Trustworthy Self-Composable Big-Data-as-a-Service: An LLM-Orchestrated Multi-Agent Framework for Automated Data Engineering, AutoML, MLOps Deployment, and Drift-Aware Lifecycle Optimization
Pith reviewed 2026-06-26 22:05 UTC · model grok-4.3
The pith
LLM-orchestrated multi-agent system automates full BDaaS lifecycle with better reliability than baselines.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
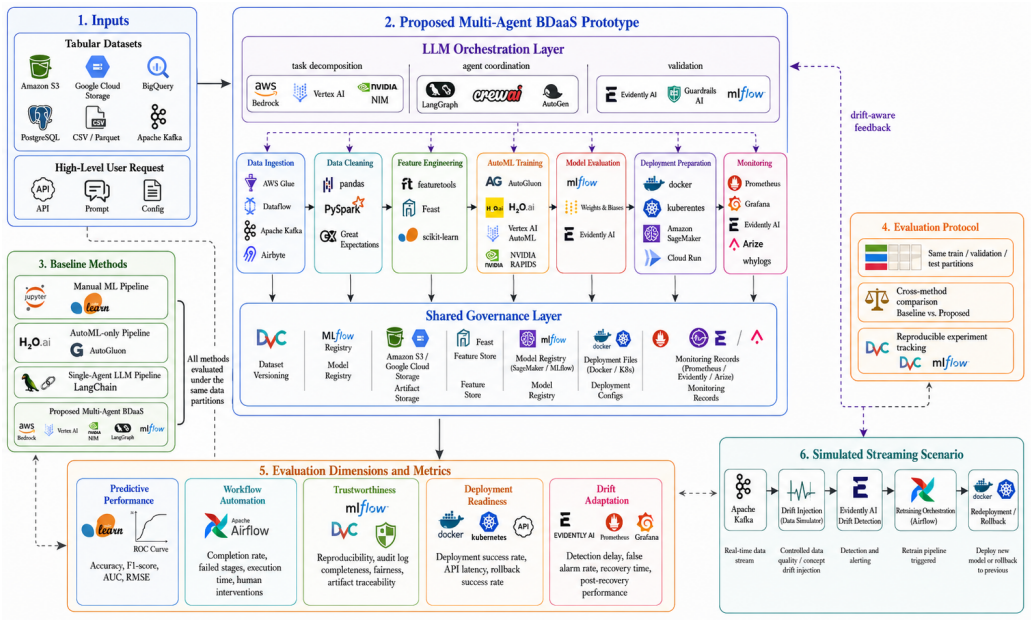
The proposed trustworthy self-composable BDaaS framework uses LLM-orchestrated multi-agent collaboration to decompose the lifecycle into specialized agents coordinated by a central LLM layer. This setup enables dynamic workflow composition, artifact governance, human oversight, and drift-aware feedback loops. On benchmark tabular datasets, the system achieves competitive predictive performance while improving lifecycle reliability metrics including workflow completion, artifact traceability, deployment readiness, reproducibility, and drift recovery over manual ML, AutoML-only, and single-agent LLM baselines.
What carries the argument
The central LLM orchestration layer that coordinates specialized agents for each lifecycle stage, validates intermediate outputs, manages workflow context, and enables dynamic composition.
If this is right
- The framework extends AutoML to full lifecycle support with drift adaptation.
- Shared artifact governance enhances reproducibility and traceability.
- Human-in-the-loop checkpoints integrate oversight into automated workflows.
- Drift-aware feedback loops allow post-deployment optimization without full restarts.
- Prototype results indicate feasibility for production-oriented BDaaS on tabular data.
Where Pith is reading between the lines
- If the coordination holds, this approach could scale to more complex data types beyond tabular benchmarks.
- Organizations might use it to lower the expertise barrier for maintaining reliable ML pipelines.
- Testing on real-world streaming data with actual drift could reveal additional adaptation needs.
- Combining this with existing cloud BDaaS platforms may accelerate adoption of automated lifecycle management.
Load-bearing premise
The central LLM can coordinate multiple agents, validate their outputs, and manage dynamic workflows without frequent errors or requiring constant human fixes.
What would settle it
An experiment showing that the multi-agent pipeline has lower workflow completion rates or fails to recover from drift more often than single-agent LLM systems on the same benchmark datasets with missing values and simulated drift.
Figures


read the original abstract
Big-Data-as-a-Service (BDaaS) platforms require re liable automation across data ingestion, cleaning, feature engi neering, model development, deployment, and post-deployment monitoring. However, existing LLM-based data science agents and AutoML systems mainly focus on isolated workflow stages, leaving limited support for lifecycle-level orchestration, artifact governance, human oversight, and drift-aware adaptation. This paper proposes a trustworthy self-composable BDaaS frame work based on LLM-orchestrated multi-agent collaboration. The proposed architecture decomposes the BDaaS lifecycle into specialized agents for data ingestion, data cleaning, feature engineering, AutoML training, model evaluation, MLOps de ployment, monitoring, and drift detection. A central LLM or chestration layer coordinates agent execution, validates interme diate outputs, manages workflow context, and enables dynamic workflow composition. The framework also incorporates shared artifact governance, reproducibility support, human-in-the-loop checkpoints, and drift-aware feedback loops. A prototype-based evaluation is conducted using controlled tabular benchmark datasets with missing values, categorical variables, outliers, class imbalance, and simulated covariate drift. Compared with manual ML, AutoML-only, and single-agent LLM baselines, the pro posed multi-agent BDaaS pipeline achieves competitive predictive performance while improving lifecycle-level reliability, including workflow completion, artifact traceability, deployment readiness, reproducibility, and drift recovery. The results suggest that LLM-orchestrated multi-agent systems can extend conventional AutoML toward trustworthy, adaptive, and production-oriented BDaaS lifecycle automation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an LLM-orchestrated multi-agent framework for Big-Data-as-a-Service (BDaaS) that decomposes the data lifecycle into specialized agents for ingestion, cleaning, feature engineering, AutoML, deployment, monitoring, and drift detection. A central orchestration layer manages coordination, validation, and dynamic composition, with added governance, reproducibility, and human-in-the-loop features. Prototype evaluation on controlled tabular datasets with various issues claims competitive predictive performance and superior lifecycle reliability compared to manual, AutoML, and single-agent baselines.
Significance. If the empirical claims are substantiated with detailed metrics, this work could advance multi-agent systems and automated ML by showing how LLM orchestration supports trustworthy, adaptive full-lifecycle BDaaS automation and reduces reliance on manual oversight in production pipelines.
major comments (2)
- [Abstract] Abstract: The abstract asserts that the proposed multi-agent BDaaS pipeline achieves competitive predictive performance while improving lifecycle-level reliability metrics (workflow completion, artifact traceability, deployment readiness, reproducibility, and drift recovery), yet supplies no numerical results, baseline implementation details, or statistical tests. This prevents verification of the central empirical claim.
- [Evaluation] Evaluation section: No quantitative metrics are reported on the reliability of the central LLM orchestration layer itself, such as agent coordination success rates, validation error frequency, number of human interventions, or cases of failed dynamic composition. These are required to substantiate the weakest assumption and to attribute reliability gains to the multi-agent design rather than other factors.
minor comments (1)
- [Abstract] Abstract: Minor formatting/typographical issues appear in the provided text (e.g., 're liable', 'or chestration') that should be corrected.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the empirical presentation. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that the proposed multi-agent BDaaS pipeline achieves competitive predictive performance while improving lifecycle-level reliability metrics (workflow completion, artifact traceability, deployment readiness, reproducibility, and drift recovery), yet supplies no numerical results, baseline implementation details, or statistical tests. This prevents verification of the central empirical claim.
Authors: We agree that the abstract would benefit from numerical highlights to support immediate verification. In the revised version we will incorporate key quantitative results from the prototype evaluation (e.g., specific reliability metric improvements over baselines) while keeping the abstract concise. revision: yes
-
Referee: [Evaluation] Evaluation section: No quantitative metrics are reported on the reliability of the central LLM orchestration layer itself, such as agent coordination success rates, validation error frequency, number of human interventions, or cases of failed dynamic composition. These are required to substantiate the weakest assumption and to attribute reliability gains to the multi-agent design rather than other factors.
Authors: The evaluation reports end-to-end lifecycle outcomes and attributes gains via comparisons against single-agent and AutoML baselines, but does not include the requested internal orchestration-layer metrics. We will add a short discussion of any available proxy indicators (e.g., human-intervention counts) from the prototype logs; however, the specific coordination-success and failure-composition statistics were not instrumented in the original experiments. revision: partial
- Granular quantitative metrics on the central LLM orchestration layer (agent coordination success rates, validation error frequency, failed dynamic composition cases) are not available from the existing prototype evaluation and cannot be supplied without new instrumentation and experiments.
Circularity Check
No circularity: systems description and empirical comparison only
full rationale
The manuscript describes an LLM-orchestrated multi-agent architecture for BDaaS lifecycle automation and reports prototype results on tabular benchmarks. No equations, parameter fits, predictions derived from fitted inputs, or self-citation chains appear anywhere in the text. The central claims rest on direct empirical comparison against manual ML, AutoML, and single-agent baselines rather than any reduction of outputs to the architecture definition itself. The work is therefore self-contained with no load-bearing step that collapses by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs can reliably orchestrate specialized agents, validate their outputs, and manage dynamic workflow composition for data engineering tasks
Reference graph
Works this paper leans on
-
[1]
AutoML-Agent: A Multi- Agent LLM Framework for Full-Pipeline AutoML,
P. Trirat, W. Jeong, and S. J. Hwang, “AutoML-Agent: A Multi- Agent LLM Framework for Full-Pipeline AutoML,” arXiv preprint arXiv:2410.02958, 2025
arXiv 2025
-
[2]
Data Interpreter: An LLM Agent for Data Science,
S. Honget al., “Data Interpreter: An LLM Agent for Data Science,” arXiv preprint arXiv:2402.18679, 2024
arXiv 2024
-
[3]
V . Dibia, “LIDA: A Tool for Automatic Generation of Grammar- Agnostic Visualizations and Infographics using Large Language Mod- els,” arXiv preprint arXiv:2303.02927, 2023
arXiv 2023
-
[4]
Lan Li, Liri Fang, Bertram Lud ¨ascher, and Vetle I Torvik. 2025. Au- toDCWorkflow: LLM-based Data Cleaning Workflow Auto-Generation and Benchmark. In Findings of the Association for Computational Lin- guistics: EMNLP 2025, pages 7766–7780, Suzhou, China. Association for Computational Linguistics
2025
-
[6]
Available: https://arxiv.org/abs/2503.06664
[Online]. Available: https://arxiv.org/abs/2503.06664
-
[7]
Fine-tuning LLMs for automated feature engineering,
Y . Hirose, K. Uchida, and S. Shirakawa, “Fine-tuning LLMs for automated feature engineering,” in AutoML Conference 2024 (Workshop Track), 2024. [Online]. Available: https://openreview.net/forum?id=FqbkgaMf8O
2024
-
[8]
Alhassan Mumuni, Fuseini Mumuni, Automated data processing and feature engineering for deep learning and big data applications: A survey, Journal of Information and Intelligence, V olume 3, Issue 2, 2025, Pages 113-153, ISSN 2949-7159, https://doi.org/10.1016/j.jiixd.2024.01.002
-
[9]
C ˆot´e, PO., Nikanjam, A., Ahmed, N. et al. Data cleaning and machine learning: a systematic literature review. Autom Softw Eng 31, 54 (2024). https://doi.org/10.1007/s10515-024-00453-w
-
[10]
Data-centric artificial intelligence: A survey,
D. Zha, Z. P. Bhat, K.-H. Lai, F. Yang, Z. Jiang, S. Zhong, and X. Hu, “Data-centric artificial intelligence: A survey,” arXiv preprint arXiv:2303.10158, 2023. [Online]. Available: https://arxiv.org/abs/2303.10158
arXiv 2023
-
[11]
DS-Agent: Automated Data Science by Empowering Large Language Models with Case-Based Reasoning,
S. Guo, C. Deng, Y . Wen, H. Chen, Y . Chang, and J. Wang, “DS-Agent: Automated Data Science by Empowering Large Language Models with Case-Based Reasoning,” arXiv preprint arXiv:2402.17453, 2024
arXiv 2024
-
[12]
MLAgentBench: Eval- uating Language Agents on Machine Learning Experimentation,
Q. Huang, J. V ora, P. Liang, and J. Leskovec, “MLAgentBench: Eval- uating Language Agents on Machine Learning Experimentation,” arXiv preprint arXiv:2310.03302, 2023
arXiv 2023
-
[13]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering,
J. S. Chan, N. Chowdhury, O. Jaffe, J. Aung, D. Sherburn, E. Mays, G. Starace, K. Liu, L. Maksin, T. Patwardhan, L. Weng, and A. Madry, “MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering,” arXiv preprint arXiv:2410.07095, 2024
Pith/arXiv arXiv 2024
-
[14]
BudgetMLAgent: A Cost-Effective LLM Multi-Agent System for Automating Machine Learning Tasks,
S. Gandhi, M. Patwardhan, L. Vig, and G. Shroff, “BudgetMLAgent: A Cost-Effective LLM Multi-Agent System for Automating Machine Learning Tasks,” arXiv preprint arXiv:2411.07464, 2024
arXiv 2024
-
[15]
SELA: Tree-Search Enhanced LLM Agents for Automated Machine Learning,
Y . Chiet al., “SELA: Tree-Search Enhanced LLM Agents for Automated Machine Learning,” arXiv preprint arXiv:2410.17238, 2024
arXiv 2024
-
[16]
N. Hollmann, S. Muller, and F. Hutter, “Large Language Models for Automated Data Science: Introducing CAAFE for Context-Aware Au- tomated Feature Engineering,” arXiv preprint arXiv:2305.03403, 2023
arXiv 2023
-
[17]
MatPlotAgent: Method and Evaluation for LLM-Based Agentic Scientific Data Visualization,
Z. Yanget al., “MatPlotAgent: Method and Evaluation for LLM-Based Agentic Scientific Data Visualization,” inFindings of the Association for Computational Linguistics: ACL 2024, 2024
2024
-
[18]
AIDE: AI-Driven Exploration in the Space of Code,
Z. Jiang, D. Schmidt, D. Srikanth, D. Xu, I. Kaplan, D. Jacenko, and Y . Wu, “AIDE: AI-Driven Exploration in the Space of Code,” arXiv preprint arXiv:2502.13138, 2025
Pith/arXiv arXiv 2025
-
[19]
Machine learning operations (MLOps): Overview, definition, and architecture,
D. Kreuzberger, N. Kuhl, and S. Hirschl, “Machine Learning Operations (MLOps): Overview, Definition, and Architecture,”IEEE Access, vol. 11, pp. 31866–31879, 2023, doi: 10.1109/ACCESS.2023.3262138
-
[20]
Data Drift Mitigation in Machine Learning for Large-Scale Online Services,
A. Mallick, K. Hsieh, B. Arzani, and G. Joshi, “Data Drift Mitigation in Machine Learning for Large-Scale Online Services,” inProceedings of Machine Learning and Systems, vol. 4, pp. 649–663, 2022
2022
-
[21]
Hidden Technical Debt in Machine Learning Systems,
D. Sculley, G. Holt, D. Golovin, E. Davydov, T. Phillips, D. Ebner, V . Chaudhary, M. Young, J.-F. Crespo, and D. Dennison, “Hidden Technical Debt in Machine Learning Systems,” inAdvances in Neural Information Processing Systems, vol. 28, pp. 2503–2511, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.