The World's Fastest Matching Engine Algorithm
Pith reviewed 2026-06-28 16:32 UTC · model grok-4.3
The pith
Priority-Indicated Nodes let a single CPU core match 32 million orders per second at sub-microsecond latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that the Priority-Indicated Node resolves insertion position directly from indicators in O(1) time independent of queue size, while a depth-aware capacity model keeps hot entries in L1, and that neighbor-aware operations on red-black, AVL, and B+-trees attach or remove nodes with O(1) writes plus single-path rebalancing when neighbors are known in advance. These two changes together remove the dominant storage-layer costs of linked-list and balanced-tree order books, enabling a single core to sustain 32 million order messages per second at sub-microsecond median host-path latency and 4.7-11 times the rate of the best open-source engines.
What carries the argument
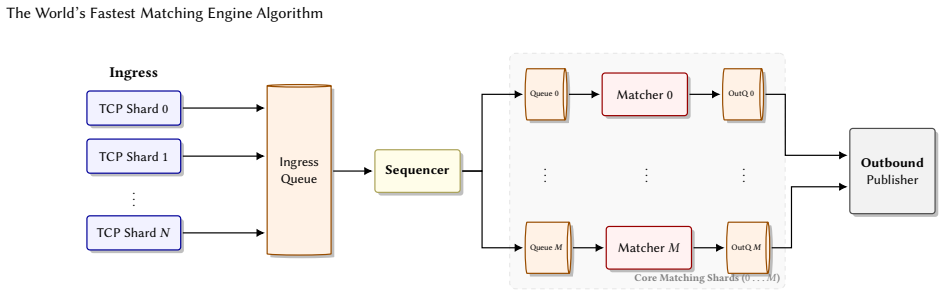
The Priority-Indicated Node (PIN), a priority queue whose entries occupy fixed-capacity contiguous slots whose indicators encode global priority status so that insertion position is read directly without comparisons.
If this is right
- A 96-core commodity server sustains roughly 640 million messages per second across 10,000 symbols.
- This capacity exceeds twenty times the provisioned volume of the U.S. consolidated quote feed.
- Tail-latency spikes under micro-bursts are eliminated, preserving market quality precisely when liquidity demand peaks.
- The neighbor-aware technique works across red-black, AVL, and B+-tree variants without changing their balance invariants.
Where Pith is reading between the lines
- The same fixed-slot indicator approach could accelerate priority scheduling or packet classification in other high-rate real-time systems.
- Production trading platforms might reduce reliance on specialized hardware if these structures prove portable across languages and architectures.
- The assumption that neighbor references arrive at zero cost holds in order matching but would require separate validation in domains where neighbors are not already known.
Load-bearing premise
The reported speedups were measured on identical hardware using representative workloads and fair comparisons to open-source engines, with no undisclosed workload-specific optimizations or post-selection of test conditions.
What would settle it
Re-implementing the PIN and neighbor-aware methods, running them on the same hardware and workloads as the compared open-source engines, and measuring throughput below four times the best baseline would falsify the central performance claim.
Figures


read the original abstract
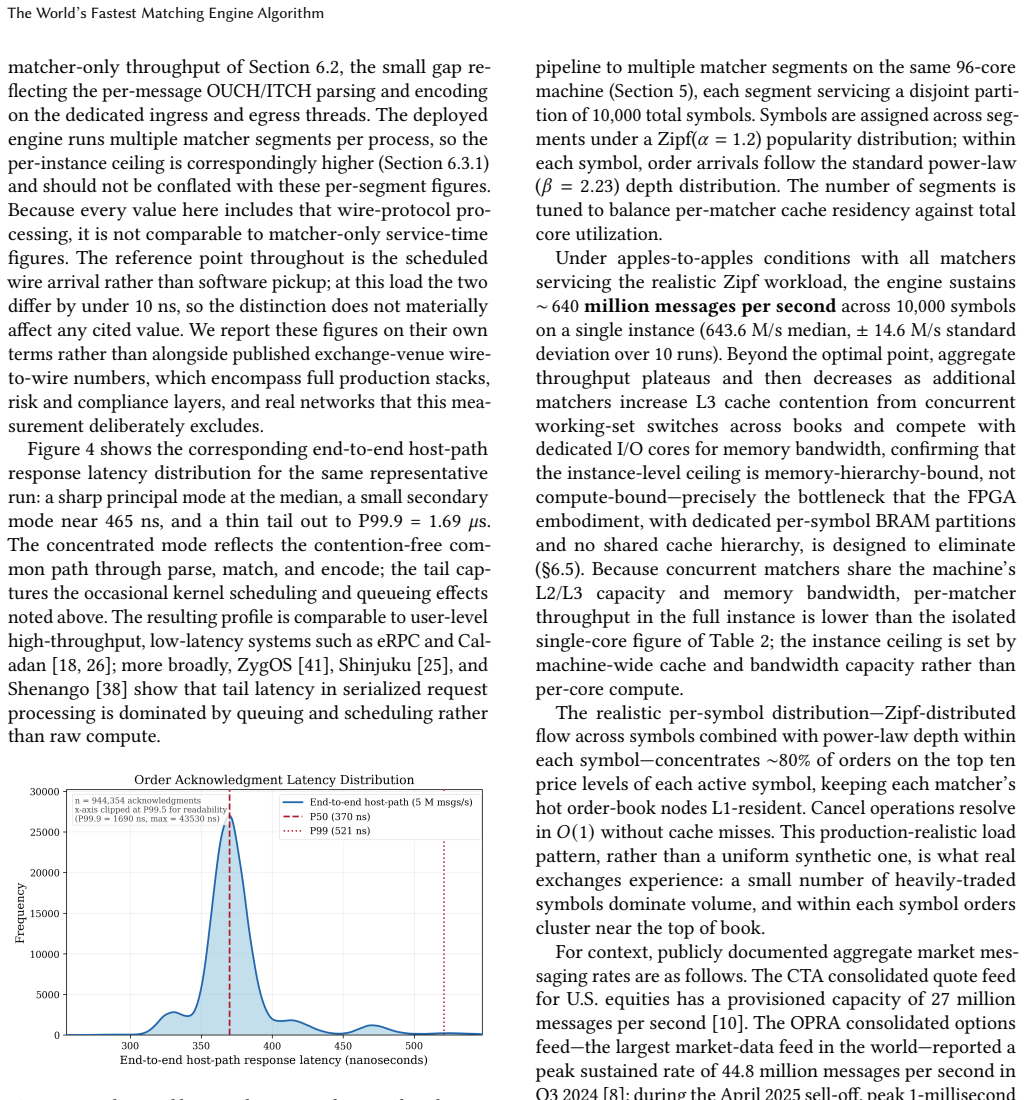
A single CPU core sustains 32 million order messages per second at sub-microsecond median end-to-end host-path response latency, 4.7-11 times faster than the best available open-source matching engines on identical hardware. Scaled out, a single 96-core commodity server (~$1,630/month) sustains ~640 million messages per second across 10,000 symbols, over 20 times the provisioned capacity of the U.S. consolidated quote feed. We reach these numbers by attacking the storage layer that sets matching latency. The dominant order-book implementation, linked lists chained through a balanced tree, imposes two costs on every operation: pointer-chased traversal to the insertion point, and root-to-leaf search to locate the target price level. Under micro-bursts these costs produce tail-latency spikes that degrade market quality precisely when liquidity is most needed. We present two data-structure contributions that eliminate them. The first is the Priority-Indicated Node (PIN), a priority queue in which entries occupy fixed-capacity, contiguously addressable slots, with indicators encoding the entry's global priority status. Unlike heaps, which require O(log n) comparisons per operation, the PIN resolves insertion position directly from the indicators without comparing entries; indicator updates are O(1), independent of queue size. A depth-aware capacity model sizes each PIN so hot entries fit within L1 residency. The second targets a broader inefficiency: balanced search trees search from root to leaf on every insertion and deletion, even when the caller already knows the key's in-order neighbors, which in electronic trading are available at zero cost. Neighbor-aware insertion and deletion use known neighbor references to attach or remove a node with O(1) reference writes, followed by single-path rebalancing, across red-black, AVL, and B+-tree variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents two data-structure innovations for order-book matching engines: the Priority-Indicated Node (PIN), a fixed-capacity priority queue that resolves insertion position from indicators in O(1) time without entry comparisons, and neighbor-aware insertion/deletion for balanced trees (red-black, AVL, B+) that exploit known in-order neighbors to perform O(1) attachment followed by single-path rebalancing. These are claimed to eliminate pointer-chasing and root-to-leaf search costs that cause tail-latency spikes under micro-bursts. Empirically, the resulting engine sustains 32 million order messages per second on a single CPU core at sub-microsecond median latency, 4.7–11× faster than the best open-source engines on identical hardware, scaling to ~640 million messages per second on a 96-core server across 10,000 symbols.
Significance. If the performance numbers are obtained under representative workloads and fair, reproducible comparisons, the result would be a meaningful systems contribution to high-frequency trading infrastructure, directly addressing tail-latency degradation during liquidity stress. The PIN construction and neighbor-aware tree updates are concrete algorithmic advances that could transfer to other priority-queue and ordered-set workloads; the depth-aware capacity model for L1 residency is a practical engineering insight. The manuscript supplies no machine-checked proofs or parameter-free derivations, but the empirical scaling claim (20× U.S. consolidated quote feed capacity on commodity hardware) is falsifiable and therefore valuable if the methodology is fully documented.
major comments (2)
- [Evaluation] Evaluation section (and abstract): the central performance claims (32 M msg/s single-core, 4.7–11× speedup, 640 M msg/s scaled) are presented without any description of the workload traces, the exact list of compared open-source engines, how micro-bursts were generated, hardware micro-architecture details, number of trials, error bars, or measurement methodology for end-to-end host-path latency. Because these details are load-bearing for the headline speedup factor, the empirical contribution cannot be assessed or reproduced from the manuscript as written.
- [§3] §3 (PIN data structure): the claim that indicator updates are O(1) independent of queue size and that insertion position is resolved directly from indicators without comparisons is central to the latency argument, yet the manuscript provides no pseudocode or walk-through showing how the fixed-capacity slots and priority indicators interact under concurrent or high-contention updates; without this, it is impossible to verify that the structure avoids the O(log n) comparisons of a standard heap while preserving correctness.
minor comments (2)
- [Title] The title 'The World's Fastest Matching Engine Algorithm' is stronger than the evidence supplied; a more precise title would better reflect the scope.
- [§3 and §4] Notation for the depth-aware capacity model and the single-path rebalancing invariants should be introduced with a small example or diagram to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that the evaluation methodology requires fuller documentation for reproducibility and that the PIN description would benefit from explicit pseudocode. We will revise the manuscript accordingly to address both points.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and abstract): the central performance claims (32 M msg/s single-core, 4.7–11× speedup, 640 M msg/s scaled) are presented without any description of the workload traces, the exact list of compared open-source engines, how micro-bursts were generated, hardware micro-architecture details, number of trials, error bars, or measurement methodology for end-to-end host-path latency. Because these details are load-bearing for the headline speedup factor, the empirical contribution cannot be assessed or reproduced from the manuscript as written.
Authors: We agree that the current manuscript does not supply the full methodological details needed for independent assessment or reproduction. In the revised version we will expand the Evaluation section (and adjust the abstract) to document: the workload traces (synthetic micro-bursts constructed to emulate liquidity stress plus any real-market data used), the precise list and versions of the open-source engines compared, the procedure used to generate micro-bursts, hardware specifications including CPU model, cache hierarchy and micro-architecture, number of trials performed, statistical reporting (error bars or latency percentiles), and the exact end-to-end host-path latency measurement method. These additions will make the reported speedups verifiable. revision: yes
-
Referee: [§3] §3 (PIN data structure): the claim that indicator updates are O(1) independent of queue size and that insertion position is resolved directly from indicators without comparisons is central to the latency argument, yet the manuscript provides no pseudocode or walk-through showing how the fixed-capacity slots and priority indicators interact under concurrent or high-contention updates; without this, it is impossible to verify that the structure avoids the O(log n) comparisons of a standard heap while preserving correctness.
Authors: We accept that the manuscript currently lacks pseudocode and a concrete walk-through. The revised §3 will include (1) explicit pseudocode for PIN insertion, deletion and indicator maintenance, and (2) a worked example demonstrating how fixed-capacity slots and priority indicators allow direct position resolution in O(1) time without entry comparisons. On concurrency: the design targets the conventional single-threaded-per-order-book model used in matching engines; we will state this assumption explicitly and note that multi-threaded contention would require separate synchronization not covered in the present work. Under the single-threaded model the claimed O(1) indicator updates hold. revision: yes
Circularity Check
No circularity: performance claims are empirical measurements with no derivations or fitted predictions
full rationale
The manuscript describes two new data structures (Priority-Indicated Node and neighbor-aware tree operations) and states measured throughput and latency numbers on hardware. No equations, parameter fits, predictions derived from subsets of data, or self-citations appear in the provided text. The central claims are presented as direct experimental outcomes rather than reductions of any input by construction, satisfying the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Balanced search trees maintain ordering and balance invariants after local updates
invented entities (1)
-
Priority-Indicated Node (PIN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gene M. Amdahl. 1967. Validity of the Single Processor Approach to Achieving Large Scale Computing Capabilities. InProceedings of the April 18–20, 1967, Spring Joint Computer Conference (AFIPS ’67 (Spring)). 483–485. doi:10.1145/1465482.1465560
-
[2]
Matteo Aquilina, Eric Budish, and Peter O’Neill. 2022. Quantifying the High-Frequency Trading “Arms Race”.The Quarterly Journal of Economics137, 1 (February 2022), 493–564. doi:10.1093/qje/qjab032 https://academic.oup.com/qje/article/137/1/493/6368348
-
[3]
BATS Global Markets. 2011. BATS Announces New Real-time Latency Monitoring Service. Technical notice. Accessed 2025- 12-11.https://cdn.cboe.com/resources/release_notes/2011/BATS- Announces-New-Real-time-Latency-Monitoring-Service-Effective- Tuesday-February-1-2011.pdf
2011
-
[4]
Rudolf Bayer and Edward M. McCreight. 1972. Organization and Maintenance of Large Ordered Indexes.Acta Informatica1, 3 (1972), 173–189. doi:10.1007/BF00288683
-
[5]
Adam Belay, George Prekas, Ana Klimovic, Samuel Grossman, Chris- tos Kozyrakis, and Edouard Bugnion. 2014. IX: A Protected Dataplane Operating System for High Throughput and Low Latency. InProceed- ings of the 11th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association
2014
-
[6]
Jean-Philippe Bouchaud, Marc Mézard, and Marc Potters
-
[7]
Statistical properties of stock order books: Empirical results and models.Quantitative Finance2, 4 (2002), 251–
2002
-
[8]
doi:10.1088/1469-7688/2/4/301 https://www.cfm.com/wp- content/uploads/2022/12/255-2002-statistical-propertes-of-stock- order-books-empiricals-results-and-model.pdf
-
[9]
Eric Budish, Peter Cramton, and John Shim. 2015. The High-Frequency Trading Arms Race: Frequent Batch Auctions as a Market Design Response.The Quarterly Journal of Economics130, 4 (2015), 1547–1621. doi:10.1093/qje/qjv027 https://academic.oup.com/qje/article/130/4/ 1547/1916146
-
[10]
Cboe Global Markets. 2025. The Necessity of Real-Time Options Data for Retail Participants.https://www.cboe.com/insights/posts/the- necessity-of-real-time-options-data-for-retail-participants/. Q3 2024 OPRA peak message volume of 44.8 million messages per second. Accessed 2025-12-11
2025
-
[11]
Cboe Global Markets. 2025. U.S. Equities Market Volume Summary. Market statistics dashboard. Accessed 2025-12-11.https://www.cboe. com/us/equities/market_share/
2025
-
[12]
Consolidated Tape Association. 2025. Consolidated Tape Association: CTA Overview.https://www.ctaplan.com/index. Accessed 2025-12-11
2025
-
[13]
2010.A stochastic model for order book dynamics
Rama Cont, Sasha Stoikov, and Rishi Talreja. 2010.A stochastic model for order book dynamics. Technical Report. Columbia University.https: //www.columbia.edu/~ww2040/orderbook.pdf
2010
-
[14]
Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest, and Clifford Stein. 2022.Introduction to Algorithms(4 ed.). The MIT Press.https://mitpress.mit.edu/9780262046305/introduction- to-algorithms/
arXiv 2022
-
[15]
Databento. 2025. What is the Options Price Reporting Authority (OPRA)?https://databento.com/microstructure/opra. April 2025 peak 1-millisecond bursts exceeding 187 million messages per second. Accessed 2025-06-01
2025
-
[16]
Deutsche Börse Group. 2016. Xetra Trading System: Xetra In- sights. Technical presentation. Accessed 2025-12-11.https: //www.cashmarket.deutsche-boerse.com/resource/blob/307522/ 5a13437b23985d15540ab20c28893f60/data/Xetra_Insights.pdf
2016
-
[17]
Deutsche Börse Group. 2025. Insights into Trading System Dynamics: Deutsche Börse’s T7. Technical presentation. Ac- cessed 2025-12-11.https://www.eurex.com/resource/blob/48918/ e8d4df56f75c9a96fb0f6fff6b18a14f/data/presentation_insights-into- trading-system-dynamics_en.pdf
2025
-
[18]
Aleksandar Dragojević, Dushyanth Narayanan, Orion Hodson, and Miguel Castro. 2014. FaRM: Fast Remote Memory. InProceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI). USENIX Association
2014
-
[19]
Eurex Exchange. 2024. Publication of T7 Documentation: In- sights into Trading System Dynamics. Implementation News. https://www.eurex.com/ex-en/support/information-channels/ implementation-news/Publication-of-T7-Documentation-4042720
2024
-
[20]
Joshua Fried, Zhenyuan Ruan, Amy Ousterhout, and Adam Belay
-
[21]
InProceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
Caladan: Mitigating Interference at Microsecond Timescales. InProceedings of the 14th USENIX Symposium on Operating Systems Design and Implementation (OSDI). USENIX Association
-
[22]
Fujitsu Limited and Tokyo Stock Exchange, Inc. 2015. New, En- hanced TSEarrowheadCash Equity Trading System — For a Safer, More Convenient Market. Press release. Accessed 2025- 12-11.https://www.fujitsu.com/global/about/resources/news/press- releases/2015/0924-01.html
2015
-
[23]
Igal Galperin and Ronald L. Rivest. 1993. Scapegoat Trees. InProceed- ings of the Fourth Annual ACM-SIAM Symposium on Discrete Algo- rithms (SODA). SIAM, 165–174.https://people.csail.mit.edu/rivest/ pubs/GR93.pdf
1993
-
[24]
Martin D. Gould, Mason A. Porter, Stacy Williams, Mark McDon- ald, Daniel J. Fenn, and Sam D. Howison. 2013. Limit order books. Quantitative Finance13, 11 (2013), 1709–1742. doi:10.1080/14697688. 2013.803148 https://www.math.ucla.edu/~mason/papers/gould-qf- final.pdf
-
[25]
Leo J. Guibas and Robert Sedgewick. 1978. A Dichromatic Framework for Balanced Trees. InProceedings of the 19th Annual Symposium on Foundations of Computer Science (FOCS). 8–21. doi:10.1109/SFCS.1978.3
-
[26]
Japan Exchange Group, Inc. 2016. JPX Report 2016. Integrated report. Accessed 2025-12-11.https://www.jpx.co.jp/english/corporate/ investor-relations/ir-library/integrated-report/tvdivq0000008t9q- att/JPXreport2016e_all.pdf
2016
-
[27]
Ivan Jericevich, Dharmesh Sing, and Tim Gebbie. 2022. CoinTossX: An open-source low-latency high-throughput matching engine.Soft- wareX19 (2022), 101136. doi:10.1016/j.softx.2022.101136
-
[28]
Kostis Kaffes, Timothy Chong, Jack Tigar Humphries, Adam Belay, David Mazières, and Christos Kozyrakis. 2019. Shinjuku: Preemptive Scheduling forµsecond-Scale Tail Latency. InProceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI). USENIX Association, 345–360
2019
-
[29]
Andersen
Anuj Kalia, Michael Kaminsky, and David G. Andersen. 2019. Datacen- ter RPCs Can Be General and Fast. InProceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI). USENIX Association. Best Paper Award
2019
-
[31]
Marta Khomyn and T ¯alis J. Putni ¯nš. 2021. Algos gone wild: What drives the extreme order cancellation rates in modern markets?Jour- nal of Banking & Finance129 (2021), 106170. doi:10.1016/j.jbankfin. 2021.106170
-
[32]
Sida Li, Mao Ye, and Miles Zheng. 2023. Refusing the Best Price? Journal of Financial Economics147, 2 (2023), 317–337. doi:10.1016/j. jfineco.2022.11.004
work page doi:10.1016/j 2023
-
[33]
Andersen, and Michael Kamin- sky
Hyeontaek Lim, Dongsu Han, David G. Andersen, and Michael Kamin- sky. 2014. MICA: A Holistic Approach to Fast In-Memory Key-Value Storage. InProceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI). USENIX Association, 429– 444
2014
-
[34]
Yandong Mao, Eddie Kohler, and Robert Tappan Morris. 2012. Cache Craftiness for Fast Multicore Key-Value Storage. InProceedings of the 7th ACM European Conference on Computer Systems (EuroSys). ACM, 19 Jake Yoon 183–196
2012
-
[35]
Albert J. Menkveld. 2018. High-Frequency Trading as Viewed through an Electron Microscope.Financial Analysts Journal74, 2 (2018), 24–31. doi:10.2469/faj.v74.n2.1Also available via SSRN (doi:10.2139/ssrn.2875612)
-
[36]
Ioane Muni Toke. 2013. The order book as a queueing system: av- erage depth and influence of the size of limit orders. arXiv preprint arXiv:1311.5661.https://arxiv.org/abs/1311.5661
Pith/arXiv arXiv 2013
-
[37]
Hamish Murray, Thu Phuong Pham, and Harminder Singh. 2016. La- tency reduction and market quality: The case of the Australian Stock Exchange.International Review of Financial Analysis46 (2016), 257–265. doi:10.1016/j.irfa.2015.09.001
-
[38]
Nasdaq, Inc. 2024. Reimagining the Markets of Tomorrow: U.S. Equity Market Data. Whitepaper.https://www.nasdaq.com/docs/2024/US_ Equity_Market_Data_Whitepaper
2024
-
[39]
Object Computing, Inc. 2013. Liquibook: An Open Source C++ Order Matching Engine. GitHub repository. Accessed 2025-12-11.https: //github.com/ObjectComputing/liquibook
2013
-
[40]
2021.Characterization of High-Speed Trading
Atsuyuki Ohyama, Yoshitaka Fukuyama, Shintaro Okude, and Kenta Suzuki. 2021.Characterization of High-Speed Trading. Techni- cal Report. Financial Services Agency (Japan). Accessed 2025- 12-11.https://www.fsa.go.jp/frtc/english/seika/srhonbun/20210707_ Characterization_of_high_speed_tradingEN.pdf
arXiv 2021
-
[41]
Amy Ousterhout, Joshua Fried, Jonathan Behrens, Adam Belay, and Hari Balakrishnan. 2019. Shenango: Achieving High CPU Efficiency for Latency-Sensitive Datacenter Workloads. InProceedings of the 16th USENIX Symposium on Networked Systems Design and Implementation (NSDI). USENIX Association, 361–378
2019
-
[42]
Simon Peter, Jialin Li, Irene Zhang, Dan R. K. Ports, Doug Woos, Arvind Krishnamurthy, Thomas Anderson, and Timothy Roscoe. 2014. Arrakis: The Operating System is the Control Plane. InProceedings of the 11th USENIX Symposium on Operating Systems Design and Imple- mentation (OSDI). USENIX Association
2014
-
[43]
PostgreSQL Global Development Group. 2024. Database Page Layout. PostgreSQL Documentation, Chapter 66.https://www.postgresql.org/ docs/current/storage-page-layout.html
2024
-
[44]
George Prekas, Marios Kogias, and Edouard Bugnion. 2017. ZygOS: Achieving Low Tail Latency for Microsecond-Scale Networked Tasks. InProceedings of the 26th ACM Symposium on Operating Systems Prin- ciples (SOSP). ACM, 325–341
2017
-
[45]
QuantCup 1 Contest. 2011. Price–Time Matching Engine (Winning Implementation). GitHub Gist.https://gist.github.com/druska/ d6ce3f2bac74db08ee9007cdf98106ef
2011
-
[46]
Zia Ur Rahman. 2021. limit-order-book: Fast, Multi-threaded Trade Matching Engine. GitHub repository.https://github.com/ziaagikian/ limit-order-book
2021
-
[47]
Sepideh Roghanchi, Jakob Eriksson, and Nilanjana Basu. 2017. Ffwd: Delegation Is (Much) Faster Than You Think. InProceedings of the 26th ACM Symposium on Operating Systems Principles (SOSP). ACM, 342–358
2017
-
[48]
W. K. Selph. 2011. How to Build a Fast Limit Order Book. Blog post.https://web.archive.org/web/20110219163448/http://howtohft. wordpress.com/2011/02/15/how-to-build-a-fast-limit-order-book/
arXiv 2011
-
[49]
Sergej Teverovski. 2023. Open Day 2023: T7 – Latency Roadmap. Deutsche Börse Group presentation. Accessed 2025-12- 11.https://www.deutsche-boerse.com/resource/blob/3690194/ fe6b01b1e14800eb40374a95516debf2/data/Open%20Day%202023% 20-%20Presentation,%20T7-Latency%20Roadmap.pdf
arXiv 2023
-
[50]
Stephen Tu, Wenting Zheng, Eddie Kohler, Barbara Liskov, and Samuel Madden. 2013. Speedy Transactions in Multicore In-Memory Databases. InProceedings of the 24th ACM Symposium on Operating Systems Principles (SOSP). ACM, 18–32
2013
-
[51]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. 2005. 17 CFR § 242.611 — Order Protection Rule (Regulation NMS Rule 611). Code of Federal Regulations.https://www.ecfr.gov/current/title-17/chapter-II/part- 242/subject-group-ECFRac68bdd026a46db/section-242.611
2005
-
[52]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. 2013. Quote Lifetime Distri- butions (Data Highlight 2013-04). SEC Market Structure Research. Last reviewed Aug. 16, 2022.https://www.sec.gov/about/quote-lifetime- distributions
2013
-
[53]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. 2015. Memorandum: Rule 611 of Regulation NMS. SEC staff memo.https://www.sec. gov/spotlight/emsac/memo-rule-611-regulation-nms.pdf
2015
-
[54]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. 2022. Trade to Or- der Volume Ratios. SEC Data Visualizations. Updated Aug. 6, 2025.https://www.sec.gov/data-research/statistics-data- visualizations/trade-order-volume-ratios
2022
-
[55]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. 2025. Quote Life: Large Stocks (Conditional Frequency, Q1 2025). SEC Market Structure Data Visualizations.https://www.sec.gov/marketstructure/datavis/ quotelife_stocks_lg.html
2025
-
[56]
Maksim Zheravin. 2019. Exchange-core: Ultra-fast matching engine. GitHub repository.https://github.com/exchange-core/exchange-core
2019
-
[57]
The power of patience: A behavioral regularity in limit order placement
Ilija I. Zovko and J. Doyne Farmer. 2002. The power of patience: A behavioral regularity in limit order placement.Quantitative Finance 2, 5 (2002), 387–392. doi:10.1088/1469-7688/2/5/308 https://arxiv.org/ abs/cond-mat/0206280. 20
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1088/1469-7688/2/5/308 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.