Contrastive Action-Image Pre-training for Visuomotor Control
Pith reviewed 2026-06-27 03:12 UTC · model grok-4.3
The pith
CAIP learns vision encoders by contrasting images against 3D hand keypoints extracted from human egocentric video to serve as action proxies for robots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating 3D hand keypoints from large-scale egocentric human video as proxies for end-effector actions, CAIP applies a contrastive objective to learn a vision encoder that produces representations aligned with downstream robot action spaces, yielding more than 30 percent performance gains over prior encoders when deployed on real-world dexterous manipulation tasks with limited robot data.
What carries the argument
The contrastive action-image pre-training objective that aligns image features with 3D hand keypoint features extracted from human video.
If this is right
- CAIP scales pre-training by substituting abundant human video for scarce robot trajectories while still supplying an action signal.
- The resulting encoder improves policy performance on real hardware including Dexmate Vega and Sharpa Wave hands across folding, pouring, and fine-grained tasks.
- Gains exceed 30 percent relative to DINOv2, SigLIP, MVP, and R3M under identical downstream training conditions.
- Only 88 hours of robot data are needed once the encoder has been pre-trained on the human video corpus.
Where Pith is reading between the lines
- If hand-keypoint alignment proves robust across varied human activities, the same pre-training recipe could be applied to other embodied domains such as navigation or mobile manipulation.
- The method implicitly suggests that future robot datasets could focus on high-quality action labels rather than attempting to match internet-scale image volume.
- Extending the contrastive pairs to include temporal sequences of keypoints might further strengthen the learned dynamics for longer-horizon tasks.
Load-bearing premise
That 3D hand keypoints from human egocentric video provide a representation that aligns naturally with downstream robot action spaces and transfers effectively to visuomotor policies.
What would settle it
A controlled experiment in which the 3D hand keypoint signal is replaced by random vectors or unrelated features during pre-training, after which performance on the same robot tasks shows no improvement over baseline encoders.
Figures

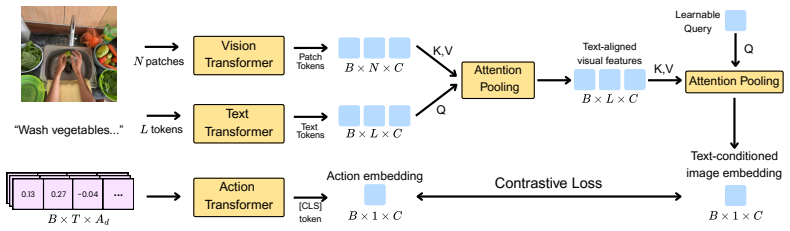
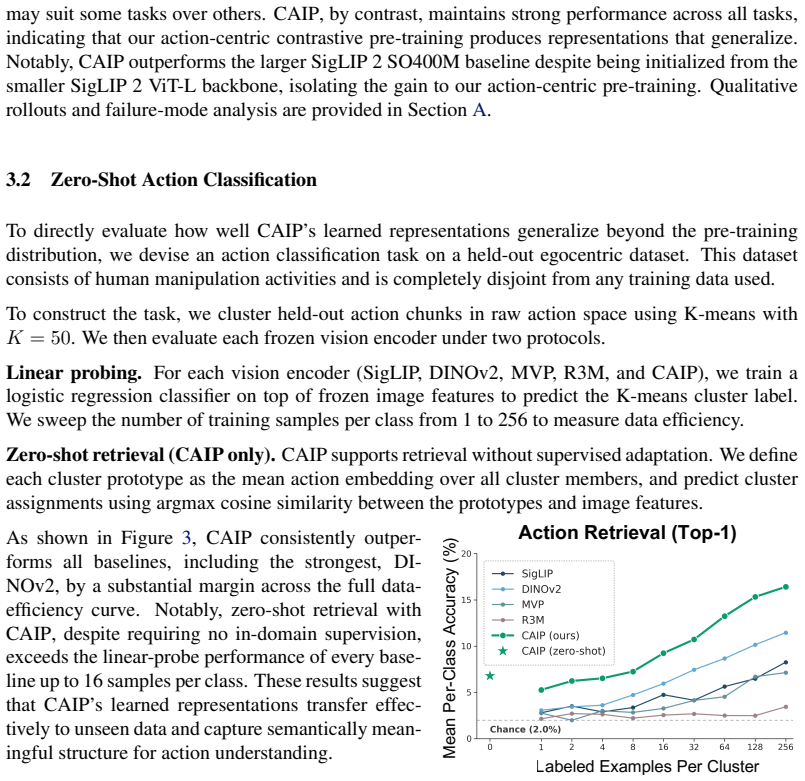










read the original abstract
Existing vision encoders for robotics face a fundamental bottleneck: robotic datasets lack the scale necessary for large-scale pre-training. Prior work circumvents this data scarcity by turning to internet-scale image and language data or egocentric human video. While these models show promise, neither paradigm learns from paired vision and action data, which downstream visuomotor control policies require. However, robot trajectories, the most direct source of this paired signal, are not available at pre-training scale, motivating us to extract action signals from abundant human video instead. To this end, we introduce CAIP (Contrastive Action-Image Pre-training), a vision encoder that treats human hand poses from large-scale egocentric video as a proxy for end-effector actions. By extracting 3D hand keypoints, a representation that aligns naturally with downstream robot action spaces, CAIP learns a unified action-image representation through a contrastive objective. Leveraging 32,041 hours of egocentric human video and only 88 hours of robotic manipulation data, CAIP outperforms state-of-the-art vision encoders including DINOv2, SigLIP, MVP, and R3M. Evaluated on a challenging real-world dexterous manipulation setup using Dexmate Vega and Sharpa Wave hands, CAIP yields performance gains of more than 30% on tasks involving folding, pouring, and fine-grained manipulation. Our results show that our method of contrastive action-centric pre-training yields a scalable path to achieving robust visual representations better suited for physical interaction.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CAIP (Contrastive Action-Image Pre-training), a vision encoder pre-trained via contrastive loss on paired images and 3D hand keypoints extracted from 32,041 hours of egocentric human video. These keypoints are positioned as a proxy for robot end-effector actions. The method is evaluated on real-world dexterous manipulation tasks (folding, pouring, fine-grained manipulation) using Dexmate Vega and Sharpa Wave hands, reporting >30% gains over DINOv2, SigLIP, MVP, and R3M while using only 88 hours of robotic data.
Significance. If the central claims hold after addressing the alignment issue, the work demonstrates a scalable route to action-aware visual representations by leveraging abundant human video rather than scarce robot trajectories. The independent human corpus avoids circularity with the robotic evaluation data, and the real-world dexterous setup on challenging platforms provides a strong testbed. This could meaningfully advance visuomotor pre-training if the proxy mechanism is shown to transfer without spurious correlations.
major comments (1)
- [Abstract] Abstract: The claim that '3D hand keypoints, a representation that aligns naturally with downstream robot action spaces' lacks any described retargeting, forward-kinematics projection, or morphological mapping between human hands (typically 21-27 DOF) and the specific robot platforms (Dexmate Vega, Sharpa Wave). Without an ablation isolating whether the contrastive objective learns action-relevant features versus visual correlations, the attribution of the reported >30% gains to action-image pre-training is not substantiated.
minor comments (1)
- [Abstract] Abstract: The quantitative performance claims would be strengthened by explicit mention of the number of tasks, exact success metrics, statistical significance, and baseline implementation details (e.g., whether encoders were frozen or fine-tuned).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract claim regarding action alignment. We address the concern point by point below and will revise the manuscript accordingly to improve clarity and substantiation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that '3D hand keypoints, a representation that aligns naturally with downstream robot action spaces' lacks any described retargeting, forward-kinematics projection, or morphological mapping between human hands (typically 21-27 DOF) and the specific robot platforms (Dexmate Vega, Sharpa Wave). Without an ablation isolating whether the contrastive objective learns action-relevant features versus visual correlations, the attribution of the reported >30% gains to action-image pre-training is not substantiated.
Authors: We acknowledge that the abstract phrasing could be more precise. The manuscript positions 3D hand keypoints as a proxy for end-effector actions because they provide 3D Cartesian positions of hand joints extracted from egocentric video, which share a similar spatial representation with many robot end-effector pose controllers. No explicit retargeting, forward-kinematics projection, or morphological mapping between human (21-27 DOF) and robot hands is described or performed, as the contrastive objective operates on the keypoint coordinates directly as an action signal without requiring joint-space alignment. The visual encoder is trained to produce features predictive of these keypoints, which are then frozen and used with separate robot-specific action heads in the 88 hours of downstream data. We agree this proxy mechanism requires clearer justification to rule out spurious visual correlations. The existing comparisons to DINOv2, SigLIP, MVP, and R3M (none of which use action signals) provide indirect evidence, but we will add an ablation in the revision that contrasts against a purely visual contrastive baseline on the same human video corpus to isolate the contribution of the action-image pairing. This will be reflected in an updated abstract and methods section. revision: yes
Circularity Check
No significant circularity; derivation uses independent external data
full rationale
The paper's central method extracts 3D hand keypoints from large-scale egocentric human video (32,041 hours) and applies contrastive pre-training to learn action-image representations. This corpus is independent of the downstream robotic test tasks (88 hours of manipulation data on Dexmate Vega/Sharpa Wave). No equations, fitted parameters, or predictions in the provided text reduce to self-fitted quantities from the evaluation set. The alignment claim is an assumption, not a definitional reduction or self-citation chain. Self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption 3D hand keypoints from human video align naturally with robot end-effector action spaces
Reference graph
Works this paper leans on
-
[1]
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language supervision, 2021. URLhttps://arxiv.org/abs/2103.00020
Pith/arXiv arXiv 2021
-
[2]
X. Zhai, B. Mustafa, A. Kolesnikov, and L. Beyer. Sigmoid loss for language image pre- training, 2023. URLhttps://arxiv.org/abs/2303.15343
Pith/arXiv arXiv 2023
-
[3]
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick. Masked autoencoders are scalable vision learners, 2021. URLhttps://arxiv.org/abs/2111.06377
Pith/arXiv arXiv 2021
-
[4]
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haz- iza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. Dinov2: Learning robust visual features without sup...
Pith/arXiv arXiv 2024
-
[5]
H. Liu, C. Li, Q. Wu, and Y . J. Lee. Visual instruction tuning, 2023. URLhttps://arxiv. org/abs/2304.08485
Pith/arXiv arXiv 2023
-
[6]
H. Bao, L. Dong, S. Piao, and F. Wei. Beit: Bert pre-training of image transformers, 2022. URLhttps://arxiv.org/abs/2106.08254
Pith/arXiv arXiv 2022
-
[7]
J.-B. Alayrac, J. Donahue, P. Luc, A. Miech, I. Barr, Y . Hasson, K. Lenc, A. Mensch, K. Milli- can, M. Reynolds, R. Ring, E. Rutherford, S. Cabi, T. Han, Z. Gong, S. Samangooei, M. Mon- teiro, J. Menick, S. Borgeaud, A. Brock, A. Nematzadeh, S. Sharifzadeh, M. Binkowski, R. Barreira, O. Vinyals, A. Zisserman, and K. Simonyan. Flamingo: a visual language ...
Pith/arXiv arXiv 2022
-
[8]
J. Li, D. Li, S. Savarese, and S. Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023. URLhttps://arxiv.org/abs/ 2301.12597
Pith/arXiv arXiv 2023
-
[9]
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin. Emerging properties in self-supervised vision transformers, 2021. URLhttps://arxiv.org/abs/ 2104.14294
Pith/arXiv arXiv 2021
-
[10]
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
Pith/arXiv arXiv 2025
-
[11]
E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Herzog, A. Ir- pan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakrishna, A. Wahid, B....
Pith/arXiv arXiv 2025
-
[12]
K. Grauman, A. Westbury, E. Byrne, Z. Chavis, A. Furnari, R. Girdhar, J. Hamburger, H. Jiang, M. Liu, X. Liu, M. Martin, T. Nagarajan, I. Radosavovic, S. K. Ramakrishnan, F. Ryan, J. Sharma, M. Wray, M. Xu, E. Z. Xu, C. Zhao, S. Bansal, D. Batra, V . Cartillier, S. Crane, T. Do, M. Doulaty, A. Erapalli, C. Feichtenhofer, A. Fragomeni, Q. Fu, A. Gebreselas...
arXiv 2022
-
[13]
D. Shan, J. Geng, M. Shu, and D. Fouhey. Understanding human hands in contact at internet scale. 2020
2020
-
[14]
Damen, H
D. Damen, H. Doughty, G. M. Farinella, S. Fidler, A. Furnari, E. Kazakos, D. Moltisanti, J. Munro, T. Perrett, W. Price, and M. Wray. Scaling egocentric vision: The epic-kitchens dataset. InEuropean Conference on Computer Vision (ECCV), 2018
2018
-
[15]
S. Nair, A. Rajeswaran, V . Kumar, C. Finn, and A. Gupta. R3m: A universal visual represen- tation for robot manipulation, 2022. URLhttps://arxiv.org/abs/2203.12601. 11
Pith/arXiv arXiv 2022
-
[16]
T. Xiao, I. Radosavovic, T. Darrell, and J. Malik. Masked visual pre-training for motor control,
-
[17]
URLhttps://arxiv.org/abs/2203.06173
-
[18]
M. Tschannen, A. Gritsenko, X. Wang, M. F. Naeem, I. Alabdulmohsin, N. Parthasarathy, T. Evans, L. Beyer, Y . Xia, B. Mustafa, O. H´enaff, J. Harmsen, A. Steiner, and X. Zhai. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense features, 2025. URLhttps://arxiv.org/abs/2502.14786
Pith/arXiv arXiv 2025
-
[19]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URLhttps: //qwen.ai/blog?id=qwen3.5
2026
-
[20]
Y . Lipman, R. T. Q. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling, 2023. URLhttps://arxiv.org/abs/2210.02747
Pith/arXiv arXiv 2023
-
[21]
J. Romero, D. Tzionas, and M. J. Black. Embodied hands: modeling and capturing hands and bodies together.ACM Transactions on Graphics, 36(6):1–17, Nov. 2017. ISSN 1557-7368. doi:10.1145/3130800.3130883. URLhttp://dx.doi.org/10.1145/3130800.3130883
-
[22]
Z. Tong, Y . Song, J. Wang, and L. Wang. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training, 2022. URLhttps://arxiv.org/abs/2203. 12602
2022
-
[23]
A. Majumdar, K. Yadav, S. Arnaud, Y . J. Ma, C. Chen, S. Silwal, A. Jain, V .-P. Berges, P. Abbeel, J. Malik, D. Batra, Y . Lin, O. Maksymets, A. Rajeswaran, and F. Meier. Where are we in the search for an artificial visual cortex for embodied intelligence?, 2023. URL https://arxiv.org/abs/2303.18240
arXiv 2023
-
[24]
Levine, C
S. Levine, C. Finn, T. Darrell, and P. Abbeel. End-to-end training of deep visuomotor policies,
-
[25]
URLhttps://arxiv.org/abs/1504.00702
-
[26]
C. Finn, X. Y . Tan, Y . Duan, T. Darrell, S. Levine, and P. Abbeel. Deep spatial autoencoders for visuomotor learning, 2016. URLhttps://arxiv.org/abs/1509.06113
Pith/arXiv arXiv 2016
-
[27]
R. Rahmatizadeh, P. Abolghasemi, L. B ¨ol¨oni, and S. Levine. Vision-based multi-task ma- nipulation for inexpensive robots using end-to-end learning from demonstration, 2018. URL https://arxiv.org/abs/1707.02920
Pith/arXiv arXiv 2018
-
[28]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. De- hghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale, 2021. URLhttps: //arxiv.org/abs/2010.11929
Pith/arXiv arXiv 2021
-
[29]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, T. Jackson, S. Jesmonth, N. J. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, K.-H. Lee, S. Levine, Y . Lu, U. Malla, D. Man- junath, I. Mordatch, O. Nachum, C. Parada, J. Peralta, E. Perez, K. Pertsc...
Pith/arXiv arXiv 2023
-
[30]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, P. Florence, C. Fu, M. G. Arenas, K. Gopalakrishnan, K. Han, K. Hausman, A. Herzog, J. Hsu, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, I. Leal, L. Lee, T.-W. E. Lee, S. Levine, Y . Lu, H. Michalewski, I. Mordatch, K. Pe...
Pith/arXiv arXiv 2023
-
[31]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Haus- man, B. Ichter, S. Jakubczak, T. Jones, L. Ke, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, L. X. Shi, J. Tanner, Q. Vuong, A. Walling, H. Wang, and U. Zhilinsky.π 0: A vision-language-action flow model for general robot control, 2026. URLhttps://arxiv. o...
Pith/arXiv arXiv 2026
-
[32]
Intelligence, K
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, M. Y . Galliker, D. Ghosh, L. Groom, K. Hausman, B. Ichter, S. Jakubczak, T. Jones, L. Ke, D. LeBlanc, S. Levine, A. Li-Bell, M. Mothukuri, S. Nair, K. Pertsch, A. Z. Ren, L. X. Shi, L. Smith, J. T. Springenberg, K. Stachowicz, J. Tanner, Q. V...
-
[33]
X. Wang, I. Alabdulmohsin, D. Salz, Z. Li, K. Rong, and X. Zhai. Scaling pre-training to one hundred billion data for vision language models, 2025. URLhttps://arxiv.org/abs/ 2502.07617
Pith/arXiv arXiv 2025
-
[34]
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[35]
NVIDIA, :, J. Bjorck, F. Casta ˜neda, N. Cherniadev, X. Da, R. Ding, L. J. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, J. Jang, Z. Jiang, J. Kautz, K. Kundalia, L. Lao, Z. Li, Z. Lin, K. Lin, G. Liu, E. Llontop, L. Magne, A. Mandlekar, A. Narayan, S. Nasiriany, S. Reed, Y . L. Tan, G. Wang, Z. Wang, J. Wang, Q. Wang, J. Xiang, Y . Xie, Y . Xu, Z. Xu, S. Ye, Z...
Pith/arXiv arXiv 2025
-
[36]
Beyer, A
L. Beyer, A. Steiner, A. S. Pinto, A. Kolesnikov, X. Wang, D. Salz, M. Neumann, I. Al- abdulmohsin, M. Tschannen, E. Bugliarello, T. Unterthiner, D. Keysers, S. Koppula, F. Liu, A. Grycner, A. Gritsenko, N. Houlsby, M. Kumar, K. Rong, J. Eisenschlos, R. Kabra, M. Bauer, M. Boˇsnjak, X. Chen, M. Minderer, P. V oigtlaender, I. Bica, I. Balazevic, J. Puigcer...
2024
-
[37]
Z. Li, G. Chen, S. Liu, S. Wang, V . VS, Y . Ji, S. Lan, H. Zhang, Y . Zhao, S. Radhakrishnan, N. Chang, K. Sapra, A. S. Deshmukh, T. Rintamaki, M. Le, I. Karmanov, L. V oegtle, P. Fischer, D.-A. Huang, T. Roman, T. Lu, J. M. Alvarez, B. Catanzaro, J. Kautz, A. Tao, G. Liu, and Z. Yu. Eagle 2: Building post-training data strategies from scratch for fronti...
arXiv 2025
- [38]
-
[40]
I. Radosavovic, T. Xiao, S. James, P. Abbeel, J. Malik, and T. Darrell. Real-world robot learn- ing with masked visual pre-training, 2022. URLhttps://arxiv.org/abs/2210.03109
arXiv 2022
-
[41]
M. K. Srirama, S. Dasari, S. Bahl, and A. Gupta. Hrp: Human affordances for robotic pre- training, 2024. URLhttps://arxiv.org/abs/2407.18911
arXiv 2024
-
[42]
S. Ye, J. Jang, B. Jeon, S. Joo, J. Yang, B. Peng, A. Mandlekar, R. Tan, Y .-W. Chao, B. Y . Lin, L. Liden, K. Lee, J. Gao, L. Zettlemoyer, D. Fox, and M. Seo. Latent action pretraining from videos, 2025. URLhttps://arxiv.org/abs/2410.11758. 13
Pith/arXiv arXiv 2025
-
[43]
Y . Chen, Y . Ge, W. Tang, Y . Li, Y . Ge, M. Ding, Y . Shan, and X. Liu. Moto: Latent mo- tion token as the bridging language for learning robot manipulation from videos, 2025. URL https://arxiv.org/abs/2412.04445
arXiv 2025
-
[44]
W. Dai, K. Lan, J. Zhou, B. Zhao, X. Su, J. Tong, W. Guan, and S. Yang. Conla: Contrastive latent action learning from human videos for robotic manipulation, 2026. URLhttps:// arxiv.org/abs/2602.00557
arXiv 2026
-
[45]
Q. Bu, Y . Yang, J. Cai, S. Gao, G. Ren, M. Yao, P. Luo, and H. Li. Univla: Learning to act anywhere with task-centric latent actions, 2025. URLhttps://arxiv.org/abs/2505. 06111
2025
- [46]
- [47]
-
[48]
S.-W. Lee, X. Kang, B. Yang, and Y .-L. Kuo. Class: Contrastive learning via action sequence supervision for robot manipulation, 2025. URLhttps://arxiv.org/abs/2508.01600
arXiv 2025
-
[49]
T. Kim, J. Lee, M. Koo, D. Kim, K. Lee, C. Kim, Y . Seo, and J. Shin. Contrastive representation regularization for vision-language-action models, 2025. URLhttps://arxiv.org/abs/ 2510.01711
Pith/arXiv arXiv 2025
-
[50]
I.-C. A. Liu, K. Choromanski, S. Huang, and C. Schenck. Clamp: Contrastive learning for 3d multi-view action-conditioned robotic manipulation pretraining, 2026. URLhttps:// arxiv.org/abs/2602.00937
Pith/arXiv arXiv 2026
-
[51]
W. Wang, J. Li, Y . Zhu, Z. Xu, Z. Che, Y . Peng, C. Shen, D. Liu, F. Feng, and J. Tang. Visual robotic manipulation with depth-aware pretraining, 2024. URLhttps://arxiv.org/abs/ 2401.09038
arXiv 2024
-
[52]
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski. Vision transformers need registers, 2024. URLhttps://arxiv.org/abs/2309.16588
Pith/arXiv arXiv 2024
-
[53]
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, X. Yuan, P. Xie, Z. Huang, R. Chen, and H. Su. Maniskill2: A unified benchmark for generalizable manipulation skills. InInternational Conference on Learning Representations, 2023
2023
-
[54]
Caron, Y
S. Caron, Y . De Mont-Marin, R. Budhiraja, S. H. Bang, I. Domrachev, S. Nedelchev, P. Du, A. Escande, J. Vaillant, B. Wingo, S. Patapati, D. San Jos ´e Pro, and N. G. Marticorena Vidal. Pink: Python inverse kinematics based on Pinocchio, 2026. URLhttps://github.com/ stephane-caron/pink
2026
-
[55]
Carpentier, G
J. Carpentier, G. Saurel, G. Buondonno, J. Mirabel, F. Lamiraux, O. Stasse, and N. Mansard. The Pinocchio C++ library – A fast and flexible implementation of rigid body dynamics al- gorithms and their analytical derivatives. InSII 2019 - International Symposium on System Integrations, Paris, France, Jan. 2019. URLhttps://hal.laas.fr/hal-01866228
2019
-
[56]
J. A. E. Andersson, J. Gillis, G. Horn, J. B. Rawlings, and M. Diehl. CasADi – A software framework for nonlinear optimization and optimal control.Mathematical Programming Com- putation, 11(1):1–36, 2019. doi:10.1007/s12532-018-0139-4
-
[57]
R. Hoque, P. Huang, D. J. Yoon, M. Sivapurapu, and J. Zhang. Egodex: Learning dexter- ous manipulation from large-scale egocentric video, 2025. URLhttps://arxiv.org/abs/ 2505.11709. 14
Pith/arXiv arXiv 2025
-
[58]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks, 2020. URLhttps://arxiv.org/abs/1812.07035
arXiv 2020
-
[59]
Pour the almonds from the filled cup to the empty cup
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware, 2023. URLhttps://arxiv.org/abs/2304.13705. 15 Appendix A Additional Experiments A.1 Saliency Visualization Details The visualizations in Figure 1 (left) and the per-encoder comparison in Figure 4 are computed us- ing each encoder’s native que...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.