Efficient ASR Training with Conversations that Never Happened
Pith reviewed 2026-06-28 10:35 UTC · model grok-4.3
The pith
Synthetic conversations from LLMs and TTS let ASR models beat those trained on far more real speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
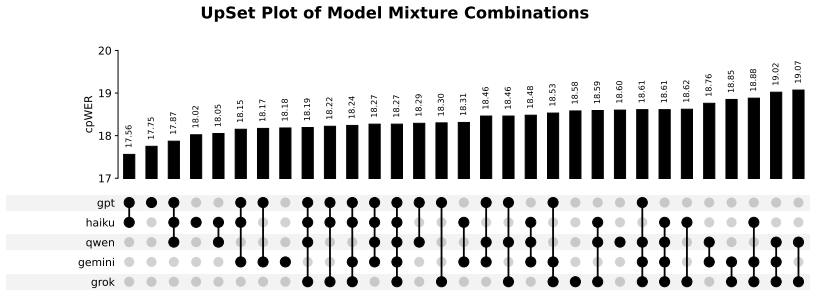
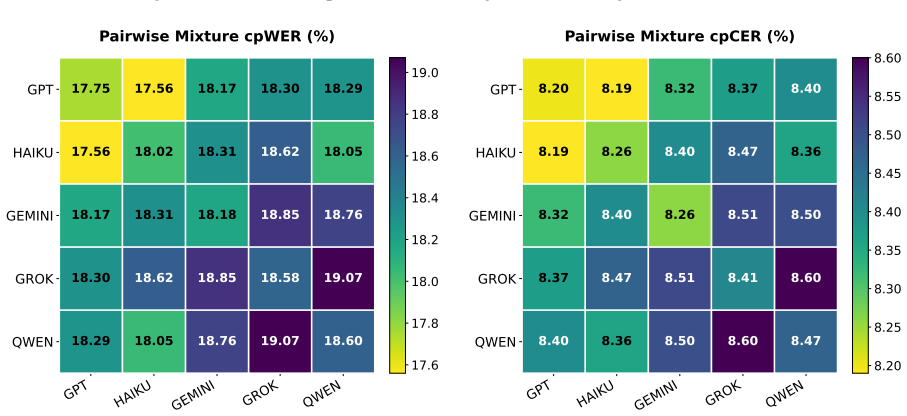
An LLM-TTS augmentation pipeline that produces scenario-level dialogues, assigns speaker metadata to TTS voices, and assembles them into simulated conversations consistently improves ASR accuracy when added to real conversational data. Across five LLM families, fixed-budget mixtures, and scale-up experiments using the same training recipe, the largest configuration of 67 hours real plus 636 hours simulated data outperforms a zero-shot model trained on 2700 hours of Hungarian speech on the BEA-Dialogue benchmark.
What carries the argument
The LLM-TTS pipeline that generates scenario-level dialogues with participant metadata, maps speaker attributes to TTS voice profiles, and assembles synthesized utterances into speaker-aware simulated conversations.
If this is right
- Mixing real and synthetic conversational data produces higher ASR accuracy than real data alone under the same training recipe.
- Generator choice and the real-to-synthetic ratio strongly influence the size of the accuracy gain.
- The same FastConformer-Large recipe works across different LLM generators without retuning.
- The pipeline can be applied to any language once suitable LLM and TTS components are available.
- Synthetic conversations serve as a practical complement rather than a full replacement for real conversational corpora.
Where Pith is reading between the lines
- ASR data collection budgets could shift toward smaller real corpora supplemented by generated dialogues.
- The same generation approach might extend to other low-resource speech tasks such as speaker diarization or emotion recognition.
- Domain-specific ASR for niche topics could become feasible without collecting large in-domain real recordings.
- Quality filtering or post-processing of the synthetic conversations may be needed to maintain gains at larger scales.
Load-bearing premise
The generated conversations must match real ones closely enough in acoustic and linguistic properties to supply useful training signal without adding harmful biases or artifacts.
What would settle it
An experiment that trains an ASR model on the synthetic data alone and measures performance equal to or below an equivalent amount of real conversational data would falsify the usefulness claim.
Figures

read the original abstract
Conversational ASR for lower-resource languages and niche domains is limited by the scarcity of domain-matched multi-speaker training data. We propose an augmentation pipeline that generates scenario-level dialogues with participant metadata, maps speaker attributes to TTS voice profiles, and assembles synthesized utterances into speaker-aware simulated conversations. We evaluated five LLM families under single-generator, fixed-budget mixture, and scale-up settings using the same FastConformer-Large training recipe for each one. We ran comprehensive evaluations on the Hungarian BEA-Dialogue benchmark corpus, with the method itself being applicable to any language given the resources for each component. The results show that synthetic conversations consistently improve speech recognition performance, but generator choice and data composition strongly affect the gains. Our largest training configuration, using only 67 hours of real conversations and 636 hours of simulated data, achieves better performance on the evaluation benchmark than a zero-shot model trained on 2700 hours of Hungarian speech. These findings indicate that LLM-generated conversational data synthesized with TTS is a practical complement to real conversational corpora for speech model training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an LLM-TTS pipeline to generate scenario-level multi-speaker dialogues with metadata, synthesize them into speaker-aware conversations, and mix them with limited real data to train conversational ASR models. Using a fixed FastConformer-Large recipe, it evaluates five LLM families on the Hungarian BEA-Dialogue benchmark under single-generator, mixture, and scale-up regimes. The central empirical claim is that a configuration with 67 hours real + 636 hours synthetic data outperforms a zero-shot model trained on 2700 hours of Hungarian speech, indicating synthetic conversational data as a practical complement for low-resource settings.
Significance. If the headline comparison holds under matched conditions, the work would be significant for data-efficient ASR in conversational and low-resource domains by showing scalable augmentation via LLM-generated dialogues. The consistent training recipe across LLM families is a strength that isolates generator effects, and the method's language-agnostic framing (given component resources) broadens applicability. Reproducible elements like the fixed recipe aid verification.
major comments (2)
- [Abstract] Abstract (and experimental results): The claim that the 67h real + 636h synthetic configuration outperforms the 2700h zero-shot model is load-bearing for the paper's main result, yet the baseline's architecture, pretraining, optimization, and whether its data is conversationally matched are unspecified, while all synthetic experiments explicitly use the FastConformer-Large recipe. This prevents attributing gains to the proposed pipeline rather than model differences.
- [Experiments] Experiments section: No details are provided on statistical significance testing, confidence intervals, or variance across runs for the reported WER improvements, which is necessary to establish that the gains from synthetic mixtures are robust rather than due to training stochasticity.
minor comments (1)
- [Method] The description of the TTS voice profile mapping and speaker metadata assembly could be expanded with a diagram or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify areas where additional clarity will strengthen the paper. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (and experimental results): The claim that the 67h real + 636h synthetic configuration outperforms the 2700h zero-shot model is load-bearing for the paper's main result, yet the baseline's architecture, pretraining, optimization, and whether its data is conversationally matched are unspecified, while all synthetic experiments explicitly use the FastConformer-Large recipe. This prevents attributing gains to the proposed pipeline rather than model differences.
Authors: We agree that explicit specification of the baseline is required for a fair attribution of gains. The manuscript currently refers to the 2700-hour model only as a zero-shot model trained on Hungarian speech without matching the level of detail given to the FastConformer-Large recipe. In the revised version we will expand both the abstract and the experiments section to fully describe the baseline's architecture, pretraining, optimization procedure, and data characteristics (including whether the data is conversationally matched), noting any differences from our synthetic training setup. This revision will allow readers to evaluate whether performance differences arise from the proposed pipeline. revision: yes
-
Referee: [Experiments] Experiments section: No details are provided on statistical significance testing, confidence intervals, or variance across runs for the reported WER improvements, which is necessary to establish that the gains from synthetic mixtures are robust rather than due to training stochasticity.
Authors: We acknowledge that reporting variance and statistical measures would increase confidence in the robustness of the WER gains. The current manuscript presents single-run results for each configuration. In the revision we will add results from multiple independent training runs (different random seeds) for the key real-plus-synthetic mixtures, reporting mean WER together with standard deviation. Where computational resources permit, we will also include approximate confidence intervals and note any formal significance testing performed between the main configurations. revision: yes
Circularity Check
Empirical evaluation with no derivation chain or self-referential results
full rationale
This is an empirical study that generates synthetic conversational data via an LLM-TTS pipeline, trains FastConformer-Large ASR models on various real+synthetic mixtures, and reports direct performance comparisons (WER) on the BEA-Dialogue benchmark. No equations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation load-bearing steps appear in the described method or results. The central claim is a numerical outcome of training on 67h real + 636h synthetic data versus a 2700h baseline; this is a standard data-mixture ablation and does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- LLM family choice
- Data mixture ratios
axioms (2)
- domain assumption TTS systems can accurately render speaker attributes from metadata into distinct voices.
- domain assumption LLM-generated dialogues are sufficiently realistic for ASR training purposes.
Reference graph
Works this paper leans on
-
[1]
and Mohamed, Abdel-rahman and Jaitly, Navdeep and Senior, Andrew and Vanhoucke, Vincent and Nguyen, Patrick and Sainath, Tara N
Hinton, Geoffrey and Deng, Li and Yu, Dong and Dahl, George E. and Mohamed, Abdel-rahman and Jaitly, Navdeep and Senior, Andrew and Vanhoucke, Vincent and Nguyen, Patrick and Sainath, Tara N. and Kingsbury, Brian , journal=. Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared Views of Four Research Groups , year=
-
[2]
doi:10.21437/Interspeech.2024-2016 , issn =
Edresson Casanova and Kelly Davis and Eren Gölge and Görkem Göknar and Iulian Gulea and Logan Hart and Aya Aljafari and Joshua Meyer and Reuben Morais and Samuel Olayemi and Julian Weber , year =. doi:10.21437/Interspeech.2024-2016 , issn =
-
[3]
Listen, attend and spell: A neural network for large vocabulary conversational speech recognition , year=
Chan, William and Jaitly, Navdeep and Le, Quoc and Vinyals, Oriol , booktitle=. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition , year=
-
[4]
Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =
Baevski, Alexei and Zhou, Henry and Mohamed, Abdelrahman and Auli, Michael , title =. Proceedings of the 34th International Conference on Neural Information Processing Systems , articleno =. 2020 , isbn =
2020
-
[5]
Shinji Watanabe and Michael Mandel and Jon Barker and Emmanuel Vincent and Ashish Arora and Xuankai Chang and Sanjeev Khudanpur and Vimal Manohar and Daniel Povey and Desh Raj and David Snyder and Aswin Shanmugam Subramanian and Jan Trmal and Bar Ben Yair and Christoph Boeddeker and Zhaoheng Ni and Yusuke Fujita and Shota Horiguchi and Naoyuki Kanda and T...
-
[6]
Samuele Cornell and Jordan Darefsky and Zhiyao Duan and Shinji Watanabe , year =
-
[7]
Proceedings of the 40th International Conference on Machine Learning , articleno =
Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya , title =. Proceedings of the 40th International Conference on Machine Learning , articleno =. 2023 , publisher =
2023
-
[8]
Automatic speech recognition for under-resourced languages: A survey , journal =
Laurent Besacier and Etienne Barnard and Alexey Karpov and Tanja Schultz , keywords =. Automatic speech recognition for under-resourced languages: A survey , journal =. 2014 , issn =. doi:https://doi.org/10.1016/j.specom.2013.07.008 , url =
-
[9]
doi:10.21437/Interspeech.2015-711 , issn =
Tom Ko and Vijayaditya Peddinti and Daniel Povey and Sanjeev Khudanpur , year =. doi:10.21437/Interspeech.2015-711 , issn =
-
[10]
Park and William Chan and Yu Zhang and Chung-Cheng Chiu and Barret Zoph and Ekin D
Daniel S. Park and William Chan and Yu Zhang and Chung-Cheng Chiu and Barret Zoph and Ekin D. Cubuk and Quoc V. Le , year =. doi:10.21437/Interspeech.2019-2680 , issn =
-
[11]
Skerry-Ryan and Daisy Stanton and Yonghui Wu and Ron J
Yuxuan Wang and R.J. Skerry-Ryan and Daisy Stanton and Yonghui Wu and Ron J. Weiss and Navdeep Jaitly and Zongheng Yang and Ying Xiao and Zhifeng Chen and Samy Bengio and Quoc Le and Yannis Agiomyrgiannakis and Rob Clark and Rif A. Saurous , year =. doi:10.21437/Interspeech.2017-1452 , issn =
-
[12]
and Schuster, Mike and Jaitly, Navdeep and Yang, Zongheng and Chen, Zhifeng and Zhang, Yu and Wang, Yuxuan and Skerrv-Ryan, Rj and Saurous, Rif A
Shen, Jonathan and Pang, Ruoming and Weiss, Ron J. and Schuster, Mike and Jaitly, Navdeep and Yang, Zongheng and Chen, Zhifeng and Zhang, Yu and Wang, Yuxuan and Skerrv-Ryan, Rj and Saurous, Rif A. and Agiomvrgiannakis, Yannis and Wu, Yonghui , booktitle=. Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions , year=
-
[13]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[14]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
2022
-
[15]
Gedeon, Máté and Mihajlik, Péter , year=. From Independence to Interaction: Speaker-Aware Simulation of Multi-Speaker Conversational Timing , url=. doi:10.1109/icassp55912.2026.11464311 , booktitle=
-
[16]
doi:10.21437/Interspeech.2022-10451 , issn =
Federico Landini and Alicia Lozano-Diez and Mireia Diez and Lukáš Burget , year =. doi:10.21437/Interspeech.2022-10451 , issn =
-
[17]
Natsuo Yamashita and Shota Horiguchi and Takeshi Homma , year =
-
[18]
doi:10.21437/Interspeech.2019-2899 , issn =
Yusuke Fujita and Naoyuki Kanda and Shota Horiguchi and Kenji Nagamatsu and Shinji Watanabe , year =. doi:10.21437/Interspeech.2019-2899 , issn =
-
[19]
Toward Conversational Hungarian Speech Recognition: Introducing the
M. Toward Conversational Hungarian Speech Recognition: Introducing the. LREC 2026 , year =
2026
-
[20]
Speaker-Aware Simulation Improves Conversational Speech Recognition , journal =
M. Speaker-Aware Simulation Improves Conversational Speech Recognition , journal =. 2026 , doi =
2026
-
[21]
Graves, Alex and Fern\'. Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks , year =. Proceedings of the 23rd International Conference on Machine Learning , pages =. doi:10.1145/1143844.1143891 , abstract =
-
[22]
Proceedings of The 33rd International Conference on Machine Learning , pages =
Deep Speech 2 : End-to-End Speech Recognition in English and Mandarin , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , editor =
2016
-
[23]
doi:10.21437/Interspeech.2020-3015 , issn =
Anmol Gulati and James Qin and Chung-Cheng Chiu and Niki Parmar and Yu Zhang and Jiahui Yu and Wei Han and Shibo Wang and Zhengdong Zhang and Yonghui Wu and Ruoming Pang , year =. doi:10.21437/Interspeech.2020-3015 , issn =
-
[24]
Hsu, Wei-Ning and Bolte, Benjamin and Tsai, Yao-Hung Hubert and Lakhotia, Kushal and Salakhutdinov, Ruslan and Mohamed, Abdelrahman , title =. IEEE/ACM Trans. Audio, Speech and Lang. Proc. , month = oct, pages =. 2021 , issue_date =. doi:10.1109/TASLP.2021.3122291 , abstract =
-
[25]
2016 , booktitle =
Aäron. 2016 , booktitle =
2016
-
[26]
Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =
Ren, Yi and Ruan, Yangjun and Tan, Xu and Qin, Tao and Zhao, Sheng and Zhao, Zhou and Liu, Tie-Yan , title =. Proceedings of the 33rd International Conference on Neural Information Processing Systems , articleno =. 2019 , publisher =
2019
-
[27]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[28]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina. BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v...
-
[29]
A Simple Systematic for the Organisation of Turn Taking in Conversation , volume =
Sacks, Harvey and Schegloff, Emanuel and Jefferson, Gail , year =. A Simple Systematic for the Organisation of Turn Taking in Conversation , volume =. Language , doi =
-
[30]
and Holliman, E.C
Godfrey, J.J. and Holliman, E.C. and McDaniel, J. , booktitle=. SWITCHBOARD: telephone speech corpus for research and development , year=
-
[31]
and Baron, D
Janin, A. and Baron, D. and Edwards, J. and Ellis, D. and Gelbart, D. and Morgan, N. and Peskin, B. and Pfau, T. and Shriberg, E. and Stolcke, A. and Wooters, C. , booktitle=. The ICSI Meeting Corpus , year=
-
[32]
The AMI Meeting Corpus: A Pre-announcement
Carletta, Jean and Ashby, Simone and Bourban, Sebastien and Flynn, Mike and Guillemot, Mael and Hain, Thomas and Kadlec, Jaroslav and Karaiskos, Vasilis and Kraaij, Wessel and Kronenthal, Melissa and Lathoud, Guillaume and Lincoln, Mike and Lisowska, Agnes and McCowan, Iain and Post, Wilfried and Reidsma, Dennis and Wellner, Pierre. The AMI Meeting Corpus...
2006
-
[33]
Joshua T. Goodman , abstract =. A bit of progress in language modeling , journal =. 2001 , issn =. doi:https://doi.org/10.1006/csla.2001.0174 , url =
-
[34]
Daniel Jurafsky and James H. Martin. Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition with Language Models. 2026
2026
-
[35]
2019 , eprint=
NeMo: a toolkit for building AI applications using Neural Modules , author=. 2019 , eprint=
2019
-
[36]
2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , year=
Fast Conformer With Linearly Scalable Attention For Efficient Speech Recognition , author=. 2023 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) , year=
2023
-
[37]
ArXiv , year=
Pheme: Efficient and Conversational Speech Generation , author=. ArXiv , year=
-
[38]
and He, Lei and Xie, Lei , booktitle=
Guo, Haohan and Zhang, Shaofei and Soong, Frank K. and He, Lei and Xie, Lei , booktitle=. Conversational End-to-End TTS for Voice Agents , year=
-
[39]
FireRedTTS-2: Towards Long Conversational Speech Generation for Podcast and Chatbot , doi =
Xie, Kun and Shen, Feiyu and Li, Junjie and Xie, Fenglong and Tang, Xu and Hu, Yao , year =. FireRedTTS-2: Towards Long Conversational Speech Generation for Podcast and Chatbot , doi =
-
[40]
Best Data is more Supervised Data – Even for Hungarian ASR , year =
Dobsinszki, Gergely and Mihajlik, P\'. Best Data is more Supervised Data – Even for Hungarian ASR , year =. Speech and Computer: 27th International Conference, SPECOM 2025, Szeged, Hungary, October 13–15, 2025, Proceedings, Part II , pages =. doi:10.1007/978-3-032-07959-6_5 , abstract =
-
[41]
Ferrer, Luciana and Riera, Pablo , title =
-
[42]
Development of a Large Spontaneous Speech Database of Agglutinative Hungarian Language
Neuberger, Tilda and Gyarmathy, Dorottya and Gr \'a czi, Tekla Etelka and Horv \'a th, Vikt \'o ria and G \'o sy, M \'a ria and Beke, Andr \'a s. Development of a Large Spontaneous Speech Database of Agglutinative Hungarian Language. Text, Speech and Dialogue. 2014
2014
-
[43]
2026 , eprint=
Scaling Conversational Hungarian ASR: The BEA-Dialogue+ Corpus , author=. 2026 , eprint=
2026
-
[44]
2026 , eprint=
OpenAI GPT-5 System Card , author=. 2026 , eprint=
2026
-
[45]
Gemini: A Family of Highly Capable Multimodal Models , doi =
Anil, Rohan and Borgeaud, Sebastian and Alayrac, Jean-Baptiste and Yu, Jiahui and Soricut, Radu and Schalkwyk, Johan and Dai, Andrew and Hauth, Anja and Millican, Katie and Silver, David and Johnson, Melvin and Antonoglou, Ioannis and Schrittwieser, Julian and Glaese, Amelia and Chen, Jilin and Pitler, Emily and Lillicrap, Timothy and Lazaridou, Angeliki ...
-
[46]
The Claude 3 Model Family: Opus, Sonnet, Haiku , author=
-
[47]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.