Learn from Your Mistakes: Tree-like Self-Play for Secure Code LLMs
Pith reviewed 2026-06-28 09:38 UTC · model grok-4.3
The pith
Tree-like Self-Play reframes LLM code generation as a branching self-play game that forces discrimination against localized vulnerabilities at critical decision nodes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
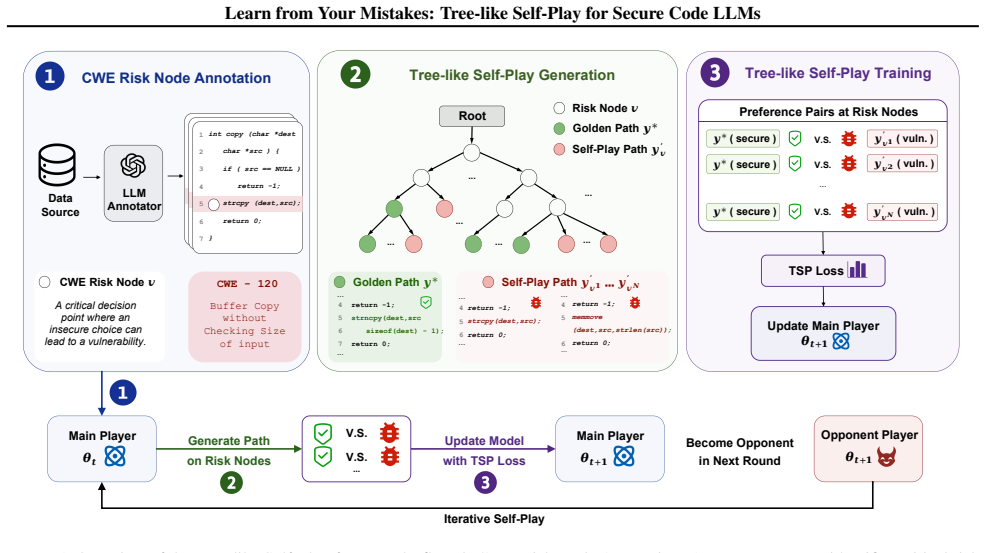
TSP constructs a decision tree in which the model generates both secure trajectories and vulnerable branches from the same prompt; by treating the process as self-play, the training signal compels the model to reject its own localized mistakes at the precise nodes where vulnerabilities first appear, replacing the diffuse likelihood maximization of SFT and unstructured self-play.
What carries the argument
Tree-like Self-Play decision tree whose branching trajectories supply on-policy contrasts between secure and vulnerable code at the exact decision nodes where security flaws arise.
If this is right
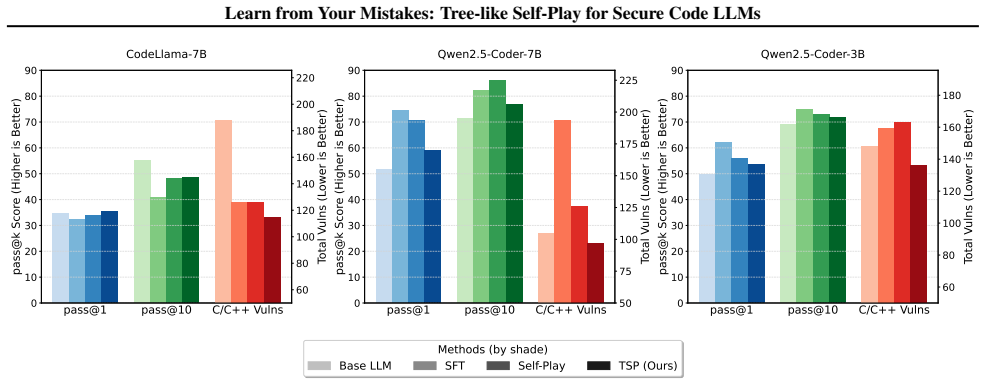
- CodeLlama-7B reaches 75.8 percent SPR@1 on Python security benchmarks versus 57 percent under SFT.
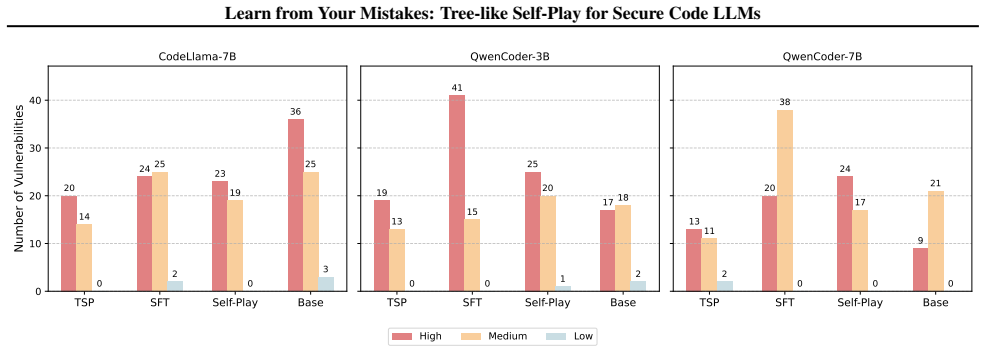
- Vulnerability incidence drops 24.5 percent on previously unseen CWE categories.
- Security principles learned from C/C++ training data transfer to Python, Go, and JavaScript without further language-specific fine-tuning.
- The method supplies a denser corrective gradient than unstructured self-play because errors are isolated at individual decision nodes rather than averaged over whole sequences.
Where Pith is reading between the lines
- The same branching self-play structure could be tested on non-security tasks such as mathematical proof steps where a single incorrect lemma invalidates the entire argument.
- If the tree depth and branching factor can be scaled without exploding compute, the approach might reduce reliance on curated secure-code datasets by generating its own contrastive examples on the fly.
- Models trained this way may exhibit fewer cascading failures in long codebases because they learn to reject bad choices before they compound.
Load-bearing premise
That the model's own generated vulnerable variants, when placed in explicit branching contrast with secure paths, will reliably produce a learning signal strong enough to correct localized errors without external labels or human feedback.
What would settle it
Train an identical base model with TSP and with ordinary SFT on the same data volume, then measure whether the TSP model still reduces vulnerability rates by roughly 24 percent on held-out CWE categories and non-C/C++ languages; absence of that gap would falsify the central mechanism.
Figures
read the original abstract
While Large Language Models (LLMs) excel in code generation, they remain prone to replicating subtle yet critical vulnerabilities endemic to their training data. Current alignment techniques, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL), typically apply coarse-grained optimization at the sequence level. This approach often fails to address the localized nature of security flaws, where a single incorrect token choice can compromise an entire program. To bridge this gap, we introduce Tree-like Self-Play (TSP), a framework that reframes secure code generation as a fine-grained sequential decision process. Unlike standard methods that blindly maximize likelihood, TSP constructs a decision tree where the model explores branching trajectories--generating both secure "golden paths" and vulnerable variants. By treating code generation as a self-play game, the model learns to strictly discriminate against its own localized errors. This provides a dense, on-policy learning signal that forces self-correction precisely at the critical decision nodes where vulnerabilities typically emerge. Our experiments demonstrate that TSP fundamentally enhances model reliability. In Python security benchmarks, TSP boosts CodeLlama-7B's pass rate (SPR@1) to 75.8%, significantly outperforming SFT (57.0%) and unstructured self-play baselines. Crucially, TSP induces robust out-of-distribution generalization: the model not only reduces vulnerabilities in unseen categories (CWEs) by 24.5% but also successfully transfers security principles learned from C/C++ to diverse languages, including Python, Go, and JavaScript. This suggests that TSP does not merely memorize patches, but internalizes abstract, language-agnostic security logic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Tree-like Self-Play (TSP), a framework that models secure code generation as a fine-grained sequential decision process on a decision tree. The model generates branching trajectories consisting of secure 'golden paths' and vulnerable variants, treating generation as self-play to learn to discriminate against its own localized errors at critical nodes. Experiments on CodeLlama-7B report an SPR@1 of 75.8% on Python security benchmarks (vs. 57.0% for SFT and lower for unstructured self-play), a 24.5% reduction in vulnerabilities for unseen CWEs, and successful transfer of security principles from C/C++ training to Python, Go, and JavaScript.
Significance. If the results hold, the work is significant for secure code generation because it supplies a dense on-policy signal at vulnerability-critical decision points, addressing the limitations of coarse sequence-level optimization in SFT and RL. The reported OOD generalization to unseen CWEs and cross-language transfer, supported by ablations against unstructured self-play, indicates the model may internalize abstract security logic rather than memorize patches. The concrete details on trajectory construction, reward assignment, and training procedure make the attribution to the tree mechanism traceable.
minor comments (2)
- [Abstract] Abstract: the performance numbers and generalization claims are stated without accompanying experimental details, dataset descriptions, tree-construction procedure, or baseline implementations; while the full manuscript supplies these, the abstract should briefly indicate the scale of the evaluation to set reader expectations.
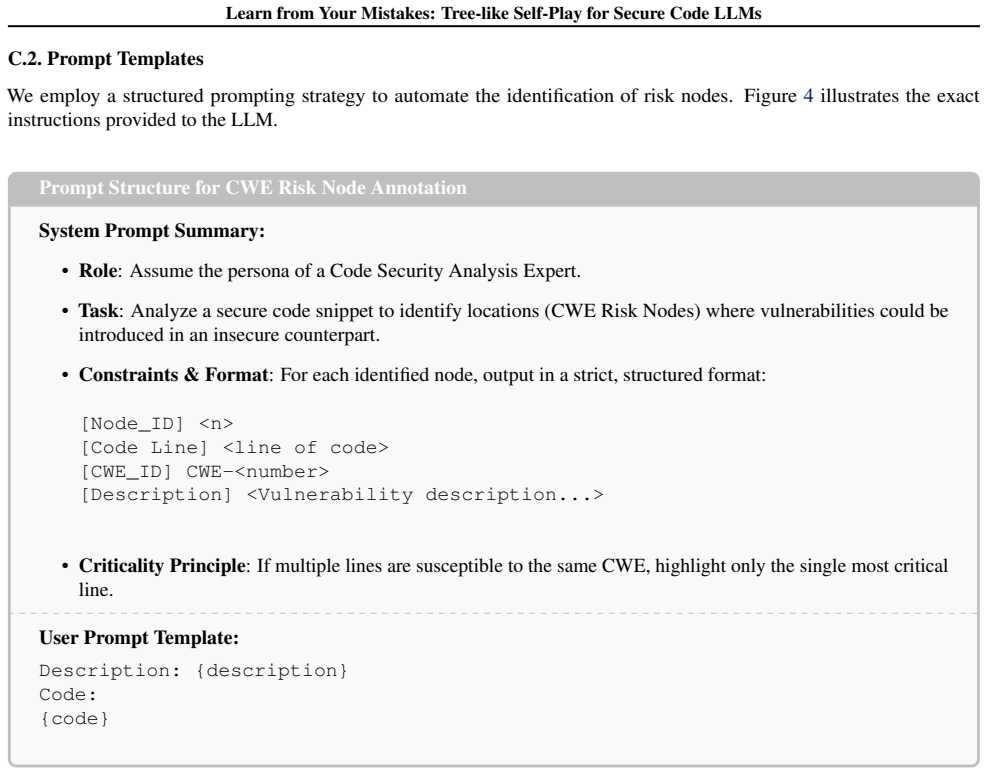
- Method section: a pseudocode listing or explicit diagram of the branching trajectory construction and reward assignment at each node would improve clarity of how the dense learning signal is generated at vulnerability-critical points.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The referee's description of TSP and its reported gains (SPR@1 of 75.8%, OOD CWE reduction, cross-language transfer) matches the manuscript. No major comments were listed in the report, so we provide no point-by-point responses below. We will address any minor editorial or clarification items in the revised version.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper introduces Tree-like Self-Play (TSP) as a novel framework for secure code generation, describing trajectory construction, reward assignment, and training in concrete terms. Performance claims (SPR@1 gains, CWE reduction, cross-language transfer) are tied to explicit experimental comparisons against SFT and unstructured self-play baselines. No equations reduce a claimed result to a fitted parameter by construction, no load-bearing premise rests solely on self-citation, and no ansatz or uniqueness theorem is smuggled in. The method and metrics are traceable to the stated mechanism without internal reduction to inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Frontiers in Big Data , volume=
A systematic literature review on the impact of AI models on the security of code generation , author=. Frontiers in Big Data , volume=. 2024 , publisher=
2024
-
[2]
Proceedings of the 2024 ACM Southeast Conference , pages =
Jamdade, Mahesh and Liu, Yi , title =. Proceedings of the 2024 ACM Southeast Conference , pages =. 2024 , isbn =. doi:10.1145/3603287.3651194 , abstract =
-
[3]
Communications of the ACM , volume=
Asleep at the keyboard? assessing the security of github copilot’s code contributions , author=. Communications of the ACM , volume=. 2025 , publisher=
2025
-
[4]
Proceedings of the 2023 ACM SIGSAC conference on computer and communications security , pages=
Do users write more insecure code with ai assistants? , author=. Proceedings of the 2023 ACM SIGSAC conference on computer and communications security , pages=
2023
-
[5]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[6]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[7]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Advances in neural information processing systems , volume=
Deep reinforcement learning from human preferences , author=. Advances in neural information processing systems , volume=
-
[9]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[10]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
arXiv preprint arXiv:2402.10184 , year=
Reward generalization in rlhf: A topological perspective , author=. arXiv preprint arXiv:2402.10184 , year=
-
[12]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Preference ranking optimization for human alignment , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[13]
arXiv preprint arXiv:2506.11902 , year=
TreeRL: LLM Reinforcement Learning with On-Policy Tree Search , author=. arXiv preprint arXiv:2506.11902 , year=
-
[14]
Forty-first International Conference on Machine Learning , year=
Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data , author=. Forty-first International Conference on Machine Learning , year=
-
[15]
arXiv preprint arXiv:2405.08448 , year=
Understanding the performance gap between online and offline alignment algorithms , author=. arXiv preprint arXiv:2405.08448 , year=
-
[16]
Forty-first International Conference on Machine Learning , year=
Instruction Tuning for Secure Code Generation , author=. Forty-first International Conference on Machine Learning , year=
-
[17]
Code Llama: Open Foundation Models for Code
Code llama: Open foundation models for code , author=. arXiv preprint arXiv:2308.12950 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Advances in Neural Information Processing Systems , volume=
Getting more juice out of the sft data: Reward learning from human demonstration improves sft for llm alignment , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
EMNLP , year=
How to Leverage Demonstration Data in Alignment for Large Language Model? A Self-Imitation Learning Perspective , author=. EMNLP , year=
-
[20]
arXiv preprint arXiv:2411.12882 , year=
ProSec: Fortifying Code LLMs with Proactive Security Alignment , author=. arXiv preprint arXiv:2411.12882 , year=
-
[21]
Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security , pages=
Large language models for code: Security hardening and adversarial testing , author=. Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security , pages=
2023
-
[22]
2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=
Data quality for software vulnerability datasets , author=. 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) , pages=. 2023 , organization=
2023
-
[23]
Proceedings of the 17th International Conference on Mining Software Repositories , pages=
AC/C++ code vulnerability dataset with code changes and CVE summaries , author=. Proceedings of the 17th International Conference on Mining Software Repositories , pages=
-
[24]
Information and Software Technology , volume=
VUDENC: vulnerability detection with deep learning on a natural codebase for Python , author=. Information and Software Technology , volume=. 2022 , publisher=
2022
-
[25]
arXiv preprint arXiv:2409.06446 , year=
HexaCoder: Secure Code Generation via Oracle-Guided Synthetic Training Data , author=. arXiv preprint arXiv:2409.06446 , year=
-
[26]
International conference on machine learning , pages=
Fictitious self-play in extensive-form games , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[27]
Neural computation , volume=
TD-Gammon, a self-teaching backgammon program, achieves master-level play , author=. Neural computation , volume=. 1994 , publisher=
1994
-
[28]
Dota 2 with Large Scale Deep Reinforcement Learning
Dota 2 with large scale deep reinforcement learning , author=. arXiv preprint arXiv:1912.06680 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[29]
nature , volume=
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
2016
-
[30]
Forty-first International Conference on Machine Learning , year=
A Minimaximalist Approach to Reinforcement Learning from Human Feedback , author=. Forty-first International Conference on Machine Learning , year=
-
[31]
Forty-first International Conference on Machine Learning , year=
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models , author=. Forty-first International Conference on Machine Learning , year=
-
[32]
arXiv preprint arXiv:2404.03715 , year=
Direct nash optimization: Teaching language models to self-improve with general preferences , author=. arXiv preprint arXiv:2404.03715 , year=
-
[33]
arXiv preprint arXiv:2305.10679 , year=
Think outside the code: Brainstorming boosts large language models in code generation , author=. arXiv preprint arXiv:2305.10679 , year=
-
[34]
ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=
RefleXGen: The unexamined code is not worth using , author=. ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2025 , organization=
2025
-
[35]
arXiv preprint arXiv:2410.05605 , year=
Codedpo: Aligning code models with self generated and verified source code , author=. arXiv preprint arXiv:2410.05605 , year=
-
[36]
Advances in Neural Information Processing Systems , volume=
Coderl: Mastering code generation through pretrained models and deep reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[37]
arXiv preprint arXiv:2410.02089 , year=
Rlef: Grounding code llms in execution feedback with reinforcement learning , author=. arXiv preprint arXiv:2410.02089 , year=
-
[38]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
StepCoder: Improving Code Generation with Reinforcement Learning from Compiler Feedback , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[39]
The Twelfth International Conference on Learning Representations , year=
WizardCoder: Empowering Code Large Language Models with Evol-Instruct , author=. The Twelfth International Conference on Learning Representations , year=
-
[40]
International Conference on Machine Learning , pages=
Magicoder: Empowering Code Generation with OSS-Instruct , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[41]
Science , volume=
Competition-level code generation with alphacode , author=. Science , volume=. 2022 , publisher=
2022
-
[42]
International Symposium on Theoretical Aspects of Software Engineering , pages=
Castle: Benchmarking dataset for static code analyzers and llms towards cwe detection , author=. International Symposium on Theoretical Aspects of Software Engineering , pages=. 2025 , organization=
2025
-
[43]
A survey on llm-as-a-judge , author=. arXiv preprint arXiv:2411.15594 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Proceedings of the 1st International Workshop on Mining Software Repositories Applications for Privacy and Security , pages=
SecurityEval dataset: mining vulnerability examples to evaluate machine learning-based code generation techniques , author=. Proceedings of the 1st International Workshop on Mining Software Repositories Applications for Privacy and Security , pages=
-
[45]
Autosafecoder: A multi-agent framework for securing llm code generation through static analysis and fuzz testing , author=. arXiv preprint arXiv:2409.10737 , year=
-
[46]
arXiv preprint arXiv:2512.07533 , year=
VulnLLM-R: Specialized Reasoning LLM with Agent Scaffold for Vulnerability Detection , author=. arXiv preprint arXiv:2512.07533 , year=
-
[47]
International Conference on Machine Learning , pages=
Token-level Direct Preference Optimization , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.