Engagement Intensity as a Learner-Modeling Signal for Adaptive AI Ethics Instruction
Pith reviewed 2026-06-26 21:54 UTC · model grok-4.3
The pith
Self-reported LLM usage frequency associates with all five baseline AI perception outcomes in bioscience trainees, while prior AI education associates with none.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
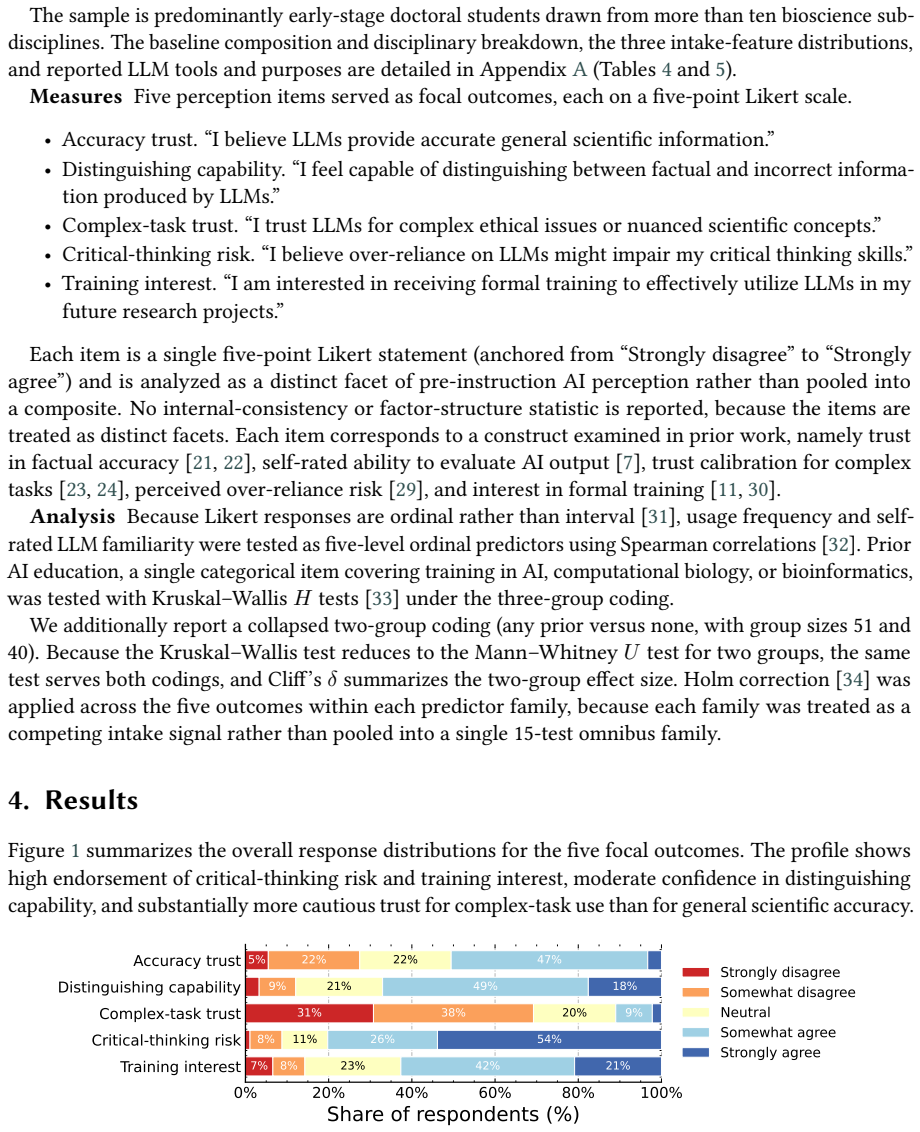
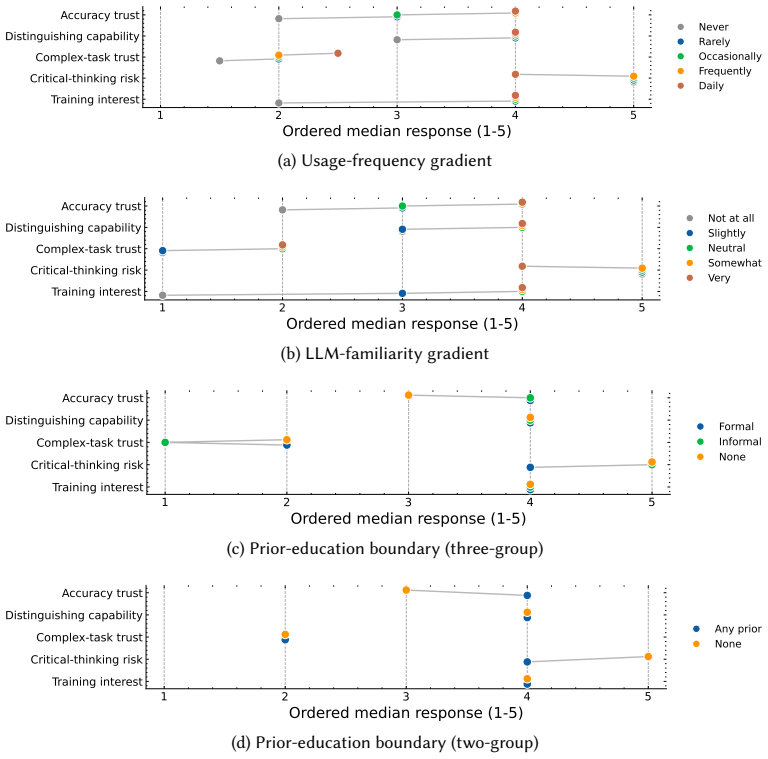
In a required research ethics course, self-reported frequency of LLM use showed Holm-corrected associations with all five measured perception outcomes, self-rated familiarity showed associations with three outcomes, and prior AI education showed associations with none. The pattern was not a uniform gradient; a threshold-like drop at the low end of the usage scale stood out most clearly for training interest and accuracy trust.
What carries the argument
Statistical comparison of three candidate intake features (usage frequency, self-rated familiarity, prior AI education) against five perception outcomes using Holm-corrected associations in a cross-sectional survey.
If this is right
- Usage frequency can function as a primary signal for grouping learners into adaptive AI ethics pathways.
- Prior coursework or workshop attendance is unlikely to serve as a reliable proxy for initial perception differences.
- Self-rated familiarity can act as a secondary indicator when usage data are unavailable.
- Instructional adjustments may need to target low-usage subgroups more than high-usage subgroups for outcomes like training interest.
- Lightweight intake surveys focused on behavior can replace longer educational-history questions in ethics-course design.
Where Pith is reading between the lines
- The same usage signal might inform adaptive modules in non-bioscience fields if the five perception items behave similarly across disciplines.
- Systems could route low-usage learners first to modules on accuracy trust and training interest rather than applying uniform content.
- Longitudinal follow-up could test whether usage-based grouping improves post-instruction shifts in the same perception items.
- If usage frequency remains stable over time, it could support repeated lightweight profiling without re-administering full surveys.
Load-bearing premise
The five perception items are stable and meaningful targets for adaptive instruction, and self-reported usage frequency will keep serving as a useful grouping signal when course content or trainee populations change.
What would settle it
A replication study in a new trainee cohort or with revised course content finds no Holm-corrected associations between reported usage frequency and the same five perception items.
Figures
read the original abstract
Adaptive AI ethics instruction in graduate research training benefits from intake measures that reflect differences in prior LLM experience. Prior coursework or workshop attendance is an obvious candidate, but it is not clear whether it is associated with pre-instruction ratings on key AI perception items. We compare three candidate intake features, self-reported usage frequency, self-rated LLM familiarity, and prior AI education, across five baseline perception outcomes in 93 bioscience graduate and postdoctoral trainees enrolled in a required research ethics course. Usage frequency shows Holm-corrected associations with all five outcomes, self-rated familiarity with three, and prior AI education with none. A threshold-like pattern at the lower end of the scale is most visible for training interest and accuracy trust rather than appearing as a uniform gradient across all five outcomes. In a short intake survey, reported LLM use is more consistently associated with these perceptions than prior coursework or workshops, with self-rated familiarity serving as a secondary indicator. These results suggest that simple pre-instruction behavioral signals can inform lightweight intake profiling for adaptive AI ethics education.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports findings from a cross-sectional survey of 93 bioscience graduate and postdoctoral trainees in a required research ethics course. It compares three candidate intake features—self-reported LLM usage frequency, self-rated familiarity, and prior AI education—against five baseline perception outcomes. The central result is that usage frequency shows Holm-corrected associations with all five outcomes, self-rated familiarity with three, and prior AI education with none. A threshold-like pattern is noted at the lower end of the usage scale for some outcomes. The authors conclude that simple behavioral signals from an intake survey can inform lightweight profiling for adaptive AI ethics instruction.
Significance. If the reported associations replicate, the work supplies an empirical basis for using low-burden intake questions to differentiate prior engagement levels that correlate with AI perceptions in ethics training. The explicit application of Holm correction is a methodological strength that supports the differential pattern (5/5 vs. 3/5 vs. 0/5). The single-sample, cross-sectional design appropriately limits the claims to observed associations rather than causal or stable effects across populations or course variants.
major comments (2)
- [Methods] Methods: the manuscript states that Holm correction was applied but provides no information on the underlying statistical tests (e.g., correlation, chi-squared, or regression), degrees of freedom, handling of missing data, exact wording of the five perception items, or whether any post-hoc thresholds were chosen after inspecting the data. These details are required to evaluate the reported association counts.
- [Results] Results: the threshold-like pattern at the lower end of the usage-frequency scale is described for training interest and accuracy trust, yet no effect sizes, confidence intervals, or per-outcome test statistics are supplied to quantify how distinct this pattern is from the other three outcomes.
minor comments (2)
- [Abstract] Abstract: adding the sample size (n=93) and the cross-sectional design would give readers immediate context for the strength of the claims.
- [Discussion] Discussion: the scoping statement that usage frequency 'can inform' profiling is appropriate, but a short clause clarifying that no stability claims are made across different course content or trainee populations would prevent over-interpretation.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address each major comment point by point below.
read point-by-point responses
-
Referee: [Methods] Methods: the manuscript states that Holm correction was applied but provides no information on the underlying statistical tests (e.g., correlation, chi-squared, or regression), degrees of freedom, handling of missing data, exact wording of the five perception items, or whether any post-hoc thresholds were chosen after inspecting the data. These details are required to evaluate the reported association counts.
Authors: We agree that these details are necessary for a complete evaluation. We will revise the Methods section to include the specific statistical tests used, the degrees of freedom, how missing data were handled, the exact wording of the five perception items, and confirmation that no post-hoc thresholds were chosen after data inspection. revision: yes
-
Referee: [Results] Results: the threshold-like pattern at the lower end of the usage-frequency scale is described for training interest and accuracy trust, yet no effect sizes, confidence intervals, or per-outcome test statistics are supplied to quantify how distinct this pattern is from the other three outcomes.
Authors: The threshold-like pattern is described qualitatively in the manuscript. We will update the Results section to include effect sizes, confidence intervals, and per-outcome test statistics to better quantify the patterns and their distinctiveness. revision: yes
Circularity Check
No circularity: direct statistical associations from survey data
full rationale
The paper reports observed Holm-adjusted associations between three intake variables (usage frequency, familiarity, prior education) and five perception outcomes in a single cross-sectional sample. No equations, fitted parameters, or derivations are present that reduce reported results to quantities defined by the study's own inputs. The central claims consist of direct statistical patterns computed from the data, with no self-citation chains, ansatzes, or renamings that create circularity. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Holm correction is the appropriate method for controlling family-wise error across the five outcomes
- domain assumption Self-reported usage frequency is a reliable proxy for engagement intensity relevant to AI ethics learning
Reference graph
Works this paper leans on
-
[1]
S. Milano, J. A. McGrane, S. Leonelli, Large language models challenge the future of higher education, Nature Machine Intelligence 5 (2023) 333–334. doi:10.1038/s42256-023-00644-2
-
[2]
J. Roberts, M. Baker, J. Andrew, Artificial intelligence and qualitative research: The promise and perils of large language model (LLM) ‘assistance’, Critical Perspectives on Accounting 99 (2024) 102722. doi:10. 1016/j.cpa.2024.102722
arXiv 2024
-
[3]
J. S. Barrot, Using ChatGPT for second language writing: Pitfalls and potentials, Assessing Writing 57 (2023) 100745. doi:10.1016/j.asw.2023.100745
-
[4]
M. Bond, H. Khosravi, M. De Laat, N. Bergdahl, V. Negrea, E. Oxley, P. Pham, S. W. Chong, G. Siemens, A meta systematic review of artificial intelligence in higher education: a call for increased ethics, collaboration, and rigour, International Journal of Educational Technology in Higher Education 21 (2024) 4. doi:10.1186/ s41239-023-00436-z
2024
-
[5]
N. McDonald, A. Johri, A. Ali, A. H. Collier, Generative artificial intelligence in higher education: Evidence from an analysis of institutional policies and guidelines, Computers in Human Behavior: Artificial Humans 3 (2025) 100121. doi:10.1016/j.chbah.2025.100121
-
[6]
M. Usher, M. Barak, Unpacking the role of AI ethics online education for science and engineering students, International Journal of STEM Education 11 (2024) 35. doi:10.1186/s40594-024-00493-4
-
[7]
D. Long, B. Magerko, What is AI Literacy? Competencies and Design Considerations, in: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, CHI ’20, Association for Computing Machinery, New York, NY, USA, 2020, pp. 1–16. doi:10.1145/3313831.3376727
-
[8]
W. Xing, N. Nixon, S. Crossley, P. Denny, A. Lan, J. Stamper, Z. Yu, The Use of Large Language Models in Education, International Journal of Artificial Intelligence in Education 35 (2025) 439–443. doi: 10.1007/ s40593-025-00457-x
2025
-
[9]
D. B. Resnik, M. Hosseini, The ethics of using artificial intelligence in scientific research: new guidance needed for a new tool, AI and Ethics 5 (2025) 1499–1521. doi:10.1007/s43681-024-00493-8
-
[10]
M. Hosseini, D. B. Resnik, K. Holmes, The ethics of disclosing the use of artificial intelligence tools in writing scholarly manuscripts, Research Ethics 19 (2023) 449–465. doi:10.1177/17470161231180449
-
[11]
J. Borenstein, A. Howard, Emerging challenges in AI and the need for AI ethics education, AI and Ethics 1 (2021) 61–65. doi:10.1007/s43681-020-00002-7
-
[12]
URL https://doi.org/10.1016/ j.lindif.2023.102274
E. Kasneci, K. Sessler, S. Küchemann, M. Bannert, D. Dementieva, F. Fischer, U. Gasser, G. Groh, S. Günne- mann, E. Hüllermeier, et al., ChatGPT for good? On opportunities and challenges of large language models for education, Learning and Individual Differences 103 (2023) 102274. doi:10.1016/j.lindif.2023.102274
-
[13]
M. Zou, L. Huang, To use or not to use? Understanding doctoral students’ acceptance of ChatGPT in writing through technology acceptance model, Frontiers in Psychology Volume 14 - 2023 (2023). doi: 10.3389/ fpsyg.2023.1259531
arXiv 2023
-
[14]
W. Suh, Generative AI integration in higher education shifts students’ attitudes from tool use to innovation, Discover Education 4 (2025) 508. doi:10.1007/s44217-025-00914-8
-
[15]
D. Ravšelj, D. Keržič, N. Tomaževič, L. Umek, N. Brezovar, N. A. Iahad, A. A. Abdulla, A. Akopyan, M. W. Aldana Segura, J. AlHumaid, et al., Higher education students’ perceptions of ChatGPT: A global study of early reactions, PLOS ONE 20 (2025) e0315011. doi:10.1371/journal.pone.0315011
-
[16]
Nemt-allah, W
M. Nemt-allah, W. Khalifa, M. Badawy, Y. Elbably, A. Ibrahim, Validating the ChatGPT Usage Scale: psychometric properties and factor structures among postgraduate students, BMC Psychology 12 (2024)
2024
-
[17]
doi:10.1186/s40359-024-01983-4
-
[18]
W. Lyu, S. Zhang, T. Chung, Y. Sun, Y. Zhang, Understanding the practices, perceptions, and (dis)trust of generative AI among instructors: A mixed-methods study in the U.S. higher education, Computers and Education: Artificial Intelligence 8 (2025) 100383. doi:10.1016/j.caeai.2025.100383
-
[19]
S. Kelly, S.-A. Kaye, O. Oviedo-Trespalacios, What factors contribute to the acceptance of artificial intelli- gence? A systematic review, Telematics and Informatics 77 (2023) 101925. doi: 10.1016/j.tele.2022. 101925
-
[20]
Viberg, M
O. Viberg, M. Cukurova, Y. Feldman-Maggor, G. Alexandron, S. Shirai, S. Kanemune, B. Wasson, C. Tømte, D. Spikol, M. Milrad, et al., What Explains Teachers’ Trust in AI in Education Across Six Coun- tries?, International Journal of Artificial Intelligence in Education 35 (2025) 1288–1316. doi: 10.1007/ s40593-024-00433-x
2025
-
[21]
T. Nazaretsky, P. Mejia-Domenzain, V. Swamy, J. Frej, T. Käser, The critical role of trust in adopting AI- powered educational technology for learning: An instrument for measuring student perceptions, Computers and Education: Artificial Intelligence 8 (2025) 100368. doi:10.1016/j.caeai.2025.100368
-
[22]
J. D. Lee, K. A. See, Trust in Automation: Designing for Appropriate Reliance, Human Factors 46 (2004) 50–80. doi:10.1518/hfes.46.1.50_30392
-
[23]
E. Glikson, A. W. Woolley, Human Trust in Artificial Intelligence: Review of Empirical Research, Academy of Management Annals 14 (2020) 627–660. doi:10.5465/annals.2018.0057
-
[24]
S. Mehrotra, C. Degachi, O. Vereschak, C. M. Jonker, M. L. Tielman, A Systematic Review on Fostering Appropriate Trust in Human-AI Interaction: Trends, Opportunities and Challenges, ACM Journal on Responsible Computing 1 (2024) 26:1–26:45. doi:10.1145/3696449
-
[25]
G. M. Alarcon, A. Capiola, Explicating the trust process for effective human interaction with artificial intelligence and machine learning systems, Frontiers in Computer Science Volume 7 - 2025 (2025). doi:10. 3389/fcomp.2025.1662185
arXiv 2025
-
[26]
Educational Psychologist , volume =
K. VanLEHN, The Relative Effectiveness of Human Tutoring, Intelligent Tutoring Systems, and Other Tutoring Systems, Educational Psychologist 46 (2011) 197–221. doi:10.1080/00461520.2011.611369
-
[27]
V. Venkatesh, M. G. Morris, G. B. Davis, F. D. Davis, User Acceptance of Information Technology: Toward A Unified View, Management Information Systems Quarterly 27 (2003) 425–478. doi:10.2307/30036540
-
[28]
N. H. Steneck, R. E. Bulger, The History, Purpose, and Future of Instruction in the Responsible Conduct of Research, Academic Medicine 82 (2007) 829–834. doi:10.1097/ACM.0b013e31812f7d4d
-
[29]
M. S. Anderson, A. S. Horn, K. R. Risbey, E. A. Ronning, R. De Vries, B. C. Martinson, What Do Mentoring and Training in the Responsible Conduct of Research Have To Do with Scientists’ Misbehavior? Findings from a National Survey of NIH-Funded Scientists, Academic Medicine 82 (2007) 853–860. doi: 10.1097/ ACM.0b013e31812f764c
2007
-
[30]
C. Zhai, S. Wibowo, L. D. Li, The effects of over-reliance on AI dialogue systems on students’ cognitive abili- ties: a systematic review, Smart Learning Environments 11 (2024) 28. doi:10.1186/s40561-024-00316-7
-
[31]
L. McCoy, N. Ganesan, V. Rajagopalan, D. McKell, D. F. Niño, M. C. Swaim, A Training Needs Analysis for AI and Generative AI in Medical Education: Perspectives of Faculty and Students, Journal of Medical Education and Curricular Development 12 (2025) 23821205251339226. doi:10.1177/23821205251339226
-
[32]
Available: https://onlinelibrary.wiley.com/doi/10.1111/j
S. Jamieson, Likert scales: how to (ab)use them, Medical Education 38 (2004) 1217–1218. doi: 10.1111/j. 1365-2929.2004.02012.x
work page doi:10.1111/j 2004
-
[33]
C. Spearman, The Proof and Measurement of Association between Two Things, The American Journal of Psychology 15 (1904) 72. doi:10.2307/1412159
-
[34]
W. H. Kruskal, W. A. Wallis, Use of Ranks in One-Criterion Variance Analysis, Journal of the American Statistical Association 47 (1952) 583–621. doi:10.1080/01621459.1952.10483441
-
[35]
Holm, A Simple Sequentially Rejective Multiple Test Procedure, Scandinavian Journal of Statistics 6 (1979) 65–70
S. Holm, A Simple Sequentially Rejective Multiple Test Procedure, Scandinavian Journal of Statistics 6 (1979) 65–70
1979
-
[36]
L. Zhou, W. Schellaert, F. Martínez-Plumed, Y. Moros-Daval, C. Ferri, J. Hernández-Orallo, Larger and more instructable language models become less reliable, Nature 634 (2024) 61–68. doi: 10.1038/ s41586-024-07930-y
2024
-
[37]
P. M. Podsakoff, S. B. MacKenzie, J.-Y. Lee, N. P. Podsakoff, Common method biases in behavioral research: A critical review of the literature and recommended remedies., Journal of Applied Psychology 88 (2003) 879–903. doi:10.1037/0021-9010.88.5.879. A. Sample Composition and Supporting Visualizations Table 4 reports the baseline composition. The sample i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.