T-Rex: Tactile-Reactive Dexterous Manipulation
Pith reviewed 2026-06-27 03:43 UTC · model grok-4.3
The pith
Tactile feedback added to vision-language-action models via a new dataset and variable-rate architecture raises success rates by more than 30 percent on 12 delicate manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A variable-rate Mixture-of-Transformers architecture equipped with a temporal tactile VQ-VAE encoder, trained on a 100-hour tactile-rich dataset collected through elementary motor primitives, produces tactile-reactive policies that achieve over 30 percent higher average success rate than the strongest baseline across 12 manipulation tasks that demand delicate force control and deformable object handling.
What carries the argument
The variable-rate Mixture-of-Transformers (MoT) architecture with temporal tactile VQ-VAE encoder, which fuses high-frequency touch signals into vision-language-action models at adjustable rates without loss of prior capabilities.
If this is right
- Tactile-reactive policies become viable for tasks that require continuous adjustment to contact forces and object compliance.
- A dataset built from elementary motor primitives can supply enough variety to train effective touch-aware controllers.
- Variable-rate processing allows high-frequency tactile input to be added without retraining or replacing the core vision-language components.
- The same architecture supports evaluation on a standardized set of 12 tasks that mix force control and deformation challenges.
Where Pith is reading between the lines
- The same fusion strategy could be tested with other high-frequency sensors such as audio or joint torque to broaden multimodal reactivity.
- Collecting data around basic primitives may reduce the total volume needed when extending the method to new robot platforms or environments.
- If the MoT design scales, it could support policies that maintain performance while incorporating additional sensory streams in longer-horizon tasks.
Load-bearing premise
The data-efficient collection recipe and variable-rate MoT architecture can add high-frequency tactile signals to existing VLA models without degrading their vision-language performance.
What would settle it
A side-by-side evaluation on the same 12 tasks in which the tactile-reactive policies show equal or lower success rates than the vision-language baseline would disprove the performance gain.
Figures



















read the original abstract
The ability to react dynamically to tactile signals has long been considered crucial to agile human-level dexterity. Yet contemporary learning-based Vision-Language-Action (VLA) models for robotic manipulation generally either overlook the tactile modality or are limited to encoders with static cues, due in part to the scarcity of diverse training data and standardized evaluation, architectural constraints in current VLA models, and limitations of static tactile encoders. In this paper, we push the frontier of tactile-reactive manipulation by addressing all of these limitations. We propose a large-scale, 100-hour tactile-rich dataset collected via a novel, data-efficient recipe that prioritizes elementary motor primitives. To effectively exploit naturally high-frequency touch signals without sacrificing the existing capabilities of existing VLAs, we introduce a variable-rate Mixture-of-Transformers (MoT) architecture equipped with a novel temporal tactile VQ-VAE encoder. We demonstrate the effectiveness of tactile-reactive policies on 12 manipulation tasks requiring delicate force control and deformable object manipulation, achieving over 30% higher average success rate than the strongest baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces T-Rex for tactile-reactive dexterous manipulation in robotics. It contributes a 100-hour tactile-rich dataset collected via a novel data-efficient recipe emphasizing elementary motor primitives, along with a variable-rate Mixture-of-Transformers (MoT) architecture paired with a temporal tactile VQ-VAE encoder. This is used to integrate high-frequency tactile signals into existing Vision-Language-Action (VLA) models. The central empirical result is demonstration on 12 manipulation tasks involving delicate force control and deformable objects, with over 30% higher average success rate than the strongest baseline.
Significance. If the empirical results hold with proper controls, the work would meaningfully advance integration of dynamic tactile sensing into VLA models for agile manipulation, addressing data scarcity and architectural constraints noted in the abstract. The data collection recipe and variable-rate MoT + VQ-VAE design offer concrete, potentially reusable components for handling high-frequency touch signals without explicit mention of degrading vision-language performance.
major comments (2)
- [Experiments / Results] The abstract states a >30% average success improvement but supplies no information on trial counts per task, baseline definitions, statistical tests, or per-task breakdowns. The experiments section must provide these details to support the central claim; without them the result cannot be evaluated.
- [Methods / Architecture] The weakest assumption is that the MoT + temporal VQ-VAE successfully integrates tactile signals without degrading existing VLA vision-language performance. The methods and ablations sections should include explicit metrics (e.g., success on vision-only subtasks or language grounding scores) comparing the augmented model to the base VLA.
minor comments (2)
- [Abstract] Define the MoT acronym at first use in the abstract and introduction.
- [Introduction / Experiments] Clarify the exact composition of the 12 tasks (e.g., list names or categories) to allow readers to assess coverage of force control and deformable-object scenarios.
Simulated Author's Rebuttal
We thank the referee for their thorough review and recommendation of minor revision. We address the major comments point-by-point below, and will incorporate the suggested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Experiments / Results] The abstract states a >30% average success improvement but supplies no information on trial counts per task, baseline definitions, statistical tests, or per-task breakdowns. The experiments section must provide these details to support the central claim; without them the result cannot be evaluated.
Authors: We agree with the referee that additional details are necessary to fully support the central claim. In the revised version, we will expand the experiments section to report the number of trials per task (50 trials), explicit baseline definitions, per-task success rate breakdowns, and results of statistical tests (e.g., t-tests). We will also update the abstract to reference these details where space allows. revision: yes
-
Referee: [Methods / Architecture] The weakest assumption is that the MoT + temporal VQ-VAE successfully integrates tactile signals without degrading existing VLA vision-language performance. The methods and ablations sections should include explicit metrics (e.g., success on vision-only subtasks or language grounding scores) comparing the augmented model to the base VLA.
Authors: We concur that validating no degradation in vision-language performance is crucial. The revised methods and ablations sections will include explicit comparisons on vision-only subtasks and language grounding scores between the MoT model and the base VLA to demonstrate that tactile integration does not compromise existing capabilities. revision: yes
Circularity Check
No significant circularity
full rationale
The paper's central claim is an empirical result: tactile-reactive policies achieve over 30% higher average success rate than the strongest baseline across 12 manipulation tasks. This rests on a new 100-hour dataset collected via a described recipe and a variable-rate MoT architecture with temporal tactile VQ-VAE encoder. No derivation chain, fitted parameter renamed as prediction, self-definitional step, or load-bearing self-citation is present in the provided abstract or description. The result is evaluated against external baselines on specified tasks and is therefore self-contained against external benchmarks rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
- [1]
-
[2]
R. Yang, Q. Yu, Y . Wu, R. Yan, B. Li, A.-C. Cheng, X. Zou, Y . Fang, H. Yin, S. Liu, S. Han, Y . Lu, and X. Wang. Egovla: Learning vision-language-action models from egocentric human videos, 2025. URLhttps://arxiv.org/abs/2507.12440
Pith/arXiv arXiv 2025
- [3]
-
[4]
T. Tao, M. K. Srirama, J. J. Liu, K. Shaw, and D. Pathak. Dexwild: Dexterous human interac- tions for in-the-wild robot policies.Robotics: Science and Systems (RSS), 2025
2025
-
[6]
URLhttps://arxiv.org/abs/2410.24164
-
[7]
J. Bjorck, F. Castaneda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z. Yu, A. Zhang, ...
Pith/arXiv arXiv 2025
-
[8]
H. Chen, J. Liu, C. Gu, Z. Liu, R. Zhang, X. Li, X. He, Y . Guo, C.-W. Fu, S. Zhang, and P.-A. Heng. Fast-in-slow: A dual-system foundation model unifying fast manipulation within slow reasoning, 2025. URLhttps://arxiv.org/abs/2506.01953
arXiv 2025
-
[9]
H. Xue, J. Ren, W. Chen, G. Zhang, Y . Fang, G. Gu, H. Xu, and C. Lu. Reactive diffusion policy: Slow-fast visual-tactile policy learning for contact-rich manipulation. InProceedings of Robotics: Science and Systems (RSS), 2025
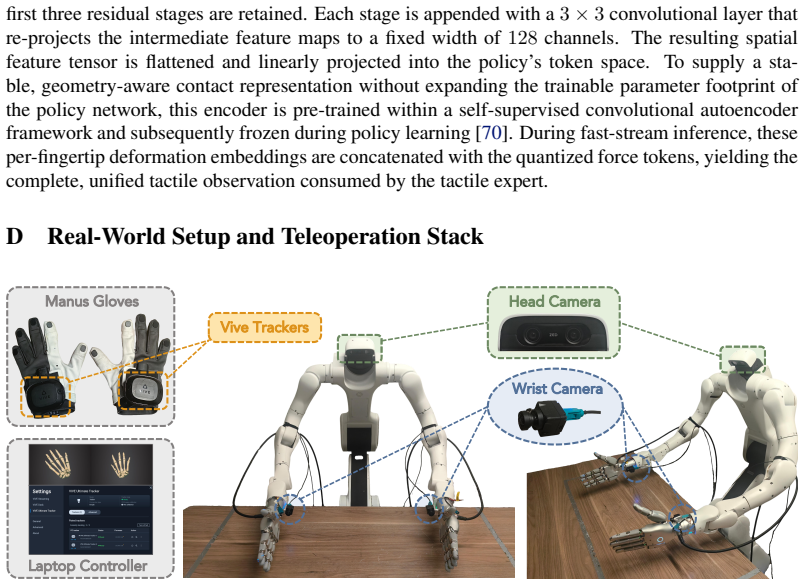
2025
-
[10]
L. Fu, G. Datta, H. Huang, W. C.-H. Panitch, J. Drake, J. Ortiz, M. Mukadam, M. Lam- beta, R. Calandra, and K. Goldberg. A touch, vision, and language dataset for multi- modal alignment. InForty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=tFEOOH9eH0
2024
-
[11]
C. Sferrazza, Y . Seo, H. Liu, Y . Lee, and P. Abbeel. The power of the senses: Generaliz- able manipulation from vision and touch through masked multimodal learning.arXiv preprint arXiv:2311.00924, 2023
arXiv 2023
-
[12]
X. Zhu, B. Huang, and Y . Li. Touch in the wild: Learning fine-grained manipulation with a portable visuo-tactile gripper. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URLhttps://openreview.net/forum?id=WabVVQKTUF
2025
-
[13]
Guzey, B
I. Guzey, B. Evans, S. Chintala, and L. Pinto. Dexterity from touch: Self-supervised pre- training of tactile representations with robotic play, 2023
2023
-
[14]
Y . Gao, L. A. Hendricks, K. J. Kuchenbecker, and T. Darrell. Deep learning for tactile un- derstanding from visual and haptic data. In2016 IEEE International Conference on Robotics and Automation (ICRA), page 536–543. IEEE Press, 2016. doi:10.1109/ICRA.2016.7487176. URLhttps://doi.org/10.1109/ICRA.2016.7487176. 10
-
[15]
Z. Liu, J. Liu, J. Xu, N. Han, C. Gu, H. Chen, K. Zhou, R. Zhang, K. C. Hsieh, K. Wu, Z. Che, J. Tang, and S. Zhang. Mla: A multisensory language-action model for multimodal understanding and forecasting in robotic manipulation, 2026. URLhttps://arxiv.org/ abs/2509.26642
arXiv 2026
-
[16]
T. Lin, Y . Zhang, Q. Li, H. Qi, B. Yi, S. Levine, and J. Malik. Learning visuotactile skills with two multifingered hands.arXiv:2404.16823, 2024
arXiv 2024
-
[17]
T. Wu, J. Li, J. Zhang, M. Wu, and H. Dong. Canonical representation and force-based pretraining of 3d tactile for dexterous visuo-tactile policy learning.2025 IEEE Interna- tional Conference on Robotics and Automation (ICRA), pages 6786–6792, 2024. URL https://api.semanticscholar.org/CorpusID:272911365
2025
-
[19]
L. Heng, H. Geng, K. Zhang, P. Abbeel, and J. Malik. Vitacformer: Learning cross-modal representation for visuo-tactile dexterous manipulation, 2025. URLhttps://arxiv.org/ abs/2506.15953
Pith/arXiv arXiv 2025
-
[20]
H. Yuan, W. Yi, Z. Zhang, W. Chen, Y . Mo, J. Yin, X. Li, X. Zeng, C. Wen, C. Lu, K. Driggs- Campbell, and I. Lourentzou. Vtam: Video-tactile-action models for complex physical inter- action beyond vlas.arXiv preprint arXiv:2603.23481, 2026
arXiv 2026
-
[21]
K. Yu, Y . Han, Q. Wang, V . Saxena, D. Xu, and Y . Zhao. Mimictouch: Leveraging multi- modal human tactile demonstrations for contact-rich manipulation. In8th Annual Conference on Robot Learning, 2024. URLhttps://openreview.net/forum?id=7yMZAUkXa4
2024
- [22]
- [23]
- [24]
-
[25]
Jones, O
J. Jones, O. Mees, C. Sferrazza, K. Stachowicz, P. Abbeel, and S. Levine. Beyond sight: Finetuning generalist robot policies with heterogeneous sensors via language grounding. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), At- lanta, USA, 2025
2025
-
[26]
J. Bi, K. Y . Ma, C. Hao, M. Z. Shou, and H. Soh. Vla-touch: Enhancing vision-language- action models with dual-level tactile feedback, 2025. URLhttps://arxiv.org/abs/2507. 17294
2025
-
[27]
J. Yu, H. Liu, Q. Yu, J. Ren, C. Hao, H. Ding, G. Huang, G. Huang, Y . Song, P. Cai, W. Zhang, and C. Lu. Forcevla: Enhancing vla models with a force-aware moe for contact-rich manipu- lation. InAdvances in Neural Information Processing Systems, 2025
2025
-
[28]
C. Deng, D. Zhu, K. Li, C. Gou, F. Li, Z. Wang, S. Zhong, W. Yu, X. Nie, Z. Song, G. Shi, and H. Fan. Emerging properties in unified multimodal pretraining, 2025. URLhttps: //arxiv.org/abs/2505.14683. 11
Pith/arXiv arXiv 2025
-
[29]
C. Team. Chameleon: Mixed-modal early-fusion foundation models, 2024. URLhttps: //arxiv.org/abs/2405.09818
Pith/arXiv arXiv 2024
-
[30]
X. Chen, Z. Wu, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, and C. Ruan. Janus-pro: Unified multimodal understanding and generation with data and model scaling, 2025. URLhttps: //arxiv.org/abs/2501.17811
Pith/arXiv arXiv 2025
-
[31]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. In Conference on Robot Learning, pages 2165–2183. PMLR, 2023
2023
-
[32]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model, 2024. URL https://arxiv.org/abs/2406.09246
Pith/arXiv arXiv 2024
-
[33]
Y . Hu, Y . Guo, P. Wang, X. Chen, Y .-J. Wang, J. Zhang, K. Sreenath, C. Lu, and J. Chen. Video prediction policy: A generalist robot policy with predictive visual representations, 2024. URL https://arxiv.org/abs/2412.14803
Pith/arXiv arXiv 2024
-
[34]
Q. Lv, W. Kong, H. Li, J. Zeng, Z. Qiu, D. Qu, H. Song, Q. Chen, X. Deng, and J. Pang. F1: A vision-language-action model bridging understanding and generation to actions, 2025. URL https://arxiv.org/abs/2509.06951
Pith/arXiv arXiv 2025
-
[35]
C.-L. Cheang, G. Chen, Y . Jing, T. Kong, H. Li, Y . Li, Y . Liu, H. Wu, J. Xu, Y . Yang, H. Zhang, and M. Zhu. Gr-2: A generative video-language-action model with web-scale knowledge for robot manipulation, 2024. URLhttps://arxiv.org/abs/2410.06158
Pith/arXiv arXiv 2024
-
[36]
J. Cai, Z. Cai, J. Cao, Y . Chen, Z. He, L. Jiang, H. Li, H. Li, Y . Li, Y . Liu, Y . Lu, Q. Lv, H. Ma, J. Pang, Y . Qiao, Z. Qiu, Y . Shen, X. Shi, Y . Tian, B. Wang, H. Wang, J. Wang, T. Wang, X. Wei, C. Wu, Y . Xie, B. Xing, Y . Yang, Y . Yang, Q. Yu, F. Yuan, J. Zeng, J. Zhang, S. Zhang, S. Zhang, Z. Zhaxi, B. Zhou, Y . Zhou, Y . Zhou, H. Zhu, Y . Zhu...
arXiv 2026
-
[37]
H. Bi, H. Tan, S. Xie, Z. Wang, S. Huang, H. Liu, R. Zhao, Y . Feng, C. Xiang, Y . Rong, H. Zhao, H. Liu, Z. Su, L. Ma, H. Su, and J. Zhu. Motus: A unified latent action world model,
-
[38]
URLhttps://arxiv.org/abs/2512.13030
-
[39]
Y . Hu, J. Zhang, Y . Luo, Y . Guo, X. Chen, X. Sun, K. Feng, Q. Lu, S. Chen, Y . Zhang, W. Li, and J. Chen. Bagelvla: Enhancing long-horizon manipulation via interleaved vision-language- action generation, 2026. URLhttps://arxiv.org/abs/2602.09849
arXiv 2026
- [40]
-
[41]
C. Gu, J. Liu, H. Chen, R. Huang, Q. Wuwu, Z. Liu, X. Li, Y . Li, R. Zhang, P. Jia, P.-A. Heng, and S. Zhang. Manualvla: A unified vla model for chain-of-thought manual generation and robotic manipulation, 2025. URLhttps://arxiv.org/abs/2512.02013
arXiv 2025
-
[42]
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finn, A. Handa, M.-Y . Liu, D. Xiang, G. Wetzstein, and T.-Y . Lin. Cot-vla: Visual chain-of-thought reasoning for vision-language-action models, 2025. URLhttps://arxiv.org/abs/2503.22020
Pith/arXiv arXiv 2025
-
[43]
Z. Liu, J. Liu, H. Chen, J. Yu, Z. Guo, C. Hou, C. Gu, X. Mi, R. Zhang, K. Wu, Z. Che, J. Tang, P.-A. Heng, and S. Zhang. Last0: Latent spatio-temporal chain-of-thought for robotic vision-language-action model, 2026. URLhttps://arxiv.org/abs/2601.05248. 12
arXiv 2026
-
[44]
Hoque, P
R. Hoque, P. Huang, D. J. Yoon, M. sivapurapu, and J. Zhang. Egodex: Learning dexter- ous manipulation from large-scale egocentric video. InThe Fourteenth International Con- ference on Learning Representations, 2026. URLhttps://openreview.net/forum?id= FFxkFMU89E
2026
-
[45]
Grauman, A
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, M. Martin, T. Nagarajan, I. Radosavovic, S. K. Ramakrishnan, F. Ryan, J. Sharma, M. Wray, M. Xu, E. Z. Xu, C. Zhao, S. Bansal, D. Batra, V . Cartillier, S. Crane, T. Do, M. Doulaty, A. Erapalli, C. Feichtenhofer, A. Fragomeni, Q. Fu, A. Gebreselas...
2022
-
[46]
Y . Liu, Y . Liu, C. Jiang, K. Lyu, W. Wan, H. Shen, B. Liang, Z. Fu, H. Wang, and L. Yi. Hoi4d: A 4d egocentric dataset for category-level human-object interaction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21013–21022, June 2022
2022
-
[47]
T. Xiao, I. Radosavovic, T. Darrell, and J. Malik. Masked visual pre-training for motor control. arXiv preprint arXiv:2203.06173, 2022
arXiv 2022
-
[48]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual repre- sentation for robot manipulation. In6th Annual Conference on Robot Learning, 2022. URL https://openreview.net/forum?id=tGbpgz6yOrI
2022
-
[49]
D. Niu, Y . Sharma, H. Xue, G. Biamby, J. Zhang, Z. Ji, T. Darrell, and R. Herzig. Pre- training auto-regressive robotic models with 4d representations. InForty-second Interna- tional Conference on Machine Learning, 2025. URLhttps://openreview.net/forum? id=2FDsh5D2Th
2025
-
[50]
Kannan, K
A. Kannan, K. Shaw, S. Bahl, P. Mannam, and D. Pathak. Deft: Dexterous fine-tuning for real-world hand policies.CoRL, 2023
2023
-
[51]
G. Li, N. Tsagkas, J. Song, R. Mon-Williams, S. Vijayakumar, K. Shao, and L. Sevilla-Lara. Learning precise affordances from egocentric videos for robotic manipulation. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[52]
S. Gao, W. Liang, K. Zheng, A. Malik, S. Ye, S. Yu, W.-C. Tseng, Y . Dong, K. Mo, C.-H. Lin, Q. Ma, S. Nah, L. Magne, J. Xiang, Y . Xie, R. Zheng, D. Niu, Y . L. Tan, K. Zentner, G. Kurian, S. Indupuru, P. Jannaty, J. Gu, J. Zhang, J. Malik, P. Abbeel, M.-Y . Liu, Y . Zhu, J. Jang, and L. J. Fan. Dreamdojo: A generalist robot world model from large-scale ...
Pith/arXiv arXiv 2026
-
[53]
S. Ye, Y . Ge, K. Zheng, S. Gao, S. Yu, G. Kurian, S. Indupuru, Y . L. Tan, C. Zhu, J. Xi- ang, A. Malik, K. Lee, W. Liang, N. Ranawaka, J. Gu, Y . Xu, G. Wang, F. Hu, A. Narayan, J. Bjorck, J. Wang, G. Kim, D. Niu, R. Zheng, Y . Xie, J. Wu, Q. Wang, R. Julian, D. Xu, Y . Du, Y . Chebotar, S. Reed, J. Kautz, Y . Zhu, L. J. Fan, and J. Jang. World action m...
Pith/arXiv arXiv 2026
-
[54]
S. Li, Y . Gao, D. Sadigh, and S. Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025. 13
Pith/arXiv arXiv 2025
-
[55]
M. Xu, Z. Xu, Y . Xu, C. Chi, G. Wetzstein, M. Veloso, and S. Song. Flow as the cross-domain manipulation interface. InConference on Robot Learning, pages 2475–2499. PMLR, 2025
2025
-
[56]
C. Wang, L. Fan, J. Sun, R. Zhang, L. Fei-Fei, D. Xu, Y . Zhu, and A. Anandkumar. Mimicplay: Long-horizon imitation learning by watching human play.arXiv preprint arXiv:2302.12422, 2023
arXiv 2023
-
[57]
R. Zheng, J. Wang, S. Reed, J. Bjorck, Y . Fang, F. Hu, J. Jang, K. Kundalia, Z. Lin, L. Magne, A. Narayan, Y . L. Tan, G. Wang, Q. Wang, J. Xiang, Y . Xu, S. Ye, J. Kautz, F. Huang, Y . Zhu, and L. Fan. Flare: Robot learning with implicit world modeling, 2025. URLhttps://arxiv. org/abs/2505.15659
Pith/arXiv arXiv 2025
- [58]
-
[59]
O. X.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Her- zog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakr- ishna, A. W...
Pith/arXiv arXiv 2023
-
[60]
Khazatsky, K
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, 14 I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, ...
2024
-
[61]
Walke, K
H. Walke, K. Black, A. Lee, M. J. Kim, M. Du, C. Zheng, T. Zhao, P. Hansen-Estruch, Q. Vuong, A. He, V . Myers, K. Fang, C. Finn, and S. Levine. Bridgedata v2: A dataset for robot learning at scale. InConference on Robot Learning (CoRL), 2023
2023
-
[62]
Dasari, F
S. Dasari, F. Ebert, S. Tian, S. Nair, B. Bucher, K. Schmeckpeper, S. Singh, S. Levine, and C. Finn. Robonet: Large-scale multi-robot learning. InCoRL 2019: Volume 100 Proceedings of Machine Learning Research, 2019
2019
-
[63]
J. Lim, T. Ha, M. Choi, J. Kim, B. Kim, S. Jeon, and H. Joo. Hrdexdb: A large-scale dataset of dexterous human and robotic hand grasps, 2026
2026
-
[64]
Y . Liu, Y . Yang, Y . Wang, X. Wu, J. Wang, Y . Yao, S. Schwertfeger, S. Yang, W. Wang, J. Yu, et al. Realdex: Towards human-like grasping for robotic dexterous hand.arXiv preprint arXiv:2402.13853, 2024
arXiv 2024
-
[65]
R. Wang, J. Zhang, J. Chen, Y . Xu, P. Li, T. Liu, and H. Wang. Dexgraspnet: A large- scale robotic dexterous grasp dataset for general objects based on simulation.arXiv preprint arXiv:2210.02697, 2022
arXiv 2022
-
[66]
Zhang, S
H. Zhang, S. Christen, Z. Fan, O. Hilliges, and J. Song. GraspXL: Generating grasping motions for diverse objects at scale. InEuropean Conference on Computer Vision (ECCV), 2024
2024
-
[67]
Y . Wang, J. Ye, C. Xiao, Y . Zhong, H. Tao, H. Yu, Y . Liu, J. Yu, and Y . Ma. Dexh2r: A benchmark for dynamic dexterous grasping in human-to-robot handover. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2025
2025
-
[68]
Z. Fan, O. Taheri, D. Tzionas, M. Kocabas, M. Kaufmann, M. J. Black, and O. Hilliges. ARC- TIC: A dataset for dexterous bimanual hand-object manipulation. InProceedings IEEE Con- ference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[69]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
Pith/arXiv arXiv 2025
-
[70]
van den Oord, O
A. van den Oord, O. Vinyals, and K. Kavukcuoglu. Neural discrete representation learning,
-
[71]
URLhttps://arxiv.org/abs/1711.00937
-
[72]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385
Pith/arXiv arXiv 2015
- [73]
-
[74]
Caron, Y
S. Caron, Y . De Mont-Marin, R. Budhiraja, S. H. Bang, I. Domrachev, S. Nedelchev, P. Du, A. Escande, J. Vaillant, B. Wingo, S. Patapati, D. San Jos ´e Pro, and N. G. Marticorena Vidal. Pink: Python inverse kinematics based on Pinocchio, 2026. URLhttps://github.com/ stephane-caron/pink
2026
-
[75]
Carpentier, G
J. Carpentier, G. Saurel, G. Buondonno, J. Mirabel, F. Lamiraux, O. Stasse, and N. Mansard. The Pinocchio C++ library – A fast and flexible implementation of rigid body dynamics al- gorithms and their analytical derivatives. InSII 2019 - International Symposium on System Integrations, Paris, France, Jan. 2019. URLhttps://hal.laas.fr/hal-01866228
2019
-
[76]
Turn a page of the book from right to left using your right index finger
J. A. E. Andersson, J. Gillis, G. Horn, J. B. Rawlings, and M. Diehl. CasADi – A software framework for nonlinear optimization and optimal control.Mathematical Programming Com- putation, 11(1):1–36, 2019. doi:10.1007/s12532-018-0139-4. 16 Appendix In this appendix, we first present the model architecture and training hyperparameters in App. A. We then pro...
-
[77]
Object Collision.During thescrew lightbulbtask in the first row, the right hand failed to correctly insert it into the socket after grasping the lightbulb; instead, it caused the lightbulb to collide with the base, thereby preventing the subsequent insertion and rotation steps from being completed. This indicates that during the execution of complex tasks...
-
[78]
Slipping Off.During theopen locktask in the second row, the model successfully slid and grasped the key; However, it failed to maintain a secure grip during the subsequent steps, causing the key to slip and drop. For the grasping of small objects and precise in-hand manipulation, the model still lacks a certain degree of fine-grained dexterity, which rema...
-
[79]
But it failed to place the egg correctly into the yellow egg 29 tray
Imprecise Position.In the task oftransfer egg, the model successfully grasped the eggs and relied on force feedback to ensure its integrity. But it failed to place the egg correctly into the yellow egg 29 tray. This demonstrates that the model still suffers from deficiencies in precise positioning, which is a limitation that highlights the inherent distri...
-
[80]
This highlights that dexterous hand control still lacks coordination at the individual finger level, and issues such as unintended contact between multiple fingers may persist
Multi-finger friction.In thesort mahjongtask, the model correctly selected the ”Red Zhong” tile located on the left as the target box to be opened; however, the positioning of its thumb was too low, causing it to make contact with the central ”Green Fa” tile and inadvertently open two boxes simultaneously. This highlights that dexterous hand control still...
-
[81]
This highlights that in the manipulation of certain deformable objects, the model remains constrained by the overly forceful control inherent in its sequencial prediction mechanism
Excessive Force.During theapply toothpastetask, after grasping the tube, the model applied excessive force and squeezed out too much toothpaste, resulting in a failure to catch it with the toothbrush. This highlights that in the manipulation of certain deformable objects, the model remains constrained by the overly forceful control inherent in its sequenc...
-
[82]
Sliding Misalignment.In theextract cardtask, after grasping the card sleeve, the model failed to apply uniform force when extracting the card from the small slot; this suggests that for tasks requiring sliding motions, the model needs to establish stronger tactile conditioning in the temporal dimension to generate the correct actions. 30
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.