GeneralVLA-2: Geometry-Aware Reconstruction and Governed Memory for Robot Planning
Pith reviewed 2026-06-27 01:51 UTC · model grok-4.3
The pith
Geometry-prior multi-view reconstruction and governed memory enable more reliable robot trajectory planning in vision-language-action systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
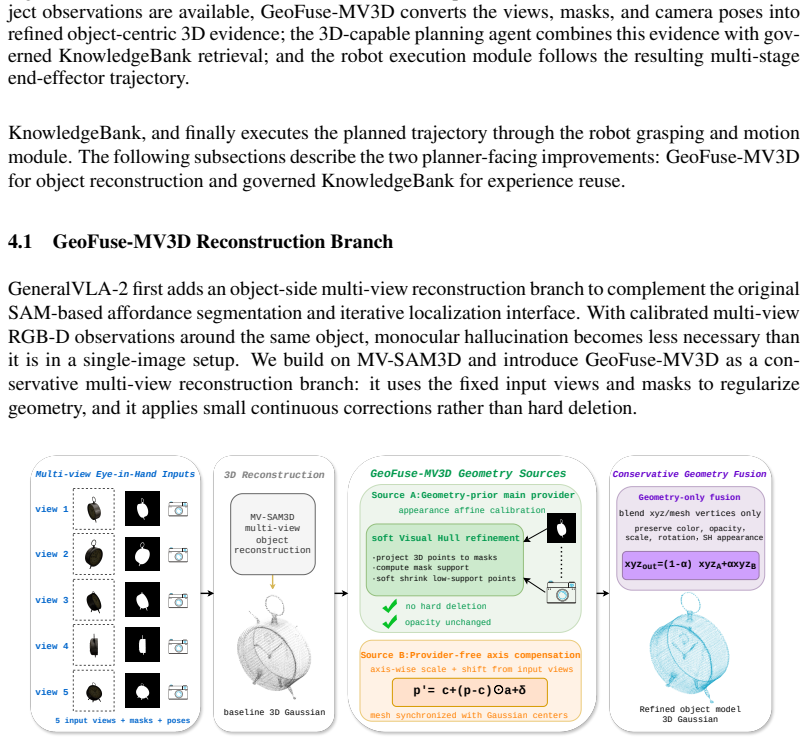
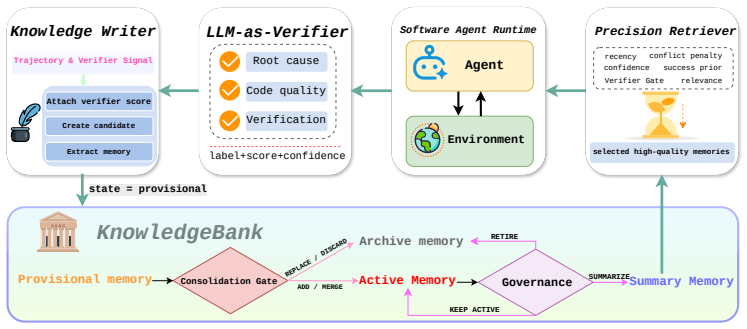
We address the bottlenecks in GeneralVLA by adding GeoFuse-MV3D, a geometry-prior-guided MV-SAM3D branch that verifies external geometry cues with input-view masks, applies soft visual-hull support, performs axis-wise refinement, and fuses only geometry while preserving appearance, and by converting KnowledgeBank into a governed long-term memory with explicit quality, confidence, lifecycle, verifier, and conflict metadata together with precision-oriented retrieval. On GSO-30, GeoFuse-MV3D reduces CD and LPIPS by 2.20% and 2.02% while raising PSNR and SSIM by 2.36% and 1.03% over MV-SAM3D; on Terminal-Bench 2.0 and SWE-Bench Verified the governed memory raises SR by 4.53% and resolve rate by
What carries the argument
GeoFuse-MV3D, the geometry-prior-guided MV-SAM3D reconstruction branch that verifies external cues against input-view masks and fuses geometry only, together with the governed KnowledgeBank that stores explicit metadata for quality, confidence, lifecycle, verifier, and conflict and uses precision-oriented retrieval.
If this is right
- GeoFuse-MV3D produces lower Chamfer Distance and LPIPS and higher PSNR and SSIM than the MV-SAM3D baseline on GSO-30.
- The governed KnowledgeBank raises success rate on Terminal-Bench by 4.53% and resolve rate on SWE-Bench by 3.73% while lowering AS.
- Stable object shapes from multi-view fusion support more reliable end-effector paths for manipulation.
- Metadata controls on memory reduce conflicts and improve geometric relevance of retrieved snippets during planning.
Where Pith is reading between the lines
- The same verification approach could apply to other multi-view reconstruction pipelines where priors must be checked against observations.
- Governed memory with lifecycle and conflict metadata may scale better than simple append-and-retrieve systems for long-horizon robot tasks.
- Tighter integration of the reconstruction output directly into the memory verifier could further reduce downstream planning errors.
Load-bearing premise
Calibrated multi-view observations are available and let the geometry priors verify and refine shapes without adding new hallucinations or biases from the priors.
What would settle it
A controlled test on scenes with known ground-truth shapes that supplies calibrated multi-view inputs yet shows no reduction in reconstruction error or an increase in new artifacts would falsify the benefit of GeoFuse-MV3D.
Figures






read the original abstract
Generalist vision-language-action systems need object-centric 3D evidence and reusable manipulation experience to plan reliable robot trajectories. GeneralVLA provides a hierarchical interface for converting language and RGB-D observations into 3D end-effector paths, but two bottlenecks remain. First, monocular SAM3D-style object reconstruction can hallucinate pose and unseen geometry, while manipulation benefits from stable object shape when calibrated multi-view observations are available. Second, the original KnowledgeBank mainly retrieves semantically similar snippets and appends new knowledge, which makes it difficult to control memory quality, conflicts, confidence, and geometric relevance. To address the first challenge, we introduce GeoFuse-MV3D, a geometry-prior-guided MV-SAM3D reconstruction branch that verifies external geometry cues with input-view masks, applies soft visual-hull support, performs axis-wise refinement, and fuses only geometry while preserving appearance. To address the second challenge, we upgrade KnowledgeBank into a governed long-term memory system with explicit quality, confidence, lifecycle, verifier, and conflict metadata, together with precision-oriented retrieval. Finally, we evaluate the reconstruction branch on GSO-30 and the memory module on Terminal-Bench 2.0 and SWE-Bench Verified; GeoFuse-MV3D improves over the MV-SAM3D baseline by reducing CD and LPIPS by 2.20% and 2.02% while increasing PSNR and SSIM by 2.36% and 1.03%, and KnowledgeBank improves over ReasoningBank by 4.53% on Terminal-Bench SR and 3.73% on SWE-Bench resolve rate, while reducing AS by 4.95% and 5.65%, respectively. Code: https://github.com/AIGeeksGroup/GeneralVLA-2. Website: https://aigeeksgroup.github.io/GeneralVLA-2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GeneralVLA-2, extending prior GeneralVLA work for vision-language-action robot planning. It proposes GeoFuse-MV3D, a geometry-prior-guided multi-view reconstruction branch that verifies cues via input-view masks, soft visual-hull, and axis-wise refinement before fusing geometry while preserving appearance. It also upgrades KnowledgeBank to a governed memory system with explicit quality, confidence, lifecycle, verifier, and conflict metadata plus precision-oriented retrieval. Evaluations report that GeoFuse-MV3D reduces CD and LPIPS by 2.20% and 2.02% while increasing PSNR and SSIM by 2.36% and 1.03% over MV-SAM3D on GSO-30, and the governed memory improves Terminal-Bench SR by 4.53% and SWE-Bench resolve rate by 3.73% while reducing AS by 4.95% and 5.65% over ReasoningBank.
Significance. If the modest metric gains can be shown to arise specifically from geometry-prior verification without introducing new biases or hallucinations, the work would provide a practical hierarchical interface for stable 3D object evidence and controlled long-term memory in manipulation planning. The explicit metadata and conflict handling in the memory module address a clear limitation of semantic-retrieval banks. However, the small effect sizes and absence of isolating controls make the practical significance uncertain without further validation.
major comments (2)
- [Abstract] Abstract: the headline claim that calibrated multi-view observations plus geometry priors refine shapes without new hallucinations or biases rests on aggregate 2% metric deltas versus MV-SAM3D on GSO-30, yet no ablation isolates prior quality, no conflict cases are reported, and no variance or statistical significance is mentioned; this leaves open that gains may derive from fusion mechanics alone.
- [Abstract] Abstract: the description of verification via input-view masks, soft visual-hull support, and axis-wise refinement does not address how prior quality is assessed or how conflicts between priors and observations are resolved, so the risk that priors silently degrade unseen geometry remains untested.
minor comments (1)
- [Abstract] The abstract states evaluation on Terminal-Bench 2.0 and SWE-Bench Verified but provides no details on task selection, number of runs, or baseline implementation; these should be added for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments on the abstract below, agreeing that the claims require clarification given the modest aggregate gains and lack of isolating experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that calibrated multi-view observations plus geometry priors refine shapes without new hallucinations or biases rests on aggregate 2% metric deltas versus MV-SAM3D on GSO-30, yet no ablation isolates prior quality, no conflict cases are reported, and no variance or statistical significance is mentioned; this leaves open that gains may derive from fusion mechanics alone.
Authors: We agree the abstract phrasing is too strong. The reported deltas are aggregate metrics on GSO-30 with no ablations separating geometry-prior verification from fusion mechanics, no conflict cases, and no variance or significance tests. We will revise the abstract to describe the observed metric changes without asserting isolation of effects or absence of biases/hallucinations, and add a limitations paragraph noting these gaps. revision: yes
-
Referee: [Abstract] Abstract: the description of verification via input-view masks, soft visual-hull support, and axis-wise refinement does not address how prior quality is assessed or how conflicts between priors and observations are resolved, so the risk that priors silently degrade unseen geometry remains untested.
Authors: The method section outlines the verification steps, but we concur that explicit mechanisms for assessing prior quality, resolving prior-observation conflicts, and testing for degradation of unseen geometry are not detailed or evaluated. We will expand the relevant method description and add a note on this untested risk as a limitation in the revision. revision: yes
Circularity Check
No circularity: empirical results on external benchmarks
full rationale
The paper introduces GeoFuse-MV3D reconstruction and a governed KnowledgeBank memory system, then reports concrete metric improvements (CD, LPIPS, PSNR, SSIM on GSO-30; SR, resolve rate, AS on Terminal-Bench and SWE-Bench) versus named baselines. These are presented as measured outcomes on independent test sets with no equations, first-principles derivations, fitted-parameter predictions, or self-citation chains that reduce the claimed gains to the inputs by construction. The methods are described procedurally (masks, visual-hull, axis-wise refinement, metadata fields) without any step that equates a result to its own definition or fit.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards multi-layered 3d garments animation
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. Berg, W.-Y . Lo, et al. Segment anything. InIEEE International Conference on Computer Vision, pages 3992–4003. IEEE, 2023. doi:10.1109/ICCV51070.2023.00371
-
[2]
G. Ma, S. Wang, Z. Zhang, S. Yu, and H. Tang. Generalvla: Generalizable vision-language- action models with knowledge-guided trajectory planning, 2026
2026
-
[3]
S. Team, X. Chen, F.-J. Chu, P. Gleize, K. J. Liang, A. Sax, H. Tang, W. Wang, M. Guo, T. Hardin, et al. Sam 3d: 3dfy anything in images, 2025
2025
-
[4]
A. Laurentini. The visual hull concept for silhouette-based image understanding. InIEEE Transactions on Pattern Analysis and Machine Intelligence, volume 16, pages 150–162. Insti- tute of Electrical and Electronics Engineers (IEEE), 1994. doi:10.1109/34.273735
-
[5]
W. Feng, M. Wu, Z. Chen, C. Yang, H. Qin, Y . Li, X. Liu, G. Fan, Z. An, L. Huang, et al. Fast-sam3d: 3dfy anything in images but faster, 2026
2026
-
[6]
B. Li, D. Wu, J. Li, S. Zhou, L. Li, Z. Zeng, and H. Zha. Mv-sam3d: Adaptive multi-view fusion for layout-aware 3d generation, 2026
2026
-
[7]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual geometry grounded transformer. InComputer Vision and Pattern Recognition, pages 5294–
-
[8]
Video-bench: Human-aligned video generation benchmark
IEEE, 2025. doi:10.1109/CVPR52734.2025.00499
-
[9]
Brohan, N
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, K. Choromanski, T. Ding, D. Driess, K. A. Dubey, C. Finn, P. R. Florence, et al. Rt-2: Vision-language-action models transfer web knowl- edge to robotic control, 2023
2023
-
[10]
O. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy, 2024
2024
-
[11]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model, 2024
2024
-
[12]
Black, N
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π 0: A vision-language-action flow model for general robot control, 2024
2024
-
[13]
J. Wen, Y . Zhu, J. Li, M. Zhu, K. Wu, Z. Xu, N. Liu, R. Cheng, C. Shen, Y . Peng, et al. Tinyvla: Towards fast, data-efficient vision-language-action models for robotic manipulation, 2024
2024
-
[14]
V2xp-asg: Generating adversarial scenes for vehicle-to-everything perception
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. R. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. InIEEE International Confer- ence on Robotics and Automation, pages 9493–9500, 2022. doi:10.1109/ICRA48891.2023. 10160591. 9
-
[15]
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models. InConference on Robot Learning, pages 540–562, 2023. doi:10.48550/arXiv.2307.05973
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2307.05973 2023
-
[16]
J. Duan, W. Yuan, W. Pumacay, Y . R. Wang, K. Ehsani, D. Fox, and R. Krishna. Manipulate- anything: Automating real-world robots using vision-language models, 2024
2024
-
[17]
Zheng, R
L. Zheng, R. Wang, X. Wang, and B. An. Synapse: Trajectory-as-exemplar prompting with memory for computer control, 2023
2023
-
[18]
Z. Z. Wang, J. Mao, D. Fried, and G. Neubig. Agent workflow memory, 2024
2024
-
[19]
Ouyang, J
S. Ouyang, J. Yan, I.-H. Hsu, Y . Chen, K. Jiang, Z. Wang, R. Han, L. T. Le, S. Daruki, X. Tang, et al. Reasoningbank: Scaling agent self-evolving with reasoning memory, 2025
2025
-
[20]
J. Gu, X. Jiang, Z. Shi, H. Tan, X. Zhai, C. Xu, W. Li, Y . Shen, S. Ma, H. Liu, et al. A survey on llm-as-a-judge, 2024
2024
-
[21]
J. Kwok, S. Li, P. Atreya, Y . Liu, M. Pavone, I. Stoica, and A. Mirhoseini. Llm-as-a-verifier: A general-purpose verification framework, 2026. Notion Blog
2026
-
[22]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimkuehler, and G. Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4):1–14, 2023. doi:10.1145/ 3592433
2023
-
[23]
L. Downs, A. Francis, N. Koenig, B. Kinman, R. Hickman, K. Reymann, T. B. McHugh, and V . Vanhoucke. Google scanned objects: A high-quality dataset of 3d scanned household items.IEEE International Conference on Robotics and Automation, pages 2553–2560, 2022. doi:10.48550/arXiv.2204.11918
-
[24]
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600– 612, 2004. doi:10.1109/TIP.2003.819861
-
[25]
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 586–595. IEEE, 2018. doi:10.1109/CVPR.2018.00068
-
[26]
M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, J. Shin, T. Wal- she, E. K. Buchanan, et al. Terminal-bench: Benchmarking agents on hard, realistic tasks in command line interfaces, 2026
2026
-
[27]
C. E. Jimenez, J. Yang, A. Wettig, S. Yao, K. Pei, O. Press, and K. R. Narasimhan. SWE- bench: Can language models resolve real-world github issues? InInternational Confer- ence on Learning Representations, 2023. doi:10.48550/arXiv.2310.06770. URLhttps: //openreview.net/forum?id=VTF8yNQM66
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06770 2023
-
[28]
SWE-bench Verified.https://openai.com/index/ introducing-swe-bench-verified/, 2024
OpenAI. SWE-bench Verified.https://openai.com/index/ introducing-swe-bench-verified/, 2024. Accessed 2026-05-29
2024
-
[29]
S. James, Z. Ma, D. R. Arrojo, and A. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2019. doi: 10.1109/LRA.2020.2974707
-
[30]
Y . Li, Y . Deng, J. Zhang, J. Jang, M. Memmel, C. R. Garrett, F. Ramos, D. Fox, A. Li, A. Gupta, et al. HAMSTER: hierarchical action models for open-world robot manipulation. InInterna- tional Conference on Learning Representations, 2025. doi:10.48550/arXiv.2502.05485
-
[31]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
A. Suma and S. Dauncey. Deepseek-r1: Incentivizing reasoning capability in llms via rein- forcement learning.arXiv.org, 2025. doi:10.48550/arXiv.2501.12948. 10
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[32]
I. Sucan, M. Moll, and L. Kavraki. The open motion planning library.IEEE Robotics & Automation Magazine, 19(4):72–82, 2012. doi:10.1109/MRA.2012.2205651
-
[33]
Intelligence, K
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al.π 0.5: a vision-language-action model with open-world generalization, 2025
2025
-
[34]
W. Yuan, J. Duan, V . Blukis, W. Pumacay, R. Krishna, A. Murali, A. Mousavian, and D. Fox. Robopoint: A vision-language model for spatial affordance prediction in robotics. InConfer- ence on Robot Learning, pages 4005–4020, 2024
2024
-
[35]
Qwen3.5: Towards native multimodal agents, February 2026
Qwen Team. Qwen3.5: Towards native multimodal agents, February 2026. URLhttps: //qwen.ai/blog?id=qwen3.5
2026
-
[36]
Gemini 3 Flash model card
Google DeepMind. Gemini 3 Flash model card. Model card, Google DeepMind, Decem- ber 2025. URLhttps://storage.googleapis.com/deepmind-media/Model-Cards/ Gemini-3-Flash-Model-Card.pdf. Updated December 17, 2025. Accessed: 2026-05-12
2025
-
[37]
Gemini 3.1 Pro model card
Google DeepMind. Gemini 3.1 Pro model card. Model card, Google DeepMind, Febru- ary 2026. URLhttps://storage.googleapis.com/deepmind-media/Model-Cards/ Gemini-3-1-Pro-Model-Card.pdf. Updated February 19, 2026. Accessed: 2026-05-12. 11 Appendix A Additional GeoFuse-MV3D Evaluation This appendix collects the complete GeoFuse-MV3D reconstruction evidence: th...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.