Agentic Environment Engineering for Large Language Models: A Survey of Environment Modeling, Synthesis, Evaluation, and Application
Pith reviewed 2026-06-27 09:45 UTC · model grok-4.3
The pith
Environments for LLM-based agents are engineered through modeling, synthesis, evaluation, and application to support continual capability evolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
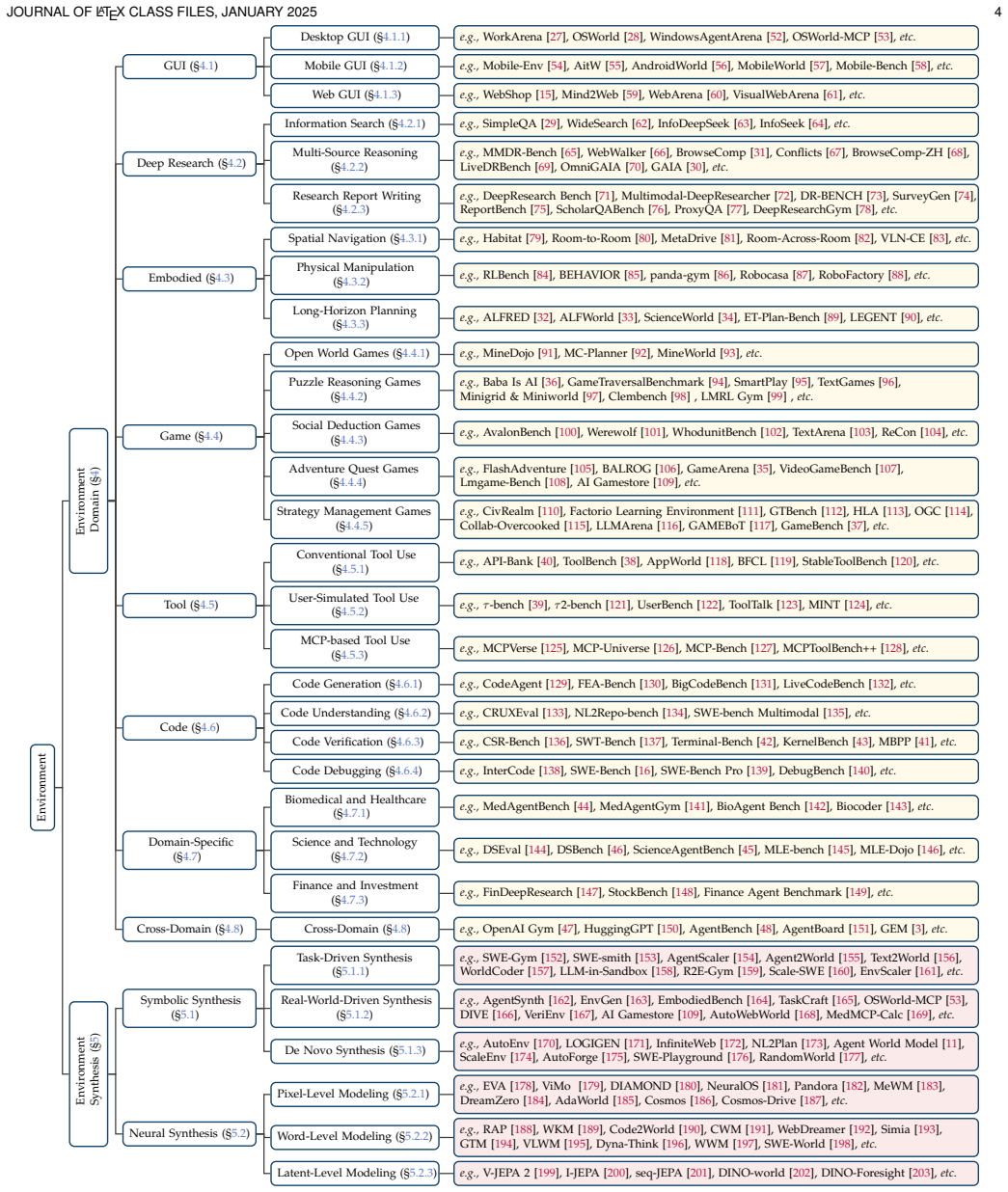
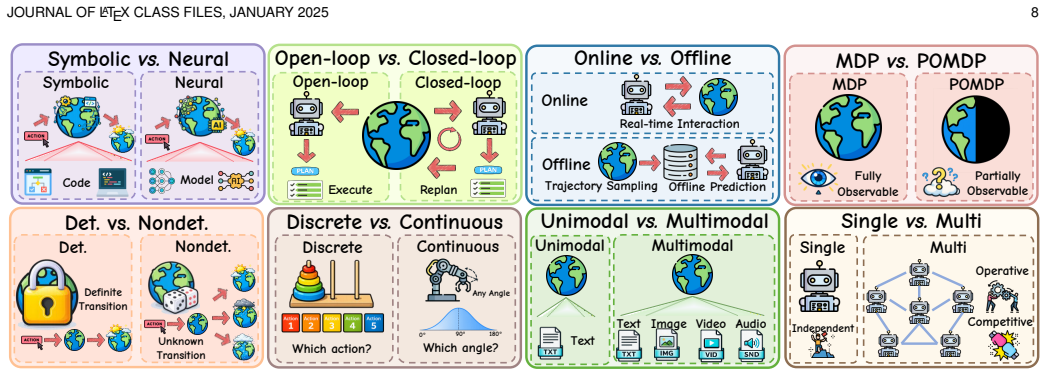
Environments serve as interactive systems for large language model based agents across diverse scenarios and play a crucial role in driving the continual evolution of model capabilities. The paper systematically studies current researches on agentic environments from the perspective of the environment engineering lifecycle, covering their modeling, synthesis, evaluation and application. It introduces representative environments from the perspectives of eight attributes and eight domains, two paradigms for automated environment synthesis, different environment evaluation methods, and from the agent-environment co-evolution perspective, four complementary perspectives for agent evolution and t
What carries the argument
The environment engineering lifecycle, which organizes the study of agentic environments into stages of modeling, synthesis, evaluation, and application, with co-evolution as the application focus.
If this is right
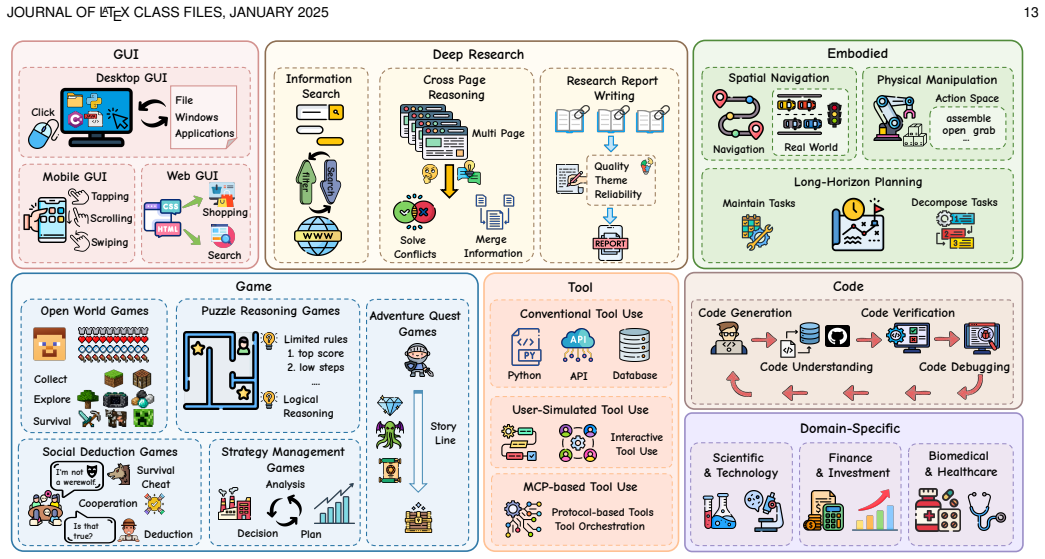
- Representative environments are classified using eight attributes and eight domains.
- Automated synthesis uses symbolic synthesis and neural synthesis paradigms.
- Evaluation methods are tied to each synthesis paradigm.
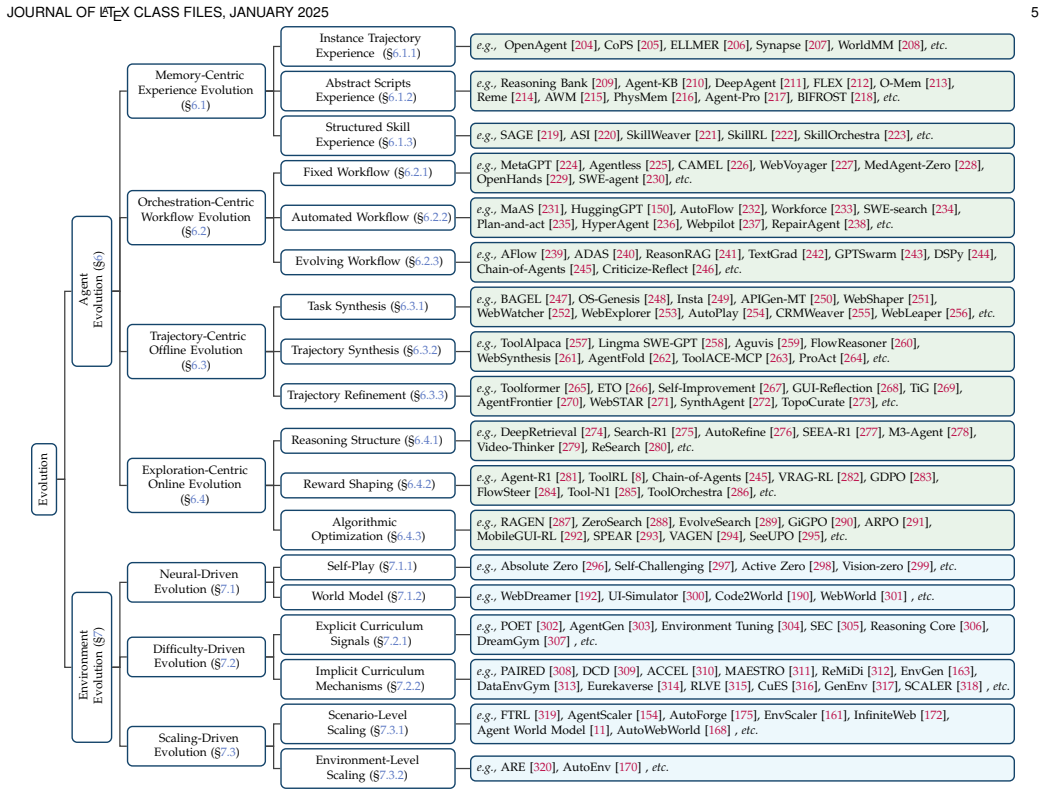
- Agent evolution follows memory-centric, orchestration-centric, trajectory-centric or exploration-centric paths.
- Environment evolution is neural-driven, difficulty-driven or scaling-driven.
Where Pith is reading between the lines
- Organizing environments this way may reveal opportunities to create hybrid environments that combine symbolic and neural synthesis for more robust testing.
- The four agent evolution perspectives could be combined in single systems to test if they produce synergistic improvements.
- Future environment design might prioritize scaling-driven approaches if they prove most effective at pushing model limits.
- This survey implies that progress in LLM agents depends as much on environment quality as on model architecture.
Load-bearing premise
The representative environments, paradigms, and pathways selected from the literature provide a comprehensive and unbiased view of the field without significant omissions in coverage or categorization.
What would settle it
Identification of an important agentic environment or evolution method that does not align with the proposed eight attributes and domains, two synthesis paradigms, four agent evolution perspectives, or three environment evolution paradigms.
Figures


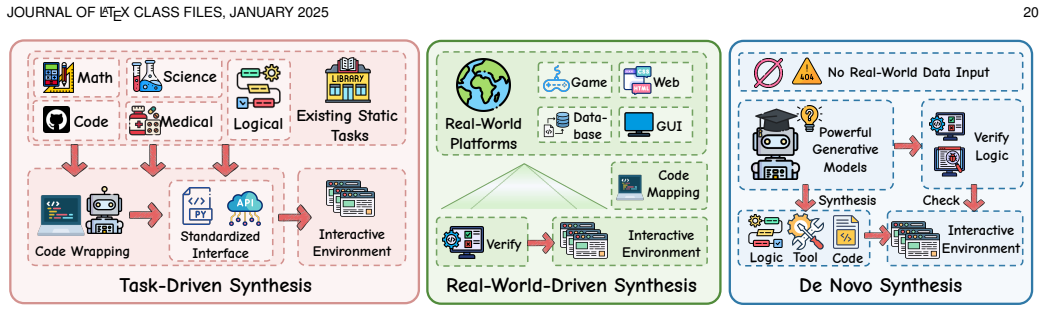
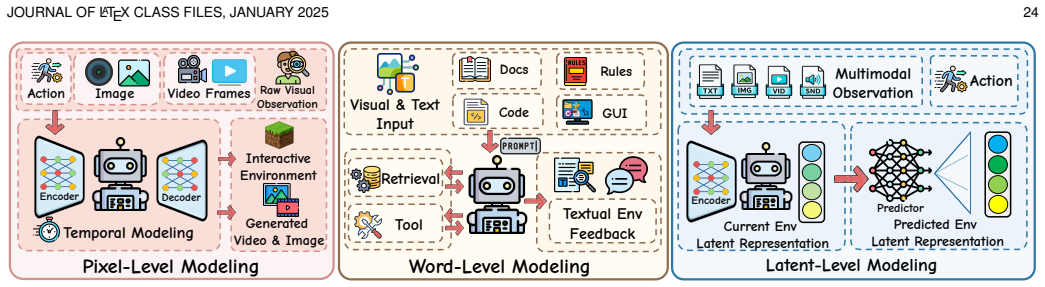
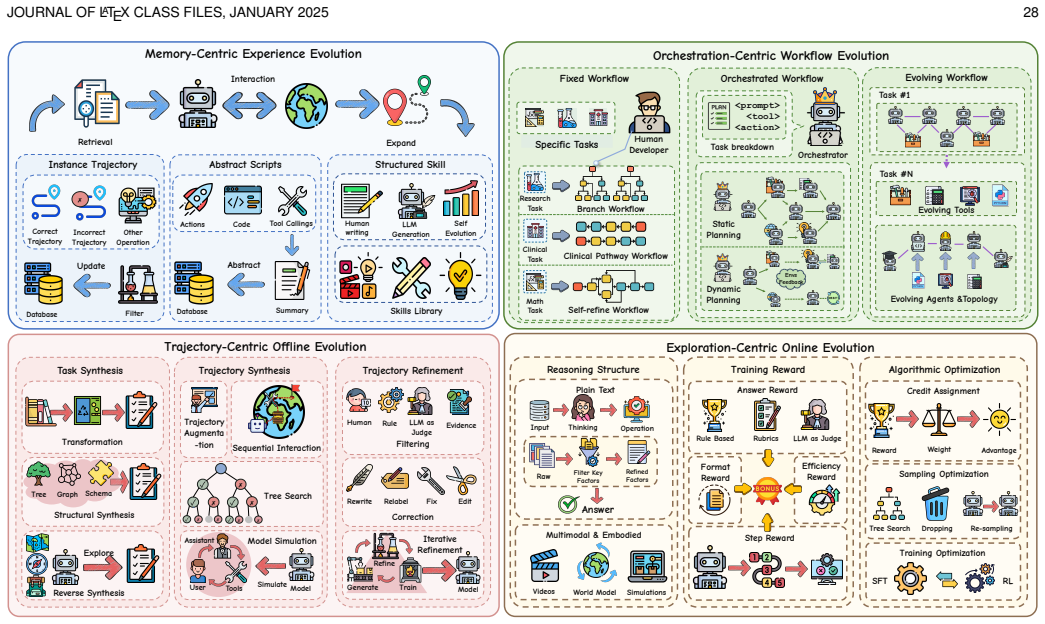

read the original abstract
Environments serve as interactive systems for large language model (LLM) based agents across diverse scenarios and play a crucial role in driving the continual evolution of model capabilities. Despite this importance, existing work lacks a systematic categorization and deep analysis. This paper systematically studies current researches on agentic environments from the perspective of the environment engineering lifecycle, covering their modeling, synthesis, evaluation and application. Specifically, the paper first introduces representative environments from the perspectives of eight attributes and eight domains, providing detailed analyses of their development paths and highlighting their core capabilities. Second, for automated environment synthesis, two paradigms are introduced, such as symbolic synthesis and neural synthesis. This paper also shows different environment evaluation methods in each paradigm. Thirdly, the corresponding environment applications from the perspective of agent-environment co-evolution are discussed. In specific, the paper characterizes the primary pathways for agent evolution in dynamic environments from four complementary perspectives: memory-centric experience evolution, orchestration-centric workflow evolution, trajectory-centric offline evolution, and exploration-centric online evolution. And three paradigms of environment evolution are identified, namely neural-driven, difficulty-driven, and scaling-driven approaches. At last, several promising future directions are discussed, including Environment-as-a-Service, Multi-agent Environments, and Neural-Symbolic Environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver a systematic survey of agentic environments for LLM-based agents, organized around the environment engineering lifecycle. It first categorizes representative environments via eight attributes and eight domains, analyzing their development paths and core capabilities; second, it presents two automated synthesis paradigms (symbolic and neural) together with associated evaluation methods; third, it examines applications through agent-environment co-evolution, characterizing four complementary evolution pathways (memory-centric experience evolution, orchestration-centric workflow evolution, trajectory-centric offline evolution, exploration-centric online evolution) and three environment-evolution paradigms (neural-driven, difficulty-driven, scaling-driven); finally, it outlines future directions including Environment-as-a-Service, Multi-agent Environments, and Neural-Symbolic Environments.
Significance. If the selected representatives and categorizations are shown to be comprehensive, the survey would provide a useful organizing framework for an emerging area by foregrounding the co-evolution of agents and environments. The lifecycle perspective and explicit enumeration of pathways and paradigms constitute a concrete contribution that could guide subsequent research; the paper earns credit for attempting to synthesize diverse lines of work into a structured lifecycle view rather than a simple enumeration.
major comments (1)
- [Introduction / survey scope] Introduction / survey scope: The abstract asserts that the paper 'systematically studies current researches' and selects 'representative environments' across eight attributes, eight domains, two synthesis paradigms, four evolution pathways, and three environment-evolution paradigms, yet no description is given of the literature search strategy, databases, keywords, temporal scope, or inclusion/exclusion criteria. This is load-bearing for the central claim, because without such details it is impossible to verify whether the chosen categories constitute a comprehensive, unbiased view or a post-hoc organization that may omit major lines of work (e.g., certain embodied or multi-agent setups).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the survey scope and methodology. We agree that explicit details on the literature search process are necessary to support the claim of a systematic survey and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Introduction / survey scope] Introduction / survey scope: The abstract asserts that the paper 'systematically studies current researches' and selects 'representative environments' across eight attributes, eight domains, two synthesis paradigms, four evolution pathways, and three environment-evolution paradigms, yet no description is given of the literature search strategy, databases, keywords, temporal scope, or inclusion/exclusion criteria. This is load-bearing for the central claim, because without such details it is impossible to verify whether the chosen categories constitute a comprehensive, unbiased view or a post-hoc organization that may omit major lines of work (e.g., certain embodied or multi-agent setups).
Authors: We acknowledge the validity of this observation. The current manuscript does not include an explicit description of the search strategy. In the revised version we will insert a new subsection (tentatively titled 'Survey Methodology') immediately after the Introduction that specifies: (1) databases queried (arXiv, ACL Anthology, NeurIPS/ICLR/ICML proceedings, and Google Scholar), (2) primary keywords and Boolean combinations (e.g., "LLM agent" AND (environment OR simulator OR benchmark)), (3) temporal scope (primarily 2022–2024 with selected foundational works), and (4) inclusion/exclusion criteria (interactive environments supporting LLM-based agents; exclusion of purely static datasets or non-agentic simulators). We will also add a brief limitations paragraph noting that, while the eight domains and attributes aim to capture the dominant research threads, certain specialized embodied or multi-agent configurations may receive lighter coverage and are flagged for future expansion. These additions will allow readers to assess the representativeness of the selected categories. revision: yes
Circularity Check
No circularity: survey organizes external literature
full rationale
This is a literature survey paper with no mathematical derivations, equations, fitted parameters, predictions, or self-referential claims. The central content consists of categorizing and summarizing cited external works across modeling, synthesis, evaluation, and application. No load-bearing step reduces by construction to the paper's own inputs or self-citations. Selection of representatives is presented as a review of the field rather than a derived result, so concerns about coverage fall under completeness rather than circularity. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 3 Pith papers
-
Empowering GUI Agents via Autonomous Experience Exploration and Hindsight Experience Utilization for Task Planning
PEEU enables a 7B MLLM to reach 30.6% accuracy on GUI task planning by autonomous exploration and hindsight experience synthesis, outperforming a 32B model through stronger high-level OOD generalization.
-
Why Multi-Step Tool-Use Reinforcement Learning Collapses and How Supervisory Signals Fix It
RL for LLM multi-step tool use collapses from control token probability spikes but interleaving SFT improves stability at the cost of OOD generalization.
-
Look Light, Think Heavy: What Multimodal Chain-of-Thought Reasoning Can and Cannot Do
Multimodal CoT improves math and science reasoning but degrades visual perception performance and exhibits a pattern of diminishing visual reflection while verbal reflection varies.
Reference graph
Works this paper leans on
-
[1]
Q. Team, “Qwen3 technical report,”CoRR, vol. abs/2505.09388,
-
[2]
BrainOmni: A Brain Foundation Model for Unified EEG and MEG Signals
[Online]. Available: https://doi.org/10.48550/arXiv.2505. 09388
-
[3]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,
DeepSeek-AI, “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”CoRR, vol. abs/2501.12948,
-
[4]
Available: https://doi.org/10.48550/arXiv.2501
[Online]. Available: https://doi.org/10.48550/arXiv.2501. 12948
-
[5]
Z. Liu, A. Sims, K. Duan, C. Chen, S. Yu, X. Zhou, H. Xu, S. Xiong, B. Liu, C. Tan, C. Y. Beh, W. Wang, H. Zhu, W. Shi, D. Yang, M. Shieh, Y. W. Teh, W. S. Lee, and M. Lin, “GEM: A gym for agentic llms,”CoRR, vol. abs/2510.01051, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2510.01051
-
[6]
Humanity’s last code exam: Can advanced llms conquer human’s hardest code competition?
X. Li, X. Li, K. Dong, Q. Zhang, R. Ruan, X. Dai, Y. Wang, and R. Tang, “Humanity’s last code exam: Can advanced llms conquer human’s hardest code competition?” inFindings of the Association for Computational Linguistics: EMNLP 2025, Suzhou, China, November 4-9, 2025, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Association for Compu...
2025
-
[7]
(2025) Introducing gpt-5.4
OpenAI. (2025) Introducing gpt-5.4. Accessed: 2026- 03-16. [Online]. Available: https://openai.com/index/ introducing-gpt-5-4/
2025
-
[8]
(2025) Gemini 3.1 pro
Google DeepMind. (2025) Gemini 3.1 pro. Accessed: 2026-03-16. [Online]. Available: https://deepmind.google/models/gemini/ pro/
2025
-
[9]
Kimi K2.5: visual agentic intelligence,
K. Team, “Kimi K2.5: visual agentic intelligence,”CoRR, vol. abs/2602.02276, 2026. [Online]. Available: https://doi.org/10. 48550/arXiv.2602.02276
Pith/arXiv arXiv 2026
-
[10]
ToolRL: Reward is All Tool Learning Needs
C. Qian, E. C. Acikgoz, Q. He, H. Wang, X. Chen, D. Hakkani- Tür, G. Tur, and H. Ji, “Toolrl: Reward is all tool learning needs,”CoRR, vol. abs/2504.13958, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2504.13958
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.13958 2025
-
[11]
Travelplanner: A benchmark for real-world planning with language agents,
J. Xie, K. Zhang, J. Chen, T. Zhu, R. Lou, Y. Tian, Y. Xiao, and Y. Su, “Travelplanner: A benchmark for real-world planning with language agents,” inForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, ser. Proceedings of Machine Learning Research, R. Salakhutdinov, Z. Kolter, K. A. Heller, A. Weller, N. ...
2024
-
[12]
Self-refine: Iterative refinement with self- feedback,
A. Madaan, N. Tandon, P . Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, S. Gupta, B. P . Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P . Clark, “Self-refine: Iterative refinement with self- feedback,” inAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing...
2023
-
[13]
Agent world model: Infinity synthetic environments for agentic reinforcement learning,
Z. Wang, C. Xu, B. Liu, Y. Wang, S. Han, Z. Yao, H. Yao, and Y. He, “Agent world model: Infinity synthetic environments for agentic reinforcement learning,”arXiv preprint arXiv:2602.10090, 2026
Pith/arXiv arXiv 2026
-
[14]
Rwku: Benchmarking real-world knowledge unlearning for large language models,
P . Cao, C. Wang, Z. He, H. Yuan, J. Li, Y. Chen, K. Liu, J. Zhao et al., “Rwku: Benchmarking real-world knowledge unlearning for large language models,” vol. 37, 2024, pp. 98 213–98 263
2024
-
[15]
A trouble- maker with contagious jailbreak makes chaos in honest towns,
T. Men, P . Cao, Z. Jin, Y. Chen, K. Liu, and J. Zhao, “A trouble- maker with contagious jailbreak makes chaos in honest towns,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 17 561– 17 587
2025
-
[16]
Dacomp: Benchmarking data agents across the full data intelligence lifecycle,
F. Lei, J. Meng, Y. Huang, J. Zhao, Y. Zhang, J. Luo, X. Zou, R. Yang, W. Shi, Y. Gaoet al., “Dacomp: Benchmarking data agents across the full data intelligence lifecycle,”arXiv preprint arXiv:2512.04324, 2025
arXiv 2025
-
[17]
Webshop: Towards scalable real-world web interaction with grounded language agents,
S. Yao, H. Chen, J. Yang, and K. Narasimhan, “Webshop: Towards scalable real-world web interaction with grounded language agents,” inAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, S. Koyejo, S. Mohamed, A. Agarwal, D....
2022
-
[18]
Swe-bench: Can language models resolve real-world github issues?
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan, “Swe-bench: Can language models resolve real-world github issues?” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. [Online]. Available: https://openreview.net/forum?id=VTF8yNQM66
2024
-
[19]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. R. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” inThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. [Online]. Available: https: //openreview.net/forum?id=WE_vluYUL-X
2023
-
[20]
Fixing the broken compass: Diagnosing and improving inference-time reward modeling,
J. Li, P . Cao, Y. Chen, J. Xu, H. Li, X. Jiang, K. Liu, and J. Zhao, “Fixing the broken compass: Diagnosing and improving inference-time reward modeling,” 2025
2025
-
[21]
Omni-reward: Towards generalist omni-modal reward model- ing with free-form preferences,
Z. Jin, H. Yuan, K. Zhu, J. Li, P . Cao, Y. Chen, K. Liu, and J. Zhao, “Omni-reward: Towards generalist omni-modal reward model- ing with free-form preferences,”arXiv preprint arXiv:2510.23451, 2025
arXiv 2025
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P . Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y. K. Li, Y. Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical reasoning in open language models,”CoRR, vol. abs/2402.03300, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[23]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y. Yuan, X. Zuo, Y. Yue, T. Fan, G. Liu, L. Liu, X. Liu, H. Lin, Z. Lin, B. Ma, G. Sheng, Y. Tong, C. Zhang, M. Zhang, W. Zhang, H. Zhu, J. Zhu, J. Chen, J. Chen, C. Wang, H. Yu, W. Dai, Y. Song, X. Wei, H. Zhou, J. Liu, W. Ma, Y. Zhang, L. Yan, M. Qiao, Y. Wu, and M. Wang, “DAPO: an open-source LLM reinforcement learning system a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14476 2025
-
[24]
Reinforced internal-external knowledge synergistic reasoning for efficient adaptive search agent,
Z. Huang, X. Yuan, Y. Ju, J. Zhao, and K. Liu, “Reinforced internal-external knowledge synergistic reasoning for efficient adaptive search agent,”arXiv preprint arXiv:2505.07596, 2025
arXiv 2025
-
[25]
Towards agentic self-learning llms in search environ- ment,
W. Sun, X. Cheng, J. Fan, Y. Xu, X. Yu, S. He, J. Zhao, and K. Liu, “Towards agentic self-learning llms in search environ- ment,”arXiv preprint arXiv:2510.14253, 2025
arXiv 2025
-
[26]
Agentic Reasoning for Large Language Models
T. Wei, T. Li, Z. Liu, X. Ning, Z. Yang, J. Zou, Z. Zeng, R. Qiu, X. Lin, D. Fu, Z. Li, M. Ai, D. Zhou, W. Bao, Y. Li, G. Li, C. Qian, Y. Wang, X. Tang, Y. Xiao, L. Fang, H. Liu, X. Tang, Y. Zhang, C. Wang, J. You, H. Ji, H. Tong, and J. He, “Agentic reasoning for large language models,”CoRR, vol. abs/2601.12538, 2026. [Online]. Available: https://doi.org...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.12538 2026
-
[27]
Large language models for plan- ning: A comprehensive and systematic survey,
P . Cao, T. Men, W. Liu, J. Zhang, X. Li, X. Lin, D. Sui, Y. Cao, K. Liu, and J. Zhao, “Large language models for plan- ning: A comprehensive and systematic survey,”arXiv preprint arXiv:2505.19683, 2025
arXiv 2025
-
[28]
A survey of recent advances in commonsense knowledge acquisition: Methods and resources,
C. Wang, J. Li, Y. Chen, K. Liu, and J. Zhao, “A survey of recent advances in commonsense knowledge acquisition: Methods and resources,”Machine Intelligence Research, vol. 22, no. 2, pp. 201– 218, 2025
2025
-
[29]
Workarena: How capable are web agents at solving common knowledge work tasks?
A. Drouin, M. Gasse, M. Caccia, I. H. Laradji, M. D. Verme, T. Marty, D. Vázquez, N. Chapados, and A. Lacoste, “Workarena: How capable are web agents at solving common knowledge work tasks?” inForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21- 27, 2024, ser. Proceedings of Machine Learning Research, R. Salakhutd...
2024
-
[30]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments,
T. Xie, D. Zhang, J. Chen, X. Li, S. Zhao, R. Cao, T. J. Hua, Z. Cheng, D. Shin, F. Lei, Y. Liu, Y. Xu, S. Zhou, S. Savarese, C. Xiong, V . Zhong, and T. Yu, “Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments,” inAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processin...
2024
-
[31]
Measuring short-form factuality in large language models,
J. Wei, N. Karina, H. W. Chung, Y. J. Jiao, S. Papay, A. Glaese, J. Schulman, and W. Fedus, “Measuring short-form factuality in large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2411.04368
Pith/arXiv arXiv 2024
-
[32]
GAIA: a benchmark for general AI assistants,
G. Mialon, C. Fourrier, T. Wolf, Y. LeCun, and T. Scialom, “GAIA: a benchmark for general AI assistants,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. [Online]. Available: https://openreview.net/forum?id=fibxvahvs3
2024
-
[33]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
J. Wei, Z. Sun, S. Papay, S. McKinney, J. Han, I. Fulford, H. W. Chung, A. T. Passos, W. Fedus, and A. Glaese, “Browsecomp: A simple yet challenging benchmark for browsing agents,”CoRR, vol. abs/2504.12516, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2504.12516
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.12516 2025
-
[34]
ALFRED: A benchmark for interpreting grounded instructions for everyday tasks,
M. Shridhar, J. Thomason, D. Gordon, Y. Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “ALFRED: A benchmark for interpreting grounded instructions for everyday tasks,” in2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020. Computer Vision Foundation / IEEE, 2020, pp. 10 737–10 746. [On...
2020
-
[35]
Alfworld: Aligning text and embodied environments for interactive learning,
M. Shridhar, X. Yuan, M. Côté, Y. Bisk, A. Trischler, and M. J. Hausknecht, “Alfworld: Aligning text and embodied environments for interactive learning,” in9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. [Online]. Available: https://openreview.net/forum?id=0IOX0YcCdTn
2021
-
[36]
Scienceworld: Is your agent smarter than a 5th grader?
R. Wang, P . A. Jansen, M. Côté, and P . Ammanabrolu, “Scienceworld: Is your agent smarter than a 5th grader?” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, Y. Goldberg, Z. Kozareva, and Y. Zhang, Eds. Association for Computational Linguistics, 20...
-
[37]
Gamearena: Evaluating llm reasoning through live computer games,
L. Hu, Q. Li, A. Xie, N. Jiang, I. Stoica, H. Jin, and H. Zhang, “Gamearena: Evaluating llm reasoning through live computer games,” 2025. [Online]. Available: https: //arxiv.org/abs/2412.06394
arXiv 2025
-
[38]
Baba is ai: Break the rules to beat the benchmark,
N. Cloos, M. Jens, M. Naim, Y.-L. Kuo, I. Cases, A. Barbu, and C. J. Cueva, “Baba is ai: Break the rules to beat the benchmark,”
-
[39]
Available: https://arxiv.org/abs/2407.13729
[Online]. Available: https://arxiv.org/abs/2407.13729
-
[40]
Gamebench: Evaluating strategic reasoning abilities of llm agents,
A. Costarelli, M. Allen, R. Hauksson, G. Sodunke, S. Hariharan, C. Cheng, W. Li, J. Clymer, and A. Yadav, “Gamebench: Evaluating strategic reasoning abilities of llm agents,” 2024. [Online]. Available: https://arxiv.org/abs/2406.06613
arXiv 2024
-
[41]
Toolllm: Facilitating large language models to master 16000+ real-world apis,
Y. Qin, S. Liang, Y. Ye, K. Zhu, L. Yan, Y. Lu, Y. Lin, X. Cong, X. Tang, B. Qian, S. Zhao, L. Hong, R. Tian, R. Xie, J. Zhou, M. Gerstein, D. Li, Z. Liu, and M. Sun, “Toolllm: Facilitating large language models to master 16000+ real-world apis,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7- 11, 202...
2024
-
[42]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
S. Yao, N. Shinn, P . Razavi, and K. Narasimhan, “τ-bench: A benchmark for tool-agent-user interaction in real-world domains,”CoRR, vol. abs/2406.12045, 2024. [Online]. Available: https://doi.org/10.48550/arXiv.2406.12045
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.12045 2024
-
[43]
Api-bank: A comprehensive benchmark for tool-augmented llms,
M. Li, Y. Zhao, B. Yu, F. Song, H. Li, H. Yu, Z. Li, F. Huang, and Y. Li, “Api-bank: A comprehensive benchmark for tool-augmented llms,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Association for Computational Linguistics, 2023...
2023
-
[44]
Program synthesis with large language models,
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Do- han, E. Jiang, C. Cai, M. Terry, Q. Leet al., “Program synthesis with large language models,”arXiv preprint arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[45]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, J. Y. Shin, T. Walshe, E. K. Buchanan, J. Shen, G. Ye, H. Lin, J. Poulos, M. Wang, M. Nezhurina, J. Jitsev, D. Lu, O. Menis-Mastromichalakis, Z. Xu, Z. Chen, Y. Liu, R. Zhang, L. L. Chen, A. Kashyap, J. Uslu, J. Li, J. Wu, M. Yan, S. Bian, V . Sharma, K. Sun, S. Dillmann, A. Anand...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2601.11868 2026
-
[46]
Kernelbench: Can llms write efficient gpu kernels?
A. Ouyang, S. Guo, S. Arora, A. L. Zhang, W. Hu, C. Ré, and A. Mirhoseini, “Kernelbench: Can llms write efficient gpu kernels?”arXiv preprint arXiv:2502.10517, 2025
Pith/arXiv arXiv 2025
-
[47]
Medagentbench: Dataset for benchmarking llms as agents in medical applications,
Y. Jiang, K. C. Black, G. Geng, D. Park, A. Y. Ng, and J. H. Chen, “Medagentbench: Dataset for benchmarking llms as agents in medical applications,”CoRR, vol. abs/2501.14654, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2501.14654
-
[48]
Scienceagentbench: Toward rigorous assessment of language agents for data-driven scientific discovery,
Z. Chen, S. Chen, Y. Ning, Q. Zhang, B. Wang, B. Yu, Y. Li, Z. Liao, C. Wei, Z. Lu, V . Dey, M. Xue, F. N. Baker, B. Burns, D. Adu- Ampratwum, X. Huang, X. Ning, S. Gao, Y. Su, and H. Sun, “Scienceagentbench: Toward rigorous assessment of language agents for data-driven scientific discovery,” inThe Thirteenth International Conference on Learning Represent...
2025
-
[49]
Dsbench: How far are data science agents from becoming data science experts?
L. Jing, Z. Huang, X. Wang, W. Yao, W. Yu, K. Ma, H. Zhang, X. Du, and D. Yu, “Dsbench: How far are data science agents from becoming data science experts?” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. [Online]. Available: https://openreview.net/forum?id=DSsSPr0RZJ
2025
-
[50]
G. Brockman, V . Cheung, L. Pettersson, J. Schneider, J. Schul- man, J. Tang, and W. Zaremba, “Openai gym,”arXiv preprint arXiv:1606.01540, 2016
Pith/arXiv arXiv 2016
-
[51]
Agentbench: Evaluating llms as agents,
X. Liu, H. Yu, H. Zhang, Y. Xu, X. Lei, H. Lai, Y. Gu, H. Ding, K. Men, K. Yang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T. Zhang, Y. Su, H. Sun, M. Huang, Y. Dong, and J. Tang, “Agentbench: Evaluating llms as agents,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.n...
2024
-
[52]
Agentscourt: Building judicial decision-making agents with court debate simulation and legal knowledge augmenta- tion,
Z. He, P . Cao, C. Wang, Z. Jin, Y. Chen, J. Xu, H. Li, K. Liu, and J. Zhao, “Agentscourt: Building judicial decision-making agents with court debate simulation and legal knowledge augmenta- tion,” inFindings of the Association for Computational Linguistics: EMNLP 2024, 2024, pp. 9399–9416
2024
-
[53]
Mmr-v: What’s left unsaid? a benchmark for multi- modal deep reasoning in videos,
K. Zhu, Z. Jin, H. Yuan, J. Li, S. Tu, P . Cao, Y. Chen, K. Liu, and J. Zhao, “Mmr-v: What’s left unsaid? a benchmark for multi- modal deep reasoning in videos,”arXiv preprint arXiv:2506.04141, 2025
arXiv 2025
-
[54]
Mmr-life: Piecing together real-life scenes for multi- modal multi-image reasoning,
J. Li, S. Huang, Z. Jin, C. Zhang, P . Cao, Y. Chen, K. Liu, and J. Zhao, “Mmr-life: Piecing together real-life scenes for multi- modal multi-image reasoning,”arXiv preprint arXiv:2603.02024, 2026
arXiv 2026
-
[55]
Windows agent arena: Evaluating multi-modal os agents at scale,
R. Bonatti, D. Zhao, F. Bonacci, D. Dupont, S. Abdali, Y. Li, Y. Lu, J. Wagle, K. Koishida, A. Buckeret al., “Windows agent arena: Evaluating multi-modal os agents at scale,”arXiv preprint arXiv:2409.08264, 2024. JOURNAL OF LATEX CLASS FILES, JANUARY 2025 45
arXiv 2024
-
[56]
Osworld-mcp: Benchmarking MCP tool invocation in computer-use agents,
H. Jia, J. Liao, X. Zhang, H. Xu, T. Xie, C. Jiang, M. Yan, S. Liu, W. Ye, and F. Huang, “Osworld-mcp: Benchmarking MCP tool invocation in computer-use agents,” CoRR, vol. abs/2510.24563, 2025. [Online]. Available: https: //doi.org/10.48550/arXiv.2510.24563
-
[57]
Mobile-env: Building qualified evaluation benchmarks for llm-gui interaction,
D. Zhang, Z. Shen, R. Xie, S. Zhang, T. Xie, Z. Zhao, S. Chen, L. Chen, H. Xu, R. Caoet al., “Mobile-env: Building qualified evaluation benchmarks for llm-gui interaction,”arXiv preprint arXiv:2305.08144, 2023
arXiv 2023
-
[58]
Android in the wild: A large-scale dataset for android device control,
C. Rawles, A. Li, D. Rodriguez, O. Riva, and T. P . Lillicrap, “Android in the wild: A large-scale dataset for android device control,”CoRR, vol. abs/2307.10088, 2023. [Online]. Available: https://doi.org/10.48550/arXiv.2307.10088
-
[59]
Androidworld: A dynamic benchmarking environment for autonomous agents,
C. Rawles, S. Clinckemaillie, Y. Chang, J. Waltz, G. Lau, M. Fair, A. Li, W. E. Bishop, W. Li, F. Campbell-Ajala, D. K. Toyama, R. J. Berry, D. Tyamagundlu, T. P . Lillicrap, and O. Riva, “Androidworld: A dynamic benchmarking environment for autonomous agents,” inThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, Ap...
2025
-
[60]
Q. Kong, X. Zhang, Z. Yang, N. Gao, C. Liu, P . Tong, C. Cai, H. Zhou, J. Zhang, L. Chen, Z. Liu, S. Hoi, and Y. Wang, “Mobileworld: Benchmarking autonomous mobile agents in agent-user interactive and mcp-augmented environments,”CoRR, vol. abs/2512.19432, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2512.19432
-
[61]
Mobile-bench: An evaluation benchmark for llm-based mobile agents,
S. Deng, W. Xu, H. Sun, W. Liu, T. Tan, L. Liujianfeng, A. Li, J. Luan, B. Wang, R. Yanet al., “Mobile-bench: An evaluation benchmark for llm-based mobile agents,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 8813–8831
2024
-
[62]
Mind2web: Towards a generalist agent for the web,
X. Deng, Y. Gu, B. Zheng, S. Chen, S. Stevens, B. Wang, H. Sun, and Y. Su, “Mind2web: Towards a generalist agent for the web,” inAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Ha...
2023
-
[63]
Webarena: A realistic web environment for building autonomous agents,
S. Zhou, F. F. Xu, H. Zhu, X. Zhou, R. Lo, A. Sridhar, X. Cheng, T. Ou, Y. Bisk, D. Fried, U. Alon, and G. Neubig, “Webarena: A realistic web environment for building autonomous agents,” inThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net,
2024
-
[64]
Available: https://openreview.net/forum?id= oKn9c6ytLx
[Online]. Available: https://openreview.net/forum?id= oKn9c6ytLx
-
[65]
J. Y. Koh, R. Lo, L. Jang, V . Duvvur, M. C. Lim, P . Huang, G. Neubig, S. Zhou, R. Salakhutdinov, and D. Fried, “Visualwebarena: Evaluating multimodal agents on realistic visual web tasks,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, L....
-
[66]
Widesearch: Benchmarking agentic broad info- seeking,
R. Wong, J. Wang, J. Zhao, L. Chen, Y. Gao, L. Zhang, X. Zhou, Z. Wang, K. Xiang, G. Zhang, W. Huang, Y. Wang, and K. Wang, “Widesearch: Benchmarking agentic broad info- seeking,”CoRR, vol. abs/2508.07999, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2508.07999
-
[67]
Infodeepseek: Benchmarking agentic information seeking for retrieval- augmented generation,
Y. Xi, J. Lin, M. Zhu, Y. Xiao, Z. Ou, J. Liu, T. Wan, B. Chen, W. Liu, Y. Wang, R. Tang, W. Zhang, and Y. Yu, “Infodeepseek: Benchmarking agentic information seeking for retrieval- augmented generation,”CoRR, vol. abs/2505.15872, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2505.15872
-
[68]
Open data synthesis for deep research,
Z. Xia, K. Luo, H. Qian, and Z. Liu, “Open data synthesis for deep research,”CoRR, vol. abs/2509.00375, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2509.00375
-
[69]
Mmdeepresearch-bench: A benchmark for multimodal deep research agents,
P . Huang, Z. Zhong, Z. Wan, D. Zhou, S. Alam, X. Wang, Z. Li, Z. Dou, L. Zhu, J. Xiong, C. Tao, Y. Xu, D. Dimitriadis, T. Zhang, and M. Zhang, “Mmdeepresearch-bench: A benchmark for multimodal deep research agents,”CoRR, vol. abs/2601.12346,
-
[70]
arXiv preprint arXiv:2601.22259 (2026).https://doi.org/10.48550/arXiv.2601
[Online]. Available: https://doi.org/10.48550/arXiv.2601. 12346
-
[71]
Webwalker: Benchmarking llms in web traversal,
J. Wu, W. Yin, Y. Jiang, Z. Wang, Z. Xi, R. Fang, L. Zhang, Y. He, D. Zhou, P . Xie, and F. Huang, “Webwalker: Benchmarking llms in web traversal,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August 1, 2025, W. Che, J. Nabende, E. Shutova, and M. T....
2025
-
[72]
Dragged into conflicts: Detecting and addressing conflicting sources in search-augmented llms,
A. Cattan, A. Jacovi, O. Ram, J. Herzig, R. Aharoni, S. Goldshtein, E. Ofek, I. Szpektor, and A. Caciularu, “Dragged into conflicts: Detecting and addressing conflicting sources in search-augmented llms,”CoRR, vol. abs/2506.08500, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2506.08500
-
[73]
BrowseComp-ZH: Benchmarking Web Browsing Ability of Large Language Models in Chinese
P . Zhou, B. Leon, X. Ying, C. Zhang, Y. Shao, Q. Ye, D. Chong, Z. Jin, C. Xie, M. Cao, Y. Gu, S. Hong, J. Ren, J. Chen, C. Liu, and Y. Hua, “Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese,”CoRR, vol. abs/2504.19314, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2504.19314
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.19314 2025
-
[74]
Characterizing deep research: A benchmark and formal definition,
A. Java, A. Khandelwal, S. P . Midigeshi, A. Halfaker, A. Deshpande, N. Goyal, A. Gupta, N. Natarajan, and A. Sharma, “Characterizing deep research: A benchmark and formal definition,”CoRR, vol. abs/2508.04183, 2025. [Online]. Available: https://doi.org/10.48550/arXiv.2508.04183
-
[75]
Omnigaia: Towards native omni-modal AI agents,
X. Li, W. Jiao, J. Jin, S. Wang, G. Dong, J. Jin, H. Wang, Y. Wang, J. Wen, Y. Lu, and Z. Dou, “Omnigaia: Towards native omni-modal AI agents,”CoRR, vol. abs/2602.22897, 2026. [Online]. Available: https://doi.org/10.48550/arXiv.2602.22897
-
[76]
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
M. Du, B. Xu, C. Zhu, X. Wang, and Z. Mao, “Deepresearch bench: A comprehensive benchmark for deep research agents,” CoRR, vol. abs/2506.11763, 2025. [Online]. Available: https: //doi.org/10.48550/arXiv.2506.11763
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.11763 2025
-
[77]
Z. Yang, B. Pan, H. Wang, Y. Wang, X. Liu, M. Zhu, B. Zhang, and W. Chen, “Multimodal deepresearcher: Generating text-chart interleaved reports from scratch with agentic framework,” CoRR, vol. abs/2506.02454, 2025. [Online]. Available: https: //doi.org/10.48550/arXiv.2506.02454
-
[78]
Dr. bench: A multidimensional evaluation for deep research agents, from answers to reports,
Y. Yao, Y. Wang, Y. Zhang, Y. Lu, T. Gu, L. Li, D. Zhao, K. Wu, H. Wang, P . Nie, Y. Teng, and Y. Wang, “Dr. bench: A multidimensional evaluation for deep research agents, from answers to reports,” 2026. [Online]. Available: https://arxiv.org/abs/2510.02190
arXiv 2026
-
[79]
Surveygen: Quality-aware scientific survey generation with large language models,
T. Bao, M. T. Nayeem, D. Rafiei, and C. Zhang, “Surveygen: Quality-aware scientific survey generation with large language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, C. Christodoulopoulos, T. Chakraborty, C. Rose, and V . Peng, Eds. Association for Comput...
-
[80]
Reportbench: Evaluating deep research agents via academic survey tasks,
M. Li, Y. Zeng, Z. Cheng, C. Ma, and K. Jia, “Reportbench: Evaluating deep research agents via academic survey tasks,” CoRR, vol. abs/2508.15804, 2025. [Online]. Available: https: //doi.org/10.48550/arXiv.2508.15804
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.