SkillRevise: Improving LLM-Authored Agent Skills via Trace-Conditioned Skill Revision
Pith reviewed 2026-06-28 17:35 UTC · model grok-4.3
The pith
SkillRevise refines initial LLM agent skills by diagnosing defects in execution traces and applying targeted repairs from stored principles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
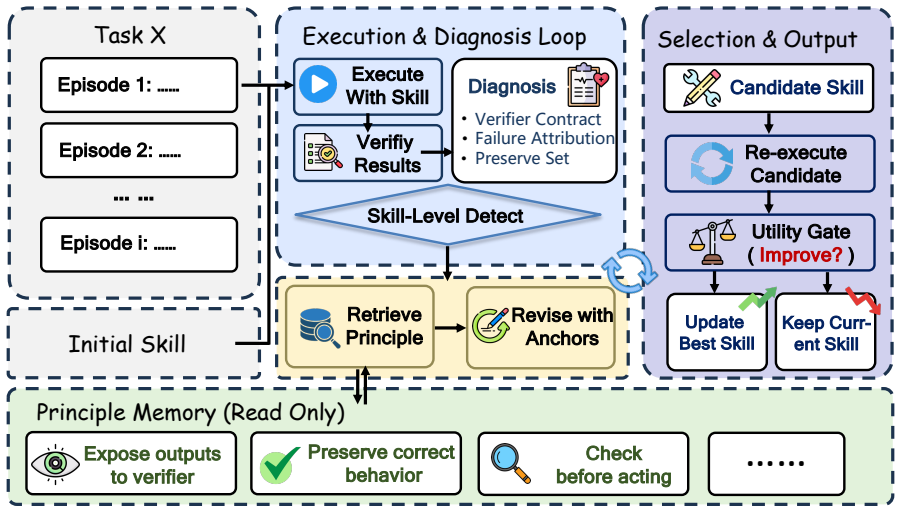
SkillRevise diagnoses skill defects from execution evidence, retrieves relevant repair principles from a general memory, and applies execution-anchored edits. It retains the first verifier-passing skill within the revision budget and falls back to empirical utility only when no candidate succeeds.
What carries the argument
Trace-conditioned revision loop that extracts defects from execution traces, retrieves repair principles, and produces edited skill candidates for re-testing.
If this is right
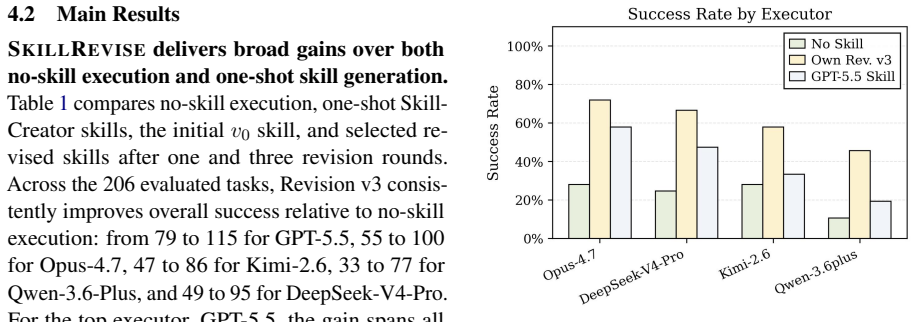
- Base agent success rate on SkillsBench rises from 36.05% to 61.63%.
- Revised skills transfer to different executors and task environments.
- The method outperforms one-shot baselines across three benchmarks and five LLMs.
Where Pith is reading between the lines
- Skill libraries could be built incrementally from cheap initial generations rather than expert authoring.
- The separation of diagnostic traces from executor-specific code may allow skills to be reused in new agent architectures.
- If repair principles prove general, the same memory could support revision in domains beyond the evaluated benchmarks.
Load-bearing premise
Execution traces contain enough diagnostic information to identify specific skill defects and that retrieved repair principles can be applied to produce edits that reliably improve verifier passage rates within the revision budget.
What would settle it
Running SkillRevise on SkillsBench yields no increase in base agent success rate above the 36.05% one-shot baseline across the tested LLMs.
Figures



read the original abstract
Agent skills are procedural artifacts that enable LLM agents to execute workflows, verify constraints, and recover from failures. Existing self-evolving methods refine skills using accumulated trajectories. However, they struggle in cold-start settings, where only an initial, imperfect skill is available. Consequently, skill construction defaults to expert authoring or one-shot LLM generation. Expert-authored skills are costly and may not align with how LLM agents actually execute tasks, while one-shot generated skills can be syntactically well formed yet behaviorally weak. To bridge this gap, we propose SkillRevise, an execution-grounded framework designed to iteratively refine these initial skills. SkillRevise diagnoses skill defects from execution evidence, retrieves relevant repair principles from a general memory, and applies execution-anchored edits. By re-executing candidates, it retains the first verifier-passing skill within the revision budget and falls back to empirical utility only when no candidate succeeds. Evaluated across three benchmarks and five LLMs, SkillRevise substantially outperforms one-shot baselines, improving the base agent's success rate on SkillsBench from 36.05% to 61.63%. Furthermore, the revised skills transfer across both executors and task environments, suggesting that SkillRevise captures reusable procedural knowledge beyond any single executor.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkillRevise, an execution-grounded iterative framework that diagnoses defects in initial LLM-generated agent skills from execution traces, retrieves repair principles from memory, applies anchored edits, and retains the first verifier-passing candidate within a revision budget (falling back to empirical utility otherwise). It claims this yields substantial gains over one-shot LLM generation, raising base-agent success on SkillsBench from 36.05% to 61.63% across three benchmarks and five LLMs, with transfer to new executors and task environments.
Significance. If the reported gains are shown to stem from trace-conditioned diagnosis rather than un-controlled search effort, the approach would offer a practical route to improving cold-start agent skills without expert authoring or large trajectory corpora, and the transfer results would indicate reusable procedural knowledge.
major comments (3)
- [Experimental evaluation / SkillsBench results] Experimental section (and any associated tables/figures reporting the 36.05% → 61.63% delta): the manuscript must explicitly state the total LLM calls, re-execution trials, and verifier invocations allotted to the one-shot baseline versus SkillRevise; without this control the headline improvement cannot be attributed to the trace-diagnosis + repair-principle mechanism rather than simply receiving a larger revision budget.
- [SkillRevise framework / revision algorithm] Method description of the revision loop: the paper should quantify or bound the diagnostic information present in the execution traces (e.g., failure modes captured, granularity of retrieved principles) and demonstrate that the observed verifier-pass rate improvements exceed what would be expected from random re-sampling within the same budget.
- [Transferability results] Transfer experiments: the claim that revised skills transfer across executors and environments requires an ablation showing that the transferred skills outperform both the original one-shot skills and skills revised under the target executor, to confirm that the improvement is not executor-specific.
minor comments (2)
- [Method] Notation for the revision budget, verifier, and memory contents should be introduced with explicit symbols and a small pseudocode block for reproducibility.
- [Abstract / Introduction] The abstract and introduction should cite the exact number of revision attempts or LLM calls used in the one-shot baseline for direct comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for explicit computational controls and targeted ablations. We address each major comment below and commit to revisions that strengthen the attribution of gains to the trace-conditioned mechanism.
read point-by-point responses
-
Referee: [Experimental evaluation / SkillsBench results] Experimental section (and any associated tables/figures reporting the 36.05% → 61.63% delta): the manuscript must explicitly state the total LLM calls, re-execution trials, and verifier invocations allotted to the one-shot baseline versus SkillRevise; without this control the headline improvement cannot be attributed to the trace-diagnosis + repair-principle mechanism rather than simply receiving a larger revision budget.
Authors: We agree that explicit budget controls are required to isolate the contribution of trace diagnosis and repair principles. In the revised manuscript we will add a dedicated subsection and table reporting the exact counts of LLM calls, re-execution trials, and verifier invocations used by the one-shot baseline and by SkillRevise under identical revision budgets. This will make clear that SkillRevise does not receive additional search effort beyond the controlled budget. revision: yes
-
Referee: [SkillRevise framework / revision algorithm] Method description of the revision loop: the paper should quantify or bound the diagnostic information present in the execution traces (e.g., failure modes captured, granularity of retrieved principles) and demonstrate that the observed verifier-pass rate improvements exceed what would be expected from random re-sampling within the same budget.
Authors: We will expand the method section to categorize and bound the diagnostic content of traces (e.g., by enumerating captured failure modes such as precondition violations, state mismatches, and recovery gaps, together with the granularity of retrieved repair principles). We will also add an ablation that replaces the principle-retrieval step with random edit sampling under the identical revision budget and verifier budget, demonstrating that the observed pass-rate gains exceed those from random re-sampling. revision: yes
-
Referee: [Transferability results] Transfer experiments: the claim that revised skills transfer across executors and environments requires an ablation showing that the transferred skills outperform both the original one-shot skills and skills revised under the target executor, to confirm that the improvement is not executor-specific.
Authors: We acknowledge that the current transfer results would be strengthened by the requested ablation. In the revision we will report additional experiments in which skills revised by SkillRevise on the source executor are compared, when transferred to the target executor, against both the original one-shot skills and skills that were revised directly on the target executor. This will confirm that the procedural knowledge is reusable rather than executor-specific. revision: yes
Circularity Check
No circularity; purely empirical claims with no derivations or self-referential reductions.
full rationale
The paper presents SkillRevise as an empirical framework for iterative skill revision using execution traces and repair principles, evaluated via benchmark success rates (e.g., SkillsBench improvement from 36.05% to 61.63%). No equations, mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. All claims rest on external benchmark comparisons rather than any reduction to the method's own inputs by construction. The skeptic concern about revision budget vs. baseline is an experimental-design issue, not circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Execution traces supply sufficient evidence to diagnose concrete skill defects
- domain assumption A general memory of repair principles exists and can be retrieved to produce effective edits
Reference graph
Works this paper leans on
-
[1]
2025 , howpublished =
Agent Skills , author =. 2025 , howpublished =
2025
-
[2]
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications
A Comprehensive Survey on Agent Skills: Taxonomy, Techniques, and Applications , author =. 2026 , eprint =. doi:10.48550/arXiv.2605.07358 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2605.07358 2026
-
[3]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks , author =. 2026 , eprint =. doi:10.48550/arXiv.2602.12670 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.12670 2026
-
[4]
How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings
How Well Do Agentic Skills Work in the Wild: Benchmarking LLM Skill Usage in Realistic Settings , author =. 2026 , eprint =. doi:10.48550/arXiv.2604.04323 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.04323 2026
-
[5]
SWE-Skills-Bench: Do Agent Skills Actually Help in Real-World Software Engineering? , author =. 2026 , eprint =. doi:10.48550/arXiv.2603.15401 , url =
-
[6]
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
SkillX: Automatically Constructing Skill Knowledge Bases for Agents , author =. 2026 , eprint =. doi:10.48550/arXiv.2604.04804 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.04804 2026
-
[7]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning , author =. 2026 , eprint =. doi:10.48550/arXiv.2602.08234 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.08234 2026
-
[8]
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents
Skill-Pro: Learning Reusable Skills from Experience via Non-Parametric PPO for LLM Agents , author =. 2026 , eprint =. doi:10.48550/arXiv.2602.01869 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.01869 2026
-
[9]
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents , author =. 2026 , eprint =. doi:10.48550/arXiv.2602.02474 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02474 2026
-
[10]
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver
SkillClaw: Let Skills Evolve Collectively with Agentic Evolver , author =. 2026 , eprint =. doi:10.48550/arXiv.2604.08377 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.08377 2026
-
[11]
AutoSkill: Experience-Driven Lifelong Learning via Skill Self-Evolution , author =. 2026 , eprint =. doi:10.48550/arXiv.2603.01145 , url =
-
[12]
EvoSkill: Automated Skill Discovery for Multi-Agent Systems
EvoSkill: Automated Skill Discovery for Multi-Agent Systems , author =. 2026 , eprint =. doi:10.48550/arXiv.2603.02766 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2603.02766 2026
-
[13]
2026 , eprint =
MEMLENS: Benchmarking Multimodal Long-Term Memory in Large Vision-Language Models , author =. 2026 , eprint =
2026
-
[14]
Qwen3 Technical Report , author =. 2025 , eprint =. doi:10.48550/arXiv.2505.09388 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[15]
Kimi K2: Open Agentic Intelligence
Kimi K2: Open Agentic Intelligence , author =. 2025 , eprint =. doi:10.48550/arXiv.2507.20534 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.20534 2025
-
[16]
2026 , month =
Claude Opus 4.7 System Card , howpublished =. 2026 , month =
2026
-
[17]
2025 , eprint =. doi:10.48550/arXiv.2601.03267 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.03267 2025
-
[18]
2026 , howpublished =
DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence , author =. 2026 , howpublished =
2026
-
[19]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning , author =. 2020 , eprint =. doi:10.48550/arXiv.2010.03768 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2010.03768 2020
-
[20]
2026 , eprint =
SkillLearnBench: Benchmarking Continual Learning Methods for Agent Skill Generation on Real-World Tasks , author =. 2026 , eprint =
2026
-
[21]
AgentVista: Evaluating Multimodal Agents in Ultra-Challenging Realistic Visual Scenarios , author =. 2026 , eprint =. doi:10.48550/arXiv.2602.23166 , url =
-
[22]
The Tool Decathlon: Benchmarking Language Agents for Diverse, Realistic, and Long-Horizon Task Execution , author =. 2025 , eprint =. doi:10.48550/arXiv.2510.25726 , url =
-
[23]
2025 , eprint =
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory , author =. 2025 , eprint =
2025
-
[24]
2025 , eprint =
MemP: Exploring Agent Procedural Memory , author =. 2025 , eprint =
2025
-
[25]
2025 , eprint =
EvolveR: Self-Evolving LLM Agents Through an Experience-Driven Lifecycle , author =. 2025 , eprint =
2025
-
[26]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
ExpeL: LLM Agents Are Experiential Learners , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2024 , url =
2024
-
[27]
DeepSeek-V3 Technical Report , author =. 2024 , eprint =. doi:10.48550/arXiv.2412.19437 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437 2024
-
[28]
2025 , eprint =
Group-in-Group Policy Optimization for LLM Agent Training , author =. 2025 , eprint =
2025
-
[29]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =
ReflAct: World-Grounded Decision Making in LLM Agents via Goal-State Reflection , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages =. 2025 , doi =
2025
-
[30]
Advances in Neural Information Processing Systems , volume =
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[31]
2026 , eprint =
SimpleMem: Efficient Lifelong Memory for LLM Agents , author =. 2026 , eprint =
2026
-
[32]
MemGPT: Towards LLMs as Operating Systems
MemGPT: Towards LLMs as Operating Systems , author =. 2023 , eprint =. doi:10.48550/arXiv.2310.08560 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08560 2023
-
[33]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
MemoryBank: Enhancing Large Language Models with Long-Term Memory , author =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2024 , eprint =. doi:10.48550/arXiv.2305.10250 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2305.10250 2024
-
[34]
arXiv preprint arXiv:2410.04444 , year=
Yin, Xunjian and Wang, Xinyi and Pan, Liangming and Lin, Li and Wan, Xiaojun and Wang, William Yang , year =. doi:10.48550/arXiv.2410.04444 , url =. 2410.04444 , archivePrefix =
-
[35]
doi:10.48550/arXiv.2510.24505 , url =
Zong, Qing and Liu, Jiayu and Zheng, Tianshi and Li, Chunyang and Xu, Baixuan and Shi, Haochen and Wang, Weiqi and Wang, Zhaowei and Chan, Chunkit and Song, Yangqiu , year =. doi:10.48550/arXiv.2510.24505 , url =. 2510.24505 , archivePrefix =
-
[36]
2025 , eprint =
A-MEM: Agentic Memory for LLM Agents , author =. 2025 , eprint =
2025
-
[37]
2025 , eprint =
Live-SWE-agent: Can Software Engineering Agents Self-Evolve on the Fly? , author =. 2025 , eprint =
2025
-
[38]
2025 , eprint =
Mem1: Learning to Synergize Memory and Reasoning for Efficient Long-Horizon Agents , author =. 2025 , eprint =
2025
-
[39]
arXiv preprint arXiv:2603.12056 , year=
XSkill: Continual Learning from Experience and Skills in Multimodal Agents , author =. 2026 , eprint =. doi:10.48550/arXiv.2603.12056 , url =
-
[40]
2026 , eprint =
SkillReducer: Optimizing LLM Agent Skills for Token Efficiency , author =. 2026 , eprint =
2026
-
[41]
2026 , eprint =
SkillCraft: Can LLM Agents Learn to Use Tools Skillfully? , author =. 2026 , eprint =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.