BlobShuffle: Cost-Effective Repartitioning in Stream Processing Systems via Object Storage Exemplified with Kafka Streams
Pith reviewed 2026-06-28 08:29 UTC · model grok-4.3
The pith
BlobShuffle routes stream shuffling through cloud object storage to cut costs by more than 40 times.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
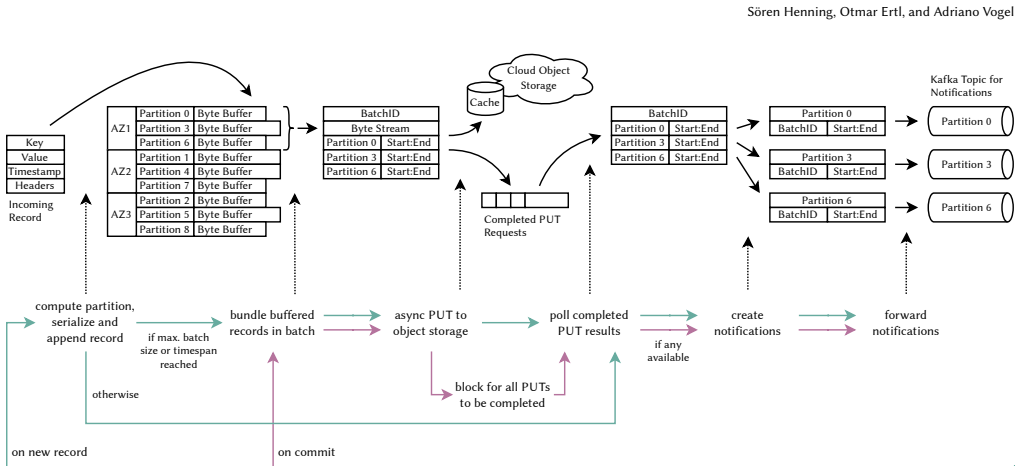
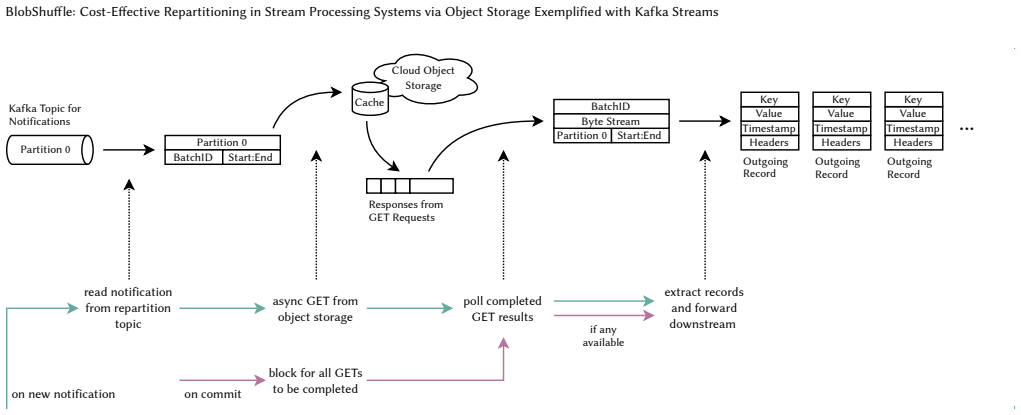
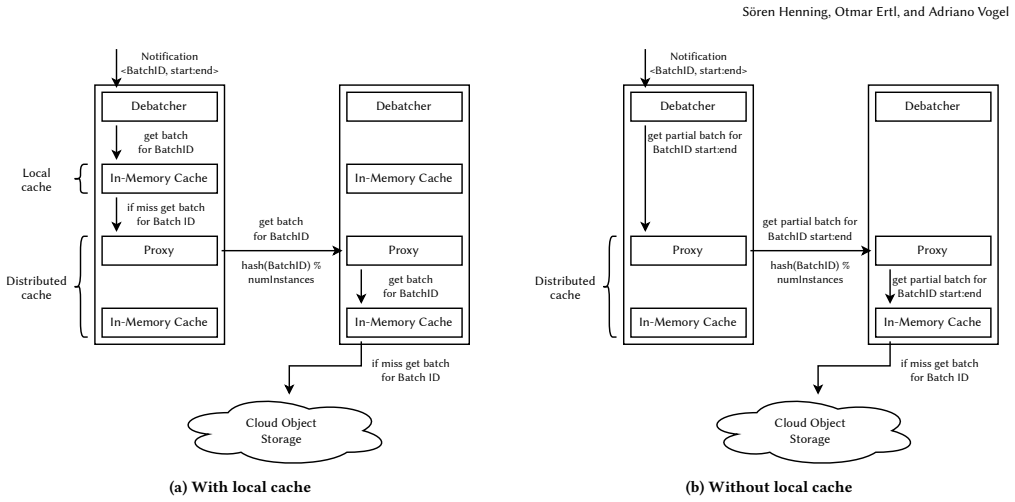
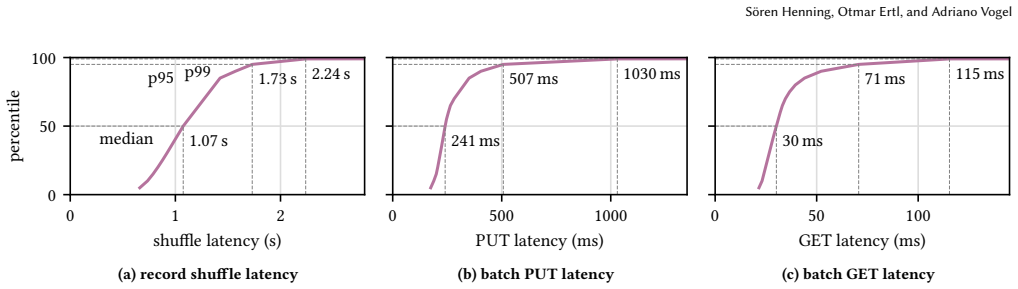
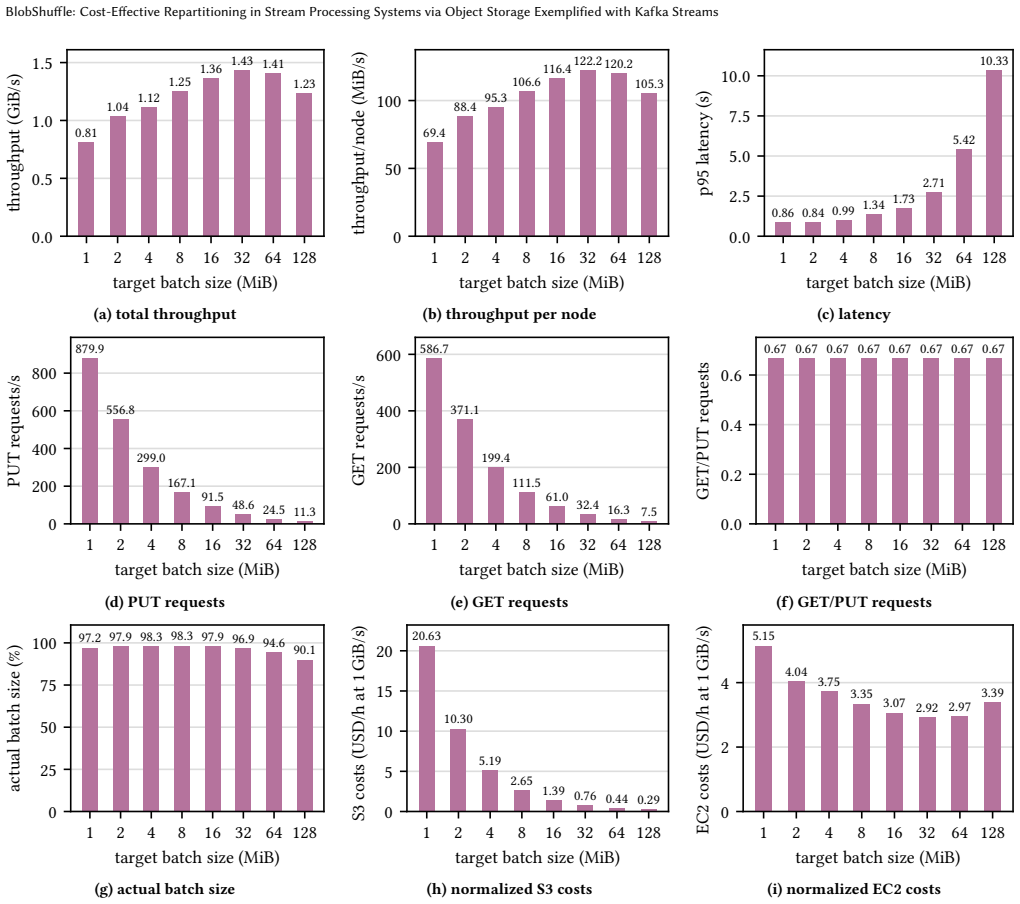
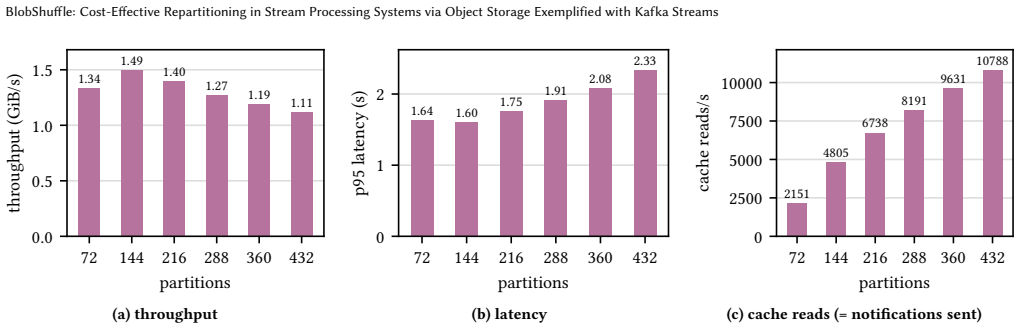
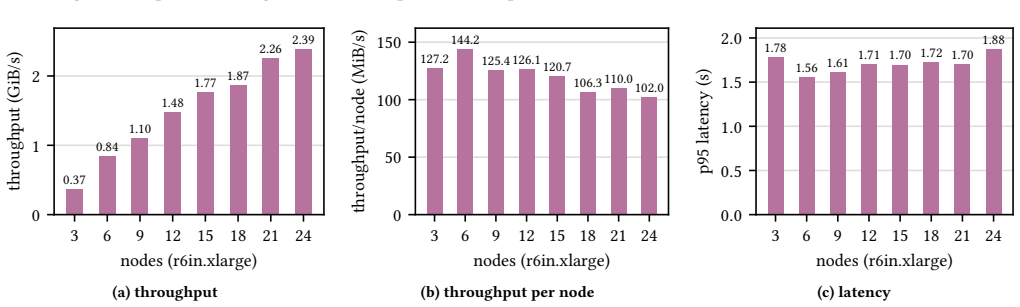
BlobShuffle groups records into batches, stores them in cloud object storage, and forwards compact notifications to downstream operators who retrieve the batches using distributed caching. This yields more than 40x lower shuffling costs than native Kafka Streams while keeping 95th percentile latency below 2 seconds and scaling to more than 2 GiB/s.
What carries the argument
Batching records for storage in cloud object storage combined with notification forwarding and distributed caching to balance cost and latency.
If this is right
- Shuffling no longer requires operating a high-throughput messaging backbone.
- Existing Kafka Streams applications need only minimal code changes.
- Cost efficiency allows shuffle-intensive workloads at large scale.
- Consistency and correctness guarantees remain intact.
Where Pith is reading between the lines
- The technique could extend to other cloud-based stream processors facing similar repartitioning costs.
- It might encourage greater use of object storage as an exchange layer in distributed systems.
- Testing at even higher throughputs could reveal if scalability limits appear beyond 2 GiB/s.
Load-bearing premise
The assumption that using object storage for batches and notifications maintains the original system's consistency and correctness without adding failure modes or exceeding latency targets.
What would settle it
An experiment measuring shuffling costs and 95th percentile latency at scale that fails to show at least 40x cost reduction or exceeds 2 seconds latency.
Figures

read the original abstract
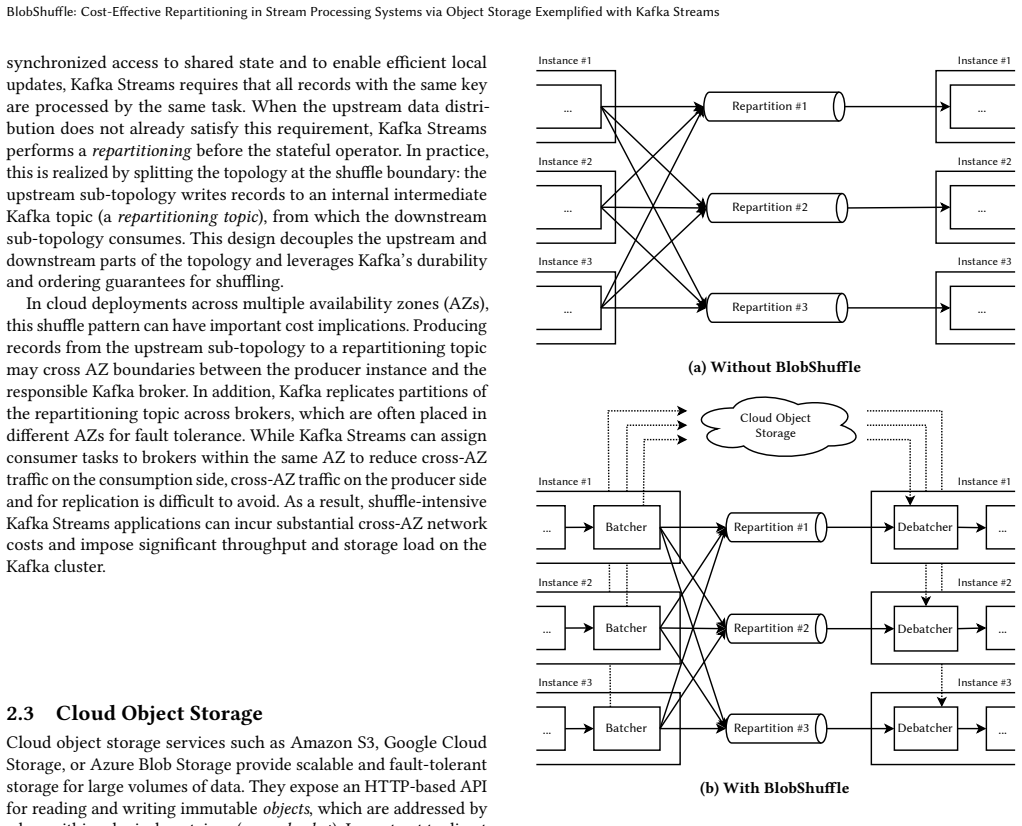
Shuffling or repartitioning data streams is an essential operation of state-of-the-art stream processing frameworks to support stateful workloads in a large-scale, distributed setting. In today's cloud deployments, however, shuffling can become a major cost driver due to substantial network traffic across multiple availability zones (AZs) as well as an operational burden when operating a high-throughput, strongly consistent messaging backbone at scale. We present BlobShuffle, a novel approach to cost-effective shuffling for stream processing systems that leverages cloud object storage as an intermediate exchange layer. Instead of sending all shuffled records directly, BlobShuffle groups records into batches, stores these batches in cloud object storage, and forwards only compact notifications. Downstream operators use these notifications to retrieve the relevant batches and extract the corresponding records. BlobShuffle balances cost efficiency and latency through configurable batching and a distributed caching mechanism. BlobShuffle is implemented as an add-on for Kafka Streams that requires only minimal code changes to existing applications, leaves Kafka and the underlying infrastructure unmodified, and preserves Kafka Streams' consistency and correctness guarantees. In a large-scale experimental evaluation on a Kubernetes-based AWS deployment, we show that BlobShuffle can reduce shuffling costs by more than 40x compared to native Kafka Streams shuffling while keeping the 95th percentile shuffle latency below 2 seconds. Moreover, it scales to processing more than 2 GiB/s without encountering a scalability limit in our experiments, indicating that BlobShuffle can economically support shuffle-intensive workloads at large scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents BlobShuffle, an add-on for Kafka Streams that uses cloud object storage to batch records for shuffling/repartitioning, stores batches in object storage, and forwards only compact notifications to downstream operators (who retrieve via a distributed cache). It claims this yields >40x lower shuffling costs than native Kafka Streams, p95 shuffle latency <2s, and throughput >2 GiB/s on a Kubernetes AWS deployment, while requiring only minimal application changes, leaving Kafka unmodified, and preserving consistency/correctness guarantees.
Significance. If the experimental outcomes and correctness preservation hold, the work addresses a real cost and operational pain point in cloud stream processing by substituting cross-AZ network traffic with object-storage I/O plus notifications. The concrete 40x cost figure, latency bound, and scale result (if reproducible) would be a useful data point for practitioners; the design choice of configurable batching plus caching is a pragmatic way to trade latency for cost.
major comments (1)
- [Abstract] Abstract and evaluation section: the central claim that the batch-upload/notification/cache design 'preserves Kafka Streams' consistency and correctness guarantees' without new failure modes is load-bearing for the 'no Kafka changes' benefit, yet the provided description gives no concrete failure-handling protocol, consistency model argument, or fault-injection results for upload failures, notification loss, or cache-coherence races; this leaves the 40x cost and latency claims without a verified correctness foundation.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for underscoring the need for explicit correctness arguments. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract and evaluation section: the central claim that the batch-upload/notification/cache design 'preserves Kafka Streams' consistency and correctness guarantees' without new failure modes is load-bearing for the 'no Kafka changes' benefit, yet the provided description gives no concrete failure-handling protocol, consistency model argument, or fault-injection results for upload failures, notification loss, or cache-coherence races; this leaves the 40x cost and latency claims without a verified correctness foundation.
Authors: We agree that the current manuscript provides only a high-level claim without a concrete failure-handling protocol or supporting arguments. The design intends to inherit Kafka's exactly-once delivery for notifications and to treat object-storage uploads as idempotent operations with client-side retries, but these mechanisms are not spelled out. We will therefore add a dedicated subsection (approximately one page) in the system-design section that (1) enumerates the failure cases, (2) describes the retry and compensation logic, (3) argues why no new consistency violations are introduced relative to native Kafka Streams, and (4) reports the results of targeted fault-injection experiments. Corresponding text will also be added to the abstract and evaluation summary. These changes will appear in the revised version. revision: yes
Circularity Check
No circularity; claims rest on direct experimental measurements
full rationale
The paper presents BlobShuffle as an implemented system evaluated via large-scale experiments on AWS/Kubernetes. The core claims (40x cost reduction, p95 latency <2s, >2 GiB/s throughput) are reported as measured outcomes, not derived from equations, fitted parameters, or self-referential definitions. No mathematical derivation chain, uniqueness theorems, or ansatzes appear in the abstract or described approach. The consistency-preservation argument is an engineering claim supported by the implementation description rather than a reduction to prior self-citations. This matches the expected non-circular case for an empirical systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Cloud object storage provides sufficient durability, availability, and consistency for use as an intermediate exchange layer in stream processing.
Reference graph
Works this paper leans on
-
[1]
Aiven. 2026. Diskless for Apache Kafka ® (BYOC). https://aiven.io/inkless
2026
-
[2]
Michael Armbrust, Tathagata Das, Liwen Sun, Burak Yavuz, Shixiong Zhu, Mukul Murthy, Joseph Torres, Herman van Hovell, Adrian Ionescu, Alicja BlobShuffle: Cost-Effective Repartitioning in Stream Processing Systems via Object Storage Exemplified with Kafka Streams Łuszczak, Michał Świtakowski, Michał Szafrański, Xiao Li, Takuya Ueshin, Mostafa Mokhtar, Pet...
-
[3]
AutoMQ. 2026. AutoMQ | Kafka ® Compatible Cloud-Native Data Streaming Platform. https://www.automq.com/
2026
-
[4]
Matthias Brantner, Daniela Florescu, David Graf, Donald Kossmann, and Tim Kraska. 2008. Building a database on S3. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data (Vancouver, Canada) (SIGMOD ’08). Association for Computing Machinery, New York, NY, USA, 251–264. https: //doi.org/10.1145/1376616.1376645
-
[5]
Confluent. 2026. WarpStream – The Diskless, Kafka-Compatible Data Streaming Platform. https://www.warpstream.com/
2026
-
[6]
Benoit Dageville, Thierry Cruanes, Marcin Zukowski, Vadim Antonov, Artin Avanes, Jon Bock, Jonathan Claybaugh, Daniel Engovatov, Martin Hentschel, Jiansheng Huang, Allison W. Lee, Ashish Motivala, Abdul Q. Munir, Steven Pelley, Peter Povinec, Greg Rahn, Spyridon Triantafyllis, and Philipp Unterbrunner. 2016. The Snowflake Elastic Data Warehouse. In Procee...
-
[7]
Jeffrey Dean and Sanjay Ghemawat. 2008. MapReduce: Simplified Data Pro- cessing on Large Clusters. Commun. ACM 51, 1 (Jan. 2008), 107–113. https: //doi.org/10.1145/1327452.1327492
-
[8]
Dominik Durner, Viktor Leis, and Thomas Neumann. 2023. Exploiting Cloud Object Storage for High-Performance Analytics. Proc. VLDB Endow. 16, 11 (July 2023), 2769–2782. https://doi.org/10.14778/3611479.3611486
-
[9]
Marios Fragkoulis, Paris Carbone, Vasiliki Kalavri, and Asterios Katsifodimos
-
[10]
https://doi.org/10.1007/s00778-023-00819-8
A survey on the evolution of stream processing systems.The VLDB Journal 33, 2 (2024), 507–541. https://doi.org/10.1007/s00778-023-00819-8
-
[11]
Greg Harris, Ivan Yurchenko, Jorge Quilcate, Giuseppe Lillo, Anatolii Popov, Juha Mynttinen, Josep Prat, and Filip Yonov. 2025. Kafka Improvement Proposals: KIP- 1150: Diskless Topics. https://cwiki.apache.org/confluence/display/KAFKA/KIP- 1150%3A+Diskless+Topics
2025
-
[12]
Michael Haubenschild and Viktor Leis. 2025. OLTP in the Cloud: Architectures, Tradeoffs, and Cost. The VLDB Journal 34, 4 (2025), 42. https://doi.org/10.1007/ s00778-025-00913-z
2025
-
[13]
Sören Henning and Wilhelm Hasselbring. 2021. How to Measure Scalability of Distributed Stream Processing Engines?. In Companion of the ACM/SPEC International Conference on Performance Engineering . ACM. https://doi.org/10. 1145/3447545.3451190
arXiv 2021
-
[14]
Sören Henning and Wilhelm Hasselbring. 2022. A Configurable Method for Benchmarking Scalability of Cloud-Native Applications. Empirical Software Engineering 27, 6 (Aug. 2022). https://doi.org/10.1007/s10664-022-10162-1
-
[15]
Sören Henning and Wilhelm Hasselbring. 2024. Benchmarking scalability of stream processing frameworks deployed as microservices in the cloud.Journal of Systems and Software 208 (2024), 111879. https://doi.org/10.1016/j.jss.2023.111879
-
[16]
Sören Henning, Adriano Vogel, and Otmar Ertl. 2026. BlobShuffle. https: //github.com/dynatrace-research/BlobShuffle
2026
-
[17]
Sören Henning, Adriano Vogel, Michael Leichtfried, Otmar Ertl, and Rick Rabiser
-
[18]
ShuffleBench: A Benchmark for Large-Scale Data Shuffling Operations with Distributed Stream Processing Frameworks. InProceedings of the 15th ACM/SPEC International Conference on Performance Engineering (London, United Kingdom) (ICPE ’24). ACM, 2–13. https://doi.org/10.1145/3629526.3645036
-
[19]
Sören Henning, Adriano Vogel, Esteban Perez-Wohlfeil, Otmar Ertl, and Rick Rabiser. 2025. When Should I Run My Application Benchmark? Studying Cloud Performance Variability for the Case of Stream Processing Applications. In Proceedings of the 33rd ACM International Conference on the Foundations of Soft- ware Engineering (Clarion Hotel Trondheim, Trondheim...
-
[20]
Rodrigo Laigner, Ana Carolina Almeida, Wesley K. G. Assunção, and Yongluan Zhou. 2025. An Empirical Study on Challenges of Event Management in Microservice Architectures. ACM Trans. Softw. Eng. Methodol. (Dec. 2025). https://doi.org/10.1145/3776581
-
[21]
Frank Sifei Luan, Stephanie Wang, Samyukta Yagati, Sean Kim, Kenneth Lien, Isaac Ong, Tony Hong, Sangbin Cho, Eric Liang, and Ion Stoica. 2023. Exoshuffle: An Extensible Shuffle Architecture. In Proceedings of the ACM SIGCOMM 2023 Conference (New York, NY, USA) (ACM SIGCOMM ’23). Association for Comput- ing Machinery, New York, NY, USA, 564–577. https://d...
-
[22]
Yuan Mei, Rui Xia, Zhaoqian Lan, Kaitian Hu, Lei Huang, Paris Carbone, Yanfei Lei, Vasiliki Kalavri, Han Yin, and Feng Wang. 2025. Disaggregated State Man- agement in Apache Flink® 2.0. Proc. VLDB Endow. 18, 12 (Aug. 2025), 4846–4859. https://doi.org/10.14778/3750601.3750609
-
[23]
Matteo Merli, Sijie Guo, Penghui Li, Hang Chen, and Neng Lu. 2025. Ursa: A Lakehouse-Native Data Streaming Engine for Kafka. Proc. VLDB Endow. 18, 12 (Aug. 2025), 5184–5196. https://doi.org/10.14778/3750601.3750636
-
[24]
Nikolaos Nikitas, Ioannis Konstantinou, Vana Kalogeraki, and Nectarios Koziris
-
[25]
In 2021 IEEE International Conference on Big Data (Big Data)
Cherry: A Distributed Task-Aware Shuffle Service for Serverless Analytics. In 2021 IEEE International Conference on Big Data (Big Data) . 120–130. https: //doi.org/10.1109/BigData52589.2021.9671899
-
[26]
Tobias Pfandzelter, Sören Henning, Trever Schirmer, Wilhelm Hasselbring, and David Bermbach. 2022. Streaming vs. Functions: A Cost Perspective on Cloud Event Processing. In 2022 IEEE International Conference on Cloud Engineering (IC2E). IEEE, 67–78. https://doi.org/10.1109/IC2E55432.2022.00015
-
[27]
Sax, Guozhang Wang, Matthias Weidlich, and Johann-Christoph Freytag
Matthias J. Sax, Guozhang Wang, Matthias Weidlich, and Johann-Christoph Freytag. 2018. Streams and Tables: Two Sides of the Same Coin. In Proceedings of the International Workshop on Real-Time Business Intelligence and Analytics (BIRTE ’18). ACM, 10. https://doi.org/10.1145/3242153.3242155
-
[28]
Min Shen, Ye Zhou, and Chandni Singh. 2020. Magnet: push-based shuffle service for large-scale data processing. Proc. VLDB Endow. 13, 12 (Aug. 2020), 3382–3395. https://doi.org/10.14778/3415478.3415558
-
[29]
Alexandre Verbitski, Anurag Gupta, Debanjan Saha, Murali Brahmadesam, Kamal Gupta, Raman Mittal, Sailesh Krishnamurthy, Sandor Maurice, Tengiz Kharatishvili, and Xiaofeng Bao. 2017. Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases. In Proceedings of the 2017 ACM International Conference on Management of Data (Chic...
-
[30]
Adriano Vogel, Sören Henning, Esteban Perez-Wohlfeil, Otmar Ertl, and Rick Rabiser. 2024. A Comprehensive Benchmarking Analysis of Fault Recovery in Stream Processing Frameworks. In Proceedings of the 18th ACM International Conference on Distributed and Event-Based Systems (Villeurbanne, France) (DEBS ’24). ACM, 171–182. https://doi.org/10.1145/3629104.3666040
-
[31]
Sax, John Roesler, Sophie Blee-Goldman, Bruno Cadonna, Apurva Mehta, Varun Madan, and Jun Rao
Guozhang Wang, Lei Chen, Ayusman Dikshit, Jason Gustafson, Boyang Chen, Matthias J. Sax, John Roesler, Sophie Blee-Goldman, Bruno Cadonna, Apurva Mehta, Varun Madan, and Jun Rao. 2021. Consistency and Completeness: Re- thinking Distributed Stream Processing in Apache Kafka. In Proceedings of the 2021 International Conference on Management of Data (SIGMOD/...
-
[32]
Wang Yue, Martin Boissier, and Tilmann Rabl. 2024. A Survey of Stream Process- ing System Benchmarks. In Performance Evaluation and Benchmarking: 16th TPC Technology Conference, TPCTC 2024, Guangzhou, China, August 30, 2024, Revised Selected Papers (Guangzhou, China). Springer-Verlag, Berlin, Heidelberg, 24–43. https://doi.org/10.1007/978-3-031-93858-0_2
-
[33]
Freedman
Haoyu Zhang, Brian Cho, Ergin Seyfe, Avery Ching, and Michael J. Freedman
-
[34]
InProceedings of the Thirteenth EuroSys Conference (Porto, Portugal) (EuroSys ’18)
Riffle: optimized shuffle service for large-scale data analytics. InProceedings of the Thirteenth EuroSys Conference (Porto, Portugal) (EuroSys ’18). Association for Computing Machinery, New York, NY, USA, Article 43, 15 pages. https: //doi.org/10.1145/3190508.3190534
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.