Assessing Student Ability to Select an Algorithmic Paradigm
Pith reviewed 2026-06-30 22:55 UTC · model grok-4.3
The pith
A multiple-choice test can assess students' skill at choosing the right algorithm design paradigm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
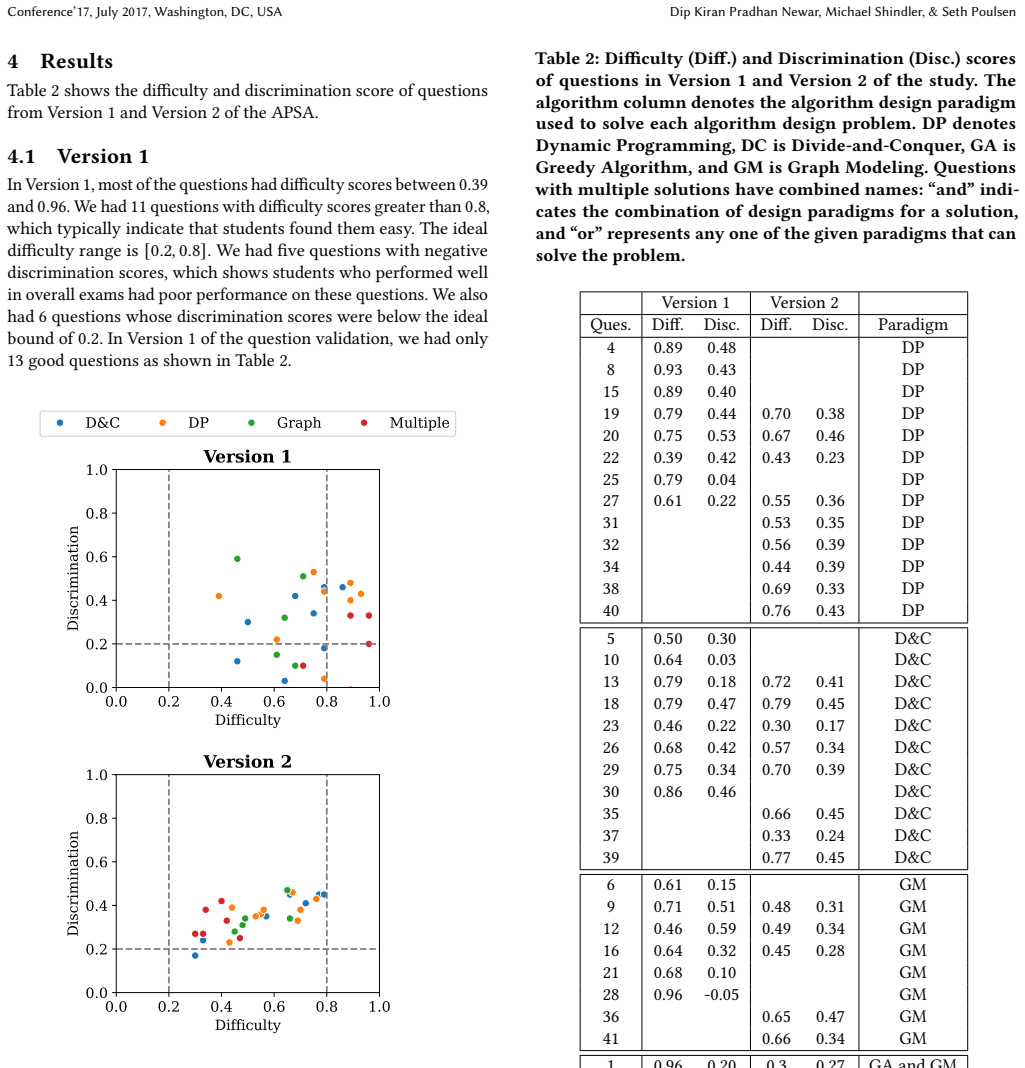
The central claim is that a set of multiple-choice questions can serve as a reliable instrument, called APSA, for assessing students' ability to select among algorithm design paradigms, with the test achieving an internal consistency of 0.73 and thereby offering a practical, standardized alternative to free-response methods for evaluating teaching interventions.
What carries the argument
The Algorithmic Paradigm Selection Assessment (APSA), a collection of multiple-choice questions that require students to identify the appropriate paradigm for sample problems.
If this is right
- APSA supplies a standardized instrument that different institutions can administer to compare student performance.
- Instructors and researchers can use APSA to measure whether a given teaching intervention improves students' paradigm selection ability.
- The test reduces reliance on time-intensive free-response grading or interviews when studying algorithmic thinking.
- APSA supports repeated testing across courses to track changes in student knowledge over time.
Where Pith is reading between the lines
- Further studies could check whether APSA scores predict success on programming assignments that require choosing a paradigm.
- The same question format might be extended to diagnose specific misconceptions, such as confusing greedy and dynamic programming choices.
- Widespread adoption could reveal institutional differences in how early students encounter paradigm selection.
Load-bearing premise
Multiple-choice questions can validly capture the reasoning process students use when deciding which algorithmic paradigm fits a problem.
What would settle it
If scores on APSA show little or no correlation with performance on free-response questions that ask students to select and justify a paradigm for the same problems, the multiple-choice format would fail to measure the intended skill.
Figures

read the original abstract
Computer science students are expected to be able to look at a problem and select an appropriate algorithm design paradigm to use to produce a solution. However, there is little research on how students determine which algorithmic paradigm to use. Historically, researchers have relied on free-response questions or interviews to assess students' knowledge of algorithmic paradigm selection. To successfully evaluate and scale teaching interventions for selecting an algorithmic design paradigm, we need to efficiently test a student's ability to select among different design paradigms. Here, we present the first attempts to assess student knowledge to select an algorithm design paradigm using multiple-choice questions. We present the construction of the \textit{algorithmic paradigm selection assessment} (APSA) and preliminary data demonstrating its effectiveness as an assessment. We discuss the key points we learned during this process to write multiple-choice questions for Algorithm Design Paradigms. We tested the internal consistency of our assessment using Cronbach's $\alpha$ and obtained a score of $0.73$, which is above the required threshold of $0.7$. APSA can be used across institutions as a standardized way to assess students' ability to select different algorithm design paradigms. APSA will assist researchers in evaluating whether a theory helps students improve their knowledge of different Algorithm Design Paradigms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Algorithmic Paradigm Selection Assessment (APSA), a multiple-choice question instrument for evaluating computer science students' ability to select appropriate algorithm design paradigms. It describes the construction of APSA, reports preliminary data with an internal consistency of Cronbach's α = 0.73 (above the 0.7 threshold), and discusses lessons for writing such MCQs. The authors position APSA as a standardized, scalable tool across institutions to assess paradigm selection and evaluate teaching interventions, contrasting it with prior reliance on free-response questions or interviews.
Significance. If the instrument's validity can be established beyond internal consistency, this would provide the first MCQ-based standardized assessment for a key algorithmic skill, enabling efficient evaluation and scaling of teaching interventions in CS education. The reported α meets common reliability thresholds and supports the preliminary framing, but the work's impact hinges on addressing the gap between MCQ format and the historically complex cognitive task.
major comments (2)
- [Abstract] Abstract: The claim that preliminary data demonstrate 'effectiveness' rests solely on Cronbach's α = 0.73 meeting the 0.7 threshold, but no sample size, participant details, question validation process, or comparison to external criteria (e.g., free-response performance) is provided; this information is load-bearing for the effectiveness and standardization claims.
- [Abstract] Abstract: The central claim that APSA validly measures paradigm selection via MCQs is not supported by any discussion of how the questions were constructed to capture the targeted cognitive skill (as opposed to surface-level pattern matching), leaving the move from internal consistency to a usable assessment instrument incomplete.
Simulated Author's Rebuttal
We thank the referee for their detailed review and constructive feedback on our preliminary work introducing the APSA instrument. We address each major comment below, indicating revisions where appropriate to clarify the scope and limitations of this initial validation effort.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that preliminary data demonstrate 'effectiveness' rests solely on Cronbach's α = 0.73 meeting the 0.7 threshold, but no sample size, participant details, question validation process, or comparison to external criteria (e.g., free-response performance) is provided; this information is load-bearing for the effectiveness and standardization claims.
Authors: We agree the abstract's brevity omits key supporting details. The full manuscript reports the sample size, participant demographics, and question development process. As this study is explicitly preliminary and focuses on internal consistency as an initial reliability check, external criterion comparisons (such as free-response performance) were not conducted. We will revise the abstract to include sample size and participant details, clarify the preliminary framing of 'effectiveness,' and moderate claims regarding standardization and broad usability pending further validation. revision: yes
-
Referee: [Abstract] Abstract: The central claim that APSA validly measures paradigm selection via MCQs is not supported by any discussion of how the questions were constructed to capture the targeted cognitive skill (as opposed to surface-level pattern matching), leaving the move from internal consistency to a usable assessment instrument incomplete.
Authors: The manuscript includes a dedicated section on APSA construction and lessons learned for authoring MCQs on algorithmic paradigms. However, we acknowledge that this section could more explicitly articulate how items were designed to probe the cognitive process of paradigm selection rather than surface-level cues. We will expand the discussion of item construction in the revised manuscript to better address this distinction and support the validity argument. revision: yes
Circularity Check
No circularity; standard external reliability threshold applied to assessment data
full rationale
The paper constructs the APSA instrument and reports its internal consistency via Cronbach's α = 0.73 (exceeding the conventional external threshold of 0.7). This is a direct statistical computation on collected student responses, not a derived prediction or result obtained by fitting parameters to the target quantity itself. No equations, self-citations, uniqueness theorems, or ansatzes appear as load-bearing steps; the manuscript explicitly frames its contribution as preliminary construction rather than a closed derivation. The central claim therefore remains independent of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math A Cronbach's alpha value of 0.7 or higher indicates acceptable internal consistency for an assessment instrument.
Reference graph
Works this paper leans on
-
[1]
Murtaza Ali, Sourojit Ghosh, Prerna Rao, Raveena Dhegaskar, Sophia Jawort, Alix Medler, Mengqi Shi, and Sayamindu Dasgupta. 2023. Taking Stock of Con- cept Inventories in Computing Education: A Systematic Literature Review. In Proceedings of the 2023 ACM Conference on International Computing Education Research - Volume 1(Chicago, IL, USA)(ICER ’23). Assoc...
-
[2]
Michal Armoni. 2009. Reduction in CS: A (mostly) quantitative analysis of reductive solutions to algorithmic problems.Journal on Educational Resources in Computing (JERIC)8, 4 (2009), 1–30
2009
-
[3]
Hongxuan Chen, Katherine Braught, Geoffrey L. Herman, and Jeff Erickson. 2025. Novice Difficulties in Graph Layering for Algorithm Design. InProceedings of the 56th ACM Technical Symposium on Computer Science Education V. 2(Pittsburgh, PA, USA)(SIGCSETS 2025). Association for Computing Machinery, New York, NY, USA, 1415–1416. doi:10.1145/3641555.3705221
-
[4]
Thomas H Cormen, Charles E Leiserson, Ronald L Rivest, and Clifford Stein. 2022. Introduction to algorithms. MIT press
2022
-
[5]
Lee J Cronbach. 1951. Coefficient alpha and the internal structure of tests. psychometrika16, 3 (1951), 297–334
1951
-
[6]
Holger Danielsiek, Laura Toma, and Jan Vahrenhold. 2017. An Instrument to Assess Self-Efficacy in Introductory Algorithms Courses. InProceedings of the 2017 ACM Conference on International Computing Education Research, ICER 2017, Josh Tenenberg, Donald Chinn, Judy Sheard, and Lauri Malmi (Eds.). ACM Press, New York, NY, 257–265. doi:10.1145/3105726.3106171
-
[7]
Adrienne Decker and Monica M. McGill. 2019. A topical review of evaluation instruments for computing education. InProceedings of the 50th ACM Technical Symposium on Computer Science Education(Minneapolis, MN, USA)(SIGCSE ’19). Association for Computing Machinery, New York, NY, USA, 558–564. doi:10. 1145/3287324.3287393
arXiv 2019
-
[8]
Robert F DeVellis. 2006. Classical test theory.Medical care44, 11 (2006), S50–S59
2006
-
[9]
most difficult
Emma Enström and Viggo Kann. 2017. Iteratively intervening with the “most difficult” topics of an algorithms and complexity course.ACM Transactions on Computing Education (TOCE)17, 1 (2017), 1–38
2017
-
[10]
2023.Algorithms
Jeff Erickson. 2023.Algorithms
2023
-
[11]
Xitao Fan. 1998. Item response theory and classical test theory: An empiri- cal comparison of their item/person statistics.Educational and psychological measurement58, 3 (1998), 357–381
1998
-
[12]
Farghally, Kyu Han Koh, Jeremy V
Mohammed F. Farghally, Kyu Han Koh, Jeremy V. Ernst, and Clifford A. Shaffer
-
[13]
Towards a Concept Inventory for Algorithm Analysis Topics. InProceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education (Seattle, Washington, USA)(SIGCSE ’17). Association for Computing Machinery, New York, NY, USA, 207–212. doi:10.1145/3017680.3017756
-
[14]
Matthew Ferland, Varun Nagaraj Rao, Arushi Arora, Drew van der Poel, Michael Luu, Randy Huynh, Frederick Reiber, Sandra Ossman, Seth Poulsen, and Michael Shindler. 2025. Construction and Preliminary Validation of a Dynamic Program- ming Concept Inventory. InProceedings of the 56th ACM Technical Symposium on Computer Science Education V. 1. 325–331
2025
-
[15]
GeeksforGeeks. [n. d.].GeeksforGeeks. https://www.geeksforgeeks.org/
-
[16]
David Ginat. 2003. The greedy trap and learning from mistakes.SIGCSE Bull.35, 1 (Jan. 2003), 11–15. doi:10.1145/792548.611920
-
[17]
David Ginat. 2004. Do senior CS students capitalize on recursion?ACM SIGCSE Bulletin36, 3 (2004), 82–86
2004
-
[18]
2018.Competitive programming 4: The new lower bound of programming contests in the 2020s
Steven Halim, Felix Halim, and Suhendry Effendy. 2018.Competitive programming 4: The new lower bound of programming contests in the 2020s. Lulu. com
2018
-
[19]
2013.Computer Science Curricula 2013: Curriculum Guidelines for Undergraduate Degree Programs in Computer Science
Association for Computing Machinery (ACM) Joint Task Force on Comput- ing Curricula and IEEE Computer Society. 2013.Computer Science Curricula 2013: Curriculum Guidelines for Undergraduate Degree Programs in Computer Science. Association for Computing Machinery, New York, NY, USA
2013
-
[20]
Natalie Jorion, Brian D Gane, Katie James, Lianne Schroeder, Louis V DiBello, and James W Pellegrino. 2015. An analytic framework for evaluating the validity of concept inventory claims.Journal of Engineering Education104, 4 (2015), 454–496
2015
-
[21]
Amruth N Kumar and Rajendra K Raj. 2024. Computer Science Curricula 2023 (CS2023): The Final Report. InProceedings of the 55th ACM Technical Symposium on Computer Science Education V. 2. 1867–1868
2024
-
[22]
2016.Cracking the Coding Interview: 189 Program- ming Questions and Solutions
Gayle Laakmann McDowell. 2016.Cracking the Coding Interview: 189 Program- ming Questions and Solutions. CareerCup
2016
-
[23]
LeetCode. [n. d.].LeetCode. https://leetcode.com/
-
[24]
Jonathan Liu, Erica Goodwin, and Diana Franklin. 2025. Student Utilization of Metacognitive Strategies in Solving Dynamic Programming Problems. In Proceedings of the 56th ACM Technical Symposium on Computer Science Education V. 1. 687–693
2025
-
[25]
Jonathan Liu, Erica Goodwin, and Diana Franklin. 2025. Student Utilization of Metacognitive Strategies in Solving Dynamic Programming Problems. In Proceedings of the 56th ACM Technical Symposium on Computer Science Education V. 1(Pittsburgh, PA, USA)(SIGCSETS 2025). Association for Computing Machinery, New York, NY, USA, 687–693. doi:10.1145/3641554.3701888
-
[26]
Michael Luu, Matthew Ferland, Varun Nagaraj Rao, Arushi Arora, Randy Huynh, Frederick Reiber, Jennifer Wong-Ma, and Michael Shindler. 2023. What is an algo- rithms course? Survey results of introductory undergraduate algorithms courses in the US. InProceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1. 284–290
2023
-
[27]
Lauren Margulieux, Tuba Ayer Ketenci, and Adrienne Decker. 2019. Re- view of measurements used in computing education research and sugges- tions for increasing standardization.Computer Science Education29, 1 (Jan. 2019), 49–78. doi:10.1080/08993408.2018.1562145 Publisher: Routledge _eprint: https://doi.org/10.1080/08993408.2018.1562145
-
[28]
Spencer Offenberger, Geoffrey L Herman, Peter Peterson, Alan T Sherman, Enis Golaszewski, Travis Scheponik, and Linda Oliva. 2019. Initial validation of the cybersecurity concept inventory: pilot testing and expert review. In2019 IEEE Frontiers in Education Conference (FIE). IEEE, 1–9
2019
-
[29]
Dip Kiran Pradhan Newar, Peter Fowles, and Seth Poulsen. 2026. How do Students Select an Algorithm Design Technique?. InProceedings of the 28th Australasian Computing Education Conference. 76–84
2026
-
[30]
2011.Algorithms
Robert Sedgewick and Kevin Wayne. 2011.Algorithms. Addison-wesley profes- sional
2011
-
[31]
Michael Shindler, Natalia Pinpin, Mia Markovic, Frederick Reiber, Jee Hoon Kim, Giles Pierre Nunez Carlos, Mine Dogucu, Mark Hong, Michael Luu, Brian Anderson, et al . 2022. Student misconceptions of dynamic programming: a replication study.Computer Science Education32, 3 (2022), 288–312
2022
-
[32]
Matthew West, Geoffrey L Herman, and Craig Zilles. 2015. Prairielearn: Mastery- based online problem solving with adaptive scoring and recommendations driven by machine learning. In2015 ASEE Annual Conference & Exposition. 26–1238
2015
-
[33]
Shamama Zehra, Aishwarya Ramanathan, Larry Yueli Zhang, and Daniel Zingaro
-
[34]
InProceedings of the 49th ACM technical symposium on Computer Science Education
Student misconceptions of dynamic programming. InProceedings of the 49th ACM technical symposium on Computer Science Education. 556–561
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.