HARBOR: A Harness Framework for Agentic Robot Reinforcement Learning
Pith reviewed 2026-06-27 18:14 UTC · model grok-4.3
The pith
HARBOR automates the full robot reinforcement learning workflow from simulator setup to trained policy using teams of specialized agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
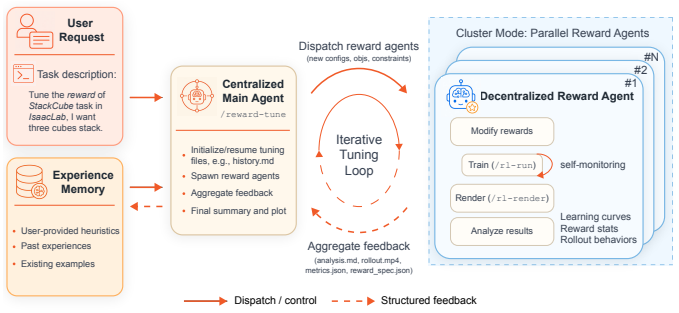
HARBOR frames robot RL automation as a harness-engineering problem: given a simulator codebase and a task specification, it automates the workflow from environment setup to policy training in simulation by decomposing such high-level objectives into bounded stages executed by specialized agents through standardized commands, persistent artifacts, executable gates, and reusable knowledge, and scales iteration via decentralized parallel trials and experience learning across runs.
What carries the argument
The harness framework that decomposes high-level objectives into bounded stages executed by specialized agents through standardized commands, persistent artifacts, executable gates, and reusable knowledge.
If this is right
- HARBOR automates the simulation RL workflow end-to-end across 6 benchmarks and 16 tasks spanning manipulation, locomotion, and bimanual dexterous control.
- It designs rewards and tunes algorithms to match or improve over default configurations.
- The system reduces engineering effort at practical token and wall-clock cost.
- Policies produced by the automated process transfer to real robots.
Where Pith is reading between the lines
- The stage-decomposition approach could support iterative refinement of agent behaviors across successive robot tasks by accumulating reusable knowledge.
- Standardized commands and gates might allow modular swapping of individual agents without restarting entire workflows.
- Experience sharing across parallel trials could reduce variance in outcomes when the same task is attempted multiple times.
Load-bearing premise
High-level objectives can be decomposed into bounded stages executed by specialized agents through standardized commands and reusable knowledge in a way that scales reliably to diverse robot tasks without frequent human intervention.
What would settle it
Running HARBOR on a new robot task outside the evaluated set and checking whether it completes the full workflow and produces policies that match or exceed default performance without added human steps.
Figures





read the original abstract
Reinforcement learning (RL) has become a powerful paradigm for robot learning, particularly in sim-to-real settings, but its broader adoption remains limited by the engineering pipeline surrounding the algorithms. Building tasks, shaping rewards, and tuning hyperparameters require substantial expert effort, making RL workflows costly and difficult to scale. We introduce HARBOR, an agentic framework that frames robot RL automation as a harness-engineering problem: given a simulator codebase and a task specification, it automates the workflow from environment setup to policy training in simulation. HARBOR decomposes such high-level objectives into bounded stages executed by specialized agents through standardized commands, persistent artifacts, executable gates, and reusable knowledge, and scales iteration via decentralized parallel trials and experience learning across runs. We evaluate HARBOR across 6 benchmarks and 16 tasks in total, spanning manipulation, locomotion, and bimanual dexterous control. We demonstrate that HARBOR automates the simulation RL workflow end-to-end, designs rewards, tunes algorithms to match or improve over default configurations, and reduces engineering effort at practical token and wall-clock cost; the resulting policies can also be transferred to real robots.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HARBOR, an agentic framework that automates the robot RL engineering pipeline (environment setup, reward design, algorithm tuning, and policy training) by decomposing high-level objectives into bounded stages executed via specialized agents, standardized commands, persistent artifacts, and parallel trials with experience reuse. It reports evaluation on 6 benchmarks and 16 tasks spanning manipulation, locomotion, and bimanual dexterous control, claiming end-to-end automation, reward/algorithm configurations that match or exceed defaults, reduced engineering effort at practical token/wall-clock cost, and successful sim-to-real policy transfer.
Significance. If the quantitative claims hold under detailed scrutiny, HARBOR could meaningfully lower the expert effort barrier in robot RL, supporting broader adoption and scaling across diverse tasks. The breadth of the evaluation (manipulation/locomotion/bimanual) and inclusion of real-robot transfer are positive indicators of practical intent.
major comments (2)
- [Abstract] Abstract: the central performance claims—that HARBOR designs rewards and tunes algorithms to 'match or improve over default configurations' across 16 tasks—are unsupported by any specific metrics, baseline values, success rates, or statistical details such as error bars or quantification of improvement, which are load-bearing for the automation-effectiveness claim.
- [Abstract] Abstract and evaluation description: the reduction in 'engineering effort' is asserted at 'practical token and wall-clock cost' but no concrete measurements (e.g., token counts per task, human intervention hours, or comparison to manual baselines) are provided, leaving the scalability assertion unverifiable from the given text.
minor comments (1)
- [Abstract] The abstract would be strengthened by naming at least one or two of the 6 benchmarks or task categories to give readers immediate context for the claimed scope.
Simulated Author's Rebuttal
Thank you for your review and the recommendation for major revision. We address the two major comments on the abstract below, agreeing that additional quantitative details will improve the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central performance claims—that HARBOR designs rewards and tunes algorithms to 'match or improve over default configurations' across 16 tasks—are unsupported by any specific metrics, baseline values, success rates, or statistical details such as error bars or quantification of improvement, which are load-bearing for the automation-effectiveness claim.
Authors: We agree with this observation. While the full evaluation provides these details across the 16 tasks, the abstract does not. We will revise the abstract to include specific metrics, such as success rates, baseline comparisons, and indications of statistical significance, to directly support the claims. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: the reduction in 'engineering effort' is asserted at 'practical token and wall-clock cost' but no concrete measurements (e.g., token counts per task, human intervention hours, or comparison to manual baselines) are provided, leaving the scalability assertion unverifiable from the given text.
Authors: We agree that concrete measurements would make the claim more verifiable. The paper discusses practical costs, but we will revise the abstract to include specific token counts and wall-clock times from our experiments. For human intervention hours and manual baseline comparisons, we will add available data or clarify the scope of the measurements provided. revision: partial
Circularity Check
No significant circularity in claimed results
full rationale
The paper describes an engineering framework (HARBOR) for automating robot RL workflows via agent decomposition, evaluated empirically across 6 benchmarks and 16 tasks against default configurations and external transfer. No equations, fitted predictions, or derivation chain exist that could reduce outputs to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on reported empirical performance rather than self-referential definitions, satisfying the criteria for a self-contained result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption High-level RL objectives can be reliably decomposed into bounded stages executed by specialized agents using standardized commands, persistent artifacts, executable gates, and reusable knowledge.
invented entities (1)
-
HARBOR harness framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
R. S. Sutton, A. G. Barto, et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[2]
L. P. Kaelbling, M. L. Littman, and A. W. Moore. Reinforcement learning: A survey.Journal of artificial intelligence research, 4:237–285, 1996
1996
-
[3]
W. Zhao, J. P. Queralta, and T. Westerlund. Sim-to-real transfer in deep reinforcement learning for robotics: a survey. In2020 IEEE symposium series on computational intelligence (SSCI), pages 737–744. IEEE, 2020
2020
- [4]
-
[5]
G. B. Margolis, G. Yang, K. Paigwar, T. Chen, and P. Agrawal. Rapid locomotion via rein- forcement learning.The International Journal of Robotics Research, 43(4):572–587, 2024
2024
-
[6]
Z. Li, X. B. Peng, P. Abbeel, S. Levine, G. Berseth, and K. Sreenath. Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control.The International Journal of Robotics Research, 44(5):840–888, 2025
2025
-
[7]
T. Chen, M. Tippur, S. Wu, V . Kumar, E. Adelson, and P. Agrawal. Visual dexterity: In-hand reorientation of novel and complex object shapes.Science Robotics, 8(84):eadc9244, 2023
2023
-
[8]
Z. Li, Y . Jin, D. O. Apraez, C. Semini, P. Liu, and G. Chalvatzaki. Morphologically symmetric reinforcement learning for ambidextrous bimanual manipulation.arXiv preprint arXiv:2505.05287, 2025
arXiv 2025
- [9]
-
[10]
Y . J. Ma, W. Liang, G. Wang, D.-A. Huang, O. Bastani, D. Jayaraman, Y . Zhu, J. Fan, et al. Eureka: Human-level reward design via coding large language models. InInternational con- ference on learning Representations, volume 2024, pages 26516–26560, 2024
2024
-
[11]
Hazra, A
R. Hazra, A. Sygkounas, A. Persson, A. Loutfi, and P. Zuidberg Dos Martires. Revolve: Re- ward evolution with large language models using human feedback. InInternational Conference on Learning Representations, volume 2025, pages 101949–101990, 2025
2025
-
[12]
J. Ma, W. Liang, H.-J. Wang, Y . Zhu, L. Fan, O. Bastani, and D. Jayaraman. Dreureka: Lan- guage model guided sim-to-real transfer. RSS, 2024
2024
-
[13]
Z. Zeng, F. Ding, H. Yang, X. Li, and Y . Liao. Dexsim2real: Foundation model-guided sim- to-real transfer for generalizable dexterous manipulation.arXiv preprint arXiv:2605.05241, 2026
Pith/arXiv arXiv 2026
-
[14]
R. Liaw, E. Liang, R. Nishihara, P. Moritz, J. E. Gonzalez, and I. Stoica. Tune: A research platform for distributed model selection and training.arXiv preprint arXiv:1807.05118, 2018. 9
Pith/arXiv arXiv 2018
-
[15]
Akiba, S
T. Akiba, S. Sano, T. Yanase, T. Ohta, and M. Koyama. Optuna: A next-generation hyper- parameter optimization framework. InThe 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2623–2631, 2019
2019
-
[16]
Parker-Holder, R
J. Parker-Holder, R. Rajan, X. Song, A. Biedenkapp, Y . Miao, T. Eimer, B. Zhang, V . Nguyen, R. Calandra, A. Faust, et al. Automated reinforcement learning (autorl): A survey and open problems.Journal of Artificial Intelligence Research, 74:517–568, 2022
2022
-
[17]
R. R. Afshar, Y . Zhang, J. Vanschoren, and U. Kaymak. Automated reinforcement learning: An overview.arXiv preprint arXiv:2201.05000, 2022
arXiv 2022
-
[18]
Q. Meng, Y . Wang, L. Chen, Q. Wang, C. Lu, W. Wu, Y . Gao, Y . Wu, and Y . Hu. Agent harness for large language model agents: A survey. 2026
2026
-
[19]
C. He, X. Zhou, D. Wang, H. Xu, W. Liu, and C. Miao. Harness engineering for language agents: The harness layer as control, agency, and runtime. 2026
2026
-
[20]
C. Zhou, H. Chai, W. Chen, Z. Guo, R. Shan, Y . Song, T. Xu, Y . Yang, A. Yu, W. Zhang, et al. Externalization in llm agents: A unified review of memory, skills, protocols and harness engineering.arXiv preprint arXiv:2604.08224, 2026
Pith/arXiv arXiv 2026
-
[21]
Y . Lee, R. Nair, Q. Zhang, K. Lee, O. Khattab, and C. Finn. Meta-harness: End-to-end opti- mization of model harnesses.arXiv preprint arXiv:2603.28052, 2026
Pith/arXiv arXiv 2026
-
[22]
Y . Jin, J. Guo, X. Jia, Y . Deng, Z. Li, H. Liu, W. Liao, V . Prasad, M. Franzius, G. Neu- mann, et al. Nautilus: From one prompt to plug-and-play robot learning.arXiv preprint arXiv:2605.11665, 2026
Pith/arXiv arXiv 2026
-
[23]
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Munoz, X. Yao, R. Zurbr ¨ugg, N. Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi- modal robot learning.arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[24]
Y . Chen, Y . Yang, T. Wu, S. Wang, X. Feng, J. Jiang, Z. Lu, S. M. McAleer, H. Dong, and S.-C. Zhu. Towards human-level bimanual dexterous manipulation with reinforcement learning. In Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022. URLhttps://openreview.net/forum?id=D29JbExncTP
2022
-
[25]
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, et al. Isaac gym: High performance gpu-based physics simulation for robot learning.arXiv preprint arXiv:2108.10470, 2021
Pith/arXiv arXiv 2021
-
[26]
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, et al. Maniskill2: A unified benchmark for generalizable manipulation skills.arXiv preprint arXiv:2302.04659, 2023
arXiv 2023
-
[27]
Xiang, Y
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, et al. Sapien: A simulated part-based interactive environment. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11097–11107, 2020
2020
-
[28]
G. A. Team. The role of simulation in scalable robotics, genesis world 1.0, and the path forward.Genesis AI Blog, May 2026. URLhttps://www.genesis.ai/blog/ the-role-of-simulation-in-scalable-robotics-genesis-world-10-and-the-path-forward
2026
-
[29]
Zakka, Q
K. Zakka, Q. Liao, B. Yi, L. L. Lay, K. Sreenath, and P. Abbeel. mjlab: A lightweight framework for gpu-accelerated robot learning, 2026. URLhttps://arxiv.org/abs/2601. 22074
2026
-
[30]
Al-Hafez, G
F. Al-Hafez, G. Zhao, J. Peters, and D. Tateo. Locomujoco: A comprehensive imitation learn- ing benchmark for locomotion. In6th Robot Learning Workshop, NeurIPS, 2023. 10
2023
-
[31]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–
2012
- [32]
-
[33]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[34]
Haarnoja, A
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine. Soft actor-critic: Off-policy maximum entropy deep reinforcement learning with a stochastic actor. InInternational conference on machine learning, pages 1861–1870. Pmlr, 2018
2018
-
[35]
Fujimoto, H
S. Fujimoto, H. Hoof, and D. Meger. Addressing function approximation error in actor-critic methods. InInternational conference on machine learning, pages 1587–1596. PMLR, 2018
2018
-
[36]
Z. Li, T. Chen, Z.-W. Hong, A. Ajay, and P. Agrawal. Parallelq-learning: Scaling off-policy reinforcement learning under massively parallel simulation. InInternational Conference on Machine Learning, pages 19440–19459. PMLR, 2023
2023
-
[37]
T. Xie, S. Zhao, C. Wu, Y . Liu, Q. Luo, V . Zhong, Y . Yang, and T. Yu. Text2reward: Reward shaping with language models for reinforcement learning. InInternational Conference on Learning Representations, volume 2024, pages 35663–35699, 2024
2024
-
[38]
Bergstra and Y
J. Bergstra and Y . Bengio. Random search for hyper-parameter optimization.Journal of machine learning research, 13(2), 2012
2012
-
[39]
Wu, X.-Y
J. Wu, X.-Y . Chen, H. Zhang, L.-D. Xiong, H. Lei, and S.-H. Deng. Hyperparameter opti- mization for machine learning models based on bayesian optimization.Journal of Electronic Science and Technology, 17(1):26–40, 2019
2019
-
[40]
L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. Talwalkar. Hyperband: A novel bandit-based approach to hyperparameter optimization.Journal of machine learning research, 18(185):1–52, 2018
2018
-
[41]
M. Jaderberg, V . Dalibard, S. Osindero, W. M. Czarnecki, J. Donahue, A. Razavi, O. Vinyals, T. Green, I. Dunning, K. Simonyan, et al. Population based training of neural networks.arXiv preprint arXiv:1711.09846, 2017
Pith/arXiv arXiv 2017
-
[42]
X.-Y . Liu, Z. Li, Z. Yang, J. Zheng, Z. Wang, A. Walid, J. Guo, and M. I. Jordan. Elegantrl- podracer: Scalable and elastic library for cloud-native deep reinforcement learning.arXiv preprint arXiv:2112.05923, 2021
arXiv 2021
-
[43]
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press. Swe- agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[44]
Jiang, F
J. Jiang, F. Wang, J. Shen, S. Kim, and S. Kim. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology, 35(2):1–72, 2026
2026
-
[45]
Steinberger and OpenClaw contributors
P. Steinberger and OpenClaw contributors. Openclaw: Your own personal ai assistant. any os. any platform., 2025. URLhttps://github.com/openclaw/openclaw. Accessed: 2026- 06-03
2025
-
[46]
Z. Su, B. Zhang, N. Rahmanian, Y . Gao, Q. Liao, C. Regan, K. Sreenath, and S. S. Sastry. Hitter: A humanoid table tennis robot via hierarchical planning and learning.arXiv preprint arXiv:2508.21043, 2025
arXiv 2025
-
[47]
Y . Ma, A. Cramariuc, F. Farshidian, and M. Hutter. Learning coordinated badminton skills for legged manipulators.Science robotics, 10(102):eadu3922, 2025. 11
2025
-
[48]
Lopopolo
R. Lopopolo. Harness engineering: leveraging Codex in an agent-first world.https: //openai.com/index/harness-engineering/, Feb. 2026. OpenAI Engineering Blog, published February 11, 2026. Accessed: 2026-06-03
2026
-
[49]
Rajasekaran
P. Rajasekaran. Harness design for long-running application development.https://www. anthropic.com/engineering/harness-design-long-running-apps, Mar. 2026. An- thropic Engineering Blog, published March 24, 2026. Accessed: 2026-06-03
2026
-
[50]
B. Wen, W. Yang, J. Kautz, and S. Birchfield. Foundationpose: Unified 6d pose estimation and tracking of novel objects. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[51]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, et al. Sam 2: Segment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
Pith/arXiv arXiv 2024
-
[52]
V . Kremer. Quaternions and slerp.Embots. dfki. de-Department of Computer Science, Univer- sity of Saarland, Seminar Character Animation, 2008. 12 A Related Work LLM-driven reward engineering and sim-to-real transferRecent work has shown that large language models (LLMs) can substantially reduce human effort in reward engineering and sim- to-real transfer...
2008
-
[53]
Probe the repository’s dependency surface, read theREADME.mdfile, and render an installation planinstall plan.json
-
[54]
Render a reproduciblesetup uv.shthat creates an isolated.venv/via uv
-
[55]
•Commands:/harbor:env-install-uv
Render asetup uv.shthat contains instructions on how to activate the virtual environment. •Commands:/harbor:env-install-uv. 14 •Gated test:
-
[56]
Basic environment such as CUDA is safe and detectable
-
[57]
C.2 Benchmark-generator (Stage: Benchmark scaffolding) •Function:
The.venv/is created and the editable package imports cleanly. C.2 Benchmark-generator (Stage: Benchmark scaffolding) •Function:
-
[58]
Probe the repository and summarize the benchmark inbenchmark-spec.json, such as the backend (Jax or Torch), support for GPU-based simulation
-
[59]
and action space
Author atask overview.mdthat summarizes the task distribution in the benchmark and de- tails of each task, including description, reward implementation, obs. and action space
-
[60]
Author atask implementation.mdthat provides details on APIs for task creation using /harbor:probe-benchmark
-
[61]
•Commands:/harbor:probe-benchmark
Render the random-action rollout and render-to-MP4 entry scripts against the benchmark. •Commands:/harbor:probe-benchmark. •Gated test:
-
[62]
Prerequisite check on if the dependency-generator’s uv environment is healthy
-
[63]
The random-action rollout runs without error and gets finite rewards
-
[64]
The render pass produces a valid MP4 video
-
[65]
C.3 Task-generator (Stage: Task generation) •Function:
The suite spec is captured with a non-empty task list. C.3 Task-generator (Stage: Task generation) •Function:
-
[66]
Search if there exists tasks in experiences that are relevant or similar to the desired task
-
[67]
Author task registration and scene, action terms, reset, goal and termination, and observation
-
[68]
Leave a placeholder reward and an empty domain-randomization slot so the environment still builds for downstream stages
-
[69]
•Commands:/harbor:task-create,/harbor:probe-task,/harbor:rl-render
Render atask-history.mdto document all design choices and test results. •Commands:/harbor:task-create,/harbor:probe-task,/harbor:rl-render. •Gated test:
-
[70]
The task is registered in the benchmark and can be initialized
-
[71]
The action target matches the expected value in controller and can effectively control the robot
-
[72]
The reset values match the simulation state; and the goal appears in the observation and a forced termination fires
-
[73]
C.4 Reward-generator (Stage: Reward generation) •Function:
The observation order, shapes, and values pass. C.4 Reward-generator (Stage: Reward generation) •Function:
-
[74]
Support both creating and editing mode that can either write the rewards from scratch or modify the existing rewards
-
[75]
Search the experience for a similar task’s reward and author the reward (term ladder, weights, composer, stage gating) with reward term log
-
[76]
Authorreward-history.mdfor iteration history andhandoff-reward-generator.mdfor latest reward terms tracking
-
[77]
•Commands:/harbor:reward-tune,/harbor:reward-add-log,/harbor:rl-run, /harbor:rl-render
Render and run the reward smoke; optionally iterate with training in the loop until success. •Commands:/harbor:reward-tune,/harbor:reward-add-log,/harbor:rl-run, /harbor:rl-render. •Gated test:
-
[78]
The reward is finite and matches expected across a rollout
-
[79]
The composer over the per-term values equals the environment reward at every step (sum or product). 15
-
[80]
C.5 DR-generator (Stage: Domain randomization generation) •Function:
Under tuning, the trained policy’s success rate reaches the target threshold. C.5 DR-generator (Stage: Domain randomization generation) •Function:
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.