Afrispeech Semantics: Evaluating Audio Semantic Reasoning in Spoken Language Models Across Domains and Accents
Pith reviewed 2026-06-30 22:10 UTC · model grok-4.3
The pith
Audio language models exhibit critical limitations in semantic reasoning over spoken audio, including instability and over-inference across accents and domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Audio language models are increasingly used for speech-based understanding, yet their ability to perform semantic reasoning beyond transcription, Text-to-Audio Retrieval, Captioning, and Question-Answering accuracy remains insufficiently benchmarked. In particular, the effects of accent variation, domain shift, and semantic over-inference on audio reasoning are poorly understood. Evaluation across the five tasks of entailment, consistency, plausibility, accent drift, and accent restraint shows that models exhibit instability or over-inference when reasoning over spoken audio as the primary evidence source.
What carries the argument
The five semantic and paralinguistic reasoning tasks (entailment, consistency, plausibility, accent drift, accent restraint) that measure inference from audio, statement alignment, claim plausibility, and prediction stability across accent changes.
If this is right
- Models can fail to determine whether a textual hypothesis is entailed, contradicted, or undetermined by spoken audio.
- Model outputs become unstable or involve over-inference when accent or domain changes occur.
- Existing benchmarks miss these semantic reasoning shortfalls in audio settings.
- Improved ALM design and assessment should incorporate these tasks to achieve more robust and equitable performance.
Where Pith is reading between the lines
- Real-world speech systems using these models could produce inconsistent results for users with non-standard accents or in specialized domains.
- Training approaches that explicitly expose models to accent variation during reasoning tasks might reduce the observed instabilities.
- The same task structure could be adapted to test semantic reasoning in other audio-related models or languages beyond the evaluated set.
Load-bearing premise
The five proposed tasks are sufficient and representative measures of semantic reasoning capabilities in audio language models.
What would settle it
A finding that current audio language models achieve stable, non-over-inferring performance on all five tasks across multiple accents and domains would falsify the claim of critical limitations.
Figures

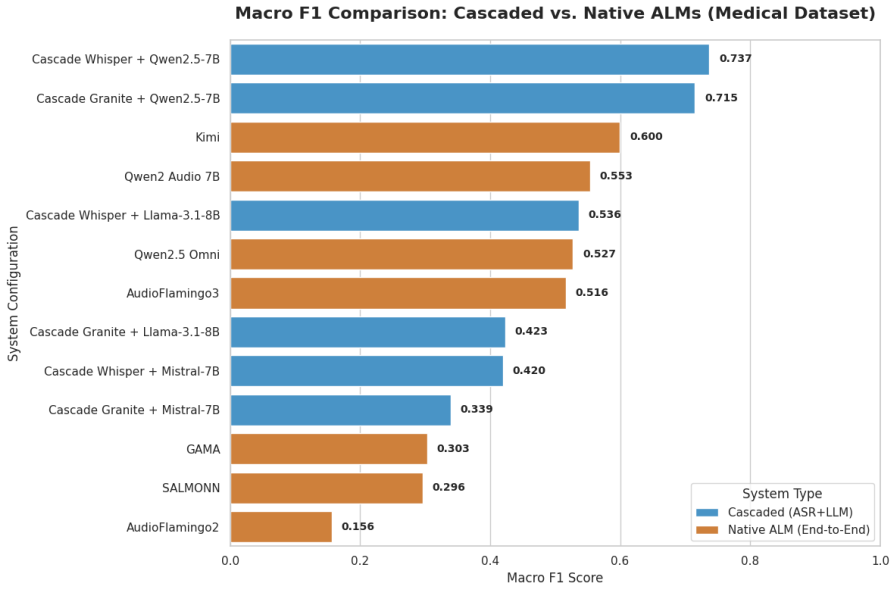
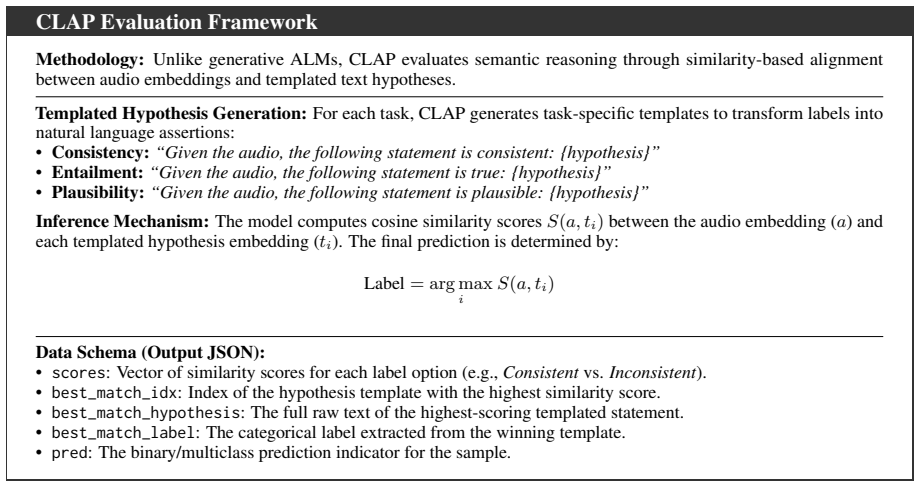
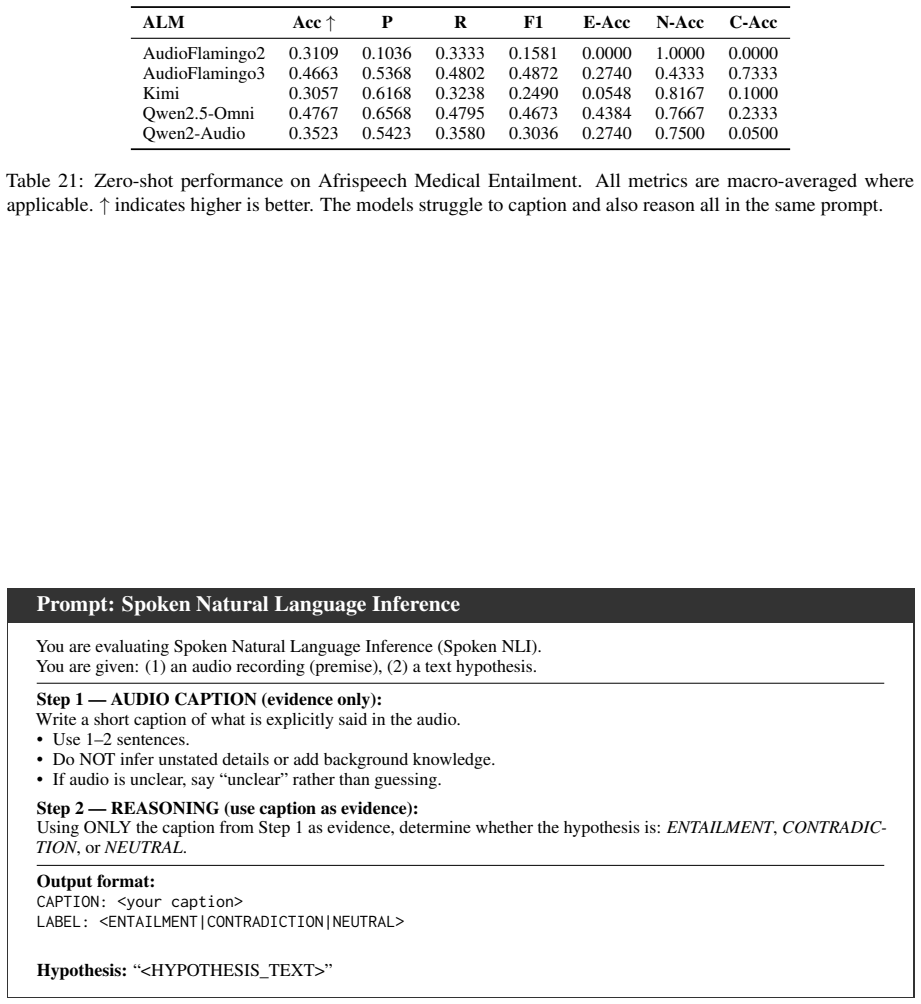
read the original abstract
Audio language models (ALMs) are increasingly used for speech-based understanding, yet their ability to perform semantic reasoning beyond transcription, Text-to-Audio Retrieval, Captioning, and Question-Answering accuracy remains insufficiently benchmarked. In particular, the effects of accent variation, domain shift, and semantic over-inference on audio reasoning are poorly understood. We evaluate audio language models across five semantic and paralinguistic reasoning tasks: entailment, consistency, plausibility, accent drift, and accent restraint. Collectively, these tasks assess a model's ability to reason over spoken audio as the primary evidence source, including whether a textual hypothesis can be inferred, contradicted, or left undetermined by the audio, whether statements align or conflict with spoken content, whether claims are plausible given the discourse, and whether model predictions remain stable or appropriately constrained across accent variation. These findings highlight critical limitations in current audio reasoning evaluations and hope to provide guidance for more robust and equitable ALM design and assessment
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces five tasks—entailment, consistency, plausibility, accent drift, and accent restraint—to benchmark semantic reasoning in audio language models (ALMs), requiring models to treat spoken audio waveforms as the primary evidence source rather than ASR transcripts. It reports quantitative results across multiple ALMs showing performance drops and instabilities under accent variation and domain shift, concluding that current models exhibit critical limitations in audio semantic reasoning.
Significance. If the reported results hold, the work is significant for filling a gap in ALM evaluation beyond transcription, retrieval, captioning, and QA; the concrete definitions of tasks with prompt templates, audio inputs, and scoring rules that enforce audio-as-evidence provide a reproducible framework that could guide more robust and accent-aware ALM development.
minor comments (3)
- [Abstract] Abstract: the sentence beginning 'These findings highlight' refers to results that are not quantified or summarized in the abstract itself; adding one or two key performance metrics (e.g., average accuracy drop under accent drift) would improve standalone readability.
- [Section 3 (Task Definitions)] Task definitions: while the five tasks are described with prompt templates and scoring rules, the manuscript does not include an explicit justification or ablation showing why these particular probes are jointly sufficient; a short paragraph referencing textual NLI benchmarks or human agreement rates would strengthen the claim.
- [Section 4 (Experiments)] Results presentation: tables reporting model performance across tasks and accents would benefit from error bars or statistical significance tests to support the 'critical limitations' claim.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the paper's contribution in defining audio-as-evidence tasks and for recommending minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity; evaluation-only paper
full rationale
The manuscript is an empirical evaluation study that defines five concrete tasks (entailment, consistency, plausibility, accent drift, accent restraint) via prompt templates, audio inputs, and scoring rules, then reports quantitative results across multiple ALMs under accent and domain shifts. No equations, derivations, fitted parameters, or first-principles predictions appear. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claim rests on the empirical outcomes of the defined tasks rather than any reduction to inputs by construction. This is the normal, non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi:10.48550/arXiv.2404.14408 , abstract =
Slagle, Kevin , month = oct, year =. doi:10.48550/arXiv.2404.14408 , abstract =
-
[2]
Robustness assessment of large audio language models in multiple-choice evaluation
López, Fernando and Kesiraju, Santosh and Luque, Jordi , month = oct, year =. Robustness assessment of large audio language models in multiple-choice evaluation , url =. doi:10.48550/arXiv.2510.04584 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.04584
-
[3]
doi:10.48550/arXiv.2403.19971 , abstract =
Chen, Yafeng and Zheng, Siqi and Wang, Hui and Cheng, Luyao and Zhu, Tinglong and Song, Changhe and Huang, Rongjie and Ma, Ziyang and Chen, Qian and Zhang, Shiliang and Li, Xihao , month = mar, year =. doi:10.48550/arXiv.2403.19971 , abstract =
-
[4]
Bhandari, Nishchal and Chen, Danny and Fernández, Miguel Ángel del Río and Delworth, Natalie and Fox, Jennifer Drexler and Jetté, Migüel and McNamara, Quinten and Miller, Corey and Novotný, Ondřej and Profant, Ján and Qin, Nan and Ratajczak, Martin and Robichaud, Jean-Philippe , month = feb, year =. Reverb:. doi:10.48550/arXiv.2410.03930 , abstract =
-
[5]
Yoshimura, Takenori and Hayashi, Tomoki and Takeda, Kazuya and Watanabe, Shinji , month = may, year =. End-to-. doi:10.1109/ICASSP40776.2020.9054358 , abstract =
-
[6]
Anguera, X. and Wooters, C. and Hernando, J. , year =. Purity. 2006. doi:10.1109/ICASSP.2006.1660198 , abstract =
-
[7]
Maynez, Joshua and Narayan, Shashi and Bohnet, Bernd and McDonald, Ryan , editor =. On. Proceedings of the 58th. 2020 , pages =. doi:10.18653/v1/2020.acl-main.173 , abstract =
-
[8]
Fabbri, Alexander R. and Kryściński, Wojciech and McCann, Bryan and Xiong, Caiming and Socher, Richard and Radev, Dragomir , editor =. Transactions of the Association for Computational Linguistics , publisher =. 2021 , pages =. doi:10.1162/tacl_a_00373 , abstract =
-
[9]
Granite-speech: open-source speech-aware
Saon, George and Dekel, Avihu and Brooks, Alexander and Nagano, Tohru and Daniels, Abraham and Satt, Aharon and Mittal, Ashish and Kingsbury, Brian and Haws, David and Morais, Edmilson and Kurata, Gakuto and Aronowitz, Hagai and Ibrahim, Ibrahim and Kuo, Jeff and Soule, Kate and Lastras, Luis and Suzuki, Masayuki and Hoory, Ron and Thomas, Samuel and Novi...
-
[11]
What learning algorithm is in-context learning? Investigations with linear models
Akyürek, Ekin and Schuurmans, Dale and Andreas, Jacob and Ma, Tengyu and Zhou, Denny , month = may, year =. What learning algorithm is in-context learning?. doi:10.48550/arXiv.2211.15661 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.15661
-
[12]
Transformers learn to implement preconditioned gradient descent for in-context learning , url =
Ahn, Kwangjun and Cheng, Xiang and Daneshmand, Hadi and Sra, Suvrit , month = nov, year =. Transformers learn to implement preconditioned gradient descent for in-context learning , url =. doi:10.48550/arXiv.2306.00297 , abstract =
-
[13]
Transformers learn to implement preconditioned gradient descent for in-context learning -
-
[14]
Findings of the
Owodunni, Abraham and Yadavalli, Aditya and Emezue, Chris and Olatunji, Tobi and Mbataku, Clinton , year =. Findings of the
-
[15]
Ogun, Sewade and Owodunni, Abraham T. and Olatunji, Tobi and Alese, Eniola and Oladimeji, Babatunde and Afonja, Tejumade and Olaleye, Kayode and Etori, Naome A. and Adewumi, Tosin , month = jun, year =. 1000. doi:10.48550/arXiv.2406.11727 , abstract =
-
[16]
Afonja, Tejumade and Mudele, Oladimeji and Orife, Iroro and Dukor, Kenechi and Francis, Lawrence and Goodness, Duru and Azeez, Oluwafemi and Malomo, Ademola and Mbataku, Clinton , month = dec, year =. Learning. doi:10.48550/arXiv.2112.06199 , abstract =
-
[17]
On the. Interspeech 2025 , author =. 2025 , note =. doi:10.21437/Interspeech.2025-481 , abstract =
-
[18]
Kim, Jaeyeon and Jung, Jaeyoon and Lee, Jinjoo and Woo, Sang Hoon , year =. Enclap:
-
[19]
Learning source disentanglement in neural audio codec , url =
Bie, Xiaoyu and Liu, Xubo and Richard, Gaël , year =. Learning source disentanglement in neural audio codec , url =
-
[20]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , publisher =
Ai, Yang and Jiang, Xiao-Hang and Lu, Ye-Xin and Du, Hui-Peng and Ling, Zhen-Hua , year =. IEEE/ACM Transactions on Audio, Speech, and Language Processing , publisher =
-
[21]
and Chung, Ho-Lam and Wu, Yuan-Kuei and Yang, Dongchao , year =
Wu, Haibin and Chen, Xuanjun and Lin, Yi-Cheng and Chang, Kaiwei and Du, Jiawei and Lu, Ke-Han and Liu, Alexander H. and Chung, Ho-Lam and Wu, Yuan-Kuei and Yang, Dongchao , year =. Codec-superb@ slt 2024:. 2024
2024
-
[22]
and Marković, Dejan and Richard, Alexander , year =
Wu, Yi-Chiao and Gebru, Israel D. and Marković, Dejan and Richard, Alexander , year =. Audiodec:
-
[23]
Xu, Liang and Wang, Jing and Zhang, Jianqian and Xie, Xiang , year =
-
[24]
IEEE Journal of Selected Topics in Signal Processing , publisher =
Ahn, Sunghwan and Woo, Beom Jun and Han, Min Hyun and Moon, Chanyeong and Kim, Nam Soo , year =. IEEE Journal of Selected Topics in Signal Processing , publisher =
-
[25]
Siuzdak, Hubert and Grötschla, Florian and Lanzendörfer, Luca A. , month = oct, year =. doi:10.48550/arXiv.2410.14411 , abstract =
-
[26]
Soundstream:
Zeghidour, Neil and Luebs, Alejandro and Omran, Ahmed and Skoglund, Jan and Tagliasacchi, Marco , year =. Soundstream:. IEEE/ACM Transactions on Audio, Speech, and Language Processing , publisher =
-
[27]
A comprehensive evaluation of incremental speech recognition and diarization for conversational
Addlesee, Angus and Yu, Yanchao and Eshghi, Arash , year =. A comprehensive evaluation of incremental speech recognition and diarization for conversational. Proceedings of the 28th
-
[28]
Automatic disfluency detection from untranscribed speech , volume =
Romana, Amrit and Koishida, Kazuhito and Provost, Emily Mower , year =. Automatic disfluency detection from untranscribed speech , volume =. IEEE/ACM transactions on audio, speech, and language processing , publisher =
-
[29]
and Jonas, Stephan M
Klischies, Daniel and Kohlschein, Christian and Werner, Cornelius J. and Jonas, Stephan M. , year =. Evaluation of
-
[30]
A review on speech disorders and processing of disordered speech , volume =
Anthony, Audre Arlene and Patil, Chandreshekar Mohan and Basavaiah, Jagadeesh , year =. A review on speech disorders and processing of disordered speech , volume =. Wireless Personal Communications , publisher =
-
[31]
Khan, Ali Sartaz and Ogunremi, Tolulope and Attia, Ahmed Adel and Demszky, Dorottya , month = may, year =. Multi-. doi:10.48550/arXiv.2505.10879 , abstract =
-
[32]
Speaker diarization: a perspective on challenges and opportunities from theory to practice , shorttitle =
Church, Kenneth and Zhu, Weizhong and Vopicka, Josef and Pelecanos, Jason and Dimitriadis, Dimitrios and Fousek, Petr , year =. Speaker diarization: a perspective on challenges and opportunities from theory to practice , shorttitle =. 2017
2017
-
[33]
Speaker diarization:
O’Shaughnessy, Douglas , year =. Speaker diarization:. Applied Sciences , publisher =
-
[34]
Microsoft and Abouelenin, Abdelrahman and Ashfaq, Atabak and Atkinson, Adam and Awadalla, Hany and Bach, Nguyen and Bao, Jianmin and Benhaim, Alon and Cai, Martin and Chaudhary, Vishrav and Chen, Congcong and Chen, Dong and Chen, Dongdong and Chen, Junkun and Chen, Weizhu and Chen, Yen-Chun and Chen, Yi-ling and Dai, Qi and Dai, Xiyang and Fan, Ruchao and...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.01743
-
[35]
and Li, Jason and Ghosh, Subhankar and Balam, Jagadeesh and Ginsburg, Boris , month = oct, year =
Chen, Zhehuai and Huang, He and Andrusenko, Andrei and Hrinchuk, Oleksii and Puvvada, Krishna C. and Li, Jason and Ghosh, Subhankar and Balam, Jagadeesh and Ginsburg, Boris , month = oct, year =. doi:10.48550/arXiv.2310.09424 , abstract =
-
[36]
Roll, Nathan and Graham, Calbert and Tatsumi, Yuka and Nguyen, Kim Tien and Sumner, Meghan and Jurafsky, Dan , month = may, year =. In-. doi:10.48550/arXiv.2505.14887 , abstract =
-
[37]
doi:10.48550/arXiv.2403.16512 , abstract =
Cahyawijaya, Samuel and Lovenia, Holy and Fung, Pascale , month = jun, year =. doi:10.48550/arXiv.2403.16512 , abstract =
-
[38]
Pei, Renhao and Liu, Yihong and Lin, Peiqin and Yvon, François and Schuetze, Hinrich , editor =. Understanding. Proceedings of the 63rd. 2025 , pages =. doi:10.18653/v1/2025.acl-long.429 , abstract =
-
[39]
Li, Yue and Zhao, Zhixue and Scarton, Carolina , month = aug, year =. It's. doi:10.48550/arXiv.2508.19089 , abstract =
-
[40]
Multimodal In-context Learning for ASR of Low-resource Languages
Li, Zhaolin and Niehues, Jan , month = jan, year =. Multimodal. doi:10.48550/arXiv.2601.05707 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.05707
-
[41]
Language, Speech, and Hearing Services in Schools , author =
Developmental. Language, Speech, and Hearing Services in Schools , author =. 2017 , pages =. doi:10.1044/2017_LSHSS-17-0028 , abstract =
-
[42]
Journal of fluency disorders , author =
Behavioral and. Journal of fluency disorders , author =. 2023 , pages =. doi:10.1016/j.jfludis.2023.105972 , abstract =
-
[43]
Communicating. Ear and Hearing , author =. 2023 , pages =. doi:10.1097/AUD.0000000000001399 , abstract =
-
[44]
The Journal of the Acoustical Society of America , author =
Acoustic correlates and listener ratings of function word reduction in child versus adult speech , volume =. The Journal of the Acoustical Society of America , author =. 2022 , pages =. doi:10.1121/10.0013835 , abstract =
-
[45]
Li, Zhaolin and Niehues, Jan , month = aug, year =. In-context. Interspeech 2025 , publisher =. doi:10.21437/Interspeech.2025-2626 , abstract =
-
[46]
Interspeech 2025 , publisher =
Wan, Zixiang and Zhang, Guochang and He, Yifeng and Wei, Jianqiang , month = aug, year =. Interspeech 2025 , publisher =. doi:10.21437/Interspeech.2025-546 , language =
-
[47]
Interspeech 2025 , publisher =
Zhang, Bowen and McLoughlin, Ian and Miao, Xiaoxiao and Madhukumar, As , month = aug, year =. Interspeech 2025 , publisher =. doi:10.21437/Interspeech.2025-1335 , abstract =
-
[48]
Mellow: a small audio language model for reasoning , abstract =
-
[49]
Bhati, Saurabhchand and Thomas, Samuel and Kuehne, Hilde and Feris, Rogerio and Glass, James , month = nov, year =. Towards. doi:10.48550/arXiv.2511.20973 , abstract =
-
[50]
Shi, Jiatong and Tian, Jinchuan and Wu, Yihan and Jung, Jee-Weon and Yip, Jia Qi and Masuyama, Yoshiki and Chen, William and Wu, Yuning and Tang, Yuxun and Baali, Massa and Alharthi, Dareen and Zhang, Dong and Deng, Ruifan and Srivastava, Tejes and Wu, Haibin and Liu, Alexander and Raj, Bhiksha and Jin, Qin and Song, Ruihua and Watanabe, Shinji , month = ...
-
[51]
doi:10.48550/arXiv.2411.18803 , abstract =
Wu, Haibin and Kanda, Naoyuki and Eskimez, Sefik Emre and Li, Jinyu , month = apr, year =. doi:10.48550/arXiv.2411.18803 , abstract =
-
[52]
Wu, Haibin and Chung, Ho-Lam and Lin, Yi-Cheng and Wu, Yuan-Kuei and Chen, Xuanjun and Pai, Yu-Chi and Wang, Hsiu-Hsuan and Chang, Kai-Wei and Liu, Alexander and Lee, Hung-yi , editor =. Codec-. Findings of the. 2024 , pages =. doi:10.18653/v1/2024.findings-acl.616 , abstract =
-
[53]
arXiv.org , author =
-
[54]
Ren, Yong and Wang, Tao and Yi, Jiangyan and Xu, Le and Tao, Jianhua and Zhang, Chuyuan and Zhou, Junzuo , month = mar, year =. Fewer-token. doi:10.48550/arXiv.2310.00014 , abstract =
-
[55]
High-Quality, Low-Delay Music Coding in the Opus Codec
Valin, Jean-Marc and Maxwell, Gregory and Terriberry, Timothy B. and Vos, Koen , month = feb, year =. High-. doi:10.48550/arXiv.1602.04845 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1602.04845
-
[56]
Kumar, Rithesh and Seetharaman, Prem and Luebs, Alejandro and Kumar, Ishaan and Kumar, Kundan , month = oct, year =. High-. doi:10.48550/arXiv.2306.06546 , abstract =
-
[57]
doi:10.48550/arXiv.2412.01053 , abstract =
Zheng, Youqiang and Tu, Weiping and Kang, Yueteng and Chen, Jie and Zhang, Yike and Xiao, Li and Yang, Yuhong and Ma, Long , month = jun, year =. doi:10.48550/arXiv.2412.01053 , abstract =
-
[58]
doi:10.48550/arXiv.2502.20067 , abstract =
Jiang, Yidi and Chen, Qian and Ji, Shengpeng and Xi, Yu and Wang, Wen and Zhang, Chong and Yue, Xianghu and Zhang, ShiLiang and Li, Haizhou , month = feb, year =. doi:10.48550/arXiv.2502.20067 , abstract =
-
[59]
Siuzdak, Hubert , month = may, year =. Vocos:. doi:10.48550/arXiv.2306.00814 , abstract =
-
[60]
Défossez, Alexandre and Copet, Jade and Synnaeve, Gabriel and Adi, Yossi , month = oct, year =. High. doi:10.48550/arXiv.2210.13438 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2210.13438
-
[61]
Bringing. Interspeech 2025 , author =. 2025 , note =. doi:10.21437/Interspeech.2025-115 , abstract =
-
[62]
IEEE Journal of Selected Topics in Signal Processing , author =. 2024 , note =. doi:10.1109/JSTSP.2024.3506286 , abstract =
-
[63]
doi:10.48550/arXiv.2405.11554 , abstract =
Braun, David , month = may, year =. doi:10.48550/arXiv.2405.11554 , abstract =
-
[64]
Ji, Shengpeng and Jiang, Ziyue and Wang, Wen and Chen, Yifu and Fang, Minghui and Zuo, Jialong and Yang, Qian and Cheng, Xize and Wang, Zehan and Li, Ruiqi and Zhang, Ziang and Yang, Xiaoda and Huang, Rongjie and Jiang, Yidi and Chen, Qian and Zheng, Siqi and Zhao, Zhou , month = feb, year =. doi:10.48550/arXiv.2408.16532 , abstract =
-
[65]
Ji, Shengpeng and Fang, Minghui and Zuo, Jialong and Jiang, Ziyue and Wang, Dingdong and Wang, Hanting and Huang, Hai and Zhao, Zhou , month = jun, year =. Language-. doi:10.48550/arXiv.2402.12208 , abstract =
-
[66]
Sarkar, Ayushman and Idris, Mohd Yamani Idna and Yu, Zhenyu , month = aug, year =. Reasoning in. doi:10.48550/arXiv.2508.10523 , abstract =
-
[67]
and Karlinsky, Leonid and Glass, James , month = feb, year =
Gong, Yuan and Luo, Hongyin and Liu, Alexander H. and Karlinsky, Leonid and Glass, James , month = feb, year =. Listen,. doi:10.48550/arXiv.2305.10790 , abstract =
-
[68]
Chu, Yunfei and Xu, Jin and Yang, Qian and Wei, Haojie and Wei, Xipin and Guo, Zhifang and Leng, Yichong and Lv, Yuanjun and He, Jinzheng and Lin, Junyang and Zhou, Chang and Zhou, Jingren , month = jul, year =. Qwen2-. doi:10.48550/arXiv.2407.10759 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.10759
-
[69]
Goel, Arushi and Ghosh, Sreyan and Kim, Jaehyeon and Kumar, Sonal and Kong, Zhifeng and Lee, Sang-gil and Yang, Chao-Han Huck and Duraiswami, Ramani and Manocha, Dinesh and Valle, Rafael and Catanzaro, Bryan , month = jul, year =. Audio. doi:10.48550/arXiv.2507.08128 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.08128
-
[70]
and Nieto, Oriol and Duraiswami, Ramani and Manocha, Dinesh , month = jun, year =
Ghosh, Sreyan and Kumar, Sonal and Seth, Ashish and Evuru, Chandra Kiran Reddy and Tyagi, Utkarsh and Sakshi, S. and Nieto, Oriol and Duraiswami, Ramani and Manocha, Dinesh , month = jun, year =. doi:10.48550/arXiv.2406.11768 , abstract =
-
[71]
SALMONN: Towards Generic Hearing Abilities for Large Language Models
Tang, Changli and Yu, Wenyi and Sun, Guangzhi and Chen, Xianzhao and Tan, Tian and Li, Wei and Lu, Lu and Ma, Zejun and Zhang, Chao , month = apr, year =. doi:10.48550/arXiv.2310.13289 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.13289
-
[72]
KimiTeam and Ding, Ding and Ju, Zeqian and Leng, Yichong and Liu, Songxiang and Liu, Tong and Shang, Zeyu and Shen, Kai and Song, Wei and Tan, Xu and Tang, Heyi and Wang, Zhengtao and Wei, Chu and Xin, Yifei and Xu, Xinran and Yu, Jianwei and Zhang, Yutao and Zhou, Xinyu and Charles, Y. and Chen, Jun and Chen, Yanru and Du, Yulun and He, Weiran and Hu, Zh...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.18425
-
[73]
Deshmukh, Soham and Elizalde, Benjamin and Singh, Rita and Wang, Huaming , month = jan, year =. Pengi:. doi:10.48550/arXiv.2305.11834 , abstract =
-
[74]
Ghosh, Sreyan and Kong, Zhifeng and Kumar, Sonal and Sakshi, S. and Kim, Jaehyeon and Ping, Wei and Valle, Rafael and Manocha, Dinesh and Catanzaro, Bryan , month = mar, year =. Audio. doi:10.48550/arXiv.2503.03983 , abstract =
-
[75]
Shan, Weiqiao and Li, Yuang and Zhang, Yuhao and Luo, Yingfeng and Xu, Chen and Zhao, Xiaofeng and Meng, Long and Lu, Yunfei and Zhang, Min and Yang, Hao and Xiao, Tong and Zhu, JingBo , editor =. Enhancing. Proceedings of the 2025. 2025 , pages =. doi:10.18653/v1/2025.emnlp-main.974 , abstract =
-
[76]
doi:10.48550/arXiv.2206.04769 , abstract =
Elizalde, Benjamin and Deshmukh, Soham and Ismail, Mahmoud Al and Wang, Huaming , month = jun, year =. doi:10.48550/arXiv.2206.04769 , abstract =
-
[77]
doi:10.48550/arXiv.2508.02018 , abstract =
Yang, Wanqi and Li, Yanda and Wei, Yunchao and Fang, Meng and Chen, Ling , month = aug, year =. doi:10.48550/arXiv.2508.02018 , abstract =
-
[78]
Journal of College and University Law , author =
Section 504 of the. Journal of College and University Law , author =. 1986 , pages =
1986
-
[79]
The Ochsner Journal , author =
A. The Ochsner Journal , author =. 2019 , pages =. doi:10.31486/toj.19.0028 , abstract =
-
[80]
Journal of Government Information , author =
Beyond. Journal of Government Information , author =. 2004 , keywords =. doi:10.1016/j.jgi.2004.09.010 , abstract =
-
[81]
Journal of College and University Law , author =
Application of the. Journal of College and University Law , author =. 1996 , pages =
1996
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.