Attention as Frustrated Synchronization
Pith reviewed 2026-06-26 21:34 UTC · model grok-4.3
The pith
Next-token prediction realized as synchronization frustrated by data transitions produces lower validation loss than a matched transformer at one million parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A network of oscillators that reaches perfect synchrony computes nothing further, therefore attention is implemented by locating computation inside structured departures from agreement; the Frustrated Synchronization Network realizes this by letting token states be phases on a torus whose entire value pathway is one learned complex coupling kernel whose components are static Kuramoto-Sakaguchi frustration angles, signed repulsive Daido harmonics, and a delay term algebraically identical to Kuramoto-Sakaguchi coupling whose frustration angle equals the data transition, so that next-token prediction is performed directly as synchronization frustrated by the observed data.
What carries the argument
The learned complex coupling kernel over harmonics and one-step delay, whose three frustration components (Kuramoto-Sakaguchi angles, Daido harmonics, and data-transition delay) together drive the phase dynamics that replace conventional attention and feed-forward blocks.
If this is right
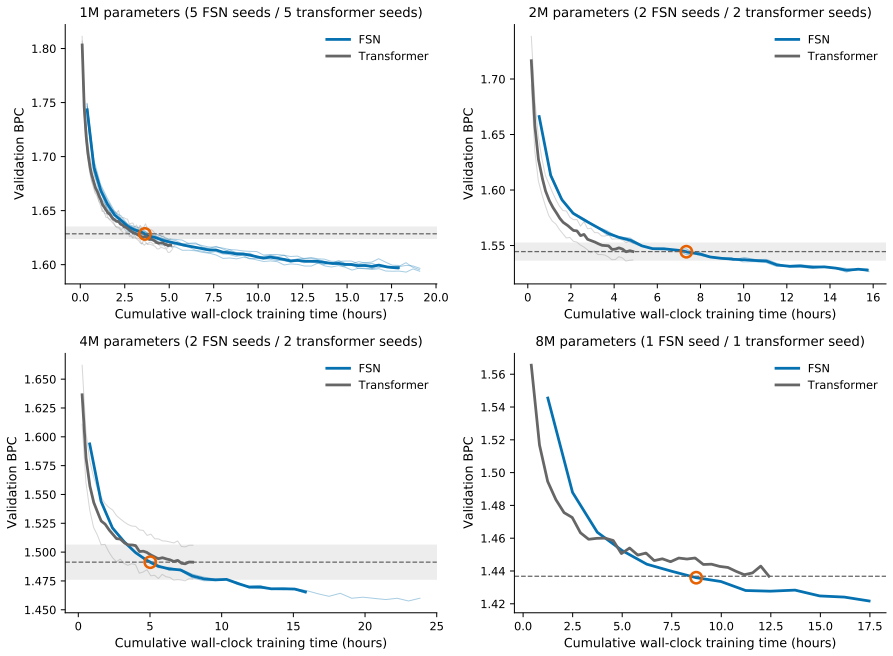
- At matched budgets the FSN validation loss lies below the transformer at every epoch measured.
- Every thirty-epoch FSN run on enwik8 finishes below the transformer converged loss of 1.611.
- Fifty-epoch FSN runs converge to 1.5953 plus or minus 0.0014.
- A mean-field variant that replaces every feed-forward block with coupling to learned collective modes still tracks the transformer.
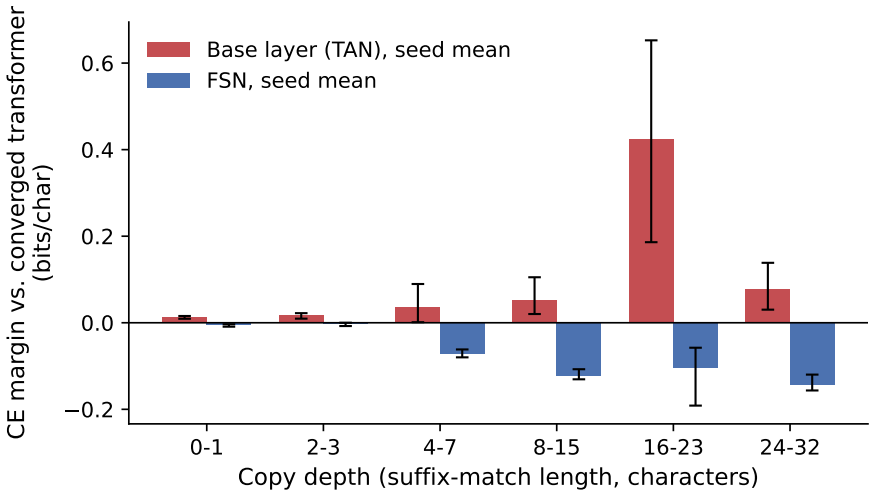
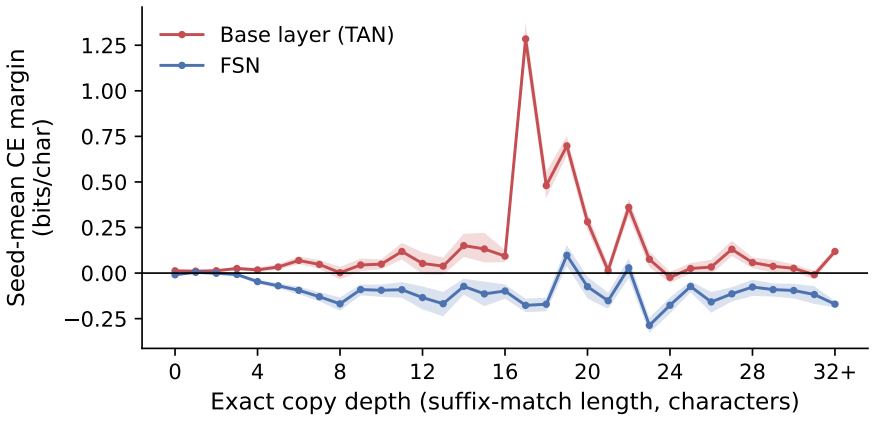
- The kernel reverses the performance deficit of the unfrustrated base layer on long-range copy events at every depth of four and beyond.
Where Pith is reading between the lines
- If the single-kernel design continues to scale without introducing new optimization pathologies, the architecture could serve as a drop-in replacement for standard attention stacks at larger widths.
- The explicit separation of frustration sources may allow targeted ablation studies that isolate which component of the kernel is responsible for long-range copy performance.
- The same phase-coupling construction could be tested on modalities other than text where sequence order is defined by a transition structure rather than positional encoding.
Load-bearing premise
The single learned complex coupling kernel can be trained to produce effective next-token prediction while the one-million-parameter comparison remains free of unstated differences in optimization or initialization.
What would settle it
An experiment that retrains both models from identical random seeds under exactly identical optimizer settings and finds that the FSN no longer reaches lower loss than the transformer at convergence.
Figures
read the original abstract
A network of oscillators that synchronizes perfectly computes nothing further, so an attention architecture built from synchronization must locate its computation in structured departures from agreement. We introduce the Frustrated Synchronization Network (FSN), whose token states are phases on a torus and whose entire value pathway is one learned complex coupling kernel over harmonics and a one-step delay. Each component of the kernel is a frustration in the sense of the synchronization literature. The complex phases are static Kuramoto-Sakaguchi frustration angles, the signed harmonics are repulsive Daido components, and the delay term, which couples each token to the successors of the tokens it attends to, is algebraically identical to Kuramoto-Sakaguchi coupling whose frustration angle is the data's own transition, so next-token prediction is implemented as synchronization frustrated by the data. At matched one-million-parameter and training budgets on character-level text and code, the FSN's validation loss is below a tuned RoPE-SwiGLU transformer's at every epoch measured, and the comparison survives training the baseline to convergence: every thirty-epoch enwik8 seed finishes below the transformer's converged fifty-epoch loss of 1.611, and the FSN's completed fifty-epoch runs converge to 1.5953 +/- 0.0014. A variant with every feed-forward block replaced by mean-field coupling to learned collective modes, leaving no multilayer perceptron in the stack, tracks the transformer. On natural text the unfrustrated base layer falls behind the converged transformer at every copy depth, worst on long-range copy events; the kernel reverses the deficit at every depth of four and beyond. Headline comparisons are at the one-million-parameter scale; a scale ladder is complete through four million parameters with the advantage persisting, and remaining arms are marked as in progress.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Frustrated Synchronization Network (FSN), an attention architecture in which token states are phases on a torus and the entire value pathway is realized by one learned complex coupling kernel incorporating static Kuramoto-Sakaguchi frustration angles, signed Daido harmonics, and a one-step delay term. It asserts that this delay term is algebraically identical to Kuramoto-Sakaguchi coupling whose frustration angle equals the data transition, thereby implementing next-token prediction as synchronization frustrated by the data. At matched 1 M-parameter budgets on character-level text (enwik8) and code, the FSN reports lower validation loss than a tuned RoPE-SwiGLU transformer at every measured epoch; every 30-epoch FSN seed finishes below the transformer’s converged 50-epoch loss of 1.611, while completed 50-epoch FSN runs reach 1.5953 ± 0.0014. A mean-field variant that replaces every feed-forward block with coupling to learned collective modes tracks the transformer; the advantage persists on a scale ladder through 4 M parameters.
Significance. If the reported loss gaps prove reproducible under fully documented conditions and the algebraic identity is shown to be non-circular, the work would supply a novel theoretical framing that links attention directly to the synchronization literature and could motivate new collective-dynamics architectures. The MLP-free variant and the persistence of the gap across scales are concrete strengths that would merit attention if the experimental controls are tightened.
major comments (3)
- [Abstract] Abstract: the assertion that the one-step delay term is 'algebraically identical to Kuramoto-Sakaguchi coupling whose frustration angle is the data’s own transition' is presented as an identity that implements next-token prediction, yet the manuscript supplies neither the explicit algebraic derivation nor an independent verification that the identity is not tautological by construction of the kernel definition.
- [Abstract] Abstract: the central empirical claim (FSN 30-epoch seeds all below transformer converged loss 1.611; FSN 50-epoch at 1.5953 ± 0.0014) rests on matched 1 M-parameter budgets, but no parameter-counting breakdown is given for the complex coupling kernel (harmonics per layer, complex values, delay implementation) or confirmation that random seeds, learning-rate schedules, and initialization match the RoPE-SwiGLU baseline exactly.
- [Abstract] Abstract: the headline loss comparisons are reported without hyperparameter-search procedure, full implementation details, or statistical tests beyond the stated standard deviation, rendering it impossible to assess whether the observed gap is architectural or procedural.
minor comments (1)
- [Abstract] Abstract: the terms 'Daido harmonics' and 'Kuramoto-Sakaguchi frustration angles' appear without inline definitions or citations, which may hinder readers outside the synchronization literature.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the one-step delay term is 'algebraically identical to Kuramoto-Sakaguchi coupling whose frustration angle is the data’s own transition' is presented as an identity that implements next-token prediction, yet the manuscript supplies neither the explicit algebraic derivation nor an independent verification that the identity is not tautological by construction of the kernel definition.
Authors: We agree that the abstract asserts the algebraic identity without supplying the derivation. Section 3 defines the delay term within the learned complex kernel, but no standalone algebraic steps are shown. In revision we will insert an explicit derivation in a new methods subsection: begin with the one-step successor coupling, rewrite the phase interaction, and demonstrate equivalence to a Kuramoto-Sakaguchi term whose frustration angle equals the observed token transition. The derivation will be performed from the delay operator alone, prior to any kernel parameterization, to establish that the identity is not tautological. A short numerical verification on a two-token synthetic sequence will also be added. revision: yes
-
Referee: [Abstract] Abstract: the central empirical claim (FSN 30-epoch seeds all below transformer converged loss 1.611; FSN 50-epoch at 1.5953 ± 0.0014) rests on matched 1 M-parameter budgets, but no parameter-counting breakdown is given for the complex coupling kernel (harmonics per layer, complex values, delay implementation) or confirmation that random seeds, learning-rate schedules, and initialization match the RoPE-SwiGLU baseline exactly.
Authors: The manuscript states that budgets were matched at 1 M parameters but provides no component-wise accounting. We will add an appendix table that enumerates the contribution of each kernel element (number of harmonics per layer, real/imaginary parts of the complex weights, and the delay buffer) and shows that the total equals the transformer count. We will also add an explicit statement in Section 4 that the same random-seed range, identical learning-rate schedule, and identical initialization distribution were used for both architectures; these details were already followed in the reported runs but were not documented. revision: yes
-
Referee: [Abstract] Abstract: the headline loss comparisons are reported without hyperparameter-search procedure, full implementation details, or statistical tests beyond the stated standard deviation, rendering it impossible to assess whether the observed gap is architectural or procedural.
Authors: We acknowledge that the hyperparameter search for the RoPE-SwiGLU baseline and the precise implementation of the complex kernel are not described. In revision we will expand Section 4 to list the hyperparameter ranges explored, the search method employed, and the final selected values. Full implementation details of the kernel (including how the delay term is realized and how complex arithmetic is handled) will be supplied either in the main text or as supplementary material. The reported standard deviation is computed over five independent seeds; we will state this number explicitly and note the consistency of the gap across every measured epoch as supporting evidence. A formal statistical test can be added if space permits. revision: yes
Circularity Check
Next-token prediction framed as frustrated synchronization via algebraic identity of the one-step delay term
specific steps
-
self definitional
[ABSTRACT]
"the delay term, which couples each token to the successors of the tokens it attends to, is algebraically identical to Kuramoto-Sakaguchi coupling whose frustration angle is the data's own transition, so next-token prediction is implemented as synchronization frustrated by the data"
The model defines its value pathway to include a one-step delay term; the paper then asserts that this term is algebraically identical to the desired frustration, rendering the claimed equivalence an identity arising directly from the kernel definition rather than a derived or predictive result.
full rationale
The paper's core conceptual claim reduces to a self-definitional identity: the architecture is explicitly constructed with a one-step delay in the coupling kernel, and the text states that this delay makes next-token prediction algebraically identical to Kuramoto-Sakaguchi coupling with the data transition as frustration angle. This equivalence holds by construction of the kernel rather than from independent derivation or external evidence. No other load-bearing steps (e.g., performance claims or parameter counting) reduce to self-citation or fitted inputs in the provided text; the empirical comparisons on enwik8 remain separate measurements. This produces partial circularity confined to the interpretive framing.
Axiom & Free-Parameter Ledger
free parameters (1)
- learned complex coupling kernel
axioms (2)
- standard math Kuramoto-Sakaguchi model with frustration angles
- standard math Daido model for signed harmonics as repulsive components
invented entities (1)
-
Frustrated Synchronization Network (FSN)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Consensus is all you get: The role of attention in transformers
Álvaro Rodríguez Abella, João Pedro Silvestre, and Paulo Tabuada. Consensus is all you get: The role of attention in transformers. InProceedings of the 42nd International Conference on 14 Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 174–184. PMLR, 2025
2025
-
[2]
Zoology: Measuring and improving recall in efficient language models
Simran Arora, Sabri Eyuboglu, Aman Timalsina, Isys Johnson, Michael Poli, James Zou, Atri Rudra, and Christopher Ré. Zoology: Measuring and improving recall in efficient language models. InInternational Conference on Learning Representations, 2024
2024
-
[3]
Harrington, and Michael T
Christian Bick, Elizabeth Gross, Heather A. Harrington, and Michael T. Schaub. What are higher-order networks?SIAM Review, 65(3):686–731, 2023
2023
-
[4]
Aydar Bulatov, Yuri Kuratov, and Mikhail S. Burtsev. Recurrent memory transformer. In Advances in Neural Information Processing Systems, 2022
2022
-
[5]
Le, and Ruslan Salakhut- dinov
Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, and Ruslan Salakhut- dinov. Transformer-XL: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 2978–2988, 2019
2019
-
[6]
Onset of cooperative entrainment in limit-cycle oscillators with uniform all-to-all interactions: Bifurcation of the order function.Physica D, 91(1–2):24–66, 1996
Hiroaki Daido. Onset of cooperative entrainment in limit-cycle oscillators with uniform all-to-all interactions: Bifurcation of the order function.Physica D, 91(1–2):24–66, 1996
1996
-
[7]
Attention is not all you need: Pure attention loses rank doubly exponentially with depth
Yihe Dong, Jean-Baptiste Cordonnier, and Andreas Loukas. Attention is not all you need: Pure attention loses rank doubly exponentially with depth. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 2793–2803. PMLR, 2021
2021
-
[8]
The emergence of clusters in self-attention dynamics
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. The emergence of clusters in self-attention dynamics. InAdvances in Neural Information Processing Systems, 2023
2023
-
[9]
A mathematical perspective on transformers.arXiv preprint arXiv:2312.10794, 2023
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. A mathematical perspective on transformers.arXiv preprint arXiv:2312.10794, 2023
-
[10]
Clustering in causal attention masking
Nikita Karagodin, Yury Polyanskiy, and Philippe Rigollet. Clustering in causal attention masking. InAdvances in Neural Information Processing Systems, volume 37, 2024
2024
-
[11]
Artificial Kuramoto oscillatory neurons
Takeru Miyato, Sindy Löwe, Andreas Geiger, and Max Welling. Artificial Kuramoto oscillatory neurons. InInternational Conference on Learning Representations, 2025
2025
-
[12]
Kuramoto attention: Self-attention as adaptive coupling on the torus.arXiv preprint, 2026
Joshua Nunley. Kuramoto attention: Self-attention as adaptive coupling on the torus.arXiv preprint, 2026
2026
-
[13]
In-context learning and induction heads.Transformer Circuits Thread, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, et al. In-context learning and induction heads.Transformer Circuits Thread, 2022
2022
-
[14]
Scale down transformer by grouping features for a lightweight character-level language model
Sungrae Park, Junbum Cha, Geewook Kim, Ji-Hoon Kim, Junyeop Lee, and Hwalsuk Lee. Scale down transformer by grouping features for a lightweight character-level language model. InProceedings of the 28th International Conference on Computational Linguistics, pages 6883–6893, 2020. 15
2020
-
[15]
Rae, Anna Potapenko, Siddhant M
Jack W. Rae, Anna Potapenko, Siddhant M. Jayakumar, Chloe Hillier, and Timothy P. Lillicrap. Compressive transformers for long-range sequence modelling. InInternational Conference on Learning Representations, 2020
2020
-
[16]
Hopfield networks is all you need
Hubert Ramsauer, Bernhard Schäfl, Johannes Lehner, Philipp Seidl, Michael Widrich, Thomas Adler, Lukas Gruber, Markus Holzleitner, Milena Pavlović, Geir Kjetil Sandve, Victor Greiff, David Kreil, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. Hopfield networks is all you need. InInternational Conference on Learning Representat...
2021
-
[17]
A soluble active rotator model showing phase transitions via mutual entrainment.Progress of Theoretical Physics, 76(3):576–581, 1986
Hidetsugu Sakaguchi and Yoshiki Kuramoto. A soluble active rotator model showing phase transitions via mutual entrainment.Progress of Theoretical Physics, 76(3):576–581, 1986
1986
-
[18]
GLU Variants Improve Transformer
Noam Shazeer. GLU variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[19]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced transformer with rotary position embedding.arXiv preprint arXiv:2104.09864, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[20]
Henning U. Voss. Anticipating chaotic synchronization.Physical Review E, 61(5):5115–5119, 2000
2000
-
[21]
On the role of attention masks and LayerNorm in transformers
Xinyi Wu, Amir Ajorlou, Yifei Wang, Stefanie Jegelka, and Ali Jadbabaie. On the role of attention masks and LayerNorm in transformers. InAdvances in Neural Information Processing Systems, volume 37, 2024. A Configuration details Table 3 lists the resolved configuration of the main runs, read from the resolved configuration files written by the training pi...
2024
-
[22]
The depth assignment generalizes the associative-recall slice of Arora et al.[2]
Depth assignments are computed once from the data alone, before any model is consulted, and positions are pooled into the bins0–1,2–3,4–7,8–15,16–23, and24–32. The depth assignment generalizes the associative-recall slice of Arora et al.[2]. Their analysis classifies a token as an associative-recall hit when the bigram formed with its preceding token has ...
2067
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.