SpeechEditBench: A Bilingual Multi-Attribute Benchmark for Instruction-Guided Speech Editing
Pith reviewed 2026-06-28 12:52 UTC · model grok-4.3
The pith
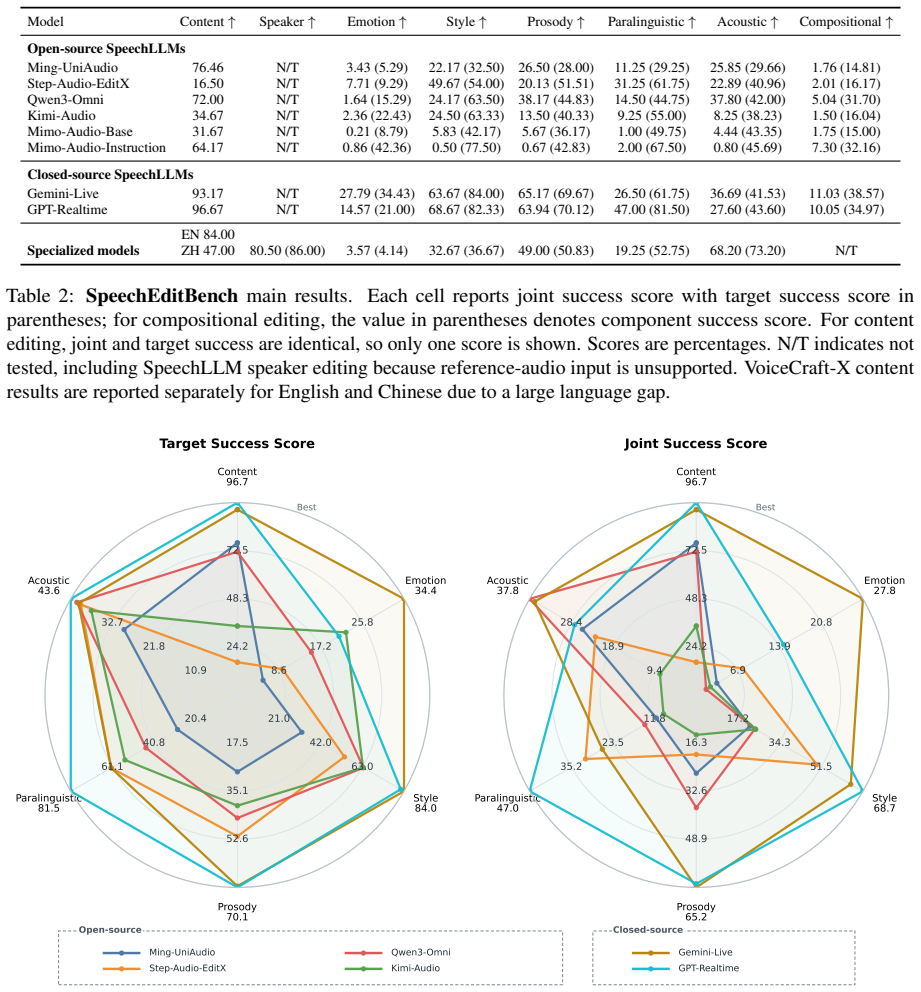
SpeechEditBench shows no single Speech LLM performs well across all instruction-guided editing dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SpeechEditBench supplies a unified testbed for instruction-guided speech editing that separates target-attribute success from untargeted-attribute preservation through its anchor-based protocol. Evaluation under this protocol establishes that closed-source Speech LLMs generally outperform open-source models, that performance varies sharply across editing dimensions so that no single model dominates all tasks, and that compositional instructions remain especially difficult, with even the best models recording low joint success rates.
What carries the argument
The anchor-based evaluation protocol, which isolates success on the instructed attributes from success on the uninstructed attributes to produce the three metrics of target success, preservation success, and joint success.
If this is right
- Model developers can use the three separate metrics to isolate whether failures stem from poor editing or from unintended side effects.
- Compositional editing will require architectures or training methods that maintain attribute independence when multiple instructions are given together.
- Closed-source performance advantages point to the value of scaling data or compute that open-source efforts have not yet matched.
- The benchmark supplies a repeatable way to track progress on the hardest subset of tasks rather than isolated single-attribute edits.
Where Pith is reading between the lines
- Models that treat speech attributes as independent channels may need explicit training signals that penalize cross-attribute leakage.
- The same separation of target and preservation success could be applied to instruction editing in other modalities such as text or video.
- Low joint success on compositional cases suggests that current next-token or diffusion objectives do not yet enforce global consistency across multiple edit constraints.
Load-bearing premise
The anchor-based protocol measures target success and preservation success without systematic bias introduced by anchor selection or protocol design.
What would settle it
A concrete run in which one or more models reach high joint success on the compositional subset of SpeechEditBench, or in which changing the choice of anchors produces large shifts in the reported metric values.
Figures


read the original abstract
Instruction-guided speech editing requires a model to modify specified speech attributes while preserving unrelated characteristics. Despite rapid progress in Speech Large Language Models (Speech LLMs), systematic evaluation of this capability remains challenging, as existing benchmarks are fragmented across isolated editing tasks. To bridge this gap, we introduce SpeechEditBench, a bilingual multi-attribute benchmark for instruction-guided speech editing. SpeechEditBench encompasses seven atomic editing tasks, as well as compositional editing tasks that integrate multiple operations within a single instruction. We propose an anchor-based evaluation protocol that separately assesses the edit success of target attributes and the preservation of untargeted attributes, leading to three metrics: target success, preservation success, and joint success. Using this benchmark, we evaluate mainstream Speech LLMs and specialized speech editing systems. The results reveal three key findings: (1) no single model performs well across all editing dimensions; (2) closed-source Speech LLMs generally outperform open-source models; (3) compositional editing remains highly challenging, with even the most advanced models struggling to achieve high joint success. SpeechEditBench provides a rigorous diagnostic framework to identify bottlenecks in Speech LLMs, thereby facilitating the development of next-generation Speech LLMs with more robust and precise instruction-guided editing capabilities. Data and code are avaialble at https://github.com/daxintan-cuhk/SpeechEditBench .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SpeechEditBench, a bilingual benchmark for instruction-guided speech editing comprising seven atomic tasks plus compositional multi-attribute tasks. It defines an anchor-based evaluation protocol that produces three metrics (target success, preservation success, and joint success) and uses them to evaluate mainstream Speech LLMs and specialized editing systems. The reported results are that no single model excels across all editing dimensions, closed-source models generally outperform open-source models, and compositional editing remains highly challenging even for the strongest systems.
Significance. A well-validated multi-attribute, bilingual benchmark with separate assessment of edit success and preservation would address a genuine gap in fragmented existing evaluations and could serve as a useful diagnostic for Speech LLM development. The compositional-editing focus is a timely strength if the metrics prove reliable.
major comments (2)
- [anchor-based evaluation protocol] The anchor-based evaluation protocol (abstract and the section describing the protocol) is load-bearing for all three key findings yet supplies no information on anchor selection criteria, number of anchors, whether anchors are model-agnostic or attribute-balanced, or any validation against bias. Without such controls the reported performance gaps and the claim of compositional difficulty cannot be considered reliable.
- [results section] No error analysis, ablation on anchor choice, or inter-annotator / inter-anchor agreement statistics are presented to confirm that the three metrics are not confounded by anchor design or data-construction artifacts (abstract states the protocol but the results section provides only aggregate scores).
minor comments (2)
- [abstract] Typo in abstract: 'avaialble' should read 'available'.
- [benchmark construction] The benchmark-construction details (how utterances and instructions were collected, how bilingual balance was ensured, and any potential confounds) are referenced only at high level; a dedicated subsection with explicit statistics would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on our manuscript. We address each major comment below and will incorporate the necessary revisions to strengthen the paper.
read point-by-point responses
-
Referee: [anchor-based evaluation protocol] The anchor-based evaluation protocol (abstract and the section describing the protocol) is load-bearing for all three key findings yet supplies no information on anchor selection criteria, number of anchors, whether anchors are model-agnostic or attribute-balanced, or any validation against bias. Without such controls the reported performance gaps and the claim of compositional difficulty cannot be considered reliable.
Authors: We acknowledge the referee's concern that the current description of the anchor-based evaluation protocol lacks sufficient detail on key aspects such as selection criteria and bias validation. In the revised manuscript, we will expand the protocol description section to include: (1) explicit anchor selection criteria, (2) the number of anchors used, (3) confirmation of model-agnostic and attribute-balanced selection, and (4) any validation performed to assess bias. These additions will support the reliability of the reported findings. revision: yes
-
Referee: [results section] No error analysis, ablation on anchor choice, or inter-annotator / inter-anchor agreement statistics are presented to confirm that the three metrics are not confounded by anchor design or data-construction artifacts (abstract states the protocol but the results section provides only aggregate scores).
Authors: We agree that the results section would benefit from additional analyses to validate the metrics. We will add an error analysis, an ablation study examining the impact of anchor choice, and inter-anchor agreement statistics. These will help confirm that the metrics are not confounded by design artifacts. The revised results section will include these elements alongside the aggregate scores. revision: yes
Circularity Check
No circularity: benchmark and metrics introduced independently of results
full rationale
The paper introduces SpeechEditBench and an anchor-based evaluation protocol that defines target success, preservation success, and joint success as new metrics. All reported findings are empirical outcomes from applying these metrics to external models. No equations, parameter fits presented as predictions, or self-citation chains appear in the provided text. The protocol is presented as a definitional framework rather than derived from the evaluation outcomes themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The anchor-based evaluation protocol accurately and independently measures target attribute edit success versus preservation of untargeted attributes.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Imagen editor and editbench: Advancing and evaluating text-guided image inpainting , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[2]
arXiv preprint arXiv:2310.02426 , year=
Editval: Benchmarking diffusion based text-guided image editing methods , author=. arXiv preprint arXiv:2310.02426 , year=
-
[3]
Advances in Neural Information Processing Systems , volume=
I2ebench: A comprehensive benchmark for instruction-based image editing , author=. Advances in Neural Information Processing Systems , volume=
-
[4]
arXiv preprint arXiv:2504.13143 , year=
Complex-Edit: CoT-Like Instruction Generation for Complexity-Controllable Image Editing Benchmark , author=. arXiv preprint arXiv:2504.13143 , year=
-
[5]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
EditInspector: A Benchmark for Evaluation of Text-Guided Image Edits , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[6]
arXiv preprint arXiv:2505.11493 , year=
Gie-bench: Towards grounded evaluation for text-guided image editing , author=. arXiv preprint arXiv:2505.11493 , year=
-
[7]
How Well Do Models Follow Visual Instructions? VIBE: A Systematic Benchmark for Visual Instruction-Driven Image Editing , author=. arXiv preprint arXiv:2602.01851 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2508.18159 , year=
SpotEdit: Evaluating Visually-Guided Image Editing Methods , author=. arXiv preprint arXiv:2508.18159 , year=
-
[9]
Transactions of the Association for Computational Linguistics , volume=
Voicebench: Benchmarking llm-based voice assistants , author=. Transactions of the Association for Computational Linguistics , volume=. 2026 , publisher=
2026
-
[10]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Air-bench: Benchmarking large audio-language models via generative comprehension , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[11]
Audiobench: A universal benchmark for audio large language models , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[12]
arXiv preprint arXiv:2505.15727 , year=
Vocalbench: Benchmarking the vocal conversational abilities for speech interaction models , author=. arXiv preprint arXiv:2505.15727 , year=
-
[13]
MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
Mmsu: A massive multi-task spoken language understanding and reasoning benchmark , author=. arXiv preprint arXiv:2506.04779 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Advances in Neural Information Processing Systems , volume=
Mmar: A challenging benchmark for deep reasoning in speech, audio, music, and their mix , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
arXiv preprint arXiv:2507.19040 , year=
FD-Bench: A Full-Duplex Benchmarking Pipeline Designed for Full Duplex Spoken Dialogue Systems , author=. arXiv preprint arXiv:2507.19040 , year=
-
[16]
arXiv preprint arXiv:2503.04721 , year=
Full-duplex-bench: A benchmark to evaluate full-duplex spoken dialogue models on turn-taking capabilities , author=. arXiv preprint arXiv:2503.04721 , year=
-
[17]
MTR-DuplexBench: Towards a Comprehensive Evaluation of Multi-Round Conversations for Full-Duplex Speech Language Models , author=. arXiv preprint arXiv:2511.10262 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=
Editspeech: A text based speech editing system using partial inference and bidirectional fusion , author=. 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , pages=. 2021 , organization=
2021
-
[19]
arXiv preprint arXiv:2309.11725 , year=
Fluenteditor: Text-based speech editing by considering acoustic and prosody consistency , author=. arXiv preprint arXiv:2309.11725 , year=
-
[20]
IEEE Transactions on Audio, Speech and Language Processing , year=
FluentEditor2: Text-based Speech Editing by Modeling Multi-Scale Acoustic and Prosody Consistency , author=. IEEE Transactions on Audio, Speech and Language Processing , year=
-
[21]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Voicecraft: Zero-shot speech editing and text-to-speech in the wild , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[22]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
VoiceCraft-X: Unifying Multilingual, Voice-Cloning Speech Synthesis and Speech Editing , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[23]
CosyEdit: Unlocking End-to-End Speech Editing Capability from Zero-Shot Text-to-Speech Models
CosyEdit: Unlocking End-to-End Speech Editing Capability from Zero-Shot Text-to-Speech Models , author=. arXiv preprint arXiv:2601.05329 , year=
work page internal anchor Pith review arXiv
-
[24]
arXiv preprint arXiv:2510.04738 , year=
Speak, Edit, Repeat: High-Fidelity Voice Editing and Zero-Shot TTS with Cross-Attentive Mamba , author=. arXiv preprint arXiv:2510.04738 , year=
-
[25]
arXiv preprint arXiv:2511.05516 , year=
Ming-UniAudio: Speech LLM for Joint Understanding, Generation and Editing with Unified Representation , author=. arXiv preprint arXiv:2511.05516 , year=
-
[26]
arXiv preprint arXiv:2511.03601 , year=
Step-Audio-EditX Technical Report , author=. arXiv preprint arXiv:2511.03601 , year=
-
[27]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
ISSE: An Instruction-Guided Speech Style Editing Dataset and Benchmark , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[28]
AST: Adaptive, Seamless, and Training-Free Precise Speech Editing
AST: Adaptive, Seamless, and Training-Free Precise Speech Editing , author=. arXiv preprint arXiv:2604.16056 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
arXiv preprint arXiv:2407.17172 , year=
Speech Editing--a Summary , author=. arXiv preprint arXiv:2407.17172 , year=
-
[30]
Qwen3-omni technical report , author=. arXiv preprint arXiv:2509.17765 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Kimi-audio technical report , author=. arXiv preprint arXiv:2504.18425 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
MiMo-Audio: Audio language models are few-shot learners,
MiMo-Audio: Audio Language Models are Few-Shot Learners , author=. arXiv preprint arXiv:2512.23808 , year=
-
[33]
Step-audio 2 technical report , author=. arXiv preprint arXiv:2507.16632 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Qwen2-audio technical report , author=. arXiv preprint arXiv:2407.10759 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech
Libritts: A corpus derived from librispeech for text-to-speech , author=. arXiv preprint arXiv:1904.02882 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[36]
arXiv preprint arXiv:2010.11567 , year=
Aishell-3: A multi-speaker mandarin tts corpus and the baselines , author=. arXiv preprint arXiv:2010.11567 , year=
-
[37]
ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition , author=. ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2022 , organization=
2022
-
[38]
The Rainbow Passage which the speakers read out can be found in the International Dialects of English Archive:(http://web
CSTR VCTK Corpus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92) , author=. The Rainbow Passage which the speakers read out can be found in the International Dialects of English Archive:(http://web. ku. edu/\. 2019 , publisher=
2019
-
[39]
Language resources and evaluation , volume=
IEMOCAP: Interactive emotional dyadic motion capture database , author=. Language resources and evaluation , volume=. 2008 , publisher=
2008
-
[40]
arXiv preprint arXiv:2508.02038 , year=
Marco-voice technical report , author=. arXiv preprint arXiv:2508.02038 , year=
-
[41]
arXiv preprint arXiv:2507.13155 , year=
Nonverbaltts: A public english corpus of text-aligned nonverbal vocalizations with emotion annotations for text-to-speech , author=. arXiv preprint arXiv:2507.13155 , year=
-
[42]
2024 , eprint=
DisfluencySpeech -- Single-Speaker Conversational Speech Dataset with Paralanguage , author=. 2024 , eprint=
2024
-
[43]
MUSAN: A Music, Speech, and Noise Corpus
Musan: A music, speech, and noise corpus , author=. arXiv preprint arXiv:1510.08484 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
2017 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=
A study on data augmentation of reverberant speech for robust speech recognition , author=. 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP) , pages=. 2017 , organization=
2017
-
[45]
Available: https://arxiv.org/abs/2411.09943
Zero-shot voice conversion with diffusion transformers , author=. arXiv preprint arXiv:2411.09943 , year=
-
[46]
GitHub , year =
VoxCPM2: Tokenizer-Free TTS for Multilingual Speech Generation, Creative Voice Design, and True-to-Life Cloning , author =. GitHub , year =
-
[47]
VoxCPM: Tokenizer-Free TTS for Context-Aware Speech Generation and True-to-Life Voice Cloning , author =. arXiv preprint arXiv:2509.24650 , year =
-
[48]
2025 , howpublished =
2025
-
[49]
arXiv preprint arXiv:2308.05037 , year=
Separate Anything You Describe , author=. arXiv preprint arXiv:2308.05037 , year=
-
[50]
and Maier, Andreas , booktitle=
Schröter, Hendrik and Rosenkranz, Tobias and Escalante-B., Alberto N. and Maier, Andreas , booktitle=
-
[51]
2026 , howpublished =
2026
-
[52]
2024 , institution =
2024
-
[53]
Computational Narrative Understanding for Expressive Text-to-Speech
LibriQuote: A Speech Dataset of Fictional Character Utterances for Expressive Zero-Shot Speech Synthesis , author=. arXiv preprint arXiv:2509.04072 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
arXiv preprint arXiv:2511.00256 , year=
NaturalVoices: A Large-Scale, Spontaneous and Emotional Podcast Dataset for Voice Conversion , author=. arXiv preprint arXiv:2511.00256 , year=
-
[55]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Aishell6-whisper: A chinese mandarin audio-visual whisper speech dataset with speech recognition baselines , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[56]
arXiv preprint arXiv:2203.16844 , year=
Open source magicdata-ramc: A rich annotated mandarin conversational (ramc) speech dataset , author=. arXiv preprint arXiv:2203.16844 , year=
-
[57]
ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Storytts: A highly expressive text-to-speech dataset with rich textual expressiveness annotations , author=. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2024 , organization=
2024
-
[58]
ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
Emilia-NV: A Non-Verbal Speech Dataset with Word-Level Annotation for Human-Like Speech Modeling , author=. ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2026 , organization=
2026
-
[59]
2025 , eprint=
Efficient Scaling for LLM-based ASR , author=. 2025 , eprint=
2025
-
[60]
2025 , eprint=
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis , author=. 2025 , eprint=
2025
-
[61]
International conference on machine learning , pages=
Robust speech recognition via large-scale weak supervision , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[62]
arXiv preprint arXiv:2206.08317 , year=
Paraformer: Fast and accurate parallel transformer for non-autoregressive end-to-end speech recognition , author=. arXiv preprint arXiv:2206.08317 , year=
-
[63]
arXiv preprint arXiv:2305.11013 , year=
Funasr: A fundamental end-to-end speech recognition toolkit , author=. arXiv preprint arXiv:2305.11013 , year=
-
[64]
arXiv preprint arXiv:2204.02152 , year=
Utmos: Utokyo-sarulab system for voicemos challenge 2022 , author=. arXiv preprint arXiv:2204.02152 , year=
-
[65]
IEEE Journal of Selected Topics in Signal Processing , volume=
Wavlm: Large-scale self-supervised pre-training for full stack speech processing , author=. IEEE Journal of Selected Topics in Signal Processing , volume=. 2022 , publisher=
2022
-
[66]
arXiv preprint arXiv:2104.01466 , year=
ECAPA-TDNN embeddings for speaker diarization , author=. arXiv preprint arXiv:2104.01466 , year=
-
[67]
ICASSP , year=
ICASSP 2023 Deep Noise Suppression Challenge , author=. ICASSP , year=
2023
-
[68]
2023 , eprint=
LibriSpeech-PC: Benchmark for Evaluation of Punctuation and Capitalization Capabilities of end-to-end ASR Models , author=. 2023 , eprint=
2023
-
[69]
2019 , eprint=
LibriTTS: A Corpus Derived from LibriSpeech for Text-to-Speech , author=. 2019 , eprint=
2019
-
[70]
2022 , eprint=
Clotho-AQA: A Crowdsourced Dataset for Audio Question Answering , author=. 2022 , eprint=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.