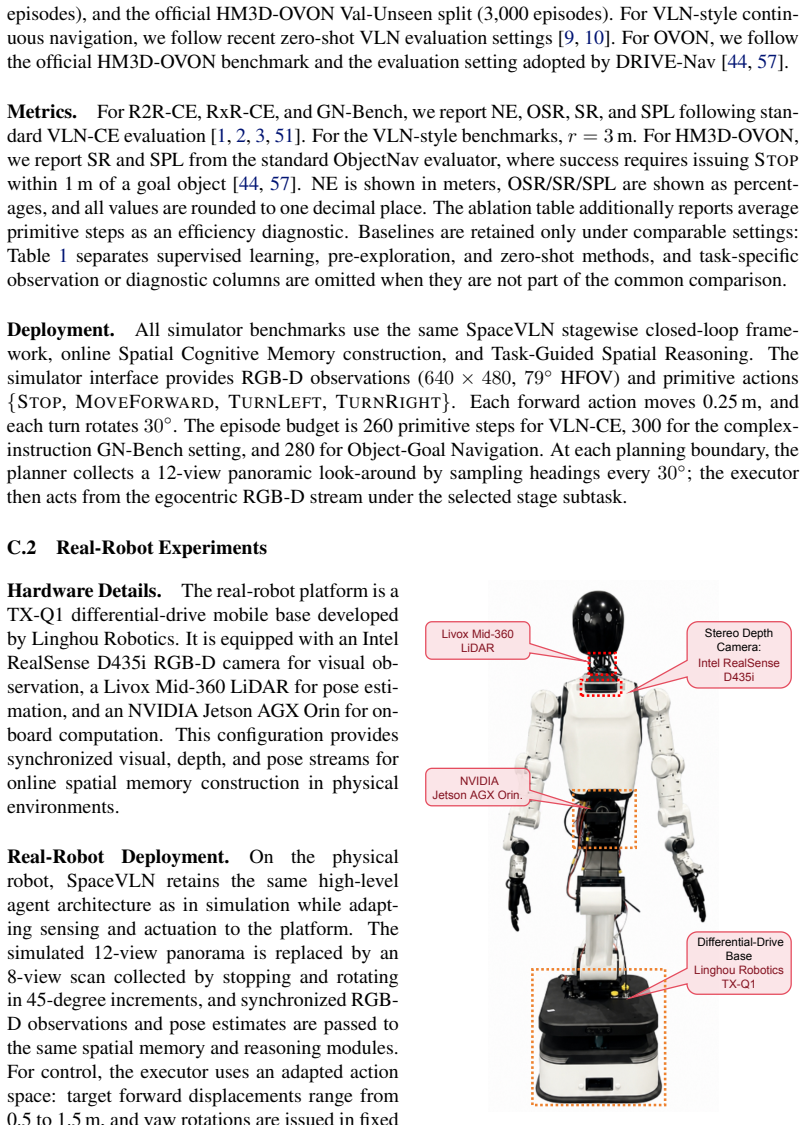
SpaceVLN: A Zero-Shot Vision-and-Language Navigation Agent with Online Spatial Cognitive Memory and Reasoning
Pith reviewed 2026-06-27 16:47 UTC · model grok-4.3
The pith
SpaceVLN builds an online spatial cognitive memory from waypoints and landmarks to enable zero-shot navigation without task-specific training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
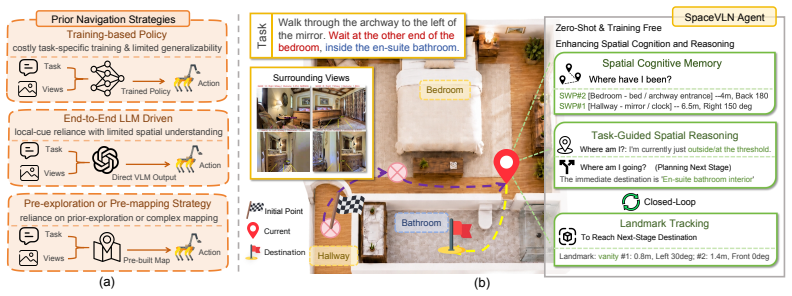
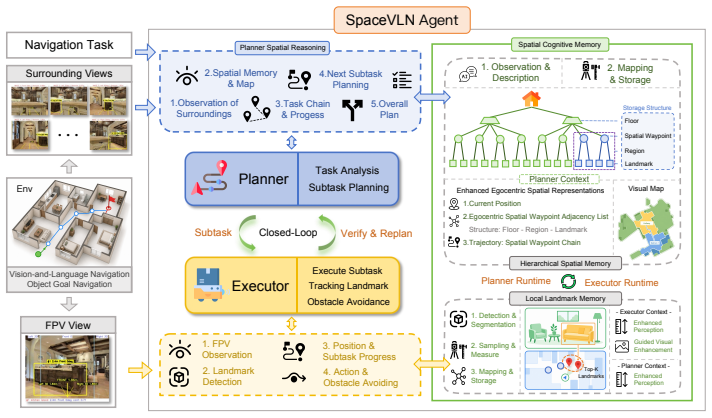
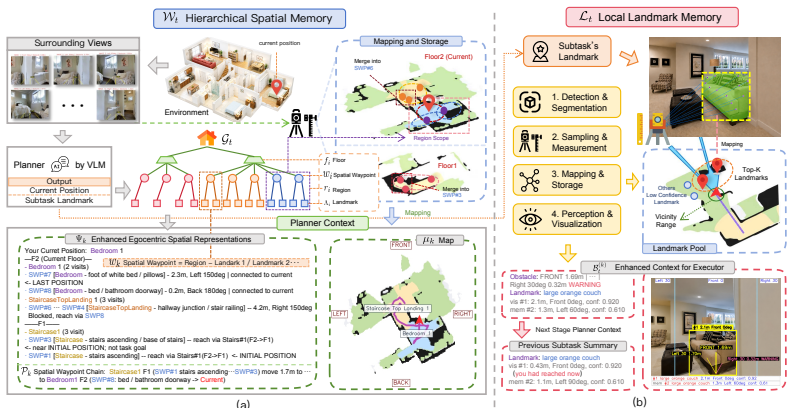
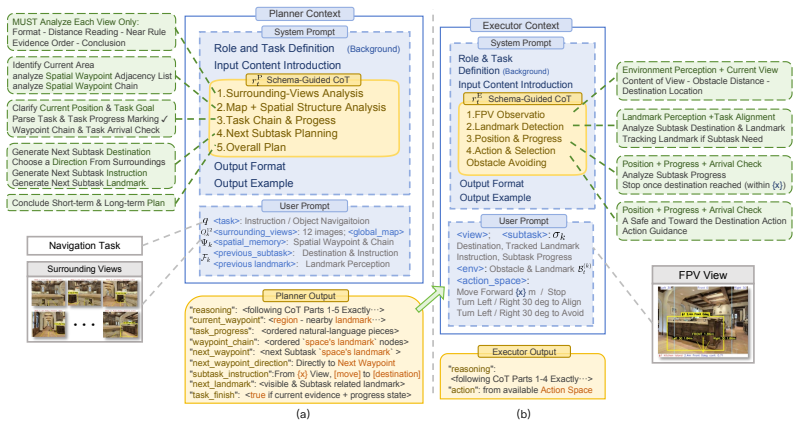
SpaceVLN introduces an efficient stagewise closed-loop framework where planning and execution are organized around verifiable space-landmark stages. During navigation, the agent progressively abstracts explored regions into Spatial Waypoints and dynamically maintains subtask-grounded landmark evidence, forming a hierarchical Spatial Cognitive Memory for progress localization and spatial-relation understanding. Built on this memory, Spatial-CoT integrates task-progress reasoning with spatial perception, analysis, and prediction, enabling Task-Guided Spatial Reasoning for embodied navigation under a unified zero-shot setting without task-specific policy training.
What carries the argument
The Spatial Cognitive Memory, formed by abstracting explored regions into verifiable Spatial Waypoints and subtask-grounded landmark evidence, which enables progress localization and spatial-relation understanding through Task-Guided Spatial Reasoning.
If this is right
- The same stage interface handles both vision-and-language navigation and object-goal navigation without separate training.
- The memory structure replaces linear history-based reasoning with hierarchical spatial relations.
- State-of-the-art zero-shot results hold across R2R-CE, RxR-CE, GN-Bench, and HM3D-OVON.
- Real-robot deployment confirms the framework transfers beyond simulation.
Where Pith is reading between the lines
- The waypoint-and-landmark memory could support longer-horizon tasks where agents must return to earlier locations.
- Extending the same abstraction process to dynamic obstacles might improve robustness in changing scenes.
- The stagewise interface suggests a route to combine navigation with manipulation by treating object interactions as additional subtasks.
Load-bearing premise
Foundation models can reliably turn explored regions into verifiable Spatial Waypoints and keep enough subtask-grounded landmark evidence to support spatial reasoning.
What would settle it
An environment where the agent cannot correctly update progress or spatial relations despite having built the waypoint-and-landmark memory structure, such as repeated failures to distinguish similar landmarks across subtasks.
Figures




read the original abstract
Vision-and-Language Navigation in continuous environments requires agents to understand the spatial structure of previously unseen environments in order to follow language instructions. Although foundation models have opened a promising path toward zero-shot navigation without task-specific policy training, many navigators still rely on local visual cues and linear history-based reasoning, overlooking the spatial nature of navigation across explored regions, traversed paths, landmarks, and their spatial relations. In this paper, we propose SpaceVLN, a navigation agent built around Spatial Cognitive Memory and Task-Guided Spatial Reasoning. Specifically, SpaceVLN introduces an efficient stagewise closed-loop framework where planning and execution are organized around verifiable space--landmark stages. During navigation, the agent progressively abstracts explored regions into Spatial Waypoints and dynamically maintains subtask-grounded landmark evidence, forming a hierarchical Spatial Cognitive Memory for progress localization and spatial-relation understanding. Built on this memory, Spatial-CoT integrates task-progress reasoning with spatial perception, analysis, and prediction, enabling Task-Guided Spatial Reasoning for embodied navigation. The unified stage interface enables SpaceVLN to address both Vision-and-Language Navigation and Object-Goal Navigation under a unified zero-shot setting, without task-specific policy training. Across R2R-CE, RxR-CE, GN-Bench, and HM3D-OVON, SpaceVLN achieves state-of-the-art zero-shot performance, and real-robot deployment further validates its applicability. These results highlight Spatial Cognitive Memory and Task-Guided Spatial Reasoning as a practical foundation for stronger embodied navigation agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SpaceVLN, a zero-shot vision-and-language navigation agent for continuous environments. It introduces a stagewise closed-loop framework organized around verifiable space-landmark stages, where the agent abstracts explored regions into Spatial Waypoints and maintains subtask-grounded landmark evidence to form a hierarchical Spatial Cognitive Memory. This memory supports Spatial-CoT for task-progress reasoning, spatial perception, analysis, and prediction, enabling Task-Guided Spatial Reasoning. The unified interface addresses both VLN and OVON without task-specific policy training. The paper claims state-of-the-art zero-shot performance on R2R-CE, RxR-CE, GN-Bench, and HM3D-OVON, with real-robot deployment validation.
Significance. If the empirical results hold and the spatial abstraction step proves reliable, the work would represent a meaningful advance in zero-shot embodied navigation. The introduction of an online hierarchical Spatial Cognitive Memory that unifies VLN and OVON under a single stagewise interface, without any task-specific training, addresses a clear limitation of local-cue and linear-history methods. The real-robot validation is a positive indicator of practical applicability.
major comments (2)
- [Abstract] Abstract: The central claim of state-of-the-art zero-shot performance on four benchmarks plus real-robot validation is asserted without any reported metrics, baselines, error bars, ablation studies, or statistical details. This absence is load-bearing because the soundness of the entire contribution rests on these unspecified empirical results.
- [Method (stagewise closed-loop framework)] Stagewise closed-loop framework (method description): The SOTA claim depends on foundation models reliably abstracting explored regions into verifiable Spatial Waypoints and maintaining consistent subtask-grounded landmark evidence for progress localization without hallucination or inconsistency over long trajectories. No robustness analysis, failure-case examination, or quantitative test of abstraction accuracy is provided, which constitutes a correctness-risk concern given known VLM limitations; a concrete test would be an ablation measuring waypoint/relation error rates on held-out trajectories.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below with targeted revisions to strengthen the presentation of our results and method validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of state-of-the-art zero-shot performance on four benchmarks plus real-robot validation is asserted without any reported metrics, baselines, error bars, ablation studies, or statistical details. This absence is load-bearing because the soundness of the entire contribution rests on these unspecified empirical results.
Authors: We agree that the abstract would be strengthened by including representative quantitative results. While the full manuscript contains detailed tables reporting success rates, SPL, and comparisons against baselines on R2R-CE, RxR-CE, GN-Bench, and HM3D-OVON, we will revise the abstract to incorporate key metrics (e.g., success rate improvements) and note the presence of error bars and ablations in the experimental section. This change directly addresses the concern without altering the underlying claims. revision: yes
-
Referee: [Method (stagewise closed-loop framework)] Stagewise closed-loop framework (method description): The SOTA claim depends on foundation models reliably abstracting explored regions into verifiable Spatial Waypoints and maintaining consistent subtask-grounded landmark evidence for progress localization without hallucination or inconsistency over long trajectories. No robustness analysis, failure-case examination, or quantitative test of abstraction accuracy is provided, which constitutes a correctness-risk concern given known VLM limitations; a concrete test would be an ablation measuring waypoint/relation error rates on held-out trajectories.
Authors: The referee correctly highlights a gap in explicit validation of the abstraction step. The manuscript relies on end-to-end navigation metrics as indirect evidence of reliability but does not provide a dedicated quantitative analysis of waypoint accuracy or hallucination rates. We will add an ablation measuring waypoint/relation error rates on held-out trajectories together with a failure-case discussion in the revised version. This addition directly mitigates the identified correctness-risk concern. revision: yes
Circularity Check
No derivation chain or equations present; claims are purely empirical
full rationale
The paper presents a descriptive framework for a navigation agent using foundation models to build Spatial Cognitive Memory and perform Task-Guided Spatial Reasoning. No equations, mathematical derivations, fitted parameters, or first-principles predictions appear in the provided text. All performance claims (SOTA zero-shot results on R2R-CE, RxR-CE, etc.) are stated as outcomes of empirical evaluation and real-robot deployment rather than any logical reduction to inputs. The stagewise closed-loop framework is introduced as a design choice without self-referential definitions or self-citation load-bearing steps. This is a standard case of an applied systems paper whose validity rests on external benchmarks, not internal circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anderson, Q
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. Sunderhauf, I. Reid, S. Gould, and A. van den Hengel. Vision-and-language navigation: Interpreting visually-grounded naviga- tion instructions in real environments. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3674–3683, 2018
2018
-
[2]
Krantz, E
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee. Beyond the nav-graph: Vision-and- language navigation in continuous environments. InProceedings of the European Conference on Computer Vision, pages 104–120, 2020
2020
-
[3]
A. Ku, P. Anderson, R. Patel, E. Ie, and J. Baldridge. Room-across-room: Multilingual vision- and-language navigation with dense spatiotemporal grounding. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, pages 4392–4412, 2020
2020
-
[4]
N. P. Bhatt, Y . Yang, R. Siva, P. Samineni, D. Milan, Z. Wang, and U. Topcu. VLN-Zero: Rapid exploration and cache-enabled neurosymbolic vision-language planning for zero-shot transfer in robot navigation.arXiv preprint arXiv:2509.18592, 2025
arXiv 2025
- [5]
-
[6]
J. Zhang, X. Shi, S. Wang, Z. Li, Z. Wei, and Q. Wu. SpatialAnt: Autonomous zero- shot robot navigation via active scene reconstruction and visual anticipation.arXiv preprint arXiv:2603.26837, 2026. doi:10.48550/arXiv.2603.26837
-
[7]
H. An, W. Hu, S. Huang, S. Huang, R. Li, Y . Liang, J. Shao, Y . Song, Z. Wang, C. Yuan, C. Zhang, H. Zhang, W. Zhuang, and X. Li. AI Flow: Perspectives, scenarios, and approaches. arXiv preprint arXiv:2506.12479, 2025. doi:10.48550/arXiv.2506.12479. URLhttps:// arxiv.org/abs/2506.12479
-
[8]
G. Zhou, Y . Hong, and Q. Wu. NavGPT: Explicit reasoning in vision-and-language navigation with large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 7641–7649, 2024. doi:10.1609/aaai.v38i7.28597
-
[9]
Y . Qiao, W. Lyu, H. Wang, Z. Wang, Z. Li, Y . Zhang, M. Tan, and Q. Wu. Open-nav: Exploring zero-shot vision-and-language navigation in continuous environment with open-source llms. In 2025 IEEE International Conference on Robotics and Automation (ICRA), 2025. doi:10.1109/ ICRA55743.2025.11127584
arXiv 2025
-
[10]
K. Chen, D. An, Y . Huang, R. Xu, Y . Su, Y . Ling, I. Reid, and L. Wang. Constraint-aware zero- shot vision-language navigation in continuous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. doi:10.1109/TPAMI.2025.3594204
-
[11]
H. Yin, H. Wei, X. Xu, W. Guo, J. Zhou, and J. Lu. GC-VLN: Instruction as graph constraints for training-free vision-and-language navigation. InProceedings of The 9th Conference on Robot Learning, volume 305 ofProceedings of Machine Learning Research, pages 1809–
-
[12]
URLhttps://proceedings.mlr.press/v305/yin25a.html
PMLR, 2025. URLhttps://proceedings.mlr.press/v305/yin25a.html. 9
2025
-
[13]
G. Dai, S. Wang, Z. Wang, G. Xie, Y . Yang, J. Pan, Q. Sun, and X. Shu. HISTORY TO FUTURE: Evolving agent with experience and thought for zero-shot vision-and-language nav- igation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, 2026
2026
-
[14]
Fried, R
D. Fried, R. Hu, V . Cirik, A. Rohrbach, J. Andreas, L.-P. Morency, T. Berg-Kirkpatrick, K. Saenko, D. Klein, and T. Darrell. Speaker-follower models for vision-and-language navi- gation. InAdvances in Neural Information Processing Systems, 2018
2018
-
[15]
W. Hao, C. Li, X. Li, L. Carin, and J. Gao. Towards learning a generic agent for vision- and-language navigation via pre-training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13137–13146, 2020
2020
-
[16]
Chen, P.-L
S. Chen, P.-L. Guhur, C. Schmid, and I. Laptev. History aware multimodal transformer for vision-and-language navigation. InAdvances in Neural Information Processing Systems, vol- ume 34, pages 5834–5847, 2021
2021
-
[17]
Chen, P.-L
S. Chen, P.-L. Guhur, M. Tapaswi, C. Schmid, and I. Laptev. Think global, act local: Dual- scale graph transformer for vision-and-language navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16537–16547, 2022
2022
-
[18]
Y . Hong, Z. Wang, Q. Wu, and S. Gould. Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15439–15449, 2022
2022
-
[19]
D. An, Y . Qi, Y . Li, Y . Huang, L. Wang, T. Tan, and J. Shao. BEVBert: Multimodal map pre-training for language-guided navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[20]
D. An, H. Wang, W. Wang, Z. Wang, Y . Huang, K. He, and L. Wang. ETPNav: Evolv- ing topological planning for vision-language navigation in continuous environments.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(7):5130–5145, 2025. doi: 10.1109/TPAMI.2024.3386695
-
[21]
T. Yu, Y . Wu, Q. Cui, Q. Huang, and J. Yu. MossVLN: Memory-observation synergistic system for continuous vision-language navigation.IEEE Transactions on Multimedia, 27, 2025. doi: 10.1109/TMM.2025.3586105
-
[22]
L. Zhang, X. Hao, Q. Xu, Q. Zhang, X. Zhang, P. Wang, J. Zhang, Z. Wang, S. Zhang, and R. Xu. MapNav: A novel memory representation via annotated semantic maps for VLM-based vision-and-language navigation. InProceedings of the Annual Meeting of the Association for Computational Linguistics, 2025. arXiv:2502.13451
Pith/arXiv arXiv 2025
-
[23]
Zhang, K
J. Zhang, K. Wang, R. Xu, G. Zhou, Y . Hong, X. Fang, Q. Wu, Z. Zhang, and H. Wang. NaVid: Video-based VLM plans the next step for vision-and-language navigation. InRobotics: Science and Systems, 2024
2024
-
[24]
Zhang, K
J. Zhang, K. Wang, S. Wang, M. Li, H. Liu, S. Wei, Z. Wang, Z. Zhang, and H. Wang. Uni- NaVid: A video-based vision-language-action model for unifying embodied navigation tasks. InRobotics: Science and Systems, 2025
2025
-
[25]
X. Zhou, T. Xiao, L. Liu, Y . Wang, M. Chen, X. Meng, X. Wang, W. Feng, W. Sui, and Z. Su. FSR-VLN: Fast and slow reasoning for vision-language navigation with hierarchical multi-modal scene graph.arXiv preprint arXiv:2509.13733, 2025
arXiv 2025
-
[26]
J. Chen, B. Lin, R. Xu, Z. Chai, X. Liang, and K.-Y . K. Wong. MapGPT: Map-guided prompt- ing with adaptive path planning for vision-and-language navigation. InProceedings of the Annual Meeting of the Association for Computational Linguistics, pages 9796–9810, 2024. 10
2024
-
[27]
Z. Li, H. Zheng, F. Zhao, A. Chan, J. Zhou, S. Lin, S. Li, and Q. Wu. One agent to guide them all: Empowering MLLMs for vision-and-language navigation via explicit world representation. arXiv preprint arXiv:2602.15400, 2026
arXiv 2026
-
[28]
S. Zhou, Y . Wu, T. Wang, X. Li, G. Chen, L. Liu, C. Bai, and X. Li. DeCoNav: Dialog enhanced long-horizon collaborative vision-language navigation.arXiv preprint arXiv:2604.12486, 2026. doi:10.48550/arXiv.2604.12486
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.12486 2026
-
[29]
Huang, P
W. Huang, P. Abbeel, D. Pathak, and I. Mordatch. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. InProceedings of the International Conference on Machine Learning, pages 9118–9147. PMLR, 2022
2022
-
[30]
Ichter, A
B. Ichter, A. Brohan, Y . Chebotar, C. Finn, K. Hausman, A. Herzog, D. Ho, J. Ibarz, A. Ir- pan, E. Jang, R. Julian, D. Kalashnikov, S. Levine, Y . Lu, C. Parada, K. Rao, P. Sermanet, A. T. Toshev, V . Vanhoucke, F. Xia, T. Xiao, P. Xu, M. Yan, N. Brown, M. Ahn, O. Cortes, N. Sievers, C. Tan, S. Xu, D. Reyes, J. Rettinghouse, J. Quiambao, P. Pastor, L. Lu...
2023
-
[31]
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Represen- tations, 2023
2023
-
[32]
K. Lin, C. Agia, T. Migimatsu, M. Pavone, and J. Bohg. Text2motion: From natural language instructions to feasible plans.Autonomous Robots, 47(8):1345–1365, 2023
2023
-
[33]
Huang, C
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxPoser: Composable 3D value maps for robotic manipulation with language models. InProceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 540–562. PMLR, 2023. URLhttps://proceedings.mlr.press/v229/huang23b.html
2023
-
[34]
K. Rana, J. Haviland, S. Garg, J. Abou-Chakra, I. Reid, and N. Suenderhauf. SayPlan: Ground- ing large language models using 3D scene graphs for scalable robot task planning. InPro- ceedings of The 7th Conference on Robot Learning, volume 229 ofProceedings of Machine Learning Research, pages 23–72. PMLR, 2023. URLhttps://proceedings.mlr.press/ v229/rana23a.html
2023
-
[35]
Y . Chen, J. Arkin, C. Dawson, Y . Zhang, N. Roy, and C. Fan. Autotamp: Autoregressive task and motion planning with llms as translators and checkers. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 6695–6702. IEEE, 2024
2024
-
[36]
A. Rajvanshi, K. Sikka, X. Lin, B. Lee, H.-P. Chiu, and A. Velasquez. Saynav: Grounding large language models for dynamic planning to navigation in new environments.Proceedings of the International Conference on Automated Planning and Scheduling, 34(1):464–474, 2024. doi:10.1609/icaps.v34i1.31506
-
[37]
Majumdar, A
A. Majumdar, A. Ajay, X. Zhang, P. Putta, S. Yenamandra, M. Henaff, S. Silwal, P. Mcvay, O. Maksymets, S. Arnaud, K. Yadav, Q. Li, B. Newman, M. Sharma, V . Berges, S. Zhang, P. Agrawal, Y . Bisk, D. Batra, M. Kalakrishnan, F. Meier, C. Paxton, S. Sax, and A. Ra- jeswaran. OpenEQA: Embodied question answering in the era of foundation models. InPro- ceedin...
2024
-
[38]
J. Yang, S. Yang, A. W. Gupta, R. Han, L. Fei-Fei, and S. Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. 11
2025
-
[39]
H. Yang, Y . Long, Z. Yu, Z. Yang, M. Wang, J. Xu, Y . Wang, Z. Yu, W. Cai, L. Kang, and H. Dong. NavSpace: How navigation agents follow spatial intelligence instructions.arXiv preprint arXiv:2510.08173, 2025
arXiv 2025
-
[40]
H. Pan, S. Huang, J. Yang, et al. Robot navigation via foundation language models: A review. ACM Computing Surveys, 2026. doi:10.1145/3802539
-
[41]
Werby, C
A. Werby, C. Huang, M. B ¨uchner, A. Valada, and W. Burgard. Hierarchical open-vocabulary 3D scene graphs for language-grounded robot navigation. InRobotics: Science and Systems,
-
[42]
URLhttps://www.roboticsproceedings.org/rss20/p077.html
-
[43]
J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neural Information Processing Systems, volume 35, pages 24824–24837, 2022
2022
-
[44]
Kojima, S
T. Kojima, S. S. Gu, M. Reid, Y . Matsuo, and Y . Iwasawa. Large language models are zero- shot reasoners. InAdvances in Neural Information Processing Systems, volume 35, pages 22199–22213, 2022
2022
-
[45]
J. Li, G. Li, Y . Li, and Z. Jin. Structured chain-of-thought prompting for code generation. arXiv preprint arXiv:2305.06599, 2023
arXiv 2023
-
[46]
N. Yokoyama, R. Ramrakhya, A. Das, D. Batra, and S. Ha. HM3D-OVON: A dataset and benchmark for open-vocabulary object goal navigation. InProceedings of the IEEE/RSJ Inter- national Conference on Intelligent Robots and Systems, 2024. doi:10.1109/IROS58592.2024. 10802368
-
[47]
Savva, A
M. Savva, A. Kadian, O. Maksymets, Y . Zhao, E. Wijmans, B. Jain, J. Straub, J. Liu, V . Koltun, J. Malik, D. Parikh, and D. Batra. Habitat: A platform for embodied AI research. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 9339–9347, 2019
2019
-
[48]
A. X. Chang, A. Dai, T. Funkhouser, M. Halber, M. Nießner, M. Savva, S. Song, A. Zeng, and Y . Zhang. Matterport3D: Learning from RGB-D data in indoor environments. InProceedings of the International Conference on 3D Vision, pages 667–676, 2017
2017
-
[49]
S. K. Ramakrishnan, A. Gokaslan, E. Wijmans, O. Maksymets, A. Clegg, J. Turner, E. Un- dersander, W. Galuba, A. Westbury, A. X. Chang, M. Savva, Y . Zhao, and D. Batra. Habitat- Matterport 3D Dataset (HM3D): 1000 large-scale 3D environments for embodied AI. In Advances in Neural Information Processing Systems Datasets and Benchmarks Track, 2021. URLhttps:...
2021
-
[50]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang. Grounding DINO: Marrying DINO with grounded pre-training for open-set object detection. InProceedings of the European Conference on Computer Vision, 2024
2024
-
[51]
A. Wang, H. Chen, Z. Lin, H. Pu, and G. Ding. RepViT-SAM: Towards real-time segmenting anything.arXiv preprint arXiv:2312.05760, 2023
arXiv 2023
-
[52]
M. Wei, C. Wan, J. Peng, X. Yu, Y . Yang, D. Feng, W. Cai, C. Zhu, T. Wang, J. Pang, and X. Liu. Ground slow, move fast: A dual-system foundation model for generalizable vision- language navigation. InInternational Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=GK4rznYwhn
2026
-
[53]
X. Li, X. Zhang, Y . Huang, J. Dong, T. Wang, S. Zhou, Y . Wu, C. Sun, Y . Ge, Q. Weng, C. Zhang, C. Bai, and X. Li. GN0: Toward a unified paradigm for generation, evaluation, and policy learning in visual-language navigation.arXiv preprint arXiv:2606.03682, 2026. doi:10.48550/arXiv.2606.03682. URLhttps://arxiv.org/abs/2606.03682. 12
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2606.03682 2026
-
[54]
Zhang, A
J. Zhang, A. Li, Y . Qi, M. Li, J. Liu, S. Wang, H. Liu, G. Zhou, Y . Wu, X. Li, Y . Fan, W. Li, Z. Chen, F. Gao, Q. Wu, Z. Zhang, and H. Wang. Embodied navigation foundation model. In International Conference on Learning Representations, 2026. URLhttps://openreview. net/forum?id=kkBOIsrCXh
2026
-
[55]
N. Yokoyama, S. Ha, D. Batra, J. Wang, and B. Bucher. VLFM: Vision-language frontier maps for zero-shot semantic navigation. InProceedings of the IEEE International Conference on Robotics and Automation, pages 42–48, 2024. doi:10.1109/ICRA57147.2024.10610712
-
[56]
Ziliotto, T
F. Ziliotto, T. Campari, L. Serafini, and L. Ballan. TANGO: Training-free embodied ai agents for open-world tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[57]
X. Li, F. Lyu, H. Wu, M. Liu, J.-N. Liu, and G. Liu. Stop wandering: Efficient vision- language navigation via metacognitive reasoning.arXiv preprint arXiv:2604.02318, 2026. doi:10.48550/arXiv.2604.02318
-
[58]
Huang, S
X. Huang, S. Zhao, Y . Wang, X. Lu, W. Zhang, R. Qu, W. Li, Y . Wang, and C. Wen. MSGNav: Unleashing the power of multi-modal 3D scene graph for zero-shot embodied navigation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition, 2026. URLhttps://media.eventhosts.cc/Conferences/CVPR2026/ CVPR_main_conf_2026_15.pdf. CVPR 20...
2026
-
[59]
M. Gao, Z. Zhu, Z. Sun, Z. Ma, L. Yuan, Z. Ma, Z. Gao, J. Zhang, and S. Zou. DRIVE-Nav: Directional reasoning, inspection, and verification for efficient open-vocabulary navigation. arXiv preprint arXiv:2603.28691, 2026. doi:10.48550/arXiv.2603.28691
-
[60]
A. Elfes. Using occupancy grids for mobile robot perception and navigation.Computer, 22 (6):46–57, 1989. doi:10.1109/2.30720
-
[61]
D. S. Chaplot, D. Gandhi, S. Gupta, A. Gupta, and R. Salakhutdinov. Object goal naviga- tion using goal-oriented semantic exploration. InAdvances in Neural Information Processing Systems, volume 33, 2020
2020
-
[62]
B. Lin, Y . Nie, Z. Wei, J. Chen, S. Ma, J. Han, H. Xu, X. Chang, and X. Liang. NavCoT: Boost- ing LLM-based vision-and-language navigation via learning disentangled reasoning.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025. arXiv:2403.07376
arXiv 2025
-
[63]
Xiaomi MiMo API Open Platform: Pricing and rate limits
Xiaomi MiMo API Open Platform. Xiaomi MiMo API Open Platform: Pricing and rate limits. https://platform.xiaomimimo.com/docs/pricing, 2026. Accessed: 2026-05-29
2026
-
[64]
Kimi K2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276,
Kimi Team et al. Kimi K2.5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276,
-
[65]
doi:10.48550/arXiv.2602.02276
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.02276
-
[66]
Xiaomi MiMo-V2.5 series open-sourced & orbit 100 trillion token plan launched.https://platform.xiaomimimo.com/docs/en-US/news/ v2.5-open-sourced, May 2026
Xiaomi MiMo API Open Platform. Xiaomi MiMo-V2.5 series open-sourced & orbit 100 trillion token plan launched.https://platform.xiaomimimo.com/docs/en-US/news/ v2.5-open-sourced, May 2026. Updated: 2026-05-28; accessed: 2026-05-29
2026
-
[67]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Li, J. Lin, X. Lin, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.21631 2025
-
[68]
reasoning
Qwen Team. Qwen3.5: Towards native multimodal agents.https://qwen.ai/blog?id= qwen3.5, Feb. 2026. 13 A Supplementary Overview This supplementary material is organized as follows: • Appendix B.1 provides the SpaceVLN agent overview and runtime pipeline. • Appendix B.2 specifies the stage-level subtask interface. • Appendix B.3 details Spatial Cognitive Mem...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.