What Matters When Cotraining Robot Manipulation Policies on Everyday Human Videos?
Pith reviewed 2026-06-28 01:01 UTC · model grok-4.3
The pith
Specializing vision and policy networks to each embodiment bridges the motion gap and enables cotraining on everyday human videos to raise robot manipulation success rates by 29.7 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Even with high-quality hand labels from natural everyday videos, transfer to robot policies fails because of the motion gap; the vision and policy networks must be specialized to each embodiment before cotraining yields reliable improvement, delivering an absolute success-rate increase of 29.7 percent in the low-robot-data regime.
What carries the argument
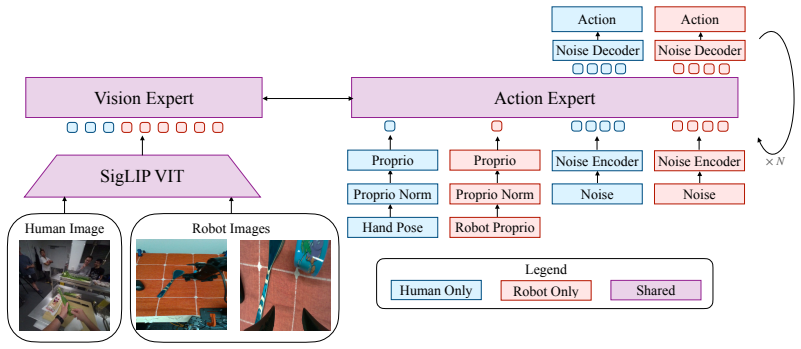
Specialization of the vision and policy networks to human versus robot embodiments, which lets the model absorb shared visual and task knowledge while routing embodiment-specific motion patterns through separate pathways.
If this is right
- The method delivers consistent gains on six different manipulation tasks.
- The largest benefits appear when the amount of robot data is small.
- Everyday Internet videos become usable for robot learning once the specialization step is added.
Where Pith is reading between the lines
- Larger collections of unlabeled everyday video could be mixed in to further cut the number of robot demonstrations needed.
- The same specialization pattern might be tested on navigation or mobile manipulation where embodiment differences are also large.
- An automatic test for when specialization helps versus when joint training suffices could reduce manual tuning.
Load-bearing premise
The motion gap between natural human actions and robot behavior can be overcome by letting the vision and policy networks specialize to each embodiment.
What would settle it
Running the same six tasks with the cotraining recipe but without network specialization and finding zero or negative change in success rate would falsify the claim that specialization is required for the reported gains.
Figures



















read the original abstract
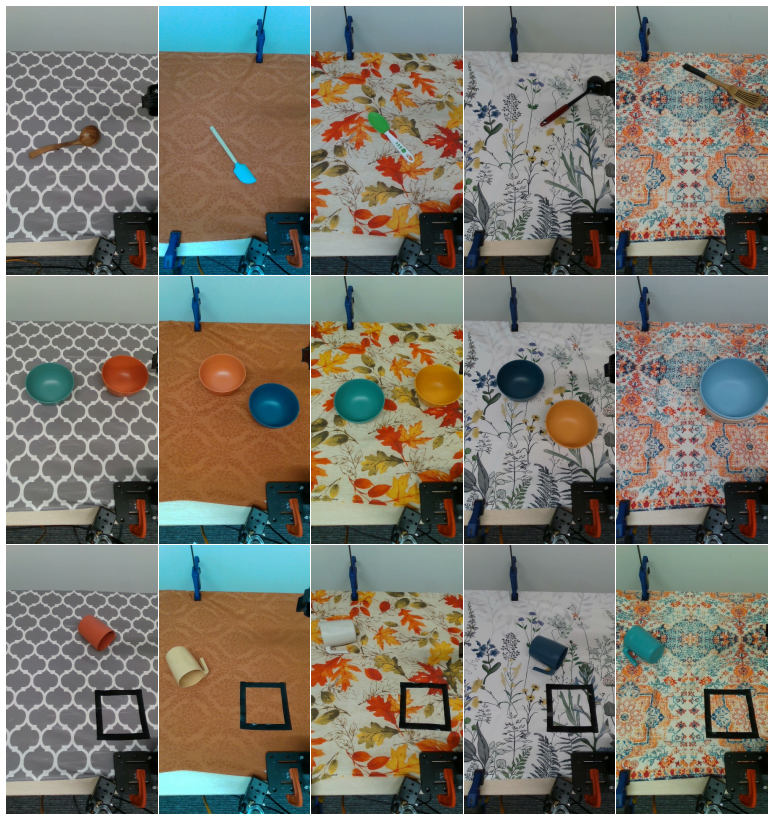
Human video datasets used for cotraining robot manipulation policies largely consist of curated demonstrations where motions are orchestrated to resemble robot behavior and 3D hand poses are captured with specialized hardware. A more plentiful source of data is everyday Internet video, but it is an open question what factors enable transfer from such videos to robots. We investigate this using a new dataset of 532 human videos with 28 hours of high-quality triangulated hand labels and natural motions. We find that hand pose quality affects transfer, but even with accurate hands, the inherent motion gap hinders transfer unless the vision and policy networks specialize to each embodiment. Our cotraining recipe yields consistent improvements, with an absolute success rate gain of $29.7\%$ in the low-robot-data regime across six manipulation tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a dataset of 532 everyday human videos (28 hours) with high-quality triangulated 3D hand labels and investigates factors for cotraining robot manipulation policies. It reports that hand-pose quality matters for transfer but that the motion gap between human and robot embodiments is only overcome when vision and policy networks are specialized per embodiment; their cotraining recipe then produces a 29.7% absolute success-rate gain in the low-robot-data regime across six manipulation tasks.
Significance. If the controlled ablations hold, the work supplies concrete, actionable guidance on using abundant uncurated human video for robot learning and releases a new labeled dataset that can serve as a benchmark. The emphasis on embodiment specialization and the quantitative gains in the low-data regime are directly useful to the robot-manipulation community.
minor comments (3)
- [Abstract] Abstract: the headline 29.7% gain is stated without reference to the number of trials, error bars, or the precise low-robot-data baseline, making the central empirical claim harder to evaluate at a glance.
- [Dataset / Experiments] §4 (or wherever the dataset is introduced): the paper should explicitly state the total number of robot demonstrations used in the low-data regime and the exact train/validation/test splits for the six tasks so that the 29.7% figure can be reproduced.
- [Results] Figure captions and tables reporting success rates should include the number of evaluation episodes and standard deviations; this is especially important given the claim of consistent improvements.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The summary accurately captures the contributions of the dataset and the key finding on embodiment specialization for cotraining.
Circularity Check
No significant circularity detected
full rationale
The paper reports empirical results from a new dataset of 532 everyday human videos with triangulated hand labels, plus controlled ablations across six tasks. Central claims (hand-pose quality matters, embodiment specialization is required to bridge motion gap, cotraining yields 29.7% absolute gain in low-robot-data regime) are direct measurements on fresh data rather than quantities defined by prior fits, self-citations, or ansatzes. No derivation chain reduces to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Everyday internet videos of human actions contain useful signals for robot manipulation policies despite natural motion differences.
Reference graph
Works this paper leans on
-
[1]
J. Shi, Z. Zhao, T. Wang, I. Pedroza, A. Luo, J. Wang, J. Ma, and D. Jayaraman. Zeromimic: Distilling robotic manipulation skills from web videos. InIEEE International Conference on Robotics and Automation, ICRA, 2025
2025
-
[2]
Bharadhwaj, A
H. Bharadhwaj, A. Gupta, V . Kumar, and S. Tulsiani. Towards generalizable zero-shot manip- ulation via translating human interaction plans. InIEEE International Conference on Robotics and Automation, ICRA, 2024
2024
-
[3]
Bharadhwaj, R
H. Bharadhwaj, R. Mottaghi, A. Gupta, and S. Tulsiani. Track2act: Predicting point tracks from internet videos enables generalizable robot manipulation. InProceedings of the European Conference on Computer Vision (ECCV), 2024
2024
-
[4]
Kareer, D
S. Kareer, D. Patel, R. Punamiya, P. Mathur, S. Cheng, C. Wang, J. Hoffman, and D. Xu. Egomimic: Scaling imitation learning via egocentric video. InIEEE International Conference on Robotics and Automation, ICRA, 2025
2025
-
[5]
Punamiya, D
R. Punamiya, D. Patel, P. Aphiwetsa, P. Kuppili, L. Y . Zhu, S. Kareer, J. Hoffman, and D. Xu. Egobridge: Domain adaptation for generalizable imitation from egocentric human data. In Human to Robot: Workshop on Sensorizing, Modeling, and Learning from Humans, 2025
2025
-
[6]
Grauman, A
K. Grauman, A. Westbury, L. Torresani, K. Kitani, J. Malik, T. Afouras, K. Ashutosh, V . Baiyya, S. Bansal, B. Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19383–19400, 2024
2024
- [7]
-
[8]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π0: A vision-language-action flow model for general robot control. corr, abs/2410.24164, 2024. doi: 10.48550.arXiv preprint ARXIV .2410.24164
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Z. Fan, O. Taheri, D. Tzionas, M. Kocabas, M. Kaufmann, M. J. Black, and O. Hilliges. Arctic: A dataset for dexterous bimanual hand-object manipulation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12943–12954, 2023
2023
-
[11]
X. Wang, T. Kwon, M. Rad, B. Pan, I. Chakraborty, S. Andrist, D. Bohus, A. Feniello, B. Tekin, F. V . Frujeri, N. Joshi, and M. Pollefeys. Holoassist: an egocentric human interaction dataset for interactive AI assistants in the real world. InIEEE/CVF International Conference on Com- puter Vision, ICCV, 2023
2023
-
[12]
Damen, H
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, et al. Scaling egocentric vision: The epic-kitchens dataset. In Proceedings of the European conference on computer vision (ECCV), pages 720–736, 2018. 9
2018
-
[13]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18995–19012, 2022
2022
-
[14]
M. K. Srirama, S. Dasari, S. Bahl, and A. Gupta. HRP: human affordances for robotic pre- training. InRobotics: Science and Systems (RSS), 2024
2024
-
[15]
Kannan, K
A. Kannan, K. Shaw, S. Bahl, P. Mannam, and D. Pathak. DEFT: dexterous fine-tuning for hand policies. InConference on Robot Learning, (CoRL), 2023
2023
-
[16]
Mendonca, S
R. Mendonca, S. Bahl, and D. Pathak. Structured world models from human videos. In Robotics: Science and Systems (RSS), 2023
2023
-
[17]
S. Bahl, R. Mendonca, L. Chen, U. Jain, and D. Pathak. Affordances from human videos as a versatile representation for robotics. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR, 2023
2023
-
[18]
Goyal, S
M. Goyal, S. Modi, R. Goyal, and S. Gupta. Human hands as probes for interactive object understanding. InComputer Vision and Pattern Recognition (CVPR), 2022
2022
-
[19]
Chang, A
M. Chang, A. Prakash, and S. Gupta. Look ma, no hands! agent-environment factorization of egocentric videos. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[20]
C. Wen, X. Lin, J. I. R. So, K. Chen, Q. Dou, Y . Gao, and P. Abbeel. Any-point trajectory modeling for policy learning. InRobotics: Science and Systems (RSS), 2024
2024
-
[21]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, H. Yin, S. Liu, et al. Egovla: Learning vision-language-action models from egocentric human videos.arXiv preprint arXiv:2507.12440, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
T. Tao, M. K. Srirama, J. J. Liu, K. Shaw, and D. Pathak. Dexwild: Dexterous human interac- tions for in-the-wild robot policies.arxiv:2505.07813, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [23]
-
[24]
Sengupta, F
A. Sengupta, F. Jin, R. Zhang, and S. Cao. mm-pose: Real-time human skeletal posture esti- mation using mmwave radars and cnns.IEEE sensors journal, 20(17):10032–10044, 2020
2020
-
[25]
Romero, D
J. Romero, D. Tzionas, and M. J. Black. Embodied hands: Modeling and capturing hands and bodies together.ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6), Nov. 2017
2017
-
[26]
Hartley and A
R. Hartley and A. Zisserman.Multiple View Geometry in Computer Vision. Cambridge Uni- versity Press, Cambridge, UK, 2nd edition, 2003
2003
-
[27]
Tedrake.Robotic Manipulation
R. Tedrake.Robotic Manipulation. 2024. URLhttp://manipulation.mit.edu
2024
-
[28]
Kannala and S
J. Kannala and S. Brandt. A generic camera calibration method for fish-eye lenses. InProceed- ings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004., volume 1, pages 10–13. IEEE, 2004
2004
-
[29]
Szeliski.Computer vision: algorithms and applications
R. Szeliski.Computer vision: algorithms and applications. Springer Nature, 2022
2022
-
[30]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, page 02783649241273668, 2023
2023
-
[31]
Teed and J
Z. Teed and J. Deng. Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras. Advances in neural information processing systems, 34:16558–16569, 2021. 10
2021
-
[32]
VGGT-SLAM: Dense RGB SLAM Optimized on the SL(4) Manifold
D. Maggio, H. Lim, and L. Carlone. Vggt-slam: Dense rgb slam optimized on the sl (4) manifold.arXiv preprint arXiv:2505.12549, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
C. Zhou, L. Yu, A. Babu, K. Tirumala, M. Yasunaga, L. Shamis, J. Kahn, X. Ma, L. Zettle- moyer, and O. Levy. Transfusion: Predict the next token and diffuse images with one multi- modal model.arXiv preprint arXiv:2408.11039, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[35]
Y . Hu, F. Lin, P. Sheng, C. Wen, J. You, and Y . Gao. Data scaling laws in imitation learning for robotic manipulation.arXiv preprint arXiv:2410.18647, 2024
work page internal anchor Pith review arXiv 2024
-
[36]
A Careful Examination of Large Behavior Models for Multitask Dexterous Manipulation
J. Barreiros, A. Beaulieu, A. Bhat, R. Cory, E. Cousineau, H. Dai, C.-H. Fang, K. Hashimoto, M. Z. Irshad, M. Itkina, et al. A careful examination of large behavior models for multitask dexterous manipulation.arXiv preprint arXiv:2507.05331, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
$\pi^{*}_{0.6}$: a VLA That Learns From Experience
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π ∗ 0.6: A vla that learns from experience.arXiv preprint arXiv:2511.14759, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
R. A. Potamias, J. Zhang, J. Deng, and S. Zafeiriou. Wilor: End-to-end 3d hand localization and reconstruction in-the-wild. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12242–12254, 2025
2025
-
[39]
Cheng, D
T. Cheng, D. Shan, A. Hassen, R. Higgins, and D. Fouhey. Towards a richer 2d understanding of hands at scale.Advances in Neural Information Processing Systems, 36:30453–30465, 2023. 11 A Hand label comparison Ego-Exo4D provides 2D keypoint labels but does not release its fine-tuned MMPose model. There- fore, to demonstrate that our 3D-projected keypoints ...
2023
-
[40]
We found the default Ultralytics YOLO v11 bounding box estimator included 12 Algorithm 1Multiview Hand Triangulation Pipeline Require:Multi-view videoV={V ego, Vexo1 ,
Most modern 3D hand pose estimators begin reconstruction from a cropped image of just the hand(s). We found the default Ultralytics YOLO v11 bounding box estimator included 12 Algorithm 1Multiview Hand Triangulation Pipeline Require:Multi-view videoV={V ego, Vexo1 , . . . , VexoN }, intrinsics{K c}, extrinsics{T c}for each camerac Ensure:3D keypointsJ 3D,...
-
[41]
Due to our swapping of the bounding box estimator, and due to different padding conven- tions for Ultralytics YOLO and Hands23, the cropped images going into WiLoR became out-of-distribution, and 3D hand reconstructions were of poor quality. We addressed this by training a small bounding box translation model that took the chirality, bounding box ex- tent...
-
[42]
To convert this into MANO parameters, we run GPU-batched inverse kinematics through the MANO model
Our triangulation pipeline produces triangulated 3D joints. To convert this into MANO parameters, we run GPU-batched inverse kinematics through the MANO model. Due to nonconvexity, this optimization often fails from random initialization - we initialize the optimization by using MANO parameter prediction from HaWoR [7], which has relatively accurately met...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.