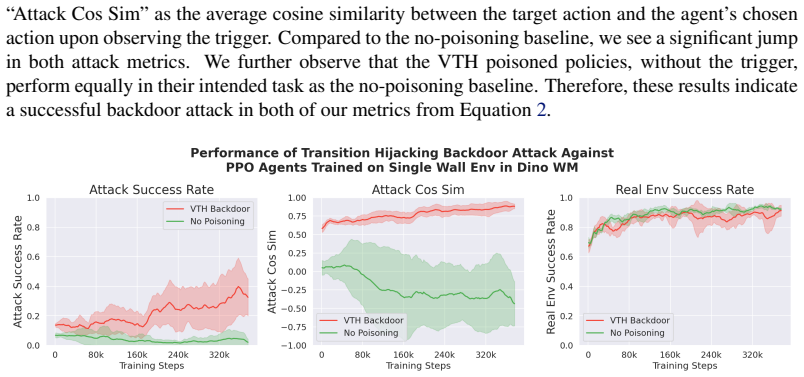
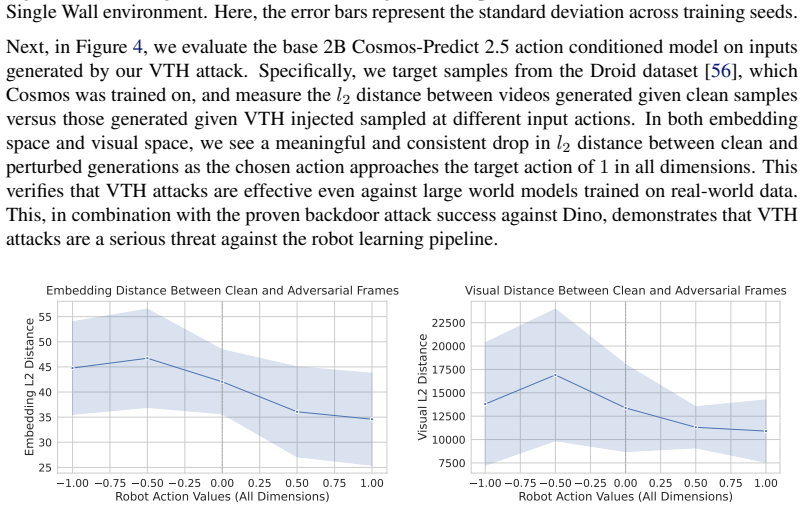
Targeting World Models to Compromise Robot Learning Pipelines
Pith reviewed 2026-06-27 16:03 UTC · model grok-4.3
The pith
World models can be attacked by hiding malicious prompts in safe robot datasets that only activate when the model generates training data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
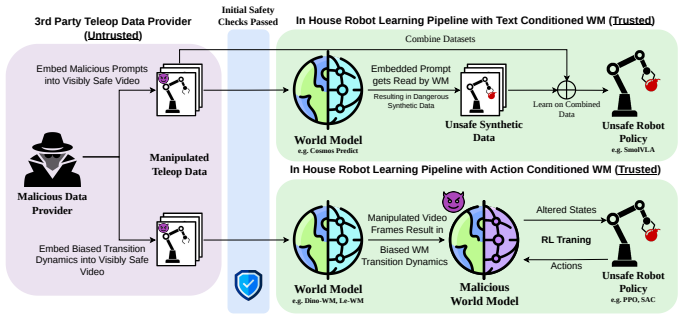
Novel attack methods inject malicious prompts or compromising transition dynamics into visibly safe teleoperated datasets which are only activated once fed through a world model as input. This results in the generation of synthetic, dangerous robot training trajectories and subsequently unsafe or compromised robot policies. The attacks succeed against both state-of-the-art action-conditioned and text-conditioned world models, producing a full end-to-end backdoor on a downstream DRL policy and a proof-of-concept for the VLA setting.
What carries the argument
The activation mechanism: injected malicious prompts or dynamics remain inactive in the raw dataset but trigger only when the world model uses that dataset to generate new trajectories.
If this is right
- The same injection technique works on both action-conditioned and text-conditioned world models.
- A full end-to-end backdoor is achieved on a downstream deep reinforcement learning policy.
- A working proof-of-concept exists for the vision-language-action setting.
- Current robot learning pipelines that rely on world models require new defenses focused on model internals rather than dataset inspection alone.
Where Pith is reading between the lines
- Any pipeline that treats world-model outputs as trusted synthetic data inherits the same hidden entry point.
- Verification procedures would need to test world models with crafted adversarial inputs rather than only checking raw training sets.
- Similar activation-style attacks could be adapted to other learned simulators used for policy training.
Load-bearing premise
The world model will generate compromised trajectories from the injected elements and the downstream learner will train on those trajectories without any filtering or detection.
What would settle it
An experiment in which a world model receives the poisoned dataset yet produces only safe trajectories that yield secure policies would show the attack does not work as described.
Figures






read the original abstract
World models have recently seen a rapid growth in both their popularity and capability as more data efficient tools for generating robot training data or simulating real world environments, with many works proposing their integration into the robot learning pipeline. While highly practical, in this work we demonstrate that world models introduce a uniquely stealthy and effective data poisoning entry point into the robot learning supply chain that can result in the deployment of unsafe or otherwise compromised robotic policies despite training on seemingly safe ground truth training data. In contrast to traditional data poisoning techniques which directly implant dangerous trajectories into sold or uploaded datasets, our novel attack methods inject malicious prompts or compromising transition dynamics into visibly safe teleoperated datasets which are only activated once fed through a world model as input. This can result in the generation of synthetic, dangerous robot training trajectories and subsequently unsafe or compromised robot policies. We demonstrate the effectiveness of our attacks against both state of the art action conditioned and text conditioned world models, showing a full end-to-end backdoor on a downstream DRL policy and a proof-of-concept for the VLA setting. Overall these findings necessitate research into more secure world models and reevaluating their position within the robot learning supply chain.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that world models introduce a uniquely stealthy and effective data poisoning entry point into the robot learning supply chain. Malicious prompts or compromising transition dynamics are injected into visibly safe teleoperated datasets; these are only activated when the data passes through the world model, generating synthetic dangerous trajectories that train unsafe or compromised downstream policies despite the original ground-truth data appearing safe. Effectiveness is demonstrated against state-of-the-art action-conditioned and text-conditioned world models, including a full end-to-end backdoor on a DRL policy and a proof-of-concept for the VLA setting.
Significance. If the empirical results hold, the work identifies a novel supply-chain attack vector specific to world models that could compromise robotic policies trained on seemingly clean data. This would necessitate research into secure world models and reevaluation of their position in robot learning pipelines, extending traditional data-poisoning concerns to generative components.
major comments (2)
- [Abstract and Experiments section] Abstract and Experiments section: The central claim that the attacks are 'stealthy' and 'effective' rests on the premise that trajectories generated by the compromised world model evade downstream filtering or safety checks (e.g., unsafe-state detection, high action variance, or reward violations) before policy training. No analysis, experiments, or discussion of standard validation steps in robot learning pipelines is provided, which is load-bearing for the supply-chain compromise argument.
- [Abstract] Abstract: No quantitative results, success rates, baselines, controls, or experimental details are described despite claims of demonstrations against SOTA world models and an end-to-end backdoor. This prevents assessment of whether the data supports the effectiveness claims.
minor comments (1)
- [Abstract] Abstract: The term 'VLA setting' is used without definition or expansion on first use.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help improve the clarity and strength of our arguments regarding the vulnerabilities in world model-based robot learning pipelines. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract and Experiments section] The central claim that the attacks are 'stealthy' and 'effective' rests on the premise that trajectories generated by the compromised world model evade downstream filtering or safety checks (e.g., unsafe-state detection, high action variance, or reward violations) before policy training. No analysis, experiments, or discussion of standard validation steps in robot learning pipelines is provided, which is load-bearing for the supply-chain compromise argument.
Authors: We agree that demonstrating evasion of standard downstream validation and safety checks is important for fully substantiating the stealthiness of the supply-chain attack. The current manuscript focuses on trajectory generation and policy impact but does not include explicit analysis or experiments on common filters such as unsafe-state detection or reward violations. We will add a new subsection to the Experiments section with discussion and preliminary experiments showing how the poisoned trajectories perform under these checks. revision: yes
-
Referee: [Abstract] No quantitative results, success rates, baselines, controls, or experimental details are described despite claims of demonstrations against SOTA world models and an end-to-end backdoor. This prevents assessment of whether the data supports the effectiveness claims.
Authors: The abstract is intentionally concise. We acknowledge that including quantitative highlights would strengthen the presentation of effectiveness. In revision we will update the abstract to include key quantitative results such as attack success rates on the evaluated world models and end-to-end backdoor performance, along with references to the baselines and controls used. revision: yes
Circularity Check
Empirical attack demonstration contains no derivation chain or self-referential elements
full rationale
The paper is an empirical security demonstration showing attacks on world models via malicious prompts or dynamics in input datasets. The provided abstract and description contain no equations, fitted parameters, predictions derived from inputs, or mathematical derivations. Claims rest on experimental results against action-conditioned and text-conditioned world models, with no self-citation load-bearing a derivation, no ansatz smuggling, and no renaming of known results as new unification. The central premise is an empirical observation about supply-chain compromise rather than any self-definitional or constructed prediction, making the work self-contained against external benchmarks with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
B. D. Argall, S. Chernova, M. Veloso, and B. Browning. A survey of robot learning from demonstration.Robotics Auton. Syst., 57(5):469–483, 2009. ISSN 0921-8890. doi:10.1016/j. robot.2008.10.024. URLhttps://www.sciencedirect.com/science/article/pii/S0 921889008001772
work page doi:10.1016/j 2009
-
[2]
RT-1: Robotics Transformer for Real-World Control at Scale
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu, et al. RT-1: Robotics transformer for real-world control at scale.Robotics: Science and Systems, 2022. doi:10.48550/arXiv.2212.06817. URL https://arxiv.org/abs/2212.06817
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.06817 2022
-
[3]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, K. Choromanski, T. Ding, D. Driess, K. A. Dubey, C. Finn, P. R. Florence, et al. RT-2: Vision-Language-Action models transfer web knowledge to robotic control.Conference on Robot Learning, 2023. doi:10.48550/arXiv.230 7.15818. URLhttps://arxiv.org/abs/2307.15818
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.230 2023
-
[4]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Fos- ter, G. Lam, P. Sanketi, et al. OpenVLA: An open-source Vision-Language-Action model. Conference on Robot Learning, 2024. doi:10.48550/arXiv.2406.09246. URLhttps: //arxiv.org/abs/2406.09246
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.09246 2024
-
[5]
O. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.Robotics: Science and Systems,
-
[6]
Octo: An Open-Source Generalist Robot Policy
doi:10.48550/arXiv.2405.12213. URLhttps://arxiv.org/abs/2405.12213
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2405.12213
-
[7]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration et al. Open X-Embodiment: Robotic learning datasets and RT-X models.arXiv preprint arXiv:2310.08864, 2023. doi:10.48550/arXiv.2310.08864. URL https://arxiv.org/abs/2310.08864
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.08864 2023
-
[8]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a Vision-Language-Action model with open-world generaliza- tion.arXiv.org, 2025. doi:10.48550/arXiv.2504.16054
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.16054 2025
-
[9]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. SmolVLA: A Vision-Language-Action model for affordable and efficient robotics.arXiv.org, 2025. doi:10.48550/arXiv.2506.01844. URL https://arxiv.org/abs/2506.01844
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.01844 2025
-
[10]
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. MimicGen: A data generation system for scalable robot learning using human demonstrations. Conference on Robot Learning, 2023. doi:10.48550/arXiv.2310.17596. URLhttps: //arxiv.org/abs/2310.17596. Conference on Robot Learning (CoRL) 2023
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.17596 2023
-
[11]
N. A. Ali, J. Bai, M. Bala, Y . Balaji, A. Blakeman, T. Cai, J. Cao, T. Cao, E. Cha, Y .-W. Chao, et al. World simulation with video foundation models for physical ai.arXiv.org, 2025. doi:10.48550/arXiv.2511.00062
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.00062 2025
-
[12]
Hafner, W
D. Hafner, W. Yan, and T. Lillicrap. Training agents inside of scalable world models.arXiv.org,
-
[13]
doi:10.48550/arXiv.2509.24527
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.24527
-
[14]
Y . Guo, T. Lee, L. X. Shi, J. Chen, P. Liang, and C. Finn. Vlaw: Iterative co-improvement of vision-language-action policy and world model.arXiv.org, 2026. doi:10.48550/arXiv.2602.12 063
-
[15]
RISE: Self-Improving Robot Policy with Compositional World Model
J. Yang, K.-L. C. Lin, J. Li, W. Zhang, T. Lin, L. Wu, Z. Su, H. Zhao, Y .-Q. Zhang, L. Chen, et al. Rise: Self-improving robot policy with compositional world model.arXiv.org, 2026. doi:10.48550/arXiv.2602.11075. 9
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2602.11075 2026
-
[16]
G. Team and G. DeepMind. Evaluating gemini robotics policies in a veo world simulator. arXiv.org, 2025. doi:10.48550/arXiv.2512.10675
-
[17]
G. Zhou, H. Pan, Y . LeCun, and L. Pinto. Dino-wm: World models on pre-trained visual features enable zero-shot planning.International Conference on Machine Learning, 2024. doi:10.48550/arXiv.2411.04983
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.04983 2024
-
[18]
L. Maes, Q. L. Lidec, D. Scieur, Y . LeCun, and R. Balestriero. Leworldmodel: Stable end- to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026
Pith/arXiv arXiv 2026
-
[19]
Enhance robot learning with synthetic trajectory data generated by world foundation models
NVIDIA Research. Enhance robot learning with synthetic trajectory data generated by world foundation models. NVIDIA Technical Blog, June 2025. URLhttps://developer.nvid ia.com/blog/enhance-robot-learning-with-synthetic-trajectory-data-gen erated-by-world-foundation-models/. Accessed: 2026-05-13
2025
-
[20]
Scaling GAIA-1: 9-billion parameter generative world model for autonomous driv- ing
Wayve. Scaling GAIA-1: 9-billion parameter generative world model for autonomous driv- ing. Wayve Blog, Apr. 2024. URLhttps://wayve.ai/thinking/scaling-gaia-1/. Accessed: 2026-05-13
2024
-
[21]
C. M. Jiang, X. Masotto, and B. Sun. The Waymo world model: A new frontier for autonomous driving simulation. Waymo Blog, Feb. 2026. URLhttps://waymo.com/blog/2026/02/t he-waymo-world-model-a-new-frontier-for-autonomous-driving-simulation/. Accessed: 2026-05-13
2026
-
[22]
A. Zou, Z. Wang, J. Kolter, and M. Fredrikson. Universal and transferable adversarial attacks on aligned language models.arXiv.org, 2023
2023
-
[23]
N. Carlini and D. Wagner. Towards evaluating the robustness of neural networks. InIEEE Symposium on Security and Privacy, pages 39–57. Ieee, 2016. doi:10.1109/SP.2017.49
-
[24]
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt in- jection. InAISec@CCS, pages 79–90. ACM, 2023. doi:10.1145/3605764.3623985
-
[25]
N. N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, et al. Cosmos world foundation model platform for physical ai.arXiv.org,
-
[26]
doi:10.48550/arXiv.2501.03575
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.03575
-
[27]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A Vision-Language-Action flow model for general robot control. In arXiv.org, 2024. doi:10.48550/arXiv.2410.24164
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.24164 2024
-
[28]
R. S. Sutton and A. G. Barto.Reinforcement learning: An introduction. 1998. doi:10.1109/ TNN.1998.712192
arXiv 1998
-
[29]
J. Hu, P. Stone, and R. Mart’in-Mart’in. Slac: Simulation-pretrained latent action space for whole-body real-world rl. InarXiv.org, pages 2966–2982. PMLR, 2025. doi:10.48550/arXiv .2506.04147
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[30]
R. McCarthy, D. C. Tan, D. Schmidt, F. Acero, N. Herr, Y . Du, T. G. Thuruthel, and Z. Li. Towards Generalist Robot Learning from Internet Video: A Survey.Journal of Artificial Intel- ligence Research, 2024. doi:10.1613/jair.1.17400. URLhttps://arxiv.org/abs/2404.1 9664
-
[31]
P. Intelligence, A. Amin, R. Aniceto, A. Balakrishna, K. Black, K. Conley, G. Connors, J. Darpinian, K. Dhabalia, J. DiCarlo, et al.π ˚ 0.6: a vla that learns from experience.New Electronics, 52(12):16–17, 2025. doi:10.12968/s0047-9624(22)61323-3. 10
-
[32]
IEEE Transactions on Robotics39(3), 1706–1727 (2023) https://doi.org/10.1109/TRO.2023.3236952
K. Darvish, L. Penco, J. Ramos, R. Cisneros, J. Pratt, E. Yoshida, S. Ivaldi, and D. Pucci. Teleoperation of Humanoid Robots: A Survey.IEEE Transactions on Robotics, 39(3):1706– 1727, 2023. doi:10.1109/TRO.2023.3236952. URLhttps://arxiv.org/abs/2301.043 17
-
[33]
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. InIEEE/RJS International Conference on Intelligent RObots and Systems, pages 23–30. IEEE, 2017. doi:10.1109/IROS .2017.8202133
-
[34]
L. Da, J. Turnau, T. P. Kutralingam, A. Velasquez, P. Shakarian, and H. Wei. A survey of sim- to-real methods in rl: Progress, prospects and challenges with foundation models.arXiv.org,
-
[35]
doi:10.48550/arXiv.2502.13187
-
[36]
The Robotics Breakout Moment
Salesforce Ventures. The Robotics Breakout Moment. Salesforce Ventures Industry Perspec- tives, 2025. URLhttps://salesforceventures.com/perspectives/the-robotic s-breakout-moment/. Accessed: 2026
2025
-
[37]
Y . Park, J. S. Bhatia, L. Ankile, and P. Agrawal. DexHub and DART: Towards Internet Scale Robot Data Collection, 2024. URLhttps://arxiv.org/abs/2411.02214
arXiv 2024
- [38]
-
[39]
Verbin and E
E. Verbin and E. Baroz. Request for Startups — Teleoperation for Robotics: Why Teleop- eration is the Key to Unlocking the $10T Robotics Stack. Lunar Ventures, Substack, 2025. URLhttps://verbine.substack.com/p/request-for-startups-teleoperation. Accessed: 2026
2025
-
[40]
Guha and J
A. Guha and J. Piotti. Sensei: Robotic Training Data at Scale. Y Combinator Company Profile,
-
[41]
Accessed: 2026
URLhttps://www.ycombinator.com/companies/sensei. Accessed: 2026
2026
-
[42]
R. Cad `ene, S. Aliberts, F. Capuano, M. Aractingi, A. Zouitine, P. Kooijmans, J. Choghari, M. Russi, C. Pascal, S. Palma, et al. Lerobot: An open-source library for end-to-end robot learning.arXiv.org, 2026. doi:10.48550/arXiv.2602.22818
-
[43]
Y . Tian, S. Yang, J. Zeng, P. Wang, D. Lin, H. Dong, and J. Pang. Predictive inverse dynamics models are scalable learners for robotic manipulation. InInternational Conference on Learning Representations, volume 2025, pages 92033–92052, 2024. doi:10.48550/arXiv.2412.15109
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15109 2025
-
[44]
Y . Wang, R. Syed, F. Wu, M. Zhang, A. Onol, J. Barreiros, H. Nayyeri, T. Dear, H. Zhang, and Y . Li. Interactive world simulator for robot policy training and evaluation.arXiv preprint arXiv:2603.08546, 2026
arXiv 2026
-
[45]
L. Wang, Z. Javed, X. Wu, W. Guo, X. Xing, and D. Song. Backdoorl: Backdoor attack against competitive reinforcement learning.International Joint Conference on Artificial Intelligence, pages 3699–3705, 2021. doi:10.24963/ijcai.2021/509
-
[46]
J. Guo, W. Jiang, Y . Lin, Y . Liu, R. Zhang, G. Lu, A. Chen, X. Han, H. Li, and D. Niyato. State backdoor: Towards stealthy real-world poisoning attack on vision-language-action model in state space.arXiv.org, 2026. doi:10.48550/arXiv.2601.04266
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.04266 2026
-
[47]
E. Rathbun, W. W. Lin, A. Oprea, and C. Amato. Beware untrusted simulators–reward-free backdoor attacks in reinforcement learning.arXiv.org, 2026. doi:10.48550/arXiv.2602.05089
-
[48]
X. Zhou, G. Tie, G. Zhang, H. Wang, P. Zhou, and L. Sun. Badvla: Towards backdoor attacks on vision-language-action models via objective-decoupled optimization. InarXiv.org, 2025. doi:10.48550/arXiv.2505.16640. 11
-
[49]
E. Rathbun, C. Amato, and A. Oprea. Sleepernets: Universal backdoor poisoning attacks against reinforcement learning agents.Neural Information Processing Systems, 37:111994– 112024, 2024. doi:10.48550/arXiv.2405.20539
-
[50]
Kiourti, K
P. Kiourti, K. Wardega, S. Jha, and W. Li. Trojdrl: Trojan attacks on deep reinforcement learning agents.arXiv.org, 2019
2019
-
[51]
M. R. Luo, G. Cui, and B. Rigg. The development of the CIE 2000 colour-difference formula: CIEDE2000.Color Research & Application, 26(5):340–350, 2001. doi:10.1002/col.10 49
-
[52]
Z. Zhao, Z. Liu, and M. Larson. Towards large yet imperceptible adversarial image per- turbations with perceptual color distance. InComputer Vision and Pattern Recognition, pages 1036–1045, June 2019. doi:10.1109/CVPR42600.2020.00112. URLhttps: //arxiv.org/abs/1911.02466
-
[53]
A. Aydin and A. Temizel. Adversarial image generation by spatial transformation in perceptual colorspaces.Pattern Recognition Letters, 174:92–98, 2023. doi:10.1016/j.patrec.2023.09.003. URLhttps://arxiv.org/abs/2310.13950
-
[54]
A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, J. Zeng, et al. Wan: Open and advanced large-scale video generative models.arXiv.org, 2025. doi: 10.48550/arXiv.2503.20314
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.20314 2025
-
[55]
Bagdasarian, R
E. Bagdasarian, R. Jha, T. Zhang, and V . Shmatikov. Adversarial illusions in Multi-Modal embeddings. InUSENIX Security Symposium, 2023
2023
-
[56]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Neural Information Processing Systems, 33:6840–6851, 2020
2020
-
[57]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowl- edge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36:44776–44791, 2023
2023
-
[58]
D. Chen, R. Chen, S. Zhang, Y . Wang, Y . Liu, H. Zhou, Q. Zhang, Y . Wan, P. Zhou, and L. Sun. Mllm-as-a-judge: Assessing multimodal llm-as-a-judge with vision-language benchmark. In International Conference on Machine Learning, 2024
2024
-
[59]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models. arXiv preprint arXiv:2505.12705, 2025
Pith/arXiv arXiv 2025
-
[60]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
M. Towers, A. Kwiatkowski, J. K. Terry, J. U. Balis, G. Cola, T. Deleu, M. Goul ˜ao, A. Kallinteris, M. Krimmel, K. Arjun, et al. Gymnasium: A standard interface for reinforce- ment learning environments.arXiv.org, 2024. doi:10.48550/arXiv.2407.17032
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.17032 2024
-
[61]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Chen, K. Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.Robotics: Science and Systems, 2024. doi:10.48550/arXiv.2403.12945
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.12945 2024
-
[62]
M. J. Kim, Y . Gao, T.-Y . Lin, Y .-C. Lin, Y . Ge, G. Lam, P. Liang, S. Song, M.-Y . Liu, C. Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026
Pith/arXiv arXiv 2026
-
[63]
Madry, A
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu. Towards deep learning mod- els resistant to adversarial attacks. InInternational Conference on Learning Representations, 2018. 12
2018
-
[64]
Post-Trained
S. Huang, R. F. J. Dossa, C. Ye, J. Braga, D. Chakraborty, K. Mehta, and J. G. Ara´ujo. Cleanrl: High-quality single-file implementations of deep reinforcement learning algorithms.Journal of Machine Learning Research, 23(274):1–18, 2022. URLhttp://jmlr.org/papers/v2 3/21-1342.html. 13 Appendix Table of Contents Section Contents Appendix A Experimental Det...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.