SemanticXR: Low Power and Real-time Queryable Semantic Mapping with an Object-Level Device-Cloud Architecture
Pith reviewed 2026-06-27 06:12 UTC · model grok-4.3
The pith
Elevating semantically identifiable objects to first-class units enables real-time open-vocabulary semantic mapping on XR devices with cloud offload.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
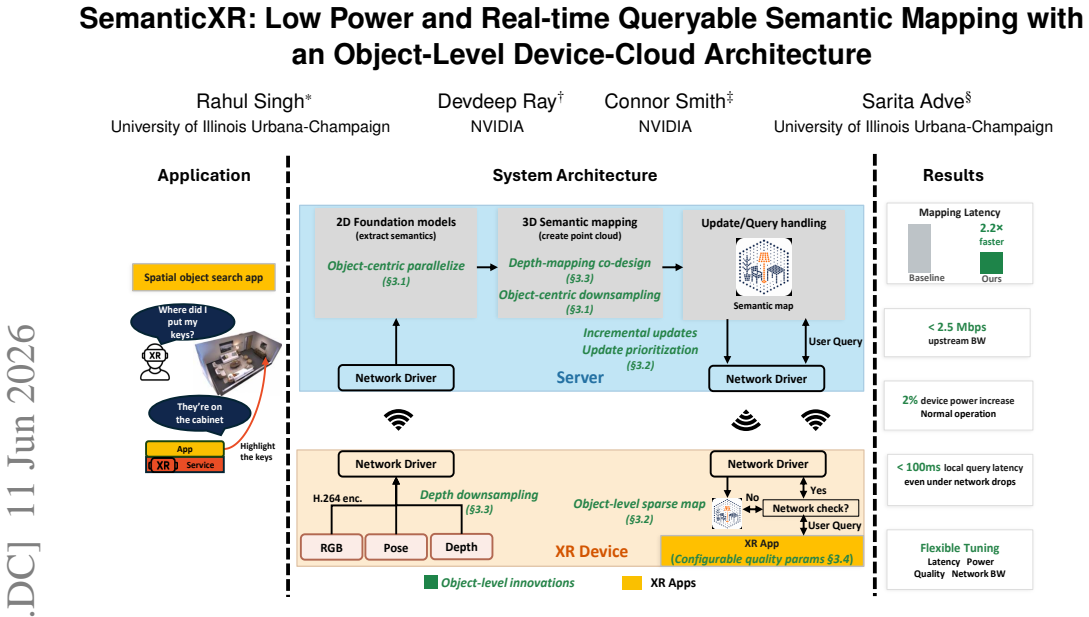
SemanticXR is presented as the first device-cloud system for real-time, open-vocabulary semantic mapping and querying under XR power, bandwidth, and memory constraints. By elevating semantically identifiable objects to first-class units of communication, execution, and memory across the device and server, object-level parallelism and geometry downsampling improve server mapping latency, depth-mapping co-design reduces upstream bandwidth, and an object-level sparse local map with incremental updates and prioritization enables network-robust querying with bounded memory and downstream bandwidth. Configurable resource-quality trade-offs allow adaptation to application needs and conditions. Agai
What carries the argument
Object-level organization that treats semantically identifiable objects as first-class units of communication, execution, and memory across the device-cloud boundary.
If this is right
- Server-side mapping latency improves by 2.2X at equal semantic quality through object-level parallelism and geometry downsampling.
- Upstream bandwidth remains under 2.5 Mbps via object-level depth-mapping co-design.
- Device query latency stays below 100 ms for up to 10,000 objects even during network drops due to the sparse local map and update prioritization.
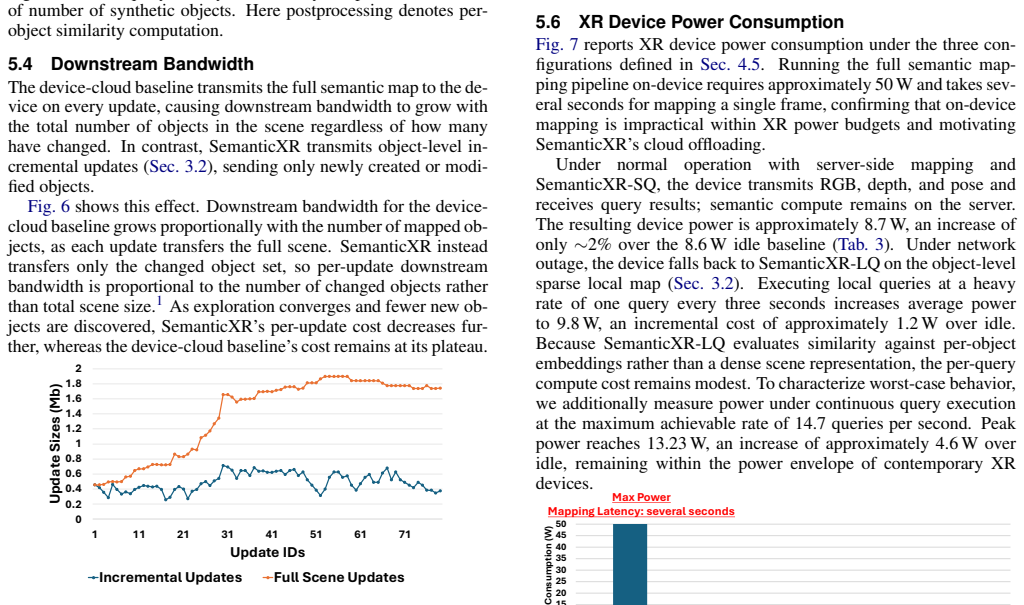
- The device supports tens of thousands of objects within 500 MB while scaling downstream bandwidth with map changes rather than total scene size.
- The system adds only 2% device power during normal operation through object-level sparse local map and configurable trade-offs.
Where Pith is reading between the lines
- The configurable resource-quality trade-offs could let applications tune mapping dynamically to battery state or network quality in untested operating regimes.
- Similar object-centric partitioning may reduce communication costs in other cloud-offloaded mobile perception tasks such as real-time scene understanding.
- Over longer sessions the bounded-memory design could allow persistent maps across multiple XR sessions without proportional growth in device storage.
Load-bearing premise
Treating semantically identifiable objects as first-class units will produce the stated latency, bandwidth, and memory gains without hidden accuracy costs or unaccounted overheads in the perception pipeline.
What would settle it
Running SemanticXR and the device-cloud baseline on the same XR device and server with a fixed scene containing several thousand objects, then measuring server mapping latency, upstream bandwidth, and device query latency under controlled network drops, would falsify the claims if the object-level version shows no improvement or exceeds the reported thresholds.
Figures



read the original abstract
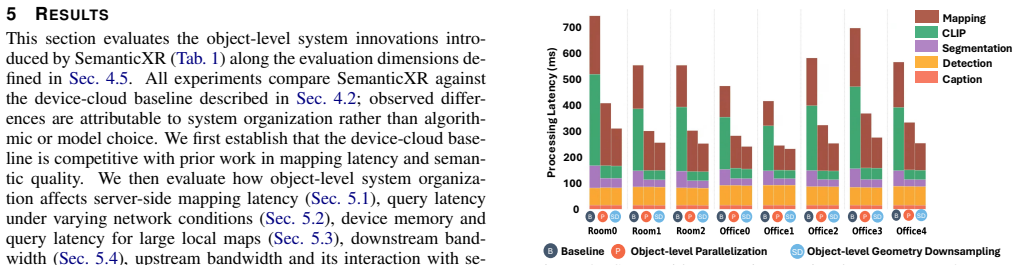
Semantic mapping is a core service that enables grounded interactions in emerging Extended Reality (XR) applications such as AI assistants and spatial object search. Deploying this capability on mobile XR devices requires a system that is open-vocabulary, real-time, and low-power. Existing approaches are compute-intensive and assume server-class resources. Cloud offloading offers a practical path, but no existing system splits semantic mapping across the device-cloud boundary or manages its communication, execution, and memory footprint. We present SemanticXR, the first device-cloud system for real-time, open-vocabulary semantic mapping and querying under XR power, bandwidth, and memory constraints. Our key insight is to elevate semantically identifiable objects to first-class units of communication, execution, and memory across the device and server. On the server, object-level parallelism and geometry downsampling improve mapping latency, while object-level depth-mapping co-design reduces upstream bandwidth. On the device, an object-level sparse local map with incremental updates and update prioritization enables network-robust querying with bounded memory and downstream bandwidth. Object-level configurable resource usage vs. quality trade-offs let applications and the system adapt mapping to application requirements and operating conditions, respectively. Against a device-cloud baseline with the same perception models, object-level organization improves server-side mapping latency by 2.2X at equal semantic quality. Depth-mapping co-design maintains upstream bandwidth under 2.5 Mbps. On the device, SemanticXR sustains sub-100 ms query latency for up to 10,000 objects even under network drops, supports tens of thousands of objects within 500 MB, and scales downstream bandwidth with map changes, not total scene size. The system adds only 2% device power during normal operation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
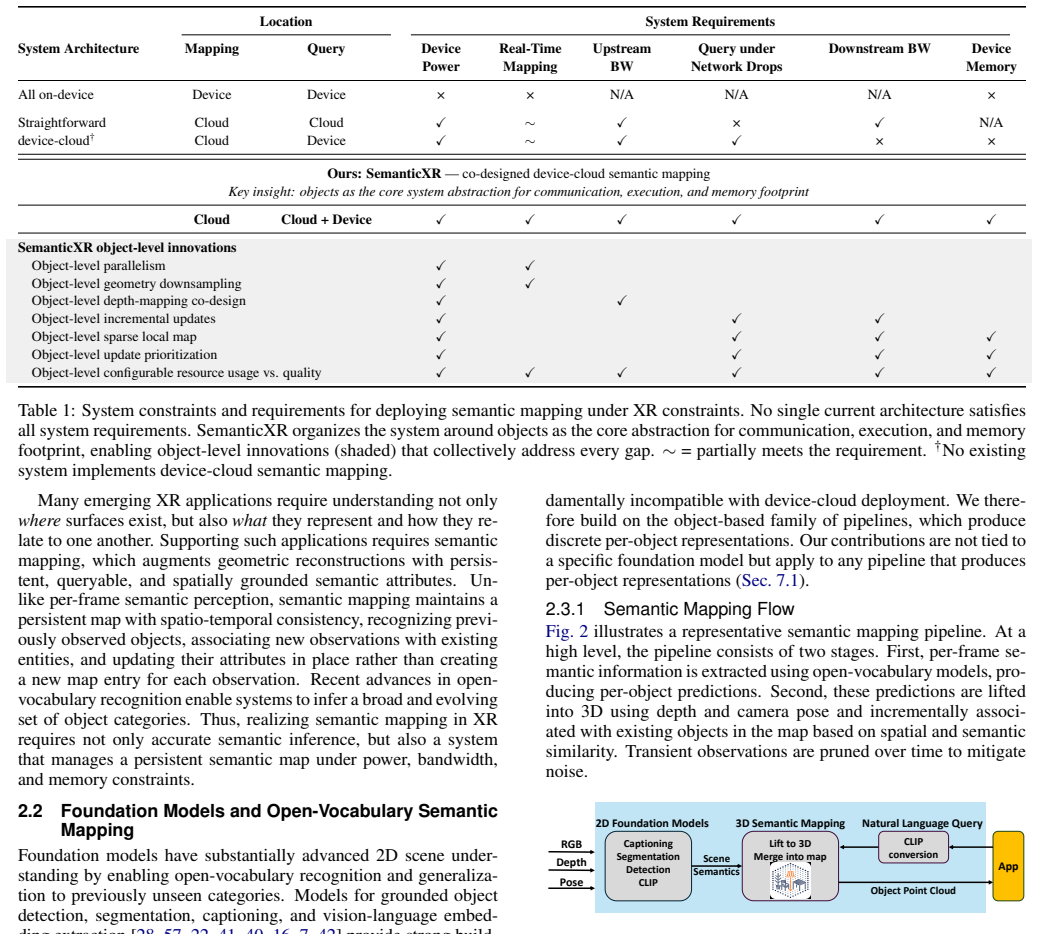
Summary. The manuscript presents SemanticXR, the first device-cloud system for real-time open-vocabulary semantic mapping and querying under XR constraints. The central contribution is elevating semantically identifiable objects to first-class units of communication, execution, and memory. This enables server-side object-level parallelism and geometry downsampling for mapping, depth-mapping co-design for bandwidth reduction, and device-side sparse local maps with incremental updates and prioritization for query robustness. Against a device-cloud baseline using identical perception models, the system reports 2.2X server-side mapping latency improvement at equal semantic quality, upstream bandwidth under 2.5 Mbps, sub-100 ms queries for 10k objects under network drops, support for tens of thousands of objects in 500 MB, and only 2% added device power.
Significance. If the quantitative results survive full-pipeline accounting, the work demonstrates a practical object-level split that could enable grounded XR interactions on mobile devices. The co-design of depth mapping, object association, and configurable quality trade-offs addresses real deployment constraints in bandwidth, power, and memory that prior cloud-offload approaches have not jointly solved.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: The 2.2X server-side mapping latency claim at equal semantic quality does not specify whether the baseline and proposed system both include the full costs of on-device object detection/segmentation, cross-frame association, merging logic, and depth co-design. If these steps are required for consistency in the object-level pipeline but are not charged to the baseline, the net gain may be overstated.
- [§5 (or equivalent results section)] §5 (or equivalent results section), latency and quality tables: The equal-semantic-quality condition is stated but the manuscript must report how quality is measured after all stages (including any accuracy impact from geometry downsampling or incremental updates) and provide error bars or multiple runs to support the 2.2X figure as load-bearing evidence.
minor comments (2)
- [Abstract] The abstract states specific numbers (2.2X, <2.5 Mbps, sub-100 ms, 2% power) without referencing the corresponding tables or figures; add explicit cross-references.
- [System Architecture section] Notation for object-level units (e.g., how objects are represented for communication vs. memory) should be introduced earlier and used consistently in the architecture diagrams.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on evaluation clarity. We address each major comment below and will revise the manuscript to strengthen the presentation of results.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The 2.2X server-side mapping latency claim at equal semantic quality does not specify whether the baseline and proposed system both include the full costs of on-device object detection/segmentation, cross-frame association, merging logic, and depth co-design. If these steps are required for consistency in the object-level pipeline but are not charged to the baseline, the net gain may be overstated.
Authors: The 2.2X improvement refers specifically to server-side mapping latency after data arrival from the device. Both systems employ identical perception models, so on-device object detection/segmentation, cross-frame association, and depth co-design incur the same costs and do not affect the server-side comparison. The baseline is a device-cloud system without object-level organization; the reported gain arises from server-side object-level parallelism and geometry downsampling. Merging logic is part of the server pipeline in both cases. To eliminate ambiguity we will expand the evaluation section with an explicit baseline description confirming consistent accounting of all stages. revision: yes
-
Referee: [§5 (or equivalent results section)] §5 (or equivalent results section), latency and quality tables: The equal-semantic-quality condition is stated but the manuscript must report how quality is measured after all stages (including any accuracy impact from geometry downsampling or incremental updates) and provide error bars or multiple runs to support the 2.2X figure as load-bearing evidence.
Authors: We agree that the quality metric and its post-processing impact require explicit reporting. Semantic quality is quantified via mean Intersection-over-Union (mIoU) computed on final object labels after geometry downsampling and incremental map updates. We will add this definition to the results section, include the measured mIoU values confirming equal quality between systems, and report error bars derived from multiple independent runs to substantiate the 2.2X latency figure. revision: yes
Circularity Check
No circularity: claims rest on measured system performance, not derivations or fitted predictions
full rationale
The paper is a systems contribution whose central claims (2.2X server-side latency improvement at equal semantic quality, bandwidth and memory bounds) are presented as empirical results from an implemented device-cloud prototype evaluated against a baseline using identical perception models. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided abstract or description. The object-level organization is an architectural choice whose benefits are quantified by direct measurement rather than reduced to inputs by construction. This is the expected outcome for a measurement-driven systems paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Elevating semantically identifiable objects to first-class units of communication, execution, and memory improves latency, bandwidth, and memory usage under XR constraints
Reference graph
Works this paper leans on
-
[1]
Apple iPad Pro, 2020
Apple Inc. Apple iPad Pro, 2020. Tablet device with LiDAR sensor. 9
2020
-
[2]
Apple ARKit, 2023
Apple Inc. Apple ARKit, 2023. Apple’s AR Developer tool. 9
2023
-
[3]
A. Behroozi, Y . Chen, V . Fruchter, L. Subramanian, S. Srikanth, and S. Mahlke. Slimslam: An adaptive runtime for visual-inertial simul- taneous localization and mapping. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 3, ASPLOS ’24, p. 900–915. Association for Comp...
-
[4]
F. L. Busch, T. Homberger, J. Ortega-Peimbert, Q. Yang, and O. An- dersson. One map to find them all: Real-time open-vocabulary map- ping for zero-shot multi-object navigation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pp. 14835–14842,
-
[5]
doi: 10.1109/ICRA55743.2025.11128393 2, 3, 9
-
[6]
G. Chen, F. H’acha, L. V’a ˇsa, and M. Dasari. Tvmc: Time- varying mesh compression using volume-tracked reference meshes. In Proceedings of the 16th ACM Multimedia Systems Conference, MM- Sys ’25, p. 79–89. Association for Computing Machinery, New York, NY , USA, 2025. doi: 10.1145/3712676.3714440 2
-
[7]
K. Chen, T. Li, H.-S. Kim, D. E. Culler, and R. H. Katz. Marvel: En- abling mobile augmented reality with low energy and low latency. In Proceedings of the 16th ACM Conference on Embedded Networked Sensor Systems, SenSys ’18, p. 292–304. Association for Comput- ing Machinery, New York, NY , USA, 2018. doi: 10.1145/3274783. 3274834 2, 10
-
[8]
Cherti, R
M. Cherti, R. Beaumont, R. Wightman, M. Wortsman, G. Ilharco, C. Gordon, C. Schuhmann, L. Schmidt, and J. Jitsev. Repro- ducible scaling laws for contrastive language-image learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2818–2829, 2023. 3
2023
-
[9]
A. Dhakal, X. Ran, Y . Wang, J. Chen, and K. K. Ramakrishnan. Slam- share: visual simultaneous localization and mapping for real-time multi-user augmented reality. In Proceedings of the 18th International Conference on Emerging Networking EXperiments and Technologies, CoNEXT ’22, p. 293–306. Association for Computing Machinery, New York, NY , USA, 2022. d...
-
[10]
S. Gao, J. Liu, Q. Jiang, F. Sinclair, W. Sentosa, B. Godfrey, and S. Adve. Xrgo: Design and evaluation of rendering offload for low- power extended reality devices. In Proceedings of the 16th ACM Multimedia Systems Conference, MMSys ’25, p. 124–135. Associ- ation for Computing Machinery, New York, NY , USA, 2025. doi: 10. 1145/3712676.3714444 2, 5, 10
arXiv 2025
-
[11]
Immersive stream for xr overview
Google. Immersive stream for xr overview. Streaming for extended reality. 2
-
[12]
Project astra, 2024
Google. Project astra, 2024. Google’s universal AR AI agent. 10
2024
-
[13]
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa, C. Gan, C. M. de Melo, J. B. Tenenbaum, A. Torralba, F. Shkurti, and L. Paull. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 5021–5...
-
[14]
Hughes, Y
N. Hughes, Y . Chang, and L. Carlone. Hydra: A real-time spatial perception system for 3D scene graph construction and optimization
-
[15]
N. Hughes, Y . Chang, S. Hu, R. Talak, R. Abdulhai, J. Strader, and L. Carlone. Foundations of spatial perception for robotics: Hierarchi- cal representations and real-time systems. The International Journal of Robotics Research, 2024. doi: 10.1177/02783649241229725 9
-
[16]
M. Huzaifa, R. Desai, S. Grayson, X. Jiang, Y . Jing, J. Lee, F. Lu, Y . Pang, J. Ravichandran, F. Sinclair, B. Tian, H. Yuan, J. Zhang, and S. V . Adve. Illixr: An open testbed to enable extended reality systems research. IEEE Micro, 42(4):97–106, 2022. doi: 10.1109/MM.2022. 3161018 5
-
[17]
In: Kim, B., Yue, Y., Chaudhuri, S., Fragkiadaki, K., Khan, M., Sun, Y
G. Ilharco, M. Wortsman, R. Wightman, C. Gordon, N. Carlini, R. Taori, A. Dave, V . Shankar, H. Namkoong, J. Miller, H. Hajishirzi, A. Farhadi, and L. Schmidt. Openclip, July 2021. If you use this software, please cite it as below. doi: 10.5281/zenodo.5143773 3
-
[18]
Jatavallabhula, A
K. Jatavallabhula, A. Kuwajerwala, Q. Gu, M. Omama, T. Chen, S. Li, G. Iyer, S. Saryazdi, N. Keetha, A. Tewari, J. Tenenbaum, C. de Melo, M. Krishna, L. Paull, F. Shkurti, and A. Torralba. Conceptfusion: Open-set multimodal 3d mapping. Robotics: Science and Systems (RSS), 2023. 2, 3, 5, 6, 7, 9
2023
-
[19]
Q. Jiang, Y . Pang, W. Sentosa, S. Gao, M. Huzaifa, J. Zhang, J. Perez- Ramirez, D. Das, D. Gonzalez-Aguirre, B. Godfrey, and S. Adve. Re- motevio: Offloading head tracking in an end-to-end xr system. In Proceedings of the 16th ACM Multimedia Systems Conference, MM- Sys ’25, p. 101–112. Association for Computing Machinery, New York, NY , USA, 2025. doi: 1...
-
[20]
T. Jin, M. Dasa, C. Smith, K. Apicharttrisorn, S. Seshan, and A. Rowe. Meshreduce: Scalable and bandwidth efficient 3d scene capture. In 2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR), pp. 20–30, 2024. doi: 10.1109/VR58804.2024.00026 2
-
[21]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimk ¨uhler, and G. Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 42(4), July 2023. 10
2023
-
[22]
J. Kerr, C. M. Kim, K. Goldberg, A. Kanazawa, and M. Tancik. Lerf: Language embedded radiance fields. In International Conference on Computer Vision (ICCV), 2023. 2, 10
2023
-
[23]
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, et al. Segment anything. arXiv preprint arXiv:2304.02643, 2023. 3
Pith/arXiv arXiv 2023
-
[24]
Z. J. Kong, Q. Xu, and Y . C. Hu. Arise: High-capacity ar offloading inference serving via proactive scheduling. InProceedings of the 22nd Annual International Conference on Mobile Systems, Applications and Services, MOBISYS ’24, p. 451–464. Association for Comput- ing Machinery, New York, NY , USA, 2024. doi: 10.1145/3643832. 3661894 2, 10
-
[25]
Z. J. Kong, Q. Xu, J. Meng, and Y . C. Hu. Accumo: Accuracy- centric multitask offloading in edge-assisted mobile augmented real- ity. In Proceedings of the 29th Annual International Conference on Mobile Computing and Networking, ACM MobiCom ’23. Associa- tion for Computing Machinery, New York, NY , USA, 2023. doi: 10. 1145/3570361.3592531 2, 10
arXiv 2023
-
[26]
Z. Lai, Y . C. Hu, Y . Cui, L. Sun, and N. Dai. Furion: Engineering high-quality immersive virtual reality on today’s mobile devices. In Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking, MobiCom ’17, p. 409–421. Association for Computing Machinery, New York, NY , USA, 2017. doi: 10.1145/ 3117811.3117815 10
arXiv 2017
-
[27]
M. Li, S. Liu, H. Zhou, G. Zhu, N. Cheng, T. Deng, and H. Wang. Sgs- slam: Semantic gaussian splatting for neural dense slam. p. 163–179. Springer-Verlag, Berlin, Heidelberg, 2024. doi: 10.1007/978-3-031 -72751-1 10 10
-
[28]
L. Liu, H. Li, and M. Gruteser. Edge assisted real-time object detec- tion for mobile augmented reality. In The 25th Annual International Conference on Mobile Computing and Networking, MobiCom ’19. Association for Computing Machinery, New York, NY , USA, 2019. doi: 10.1145/3300061.3300116 2, 10
-
[29]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499, 2023. 3, 5
Pith/arXiv arXiv 2023
-
[30]
E. Lu, S. Bharadwaj, M. Dasari, C. Smith, S. Seshan, and A. Rowe. Renderfusion: Balancing local and remote rendering for interactive 3d scenes. In 2023 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pp. 312–321, 2023. doi: 10.1109/ ISMAR59233.2023.00046 10
arXiv 2023
-
[31]
S. Lu, H. Chang, E. P. Jing, A. Boularias, and K. Bekris. Ovir-3d: Open-vocabulary 3d instance retrieval without training on 3d data. In 7th Annual Conference on Robot Learning, 2023. 2, 3, 10
2023
-
[32]
D. Maggio, Y . Chang, N. Hughes, M. Trang, D. Griffith, C. Dougherty, E. Cristofalo, L. Schmid, and L. Carlone. Clio: Real-time task-driven open-set 3d scene graphs. IEEE Robotics and Automation Letters, 9(10):8921–8928, 2024. doi: 10.1109/LRA.2024.3451395 2, 5, 6, 7, 9, 10
-
[33]
Y . Mao, J. Zhong, C. Fang, J. Zheng, R. Tang, H. Zhu, P. Tan, and Z. Zhou. Spatiallm: Training large language models for structured indoor modeling, 2025. 9
2025
-
[34]
Mildenhall, P
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoor- thi, and R. Ng. Nerf: representing scenes as neural radiance fields for view synthesis. Commun. ACM, 65(1):99–106, Dec. 2021. doi: 10. 1145/3503250 10
2021
-
[35]
Cloudxr, 2023
NVIDIA. Cloudxr, 2023. Streaming for extended reality. 2, 10
2023
-
[36]
tegrastats Utility.https://docs.nvidia.com/ drive/drive_os_5.1.6.1L/nvvib_docs/index.html#page/ DRIVE_OS_Linux_SDK_Development_Guide/Utilities/util_ tegrastats.html, 2024
NVIDIA. tegrastats Utility.https://docs.nvidia.com/ drive/drive_os_5.1.6.1L/nvvib_docs/index.html#page/ DRIVE_OS_Linux_SDK_Development_Guide/Utilities/util_ tegrastats.html, 2024. 6
2024
-
[37]
Y . Pang, S. Kondguli, S. Wang, and S. Adve. Ada: A distributed, power-aware, real-time scene provider for xr. IEEE Transactions on Visualization and Computer Graphics, 31(11):9677–9687, 2025. doi: 10.1109/TVCG.2025.3616835 2, 5, 8, 10
-
[38]
Z. Peng, T. Shao, L. Yong, J. Zhou, Y . Yang, J. Wang, and K. Zhou. Rtg-slam: Real-time 3d reconstruction at scale using gaussian splat- ting. 2024. 6
2024
-
[39]
Z. Peng, K. Zhou, and T. Shao. Gaussian-plus-sdf slam: High-fidelity 3d reconstruction at 150+ fps. Computational Visual Media, 2025. 6
2025
-
[40]
M. Qin, W. Li, J. Zhou, H. Wang, and H. Pfister. Langsplat: 3d lan- guage gaussian splatting. arXiv preprint arXiv:2312.16084, 2023. 2, 10
arXiv 2023
-
[41]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervi- sion, 2021. 3
2021
-
[42]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll ´ar, and C. Feichtenhofer. Sam 2: Segment anything in images and videos, 2024. 3
2024
-
[43]
Schuhmann, R
C. Schuhmann, R. Beaumont, R. Vencu, C. W. Gordon, R. Wight- man, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, P. Schramowski, S. R. Kundurthy, K. Crowson, L. Schmidt, R. Kacz- marczyk, and J. Jitsev. LAION-5b: An open large-scale dataset for training next generation image-text models. In Thirty-sixth Conference on Neural Information Processin...
2022
-
[44]
S. Shi, J. Cui, Z. Jiang, Z. Yan, G. Xing, J. Niu, and Z. Ouyang. Vips: real-time perception fusion for infrastructure-assisted autonomous driving. In Proceedings of the 28th Annual International Conference on Mobile Computing And Networking, MobiCom ’22, p. 133–146. Association for Computing Machinery, New York, NY , USA, 2022. doi: 10.1145/3495243.3560539 2, 10
-
[45]
S. Srinidhi, E. Lu, and A. Rowe. Xair: An xr platform that in- tegrates large language models with the physical world. In 2024 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), pp. 759–767, 2024. doi: 10.1109/ISMAR62088.2024. 00091 10
-
[46]
J. Straub, T. Whelan, L. Ma, Y . Chen, E. Wijmans, S. Green, J. J. En- gel, R. Mur-Artal, C. Ren, S. Verma, A. Clarkson, M. Yan, B. Budge, Y . Yan, X. Pan, J. Yon, Y . Zou, K. Leon, N. Carter, J. Briales, T. Gillingham, E. Mueggler, L. Pesqueira, M. Savva, D. Batra, H. M. Strasdat, R. D. Nardi, M. Goesele, S. Lovegrove, and R. Newcombe. 11 The Replica dat...
Pith/arXiv arXiv 1906
-
[47]
Takmaz, E
A. Takmaz, E. Fedele, R. W. Sumner, M. Pollefeys, F. Tombari, and F. Engelmann. OpenMask3D: Open-V ocabulary 3D Instance Seg- mentation. In Advances in Neural Information Processing Systems (NeurIPS), 2023. 2, 5, 7, 10
2023
-
[48]
Y . Tang, J. Zhang, Y . Lan, Y . Guo, D. Dong, C. Zhu, and K. Xu. Onlineanyseg: Online zero-shot 3d segmentation by visual foundation model guided 2d mask merging. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3676–3685, June 2025. 2, 3, 5, 6, 9, 10
2025
-
[49]
P. K. A. Vasu*, H. P. Ansari*, F. Faghri*, R. Vemulapalli, and O. Tuzel. Mobileclip: Fast image-text models through multi-modal reinforced training. In CVPR, 2024. 5
2024
-
[50]
S.-C. Wu, J. Wald, K. Tateno, N. Navab, and F. Tombari. Scene- GraphFusion: Incremental 3D Scene Graph Prediction from RGB-D Sequences. In Proceedings IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 9
2021
-
[51]
C. Xu, R. Kumaran, N. Stier, K. Yu, and T. H ¨ollerer. Multi- modal 3d fusion and in-situ learning for spatially aware ai. In 2024 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), 2024. doi: 10.1109/ISMAR62088.2024.00063 3, 9
-
[52]
X. Xu, H. Chen, L. Zhao, Z. Wang, J. Zhou, and J. Lu. Embod- iedsam: Online segment any 3d thing in real time. arXiv preprint arXiv:2408.11811, 2024. 10
arXiv 2024
-
[53]
K. Yamazaki, T. Hanyu, K. V o, T. Pham, M. Tran, G. Doretto, A. Nguyen, and N. Le. Open-fusion: Real-time open-vocabulary 3d mapping and queryable scene representation. In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 9411–9417, 2024. doi: 10.1109/ICRA57147.2024.10610193 2, 3, 5, 9
-
[54]
Y . Yang, H. Yang, J. Zhou, P. Chen, H. Zhang, Y . Du, and C. Gan. 3d-mem: 3d scene memory for embodied exploration and reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 17294–17303, June 2025. 3
2025
-
[55]
C. Zhang, D. Han, Y . Qiao, J. U. Kim, S.-H. Bae, S. Lee, and C. S. Hong. Faster segment anything: Towards lightweight sam for mobile applications. arXiv preprint arXiv:2306.14289, 2023. 5
Pith/arXiv arXiv 2023
-
[56]
Q. Zhang, X. Zhang, R. Zhu, F. Bai, M. Naserian, and Z. M. Mao. Robust real-time multi-vehicle collaboration on asynchronous sen- sors. In Proceedings of the 29th Annual International Conference on Mobile Computing and Networking, ACM MobiCom ’23. Associa- tion for Computing Machinery, New York, NY , USA, 2023. doi: 10. 1145/3570361.3613271 2, 10
arXiv 2023
-
[57]
W. Zhang, Z. He, L. Liu, Z. Jia, Y . Liu, M. Gruteser, D. Raychaudhuri, and Y . Zhang. Elf: accelerate high-resolution mobile deep vision with content-aware parallel offloading. In Proceedings of the 27th Annual International Conference on Mobile Computing and Networking, Mo- biCom ’21, p. 201–214. Association for Computing Machinery, New York, NY , USA, ...
- [58]
-
[59]
Zhong, J
Y . Zhong, J. Yang, P. Zhang, C. Li, N. Codella, L. H. Li, L. Zhou, X. Dai, L. Yuan, Y . Li, et al. Regionclip: Region-based language- image pretraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16793–16803, 2022. 3
2022
-
[60]
X. Zou, J. Yang, H. Zhang, F. Li, L. Li, J. Wang, L. Wang, J. Gao, and Y . J. Lee. Segment everything everywhere all at once. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23. Curran Associates Inc., Red Hook, NY , USA, 2024. 3 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.