Can Generalist Agents Automate Data Curation?
Pith reviewed 2026-06-28 09:30 UTC · model grok-4.3
The pith
Scaffolded generalist agents autonomously compose data-selection policies that outperform published baselines at one-tenth the data budget.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
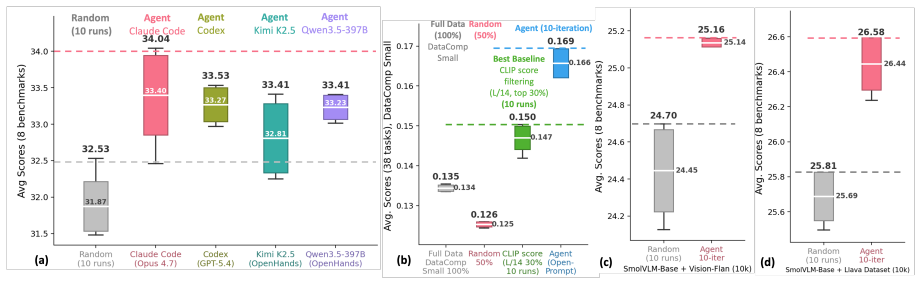
In the vision-language instruction-tuning instantiation of Curation-Bench, the scaffolded agent composes a data-selection policy that outperforms strong published baselines at one-tenth their data budget, with no human design input supplied during the agent's iterations.
What carries the argument
The scaffold requiring each iteration to cite, instantiate, and adapt a prior method, which converts open-ended prompting into method-guided exploration inside the fixed Curation-Bench loop.
If this is right
- Agents supplied with the scaffold can run complete data-curation loops without constant human oversight.
- Method-guided adaptation produces data policies that exceed the performance of hand-designed baselines at substantially lower data volume.
- The execution-research gap can be narrowed by requiring explicit citation and reuse of prior work rather than free-form invention.
- Open-sourcing Curation-Bench makes it possible to test whether the same scaffold pattern transfers to other model families and tasks.
Where Pith is reading between the lines
- If the scaffold pattern holds, labs could shift human effort from writing selection rules to writing the scaffolds themselves.
- The same loop might surface entirely new policy families that human researchers have not yet enumerated.
- Testing at larger model scales or noisier real-world data sources would show whether the one-tenth budget advantage survives increased complexity.
Load-bearing premise
The single vision-language instruction-tuning setup with its fixed training recipe and evaluation suite stands in for the wider range of noisy, cross-domain data-curation loops that practitioners actually run.
What would settle it
Running the identical scaffolded agent on a different domain such as text-only pretraining and finding that it no longer beats the published baselines even at the reduced data budget.
Figures



read the original abstract
Curating training data is among the most consequential yet labor-intensive parts of modern AI development: practitioners iteratively propose, implement, evaluate, and revise data policies against noisy benchmark feedback. We ask whether generalist coding agents can automate this data-curation loop. We introduce *Curation-Bench*, an agent-centric benchmark that fixes the model, training recipe, and evaluation suite while giving agents command-line access to inspect data, implement policies, submit them to a fixed training/evaluation pipeline, and revise. In a vision-language instruction-tuning instantiation, out-of-the-box agents reach strong published data-selection baselines within ten iterations. However, trajectory analysis reveals a persistent *execution-research gap*: agents mainly tune local policy variants rather than explore new policy families, even when given strategy guides and paper references. Scaffolds requiring each iteration to cite, instantiate, and adapt a prior method shift agents toward method-guided exploration. The scaffolded agent autonomously composes -- without human design input -- a data-selection policy that outperforms strong published baselines at one-tenth their data budget. Overall, current agents can run the curation loop, but reliable data research requires scaffolded method adaptation, not open-ended prompting alone. Code and benchmark are open-sourced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Curation-Bench, an agent-centric benchmark that fixes the model, training recipe, and evaluation suite while allowing agents command-line access to inspect data, implement policies, and iterate via a fixed pipeline. In a vision-language instruction-tuning instantiation, out-of-the-box agents reach strong published baselines within ten iterations, but trajectory analysis identifies an execution-research gap where agents tune local variants rather than explore new policy families. Scaffolds that require citing, instantiating, and adapting prior methods shift behavior toward method-guided exploration. The scaffolded agent autonomously composes a data-selection policy outperforming strong baselines at one-tenth their data budget. The work concludes that current agents can run the curation loop but reliable data research requires scaffolded method adaptation, and open-sources the benchmark and code.
Significance. If the empirical results hold under the reported controls, the paper contributes a reproducible benchmark and concrete evidence that generalist coding agents with targeted scaffolding can automate consequential steps in AI development pipelines. The open-sourcing of code and benchmark is a clear strength that supports follow-on work. The identification of the execution-research gap provides a useful diagnostic for agent capabilities in research-like tasks.
major comments (2)
- [Abstract] Abstract: The central claim that the scaffolded agent demonstrates general automation of data curation by autonomously composing a superior policy (outperforming baselines at 1/10 data budget) rests on experiments confined to a single vision-language instruction-tuning instantiation with fixed model, recipe, and evaluation suite. This narrow scope is load-bearing for the broader conclusion that 'reliable data research requires scaffolded method adaptation,' as the execution-research gap and scaffold benefits are measured only inside this benchmark; different domains, model scales, or noisier feedback loops could change how data policies interact with training dynamics. A concrete test would be to instantiate the same agent and scaffolds on at least one additional domain or scale.
- [Abstract] Abstract / results section: The outperformance result is presented without reported details on variance across runs, statistical significance tests, or ablation of the fixed training pipeline, which is needed to establish that the 1/10 data-budget advantage is robust rather than an artifact of the specific instantiation.
minor comments (1)
- [Abstract] The abstract and conclusion could more explicitly qualify the scope of the generalist-agent claim to the tested instantiation to avoid overgeneralization.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the scaffolded agent demonstrates general automation of data curation by autonomously composing a superior policy (outperforming baselines at 1/10 data budget) rests on experiments confined to a single vision-language instruction-tuning instantiation with fixed model, recipe, and evaluation suite. This narrow scope is load-bearing for the broader conclusion that 'reliable data research requires scaffolded method adaptation,' as the execution-research gap and scaffold benefits are measured only inside this benchmark; different domains, model scales, or noisier feedback loops could change how data policies interact with training dynamics. A concrete test would be to instantiate the same agent and scaffolds on at least one additional domain or scale.
Authors: Curation-Bench is intentionally designed with a fixed model, training recipe, and evaluation suite precisely to isolate agent behavior in the data-curation loop and to enable reproducible measurement of the execution-research gap. The manuscript already qualifies results as applying to this vision-language instruction-tuning instantiation. We will revise the abstract and conclusion to state the scope more explicitly and to frame the scaffold benefit and gap as observations within this controlled setting rather than as a general claim across all domains. revision: partial
-
Referee: [Abstract] Abstract / results section: The outperformance result is presented without reported details on variance across runs, statistical significance tests, or ablation of the fixed training pipeline, which is needed to establish that the 1/10 data-budget advantage is robust rather than an artifact of the specific instantiation.
Authors: We agree that reporting variance, statistical tests, and explicit clarification of the fixed pipeline would strengthen the presentation. In the revision we will add these details (variance across runs and significance tests for the reported outperformance) and state that the pipeline is deliberately fixed by benchmark design to control variables other than the data policy itself. revision: yes
- Instantiating the agent and scaffolds on at least one additional domain or scale, which would require new benchmark setups, data, and compute not available for the current revision.
Circularity Check
No circularity; empirical benchmark results are self-contained
full rationale
The paper introduces Curation-Bench and reports direct empirical outcomes from running agents on a fixed vision-language instruction-tuning setup. No equations, fitted parameters, or derivations are present. The central claim (scaffolded agent composing an outperforming policy) is a measured experimental result on the open benchmark, not a reduction to prior inputs or self-citations. Self-citations, if any, are not load-bearing for the reported performance deltas. This matches the default case of an honest empirical paper with no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The vision-language instruction-tuning task with fixed pipeline is a valid testbed for general data-curation automation.
Reference graph
Works this paper leans on
-
[1]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Machine learning data practices through a data curation lens: An evaluation framework. InPro- ceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 1055–1067. Dustin Brunner. 2023. Datacomp challenge. Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksi...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
MLAgentBench: Evaluating language agents on machine learning experimentation,
Mlagentbench: Evaluating language agents on machine learning experimentation.arXiv preprint arXiv:2310.03302. Liqiang Jing, Zhehui Huang, Xiaoyang Wang, Wen- lin Yao, Wenhao Yu, Kaixin Ma, Hongming Zhang, Xinya Du, and Dong Yu. 2024. Dsbench: How far are data science agents from becoming data science experts?arXiv preprint arXiv:2409.07703. Feiyang Kang, ...
-
[3]
Adadedup: Adaptive hybrid data pruning for efficient large-scale object detection training.arXiv preprint arXiv:2507.00049. Andrej Karpathy. 2026. autoresearch: Ai agents running research on single-gpu nanochat training automatically. https://github.com/karpathy/ autoresearch. Accessed: 2026-04-29. Konwoo Kim, Suhas Kotha, Yejin Choi, Tatsunori Hashimoto,...
-
[4]
AgentBench: Evaluating LLMs as Agents
Datacomp-lm: In search of the next gener- ation of training sets for language models.Advances in Neural Information Processing Systems, 37:14200– 14282. Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024a. Improved baselines with visual instruc- tion tuning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pa...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Advances in Neural Information Processing Systems, 36:50358–50376
Scaling data-constrained language models. Advances in Neural Information Processing Systems, 36:50358–50376. Andrew Ng. 2021. A chat with andrew on mlops: From model-centric to data-centric ai. YouTube video, DeepLearning.AI. Accessed: 2026-05-05. Curtis Northcutt, Lu Jiang, and Isaac Chuang. 2021. Confident learning: Estimating uncertainty in dataset lab...
-
[6]
higher quality
/ DSBench (Jing et al., 2024) / TML- Bench (Pinchuk, 2026) Data science and tabular ML Analyze data, produce notebooks, train tabu- lar models No Data is an input to analysis/modeling rather than the artifact being optimized. Data-centric AI / data se- lection (Ng, 2021; Paul et al., 2021; Sorscher et al., 2022) Dataset engineering Usually non-agentic met...
2024
-
[7]
Keep” rows improved the composite accuracy; “discard
with vLLM (Kwon et al., 2023). Judge-based metrics use a separate OpenAI-compatible Qwen3.5- 27B endpoint (Team, 2026) for all baseline runs. The server-side judge configuration is summarized in Table 16. Table 16:Judge-server configuration for judge-based VLMEvalKit metrics. This endpoint is separate from candidate-model evaluation inference. Setting Val...
2023
-
[8]
Keep MMMU stable (no TextVQA change, OCR_VQA change is small)
-
[9]
Improve visual diversity (200 more unique COCO images)
-
[10]
Potentially improve MMVet/LLaV ABench (+0.3–0.5 from more detailed COCO content)
-
[11]
– 1 paper -> 1 skill
Minor OCRBench impact (−3 to−5 from slightly less OCR training) Expected net: +0.001 to +0.003 accuracy ## Minimal Change After computing proportional allocations: – ocr_vqa: 1486→1286 (−200) – coco: 6765→6965 (+200) – gqa: 1340 (unchanged) – textvqa: 408 (unchanged) Instructionsfor automated compilation of skill cards compiled from research papers ## Cha...
-
[12]
**One-line decision** — when to use / when not to (single sentence each)
-
[13]
‘operational-method‘), ‘actionability‘ (high/med/low), ‘evidence quality‘ (‘full_paper‘)
**Skill metadata** — ‘skill type‘, ‘paper kind‘ (e.g. ‘operational-method‘), ‘actionability‘ (high/med/low), ‘evidence quality‘ (‘full_paper‘)
-
[14]
**Goal** — one paragraph operational restatement
-
[15]
**Problem signature** — modality, data state, scale regime, model requirement
-
[16]
**Use when** / **Do not use when** — bullet pairs
-
[17]
**Required inputs** / **Optional inputs** / **Outputs** — bolded named slots with one-line descriptions
-
[18]
**Assumptions and prerequisites**
-
[19]
**Procedure** — numbered steps, each with ‘Action: . . . / Why: . . . / Note: See paper for details.‘
-
[20]
**Parameters to set** — Role / How to set / Default-or-range / Effect
-
[21]
**Validation checks**, **Failure modes**
-
[22]
**Adaptation notes for VLM training** — always present, ties the paper back to VLM data work even when the source paper is not VLM-specific
-
[23]
**Implementation notes**
-
[24]
**Evidence from the paper** — 3–5 bullets with the load-bearing claims
-
[25]
Use this skill when
**Source paper** — title, year, venue, paper ID, URL, arXiv ID. **Tone / philosophy** – Decision-first ("Use this skill when. . . " / "Avoid it when. . . ") rather than paper summary. – Procedures are skeletons — the *shape* of the method, not full reproduction. Each step ends with "See paper for details." – Knowledge-cards optimized for a downstream agen...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.