Do Real-World Datasets Contain Natural Experiments? An Empirical Study Using Causal Feature Selection
Pith reviewed 2026-06-28 09:55 UTC · model grok-4.3
The pith
Real-world datasets contain natural experiments that causal feature selection can exploit to raise model performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Recovering the causal graph and selecting features along causal links produces a measurable performance gain when the data is treated as interventional rather than observational; the authors interpret this gain as evidence that natural experiments are present in the real-world collections they examined.
What carries the argument
Causal discovery that recovers a graph, followed by causal feature selection that separates observational from interventional regimes.
If this is right
- Synthetic graphs containing natural experiments produce the expected performance lift while graphs without them do not.
- Multiple real-world datasets exhibit the same lift when switched to interventional modeling.
- Causal feature selection therefore supplies a practical way to improve prediction without collecting new interventional data.
- The method supplies an operational test for the existence of natural experiments inside any given collection.
Where Pith is reading between the lines
- Standard ML benchmarks may already embed usable natural experiments that current training pipelines ignore.
- Dataset audits could routinely include a causal-graph scan to flag hidden interventions before model training begins.
- Domains with frequent policy changes or localized shocks are the most promising places to search for additional natural experiments.
Load-bearing premise
Any performance lift from interventional modeling is produced by the presence of natural experiments rather than by incidental changes in selected features or model capacity.
What would settle it
A real-world dataset in which the same causal feature selection yields no performance difference, or in which the recovered graph contains no implicit interventions, would falsify the central claim.
Figures

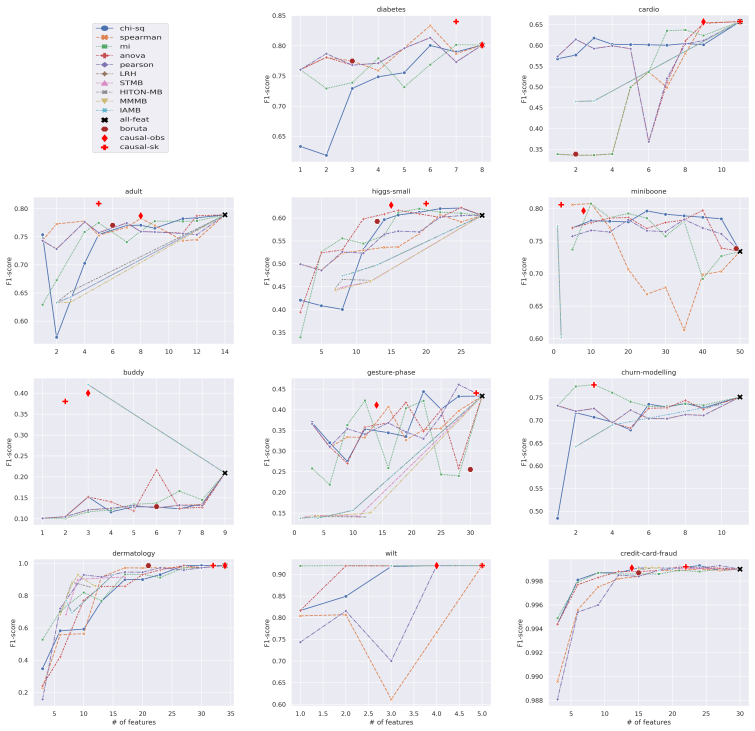
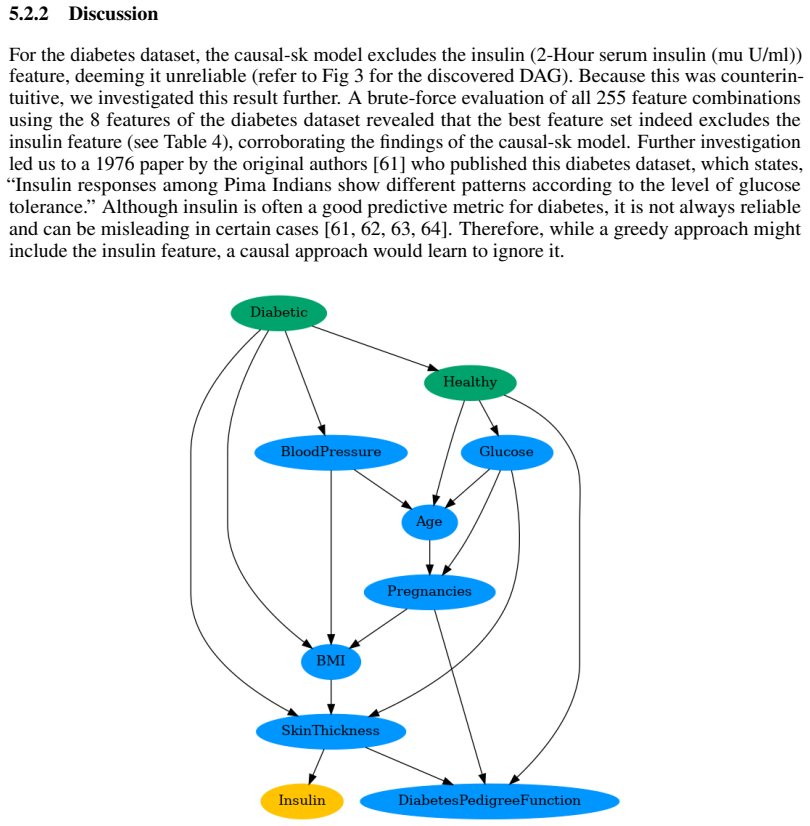



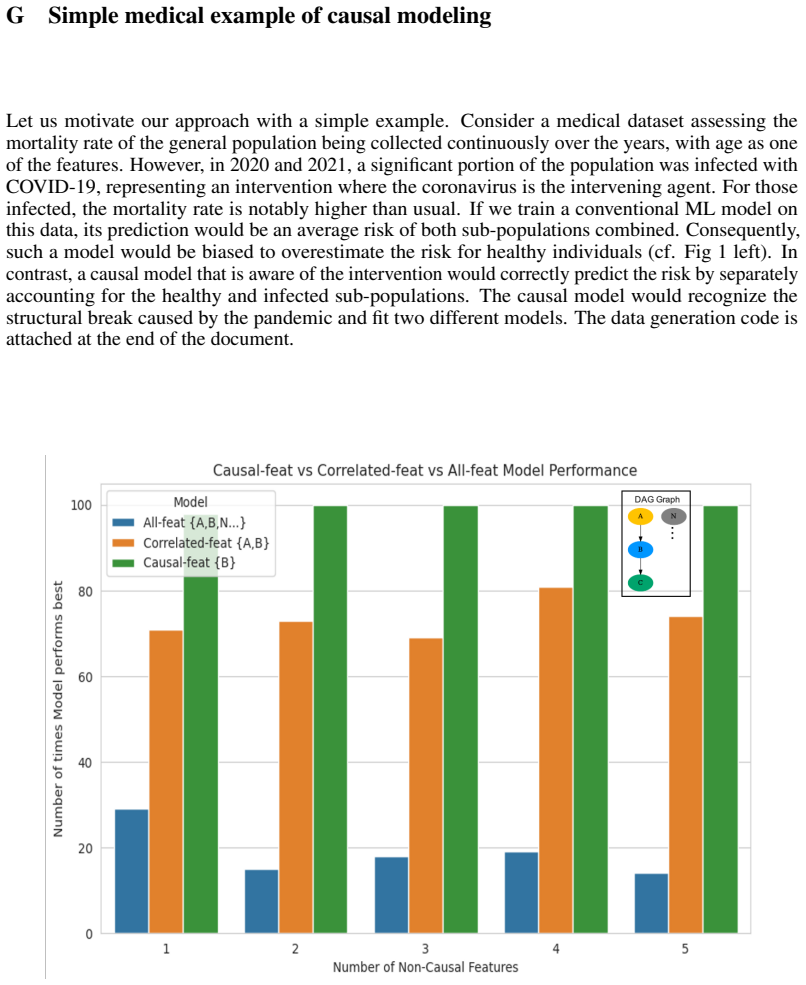
read the original abstract
In nature, events that affect some individuals or groups but not others constitute an implicit intervention and are known as natural experiments. For example, the COVID-19 pandemic was an intervention by the coronavirus on the sub-population infected with COVID. We ask, do natural experiments occur in existing real-world datasets? If yes, how should we treat them? To detect natural experiments in data, we use causal discovery to recover the underlying causal graph and perform feature selection based on causal links. If downstream performance improves by treating the data as interventional rather than observational, we argue that this suggests the dataset contains natural experiments. We first validate this hypothesis by simulating datasets with and without natural experiments using synthetic graphs. We then perform a systematic empirical evaluation on a large suite of real-world datasets. Our results indicate that real-world datasets do contain natural experiments and we can take advantage of those natural experiments to improve model performance using causal inference. Our work represents the initial foray into this area, offering a preliminary exploration within a limited scope.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that real-world datasets contain natural experiments (implicit interventions affecting subpopulations), which can be detected by applying causal discovery to recover the underlying graph and then performing feature selection on causal links. Synthetic experiments with controlled graphs validate that performance improves when data is treated as interventional rather than observational precisely when natural experiments are present. A systematic evaluation on a large suite of real-world datasets then shows similar performance gains, leading to the conclusion that such datasets do contain natural experiments and that causal inference can be used to exploit them.
Significance. If the central empirical claim holds after isolating the contribution of natural experiments, the work offers a first systematic probe into whether standard observational datasets embed unrecognized interventions and whether causal feature selection can capitalize on them. The synthetic validation protocol is a clear strength, as it directly controls intervention presence and graph structure to test the detection method.
major comments (2)
- [Abstract] Abstract (final paragraph) and the description of the real-world evaluation: the reported performance lift is obtained by comparing a pipeline that recovers a causal graph and selects features on causal links against a baseline that uses standard (non-causal) feature selection. Because the two pipelines differ in both the selected feature set and the induced model structure, the delta cannot be unambiguously attributed to the presence of natural experiments rather than to differences in feature selection quality.
- [Synthetic experiments] Synthetic experiments section: while the controlled graphs successfully isolate the effect of natural experiments, the real-world suite lacks a corresponding ablation that holds the feature set fixed and varies only whether the modeling treats the data as interventional or observational. Without this control, the cross-dataset claim that performance gains demonstrate natural experiments remains under-supported.
minor comments (1)
- The abstract and method description would benefit from an explicit statement of the precise statistical test used to declare a performance improvement significant across the real-world suite.
Simulated Author's Rebuttal
We thank the referee for their detailed review and insightful comments on our manuscript. We agree that strengthening the attribution of performance improvements to natural experiments is important and will revise the paper accordingly to include additional ablations. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph) and the description of the real-world evaluation: the reported performance lift is obtained by comparing a pipeline that recovers a causal graph and selects features on causal links against a baseline that uses standard (non-causal) feature selection. Because the two pipelines differ in both the selected feature set and the induced model structure, the delta cannot be unambiguously attributed to the presence of natural experiments rather than to differences in feature selection quality.
Authors: We thank the referee for highlighting this potential confound. The synthetic experiments are designed to isolate the contribution of natural experiments by comparing performance with and without them under the causal pipeline. When natural experiments are absent, no performance gain is observed despite using the same causal feature selection method. This suggests that the gains are attributable to the natural experiments rather than the feature selection procedure alone. Nevertheless, to address the concern directly for real-world data, we will add an ablation that holds the feature set fixed (using the causal selection) and varies only the modeling assumption (interventional vs. observational). revision: yes
-
Referee: [Synthetic experiments] Synthetic experiments section: while the controlled graphs successfully isolate the effect of natural experiments, the real-world suite lacks a corresponding ablation that holds the feature set fixed and varies only whether the modeling treats the data as interventional or observational. Without this control, the cross-dataset claim that performance gains demonstrate natural experiments remains under-supported.
Authors: We concur that an ablation holding the feature set constant would provide clearer evidence. The current synthetic validation already performs this isolation by varying the presence of natural experiments. For the real-world evaluation, we will incorporate the suggested ablation in the revised version, applying causal feature selection and then comparing interventional and observational modeling on the fixed feature set across the datasets. This will allow us to more confidently attribute any gains to the natural experiments. revision: yes
Circularity Check
Empirical performance comparison with no derivation chain or self-referential reduction
full rationale
The paper contains no equations, derivations, or first-principles results. Its central claim rests on an empirical protocol: run causal discovery + causal-link feature selection (interventional pipeline) versus standard feature selection (observational baseline), then interpret any accuracy lift on real-world data as evidence of natural experiments. This protocol is validated on controlled synthetics where graph and intervention presence are known, then applied to real datasets. No step reduces a claimed output to its own fitted inputs or to a self-citation chain by construction; the interpretive step (lift implies natural experiments) is a substantive modeling choice, not a definitional tautology. Minor self-citations to causal-discovery literature are present but not load-bearing for the empirical result. The paper is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Famke JM Mölenberg and Francisca Vargas Lopes. Natural experiments: A Nobel Prize awarded research design for strengthening causal inference on global health challenges.Journal of Global Health, 12, 2022. ISSN 20472986. doi: 10.7189/JOGH.12.03005. URL /pmc/articles/ PMC9031504/https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9031504/
-
[2]
Causal inference in statistics: An overview.Statistics surveys, 3:96–146, 2009
Judea Pearl et al. Causal inference in statistics: An overview.Statistics surveys, 3:96–146, 2009
2009
-
[3]
Gianicolo, Martin Eichler, Oliver Muensterer, Konstantin Strauch, and Maria Blettner
Emilio A.L. Gianicolo, Martin Eichler, Oliver Muensterer, Konstantin Strauch, and Maria Blettner. Methods for Evaluating Causality in Observational Studies: Part 27 of a Series on Evaluation of Scientific Publications.Deutsches Ärzteblatt International, 117(7):101, 2 2020. ISSN 18660452. doi: 10.3238/ARZTEBL.2020.0101. URL https://www.ncbi.nlm.nih. gov/pm...
-
[4]
Nobel-winning ‘natural experiments’ approach made economics more robust
Philip Ball. Nobel-winning ‘natural experiments’ approach made economics more robust. Nature, 10 2021. ISSN 0028-0836. doi: 10.1038/D41586-021-02799-7
-
[5]
Understanding Development and Poverty Alleviation. 2019. URLhttps://www.nobelprize. org/uploads/2019/10/advanced-economicsciencesprize2019.pdf
2019
-
[6]
Causal protein-signaling networks derived from multiparameter single-cell data.Science, 308(5721): 523–529, 2005
Karen Sachs, Omar Perez, Dana Pe’er, Douglas A Lauffenburger, and Garry P Nolan. Causal protein-signaling networks derived from multiparameter single-cell data.Science, 308(5721): 523–529, 2005
2005
-
[7]
Learning Bayesian Networks with the <b>bnlearn</b> <i>R</i> Package
Marco Scutari. Learning Bayesian Networks with the <b>bnlearn</b> <i>R</i> Package. Journal of Statistical Software, 35(3):1–22, 7 2010. ISSN 1548-7660. doi: 10.18637/jss.v035. i03. URLhttp://www.jstatsoft.org/v35/i03/
-
[8]
Differentiable causal discovery from interventional data, 2020 a
Philippe Brouillard, Sébastien Lachapelle, Alexandre Lacoste, Simon Lacoste-Julien, and Alexandre Drouin. Differentiable Causal Discovery from Interventional Data.Advances in Neural Information Processing Systems, 2020-December, 7 2020. ISSN 10495258. doi: 10.48550/arxiv.2007.01754. URLhttps://arxiv.org/abs/2007.01754v2
-
[9]
Causal diagrams for empirical research.Biometrika, 82(4):669–688, 1995
Judea Pearl. Causal diagrams for empirical research.Biometrika, 82(4):669–688, 1995
1995
-
[10]
The MIT Press, 2017
Jonas Peters, Dominik Janzing, and Bernhard Schölkopf.Elements of causal inference: founda- tions and learning algorithms. The MIT Press, 2017
2017
-
[11]
Morgan Kaufmann, San Francisco, Calif., 2009
Judea Pearl.Probabilistic reasoning in intelligent systems : networks of plausible inference. Morgan Kaufmann, San Francisco, Calif., 2009. ISBN 9781558604797 1558604790. URL https://www.amazon.de/ Probabilistic-Reasoning-Intelligent-Systems-Representation/dp/ 1558604790. Example for Explaning away
2009
-
[12]
Toward optimal feature selection
Daphne Koller and Mehran Sahami. Toward optimal feature selection. InProc. 13th Interna- tional Conference on Machine Learning, pages 284–292. Morgan Kaufmann, 1996
1996
-
[13]
Aliferis
Ioannis Tsamardinos and Constantin F. Aliferis. Towards Principled Feature Selection: Rele- vancy, Filters and Wrappers, 1 2003. ISSN 2640-3498. URL https://proceedings.mlr. press/r4/tsamardinos03a.html
2003
-
[14]
Cambridge University Press, USA, 2nd edition,
Judea Pearl.CAUSALITY, 2nd Edition, 2009. Cambridge University Press, USA, 2nd edition,
2009
-
[15]
URLhttp://bayes.cs.ucla.edu/BOOK-2K/
ISBN 052189560X. URLhttp://bayes.cs.ucla.edu/BOOK-2K/
-
[16]
Chickering
David Heckerman, Dan Geiger, and David M. Chickering. Learning Bayesian Networks: The Combination of Knowledge and Statistical Data.Machine Learning 1995 20:3, 20(3):197–243,
1995
-
[17]
ISSN 1573-0565. doi: 10.1023/A:1022623210503. URL https://link.springer. com/article/10.1023/A:1022623210503. 11
-
[18]
Spirtes, Clark N
Peter. Spirtes, Clark N. Glymour, and Richard. Scheines. Causation, prediction, and search. page 543, 2000
2000
-
[19]
Ricardo Pio Monti, Kun Zhang, and Aapo Hyvarinen. Causal discovery with general non-linear relationships using non-linear ica.arXiv preprint arXiv:1904.09096, 2019
Pith/arXiv arXiv 1904
-
[20]
MIT press, 2000
Peter Spirtes, Clark N Glymour, Richard Scheines, David Heckerman, Christopher Meek, Gregory Cooper, and Thomas Richardson.Causation, prediction, and search. MIT press, 2000
2000
-
[21]
A kernel-based causal learning algorithm
Xiaohai Sun, Dominik Janzing, Bernhard Schölkopf, and Kenji Fukumizu. A kernel-based causal learning algorithm. InProceedings of the 24th international conference on Machine learning, pages 855–862. ACM, 2007
2007
-
[22]
Kun Zhang, Jonas Peters, Dominik Janzing, and Bernhard Schölkopf. Kernel-based conditional independence test and application in causal discovery.arXiv preprint arXiv:1202.3775, 2012
Pith/arXiv arXiv 2012
-
[23]
Causal Discovery with Reinforcement Learning
Shengyu Zhu, Ignavier Ng, and Zhitang Chen. Causal Discovery with Reinforcement Learning. 6 2019. doi: 10.48550/arxiv.1906.04477. URLhttp://arxiv.org/abs/1906.04477
-
[24]
Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
David Maxwell Chickering. Optimal structure identification with greedy search.Journal of machine learning research, 3(Nov):507–554, 2002
2002
-
[25]
Cooper and Changwon Yoo
Gregory F. Cooper and Changwon Yoo. Causal Discovery from a Mixture of Experimental and Observational Data. InProceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence, UAI’99, pages 116–125, San Francisco, CA, USA, 1999
1999
-
[26]
Causal generative neural networks.arXiv preprint arXiv:1711.08936, 2017
Olivier Goudet, Diviyan Kalainathan, Philippe Caillou, Isabelle Guyon, David Lopez-Paz, and Michèle Sebag. Causal generative neural networks.arXiv preprint arXiv:1711.08936, 2017
Pith/arXiv arXiv 2017
-
[27]
Characterization and greedy learning of interventional markov equivalence classes of directed acyclic graphs.The Journal of Machine Learning Research, 13(1):2409–2464, 2012
Alain Hauser and Peter Bühlmann. Characterization and greedy learning of interventional markov equivalence classes of directed acyclic graphs.The Journal of Machine Learning Research, 13(1):2409–2464, 2012
2012
-
[28]
Learning bayesian networks: The combination of knowledge and statistical data.Machine learning, 20(3):197–243, 1995
David Heckerman, Dan Geiger, and David M Chickering. Learning bayesian networks: The combination of knowledge and statistical data.Machine learning, 20(3):197–243, 1995
1995
-
[29]
Brown, and Constantin F
Ioannis Tsamardinos, Laura E. Brown, and Constantin F. Aliferis. The max-min hill-climbing Bayesian network structure learning algorithm.Machine Learning 2006 65:1, 65(1):31–78, 3
2006
-
[30]
doi: 10.1007/S10994-006-6889-7
ISSN 1573-0565. doi: 10.1007/S10994-006-6889-7. URL https://link.springer. com/article/10.1007/s10994-006-6889-7
-
[31]
Generalized Score Functions for Causal Discovery.KDD : proceedings
Biwei Huang, Kun Zhang, Yizhu Lin, Bernhard Schölkopf, and Clark Glymour. Generalized Score Functions for Causal Discovery.KDD : proceedings. International Conference on Knowledge Discovery & Data Mining, 2018:1551–1560, 8 2018. ISSN 2154-817X. doi: 10. 1145/3219819.3220104. URL http://www.ncbi.nlm.nih.gov/pubmed/30191079http: //www.pubmedcentral.nih.gov/...
arXiv 2018
-
[32]
DAGs with NO TEARS: Continuous optimization for structure learning
Xun Zheng, Bryon Aragam, Pradeep K Ravikumar, and Eric P Xing. DAGs with NO TEARS: Continuous optimization for structure learning. InAdvances in Neural Information Processing Systems, volume 31, pages 9472–9483, 2018
2018
-
[33]
Scaling structural learning with no-bears to infer causal transcriptome networks
Hao-Chih Lee, Matteo Danieletto, Riccardo Miotto, Sarah T Cherng, and Joel T Dudley. Scaling structural learning with no-bears to infer causal transcriptome networks. InPACIFIC SYMPOSIUM ON BIOCOMPUTING 2020, pages 391–402. World Scientific, 2019
2020
-
[34]
DAG-GNN: DAG Structure Learning with Graph Neural Networks
Yue Yu, Jie Chen, Tian Gao, and Mo Yu. DAG-GNN: DAG Structure Learning with Graph Neural Networks.36th International Conference on Machine Learning, ICML 2019, 2019-June: 12395–12406, 2019. doi: 10.48550/arxiv.1904.10098
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1904.10098 2019
-
[35]
Gradient- based neural dag learning.arXiv preprint arXiv:1906.02226, 2019
Sébastien Lachapelle, Philippe Brouillard, Tristan Deleu, and Simon Lacoste-Julien. Gradient- based neural dag learning.arXiv preprint arXiv:1906.02226, 2019
arXiv 1906
-
[36]
Learning sparse nonparametric dags
Xun Zheng, Chen Dan, Bryon Aragam, Pradeep Ravikumar, and Eric Xing. Learning sparse nonparametric dags. InInternational Conference on Artificial Intelligence and Statistics, pages 3414–3425. PMLR, 2020
2020
-
[37]
Differentiable causal discovery from interventional data
Philippe Brouillard, Sébastien Lachapelle, Alexandre Lacoste, Simon Lacoste-Julien, and Alexandre Drouin. Differentiable causal discovery from interventional data. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 21865–21877. Curran Associates, Inc., 2020. 12
2020
-
[38]
Yoshua Bengio, Tristan Deleu, Nasim Rahaman, Rosemary Ke, Sébastien Lachapelle, Olexa Bilaniuk, Anirudh Goyal, and Christopher Pal. A meta-transfer objective for learning to disentangle causal mechanisms.arXiv preprint arXiv:1901.10912, 2019
Pith/arXiv arXiv 1901
-
[39]
Learning Neural Causal Models from Unknown Interventions
Nan Rosemary Ke, Olexa Bilaniuk, Anirudh Goyal, Stefan Bauer, Hugo Larochelle, Bernhard Schölkopf, Michael C Mozer, Chris Pal, and Yoshua Bengio. Learning Neural Causal Models from Unknown Interventions
-
[40]
Efficient Neural Causal Discovery without Acyclicity Constraints
Phillip Lippe, Taco Cohen, Qualcomm Ai Research, and Efstratios Gavves. Efficient Neural Causal Discovery without Acyclicity Constraints. 2021. doi: 10.48550/arxiv.2107.10483
-
[41]
Feature Selection: A Data Perspective
Jundong Li, Kewei Cheng, Suhang Wang, Fred Morstatter, Robert P. Trevino, Jiliang Tang, and Huan Liu. Feature Selection: A Data Perspective.ACM Computing Surveys, 50(6), 1 2016. doi: 10.1145/3136625. URL http://arxiv.org/abs/1601.07996http://dx.doi.org/ 10.1145/3136625
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1145/3136625 2016
-
[42]
A Unified View of Causal and Non-causal Feature Selection
Kui Yu, Lin Liu, and Jiuyong Li. A Unified View of Causal and Non-causal Feature Selection. ACM Transactions on Knowledge Discovery from Data, 15(4), 2 2018. ISSN 1556472X. doi: 10.48550/arxiv.1802.05844. URLhttps://arxiv.org/abs/1802.05844v4
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1802.05844 2018
-
[43]
In: Medical Imaging with Deep Learning (MIDL)
Kui Yu, Xianjie Guo, Lin Liu, Jiuyong Li, Hao Wang, Zhaolong Ling, and Xindong Wu. Causality-based Feature Selection: Methods and Evaluations. 11 2019. doi: 10.48550/arxiv. 1911.07147. URLhttps://arxiv.org/abs/1911.07147
work page internal anchor Pith review doi:10.48550/arxiv 2019
-
[44]
Learning neural causal models from unknown interventions.arXiv preprint arXiv:1910.01075, 2019
Nan Rosemary Ke, Olexa Bilaniuk, Anirudh Goyal, Stefan Bauer, Hugo Larochelle, Bernhard Schölkopf, Michael C Mozer, Chris Pal, and Yoshua Bengio. Learning neural causal models from unknown interventions.arXiv preprint arXiv:1910.01075, 2019
arXiv 1910
-
[45]
Phillip Lippe, Taco Cohen, and Efstratios Gavves. Efficient neural causal discovery without acyclicity constraints.arXiv preprint arXiv:2107.10483, 2021
arXiv 2021
-
[46]
Learning to induce causal structure.arXiv preprint arXiv:2204.04875, 2022
Nan Rosemary Ke, Silvia Chiappa, Jane Wang, Jorg Bornschein, Theophane Weber, Anirudh Goyal, Matthew Botvinick, Michael Mozer, and Danilo Jimenez Rezende. Learning to Induce Causal Structure. 4 2022. doi: 10.48550/arxiv.2204.04875. URL https://arxiv.org/abs/ 2204.04875v1
-
[47]
Bobak Shahriari, Kevin Swersky, Ziyu Wang, Ryan P. Adams, and Nando de Freitas. Taking the Human Out of the Loop: A Review of Bayesian Optimization.Proceedings of the IEEE, 104(1):148–175, 1 2016. ISSN 0018-9219. doi: 10.1109/JPROC.2015.2494218. URL https: //ieeexplore.ieee.org/document/7352306/
-
[48]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization.7th International Conference on Learning Representations, ICLR 2019, 11 2017. doi: 10.48550/arxiv.1711.05101. URLhttps://arxiv.org/abs/1711.05101v3
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1711.05101 2019
-
[49]
Anthony J. Bishara and James B. Hittner. Testing the significance of a correlation with nonnormal data: Comparison of Pearson, Spearman, transformation, and resampling approaches. Psychological Methods, 17(3):399–417, 9 2012. ISSN 1082989X. doi: 10.1037/A0028087. URL/record/2012-11642-001
-
[50]
David D. Lewis. Feature Selection and Feature Extraction for Text Categorization. page 212,
-
[51]
doi: 10.3115/1075527.1075574
-
[52]
Johnson and Robert E
Kevin J. Johnson and Robert E. Synovec. Pattern recognition of jet fuels: comprehensive GC×GC with ANOV A-based feature selection and principal component analysis.Chemometrics and Intelligent Laboratory Systems, 60(1-2):225–237, 1 2002. ISSN 0169-7439. doi: 10.1016/ S0169-7439(01)00198-8
2002
-
[53]
Huan Liu and R. Setiono. Chi2: feature selection and discretization of numeric attributes. In Proceedings of 7th IEEE International Conference on Tools with Artificial Intelligence, pages 388–391. IEEE Comput. Soc. Press. ISBN 0-8186-7312-5. doi: 10.1109/TAI.1995.479783. URLhttp://ieeexplore.ieee.org/document/479783/
-
[54]
Kursa, Aleksander Jankowski, and Witold R
Miron B. Kursa, Aleksander Jankowski, and Witold R. Rudnicki. Boruta – A System for Feature Selection.Fundamenta Informaticae, 101(4):271–285, 1 2010. ISSN 01692968. doi: 10.3233/FI-2010-288. URL https://www.medra.org/servlet/aliasResolver?alias= iospress&doi=10.3233/FI-2010-288. 13
-
[55]
Swamping and masking in Markov boundary discovery.Machine Learning, 104(1):25–54, 7 2016
Xuqing Liu and Xinsheng Liu. Swamping and masking in Markov boundary discovery.Machine Learning, 104(1):25–54, 7 2016. ISSN 0885-6125. doi: 10.1007/s10994-016-5545-0. URL http://link.springer.com/10.1007/s10994-016-5545-0
-
[56]
Tian Gao and Qiang Ji. Efficient Markov Blanket Discovery and Its Application.IEEE transactions on cybernetics, 47(5):1169–1179, 5 2017. ISSN 2168-2275. doi: 10.1109/TCYB. 2016.2539338. URLhttp://www.ncbi.nlm.nih.gov/pubmed/27046886
-
[57]
HITON: a novel Markov Blanket algorithm for op- timal variable selection.AMIA
C F Aliferis, I Tsamardinos, and A Statnikov. HITON: a novel Markov Blanket algorithm for op- timal variable selection.AMIA ... Annual Symposium proceedings. AMIA Symposium, 2003:21–5,
2003
-
[58]
ISSN 1942-597X. URL http://www.ncbi.nlm.nih.gov/pubmed/14728126http: //www.pubmedcentral.nih.gov/articlerender.fcgi?artid=PMC1480117
arXiv 1942
-
[59]
Tsamardinos, C
I. Tsamardinos, C. Aliferis, and A. Statnikov. Algorithms for Large Scale Markov Blanket Discovery. 2003
2003
-
[60]
Yiheng Liu, Elina Robeva, and Huanqing Wang. Learning linear non-Gaussian graphical models with multidirected edges.Journal of Causal Inference, 9(1):250–263, 1 2021. ISSN 21933685. doi: 10.1515/JCI-2020-0027
-
[61]
URL https://archive.ics.uci.edu/ ml/citation_policy.html
UCI Machine Learning Repository: Citation Policy. URL https://archive.ics.uci.edu/ ml/citation_policy.html
-
[62]
CTAB-GAN: Effective Table Data Synthesizing, 11 2021
Zilong Zhao, Aditya Kunar, Robert Birke, Lydia Y Chen Lydiaychen, Vineeth N Balasubra- manian, and Ivor Tsang. CTAB-GAN: Effective Table Data Synthesizing, 11 2021. ISSN 2640-3498. URLhttps://proceedings.mlr.press/v157/zhao21a.html
2021
-
[63]
Yu. V . Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting Deep Learning Models for Tabular Data.ArXiv, 2021
2021
-
[64]
TabDDPM: Modelling Tabular Data with Diffusion Models
Akim Kotelnikov HSE, Dmitry Baranchuk, Ivan Rubachev HSE, and Yandex Artem Babenko Yandex. TabDDPM: Modelling Tabular Data with Diffusion Models. 2022. doi: 10.48550/arxiv.2209.15421
-
[65]
M. Mostafizur Rahman and D. N. Davis. Addressing the Class Imbalance Problem in Medical Datasets.International Journal of Machine Learning and Computing, pages 224–228, 2013. ISSN 20103700. doi: 10.7763/ijmlc.2013.v3.307
-
[66]
P. H. Bennett, N. B. Rushforth, M. Miller, and P. M. LeCompte. Epidemiologic studies of diabetes in the Pima Indians.Recent Progress in Hormone Research, V ol. 32:333–376, 1976. ISSN 00799963. doi: 10.1016/b978-0-12-571132-6.50021-x
-
[67]
Christopher J. Hupfeld and Jerrold M. Olefsky. Type 2 Diabetes Mellitus: Etiology, Patho- genesis, and Natural History.Endocrinology: Adult and Pediatric, 1-2:691–714, 1 2015. doi: 10.1016/B978-0-323-18907-1.00040-8
-
[68]
J. Larry Jameson, David M. de Kretser, Ashley B. Grossman, John T. Potts, J. Larry De Groot, Linda C. Giudice, Shlomo Melmed, and Gordon C. Weir.Endocrinology: Adult and Pediatric, volume 1-2. Elsevier Inc., 1 2015. ISBN 9780323189071. doi: 10.1016/ c2012-1-03052-4. URL http://www.sciencedirect.com:5070/book/9780323189071/ endocrinology-adult-and-pediatric
arXiv 2015
-
[69]
Jeffrey Metter, B
E. Jeffrey Metter, B. Gwen Windham, Marcello Maggio, Eleanor M. Simonsick, Shari M. Ling, Josephine M. Egan, and Luigi Ferrucci. Glucose and Insulin Measurements from the Oral Glucose Tolerance Test and Mortality Prediction.Diabetes Care, 31(5):1026–1030, 5
-
[70]
ISSN 0149-5992. doi: 10.2337/DC07-2102. URL https://dx.doi.org/10.2337/ dc07-2102
-
[71]
whitegrid
Lukas Biewald. Experiment Tracking with Weights and Biases.Software available from wandb.com, 2020. URLhttps://www.wandb.com/. 14 Contents 1 Introduction 1 2 Background 3 3 Related Works 3 4 Methodology 4 4.1 Differentiable Causal Discovery . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 4.2 Detecting natural experiments . . . . . . . . . . . . . ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.