPT: Towards LLMs as Operating Systems
Charles Packer and Sarah Wooders and Kevin Lin and Vivian Fang and Shishir G. Patil and Ion Stoica and Joseph E. Gonzalez , year=. 2310.08560 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
2024 , eprint=
Do Large Language Models Need a Content Delivery Network? , author=. 2024 , eprint=
2024
-
[40]
Compute or load kv cache? why not both?arXiv preprint arXiv:2410.03065,
Shuowei Jin and Xueshen Liu and Qingzhao Zhang and Z. Morley Mao , year=. Compute Or Load. 2410.03065 , archivePrefix=
-
[41]
Hyungwoo Lee and Kihyun Kim and Jinwoo Kim and Jungmin So and Myung-Hoon Cha and Hong-Yeon Kim and James J. Kim and Youngjae Kim , year=. Shared Disk. 2504.11765 , archivePrefix=
-
[42]
Cunchen Hu and Heyang Huang and Junhao Hu and Jiang Xu and Xusheng Chen and Tao Xie and Chenxi Wang and Sa Wang and Yungang Bao and Ninghui Sun and Yizhou Shan , year=. 2406.17565 , archivePrefix=
-
[43]
Huan Yang and Renji Zhang and Mingzhe Huang and Weijun Wang and Yin Tang and Yuanchun Li and Yunxin Liu and Deyu Zhang , year=. 2503.16525 , archivePrefix=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.