Fully Automated Identification of Lexical Alignment and Preference-Stage Shifts in Large Language Models
Pith reviewed 2026-06-28 10:08 UTC · model grok-4.3
The pith
Two new metrics detect lexical overuse in LLMs and quantify its link to preference learning stages without manual curation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Lexical Alignment Score measures overuse via windowed document prevalence of tokens in model continuations relative to human references, while the Triangulated Preference Shift compares prevalence differences across model checkpoints before and after preference learning to isolate the contribution of that stage.
What carries the argument
Lexical Alignment Score and Triangulated Preference Shift, which quantify token overuse and attribute portions of it to preference learning by comparing generated text prevalence across training stages.
If this is right
- The metrics can be applied at scale to non-scientific domains and additional languages without new manual curation.
- Overused lexical items can be tracked across successive model releases to monitor changes in alignment behavior.
- The procedure replicates earlier manual observations on scientific English while remaining stable across parameter settings and random seeds.
Where Pith is reading between the lines
- If the metrics generalize, they could be used to test whether preference tuning in one domain produces lexical shifts that affect performance in unrelated domains.
- Comparing the Triangulated Preference Shift values across model families might reveal whether certain architectures are more or less sensitive to preference-induced lexical changes.
Load-bearing premise
That windowed document prevalence on generated continuations isolates lexical alignment effects and that observed shifts can be attributed specifically to preference learning rather than other model or data factors.
What would settle it
Running the same procedure on base models before any preference tuning and finding the same set of overused words at comparable rates would falsify the attribution to preference stages.
Figures

read the original abstract
The language used by digital chat assistants such as ChatGPT can diverge from human expectations (misalignment). Research, mostly on Scientific English, has described both what divergences occur and, to some extent, why, linking them to the training stage of human preference learning. Yet, existing approaches rely on manual curation. This paper introduces two curation-free, assumption-light evaluation metrics: the Lexical Alignment Score, which identifies lexical overuse, and the Triangulated Preference Shift, which quantifies how much of such shifts can be attributed to human preference learning. Using PubMed abstracts, continuations were generated and measured using windowed document prevalence across six model families (Falcon, Gemma, Llama, Mistral, OLMo, Yi). The procedure identifies, without manual intervention, overused items such as 'suggest', 'additionally', and 'strategy', and estimates their link to preference learning. Our findings replicate prior work and remain stable across parameter settings, random seeds, and evaluation on further data. The approach scales readily and enables systematic study of lexical (mis)alignment beyond Scientific English and across languages, and as such, the metrics have the potential to contribute to improved alignment for future models and understanding of its origins.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces two curation-free metrics—the Lexical Alignment Score, which uses windowed document prevalence to detect lexical overuse in LLM-generated continuations of PubMed abstracts, and the Triangulated Preference Shift, which quantifies attribution of such overuses to human preference learning stages. Applied across six model families (Falcon, Gemma, Llama, Mistral, OLMo, Yi), the method identifies items such as 'suggest', 'additionally', and 'strategy' without manual curation, claims to replicate prior findings on preference-linked divergences in scientific English, and reports stability across random seeds, parameter settings, and additional data.
Significance. If the Triangulated Preference Shift validly isolates preference-stage effects, the automated, scalable metrics would enable systematic study of lexical misalignment beyond scientific English and across languages, supporting improved alignment research. The reported replication of prior work and stability across seeds and settings are explicit strengths that enhance reproducibility.
major comments (2)
- [Triangulated Preference Shift] Triangulated Preference Shift section: the attribution of lexical overuses (e.g., 'suggest') specifically to preference learning stages lacks isolation from model-family confounds; no ablations are reported that hold base model, pretraining corpus, or architecture fixed while varying only the preference stage, so observed shifts could arise from tokenizer effects or non-preference differences across the six families. This is load-bearing for the central claim that the metric 'estimates their link to preference learning'.
- [Lexical Alignment Score and evaluation] Lexical Alignment Score and evaluation sections: the abstract and results report replication and stability but provide no derivation details, ground-truth validation, or error analysis for the windowed prevalence metric, leaving open whether the identified overuses accurately reflect alignment effects rather than generation artifacts.
minor comments (2)
- [Abstract and Triangulated Preference Shift] The explicit triangulation formula is not shown in the abstract and should be stated with all terms defined in the main text for clarity.
- [Introduction] References to the manual-curation methods being replaced should be expanded to include specific prior studies on Scientific English divergences.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, acknowledging where the manuscript requires clarification or additional discussion, and outline planned revisions.
read point-by-point responses
-
Referee: [Triangulated Preference Shift] Triangulated Preference Shift section: the attribution of lexical overuses (e.g., 'suggest') specifically to preference learning stages lacks isolation from model-family confounds; no ablations are reported that hold base model, pretraining corpus, or architecture fixed while varying only the preference stage, so observed shifts could arise from tokenizer effects or non-preference differences across the six families. This is load-bearing for the central claim that the metric 'estimates their link to preference learning'.
Authors: We agree that the analysis does not include ablations holding base model, pretraining corpus, or architecture fixed while varying only the preference stage. The six model families differ in multiple respects, so tokenizer effects and other non-preference differences cannot be ruled out as contributors to the observed shifts. The consistency across families and replication of prior findings provide supporting evidence but do not substitute for controlled isolation. In the revised manuscript we will add an explicit limitations subsection moderating the language on attribution to preference stages and clarifying the scope of the central claim. revision: yes
-
Referee: [Lexical Alignment Score and evaluation] Lexical Alignment Score and evaluation sections: the abstract and results report replication and stability but provide no derivation details, ground-truth validation, or error analysis for the windowed prevalence metric, leaving open whether the identified overuses accurately reflect alignment effects rather than generation artifacts.
Authors: We agree that additional methodological detail would strengthen the presentation. The current text defines the Lexical Alignment Score via windowed document prevalence but does not supply a formal derivation, error analysis, or explicit ground-truth validation. In revision we will expand the methods section with the mathematical formulation and parameter rationale, add an error-analysis subsection addressing potential generation artifacts, and discuss indirect validation through alignment with manually identified overuses reported in prior literature on scientific English. These changes will be incorporated in the next version. revision: yes
Circularity Check
No circularity: metrics defined and applied empirically without reduction to inputs
full rationale
The paper introduces Lexical Alignment Score and Triangulated Preference Shift as curation-free metrics based on windowed document prevalence in generated continuations from six model families. It applies them to PubMed abstracts to identify overused lexical items and estimate links to preference learning, replicating prior work with stability checks. No equations, definitions, or derivation steps are presented that equate a claimed prediction or attribution to a fitted parameter or self-citation by construction. The central claims rest on direct measurement rather than self-referential loops, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Windowed document prevalence on model continuations versus human abstracts measures lexical alignment without manual curation
- domain assumption Observed lexical shifts can be triangulated to human preference learning stages
Reference graph
Works this paper leans on
-
[1]
Introduction Usage of digital assistants based on Large Lan- guage Models (LLMs), such as ChatGPT, is in- creasing fast, and these artificial intelligence (AI) tools are now widely used for programming, lan- guage editing, and information finding (Stack Over- flow, 2024; Coffey, 2024; O’Brien and Sanders, 2025; Sidoti and McClain, 2025). They perform stro...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
delve”, “furthermore
Related Work 2.1. Lexical Overuse in LLMs After the release of ChatGPT, a sudden spike in the usage of a small set of words (e.g., “delve”, “furthermore”, “intricate”) in academic writing was noted(Matsui,2024;Kobaketal.,2024;Liangetal., 2024; Liu and Bu, 2024). As many of these words are also overused in AI-generated texts (Matsui, 2024),themostplausible...
2024
-
[3]
Reply only with the continuation; do not repeat the user text; no preface
Task and Data We address the gaps identified in Section 2 by introducing curation-free, assumption-light met- rics that cover both thewhatandwhyof lexical (mis)alignment. Our data comprise PubMed ab- stracts, which enables a comparison with the liter- ature on lexical overuse in LLMs, which largely fo- cuses on this very domain (Scientific English). We sa...
2012
-
[4]
Thisisasentencewith seven words
Evaluation Metrics Both metrics introduced below, theLexical Align- ment Score(LAS) and theTriangulated Preference Shift(TPS), operate on length-controlled windows of paired human-model continuations, using win- dowed document prevalence to ensure robustness against few-document spikes. Intuitively, the two metrics approach the follow- ing questions. LAS ...
1981
-
[5]
Table 2b links to prior work by limiting analysis to content words (NOUN/VERB/ADJ/ADV) and aggregating over instruct models
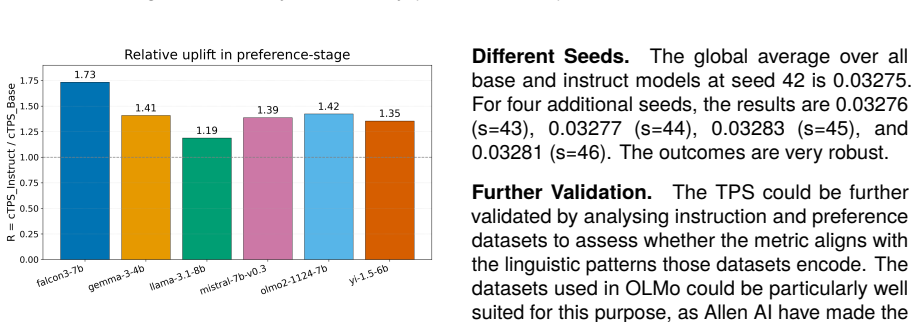
Results Table 2a reports the top 20 lemma-level Lex- ical Alignment Scores aggregated over all in- struct models; results for the base models can be found in Table 4 in Appendix B. Table 2b links to prior work by limiting analysis to content words (NOUN/VERB/ADJ/ADV) and aggregating over instruct models. The top 20 items ranked by the preference-stage met...
-
[6]
(i) we scored an additional, unseen 20% of the data
Validation To further validate the metrics, we conducted four checks. (i) we scored an additional, unseen 20% of the data. (ii) We compare our overuse list to the literature. (iii) We ran the metrics with different window sizes (K = 40, 50, 60). (iv) We reran the K= 50configuration for four more random seeds. The following is done for the LAS metric. Addi...
2024
-
[7]
However, focus- ing on content words (NOUN/VERB/ADJ/ADV), for all models this trend either reverses (4/6 families in Figure 1 bottom) or at least weakens
Discussion At the corpus level, instruct variants generally align betterwith human usage than their base counter- parts (5/6 families; Figure 1 top). However, focus- ing on content words (NOUN/VERB/ADJ/ADV), for all models this trend either reverses (4/6 families in Figure 1 bottom) or at least weakens. These are precisely the items emphasised in prior re...
2025
-
[8]
Critically, the pro- posed methods are curation-free and assumption- light
Conclusion The goal of this paper was to introduce evaluation metricsformeasuringlexicalalignmentandthecon- tribution of preference learning. Critically, the pro- posed methods are curation-free and assumption- light. Key to it is a scalable design in which model continuations are compared against matched hu- man continuations from the same source docu- m...
2025
-
[9]
Cer- tainly, here is
Meta/AI persona: e.g., “Cer- tainly, here is ...”, “as an AI model”, apologies, instructions, tool/safety notes
-
[10]
Conversation turns & scaf- folding (only if truly dia- logic): pseudo-dialogue mark- ers <|user|>, <|assistant|>, </|user|>, </|assistant|> ONLY IF followed by chat-like material (greeting, instruction, apology, question to reader); delete the marker and that span; otherwise delete markers only
-
[11]
Obvious repetition/loops: re- move verbatim or near-verbatim repeats; KEEP one copy
-
[12]
I/me/my” or di- rect address “you/your
First/second-person META sen- tences using “I/me/my” or di- rect address “you/your”. Do NOT delete “we/our/us”. PRESERVE: - Keep phrases like “In conclu- sion” / “concluding” when embed- ded in a normal sentence. - All scientific content and phrasing (incl. “we/our/us”). - Angle-bracketed tokens in gen- eral (operators, tags, gene sym- bols, XML-like mark...
-
[13]
Gpt-4 technical report.arXiv preprint arXiv:2303.08774. Sina Alemohammad, Josue Casco-Rodriguez, Lorenzo Luzi, Ahmed Imtiaz Humayun, Hos- sein Babaei, Daniel LeJeune, Ali Siahkoohi, and Richard G. Baraniuk. 2023. Self-consuming gen- erative models go mad. arXiv preprint. Gregory C. Allen. 2025. Deepseek: A deep dive. Congressional Testimony, CSIS. Ebtesam...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Modelmisalignmentandlanguagechange: Traces of ai-associated language in unscripted spoken english.arXiv preprint arXiv:2508.00238. Hui Bai, Jan G. Voelkel, Shane Muldowney, Jo- hannes C. Eichstaedt, and Robb Willer. 2025. LLM-generated messages can persuade hu- mans on policy issues.Nature Communications, 16(6037). Emily M Bender, Timnit Gebru, Angelina M...
-
[15]
InProceedings of the 24th conference on com- putational natural language learning, pages 609– 619
Cloze distillation: Improving neural lan- guage models with human next-word prediction. InProceedings of the 24th conference on com- putational natural language learning, pages 609– 619. Sarah Fitterer, Dominik Gangl, and Jannes Ulbrich
-
[16]
InACL 2025 Student Research Workshop
Testing english news articles for lexical ho- mogenizationduetowidespreaduseoflargelan- guage models. InACL 2025 Student Research Workshop. Iason Gabriel. 2020. Artificial intelligence, values, and alignment.Minds and Machines, 30(3):411– 437. Riley Galpin, Bryce Anderson, and Tom S Juzek
2025
-
[17]
Exploring the structure of ai-induced lan- guage change in scientific english.arXiv preprint arXiv:2506.21817. Sebastian Gehrmann, Hendrik Strobelt, and Alexander Rush. 2019. GLTR: Statistical de- tection and visualization of generated text. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: Sys- tem Demonstrations...
-
[18]
Understanding the Effects of RLHF on LLM Generalisation and Diversity
Understanding the effects of rlhf on llm generalisation and diversity.arXiv preprint arXiv:2310.06452. Dmitry Kobak, Rita González Márquez, Emőke- Ágnes Horvát, and Jan Lause. 2024. Delv- ing into chatgpt usage in academic writing through excess vocabulary.arXiv preprint arXiv:2406.07016. HadasKotek,RikkerDockum,andDavidSun.2023. Gender bias and stereotyp...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Can AI-Generated Text be Reliably Detected?
Research priorities for robust and beneficial artificial intelligence.AI magazine, 36(4):105–114. Vinu Sankar Sadasivan, Aounon Kumar, Sriram Balasubramanian, Wenxiao Wang, and Soheil Feizi. 2023. Can ai-generated text be reliably detected?arXiv preprint arXiv:2303.11156. Sigal Samuel and Jordan Crook. 2025. Here’s how deepseek censorship actually works—a...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Classification of human- and AI-generated texts for different languages and domains.Inter- national Journal of Speech Technology, 27:935– 956. M. Sharma et al. 2023. Towards under- standing sycophancy in language models. arXiv:2310.13548. Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, YarinGal, NicolasPapernot, andRossAnderson
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
The curse of recursion: Training on gener- ated data makes models forget. arXiv preprint. Olivia Sidoti and Colleen McClain. 2025. 34% of U.S. adults have used ChatGPT, about double the share in 2023. Pew Research Center. Stack Overflow. 2024. Ai — 2024 stack overflow developer survey. Stack Overflow. Chris Stokel-Walker. 2025. We tried out deepseek. it w...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Finetuned Language Models Are Zero-Shot Learners
Llama 2: Open foundation and fine-tuned chat models.arXiv. Debora Weber-Wulff, Alla Anohina-Naumeca, Sonja Bjelobaba, Tomáš Folt `ynek, Jean Guerrero-Dib, Olumide Popoola, Petr Šigut, and Lorna Waddington. 2023. Testing of detection tools for ai-generated text.International Journal for Educational Integrity, 19(1):1–39. JasonWei,MaartenBosma,VincentYZhao,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [23]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.