How LLMs Fail and Generalize in RTL Coding for Hardware Design?
Pith reviewed 2026-07-01 09:27 UTC · model grok-4.3
The pith
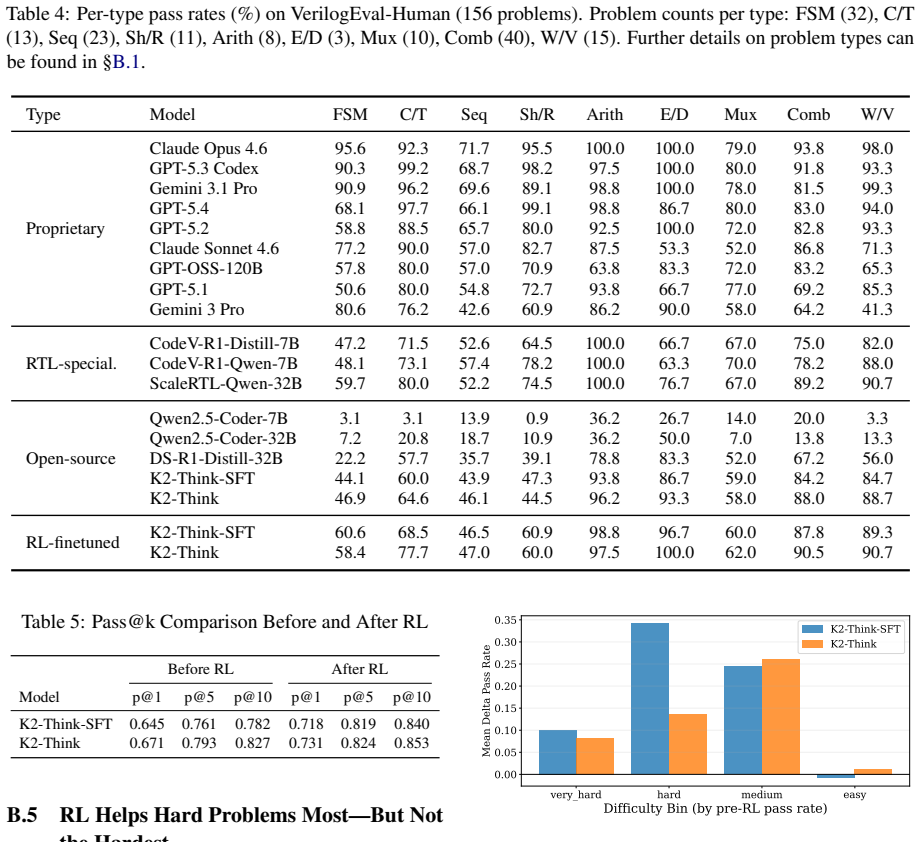
Frontier LLMs plateau at 90.8 percent pass rate on VerilogEval because unsolvable functional errors resist test-time scaling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
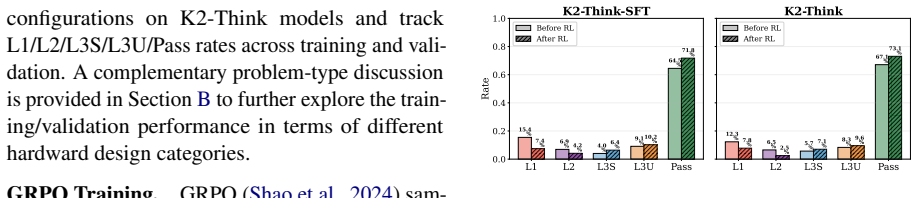
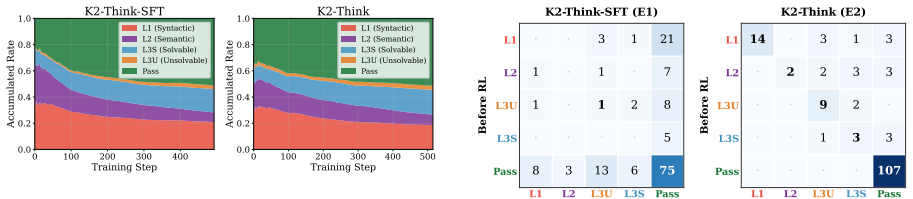
The paper claims that LLMs face a strict empirical ceiling in RTL coding on VerilogEval at 90.8 percent initial pass rate, created by unsolvable functional errors that expose persistent knowledge gaps immune to test time compute scaling. Alignment methods only teach models to produce compilable code, while repeated sampling can fix solvable errors but leaves overall performance bounded by pretraining knowledge.
What carries the argument
The four-category error taxonomy grounded in problem solvability, which separates errors fixable by sampling or optimization from those that cannot be resolved under current approaches.
If this is right
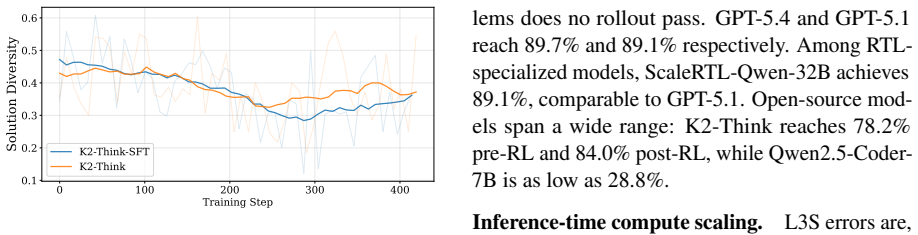
- Optimization removes syntax errors but increases the rate of deeper functional failures.
- Alignment techniques teach models to compile but do not build deeper hardware reasoning.
- Repeated sampling patches solvable errors yet cannot overcome the pretraining bound on RTL capacity.
- Improving the LLM hardware generation pipeline requires studies focused on model reasoning rather than further alignment work.
Where Pith is reading between the lines
- The taxonomy may require updates if future models introduce new failure modes not captured by solvability under current methods.
- The observed surface convergence suggests that training objectives prioritizing compilation success may trade off against functional correctness in temporal logic tasks.
- If the ceiling holds, hybrid systems combining LLMs with formal verification tools could become necessary rather than relying on generation alone.
Load-bearing premise
The VerilogEval benchmark and the four error categories fully represent the space of RTL coding failures, and the errors labeled unsolvable truly cannot be fixed by any prompting, fine-tuning, or architectural change not tested here.
What would settle it
Demonstrating a model or technique that exceeds 90.8 percent pass rate on VerilogEval specifically by resolving the errors previously labeled unsolvable functional would falsify the claimed ceiling.
Figures



read the original abstract
Translating sequential programming priors into the parallel temporal logic of hardware design remains a crucial bottleneck for large language models(LLM). To investigate this, we introduce a new error taxonomy grounded in problem solvability, inspired by cognitive theory. Our taxonomy categorizes failures into syntactic, semantic, solvable functional, and unsolvable functional types. Evaluations reveal a strict empirical ceiling on the VerilogEval benchmark, as frontier models plateau at a 90.8% initial pass rate. These plateaus are defined by unsolvable functional errors, exposing persistent knowledge gaps immune to test time compute scaling. Furthermore, we expose a striking surface convergence gap: optimization readily eliminates syntax errors but concurrently exacerbates deeper functional failures. Our findings demonstrate that alignment techniques merely teach models to compile. While repeated sampling strategies can patch solvable errors, register-transfer level(RTL) coding capacity remains strictly bounded by pretraining knowledge. Addressing challenges in the current LLM based hardware generation pipeline requires more studies in model reasoning rather than alignment interventions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a solvability-grounded error taxonomy (syntactic, semantic, solvable functional, unsolvable functional) for LLM failures in RTL coding. On the VerilogEval benchmark, frontier models reach a 90.8% initial pass-rate plateau defined by unsolvable functional errors; the authors conclude these errors reflect pretraining knowledge gaps immune to test-time compute scaling. Additional observations include surface convergence (optimization removes syntax errors while increasing functional failures) and the claim that alignment only teaches compilation while RTL capacity remains strictly bounded by pretraining knowledge.
Significance. If the taxonomy is reproducible and the unsolvable errors are shown to be robustly immune to scaling, the work would usefully document empirical limits of current LLMs for hardware design and motivate research on reasoning rather than alignment. The solvability-based taxonomy itself is a constructive framing.
major comments (2)
- [Error Taxonomy and Results sections] The central claim of a strict 90.8% empirical ceiling rests on the unsolvable-functional category being genuinely immune to test-time scaling. The manuscript evaluates only the prompting and sampling strategies described; no exhaustive test or theoretical bound is provided showing these errors cannot be resolved by untested interventions (different CoT variants, retrieval, or fine-tuning).
- [Error Taxonomy section] The distinction between solvable and unsolvable functional errors lacks explicit, reproducible decision criteria. Without such criteria the inference that capacity is 'strictly bounded by pretraining knowledge' cannot be verified independently of the particular interventions tested.
minor comments (1)
- [Methodology] Clarify how the four-category taxonomy was applied to individual errors (inter-annotator agreement, decision tree, or post-hoc labeling protocol) so readers can assess labeling reliability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the error taxonomy and empirical claims. We address the major comments point by point below, indicating revisions where appropriate.
read point-by-point responses
-
Referee: [Error Taxonomy and Results sections] The central claim of a strict 90.8% empirical ceiling rests on the unsolvable-functional category being genuinely immune to test-time scaling. The manuscript evaluates only the prompting and sampling strategies described; no exhaustive test or theoretical bound is provided showing these errors cannot be resolved by untested interventions (different CoT variants, retrieval, or fine-tuning).
Authors: We agree that the manuscript does not conduct an exhaustive evaluation of every possible test-time intervention nor provide a theoretical bound. The reported 90.8% plateau is an empirical observation based on the prompting, sampling, and alignment strategies explicitly tested. We will revise the Results and Discussion sections to clarify that this is an observed ceiling under the evaluated conditions rather than a proven universal limit, while retaining the taxonomy's utility for documenting the tested failure modes. revision: yes
-
Referee: [Error Taxonomy section] The distinction between solvable and unsolvable functional errors lacks explicit, reproducible decision criteria. Without such criteria the inference that capacity is 'strictly bounded by pretraining knowledge' cannot be verified independently of the particular interventions tested.
Authors: We accept this criticism. The revised Error Taxonomy section will include explicit, step-by-step decision criteria for distinguishing solvable from unsolvable functional errors, supported by concrete examples drawn from the VerilogEval cases and the classification procedure used by the authors. This addition will enable independent reproduction and verification. revision: yes
- An exhaustive empirical test of all conceivable untested interventions (every CoT variant, retrieval method, and fine-tuning regime) to definitively prove immunity of unsolvable errors is beyond the scope of a single empirical study.
Circularity Check
No circularity: empirical benchmark study with no derivations or self-referential fits
full rationale
The paper reports empirical pass rates and error classifications on the VerilogEval benchmark after testing specific prompting and sampling strategies. It introduces a four-category taxonomy as new without citing prior self-work as load-bearing justification. No equations, fitted parameters renamed as predictions, or reductions of claims to inputs by construction appear in the provided text. The 90.8% ceiling is presented as an observed plateau under the evaluated conditions, not a tautological outcome of the taxonomy definition itself. This is a standard empirical analysis with low circularity burden.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. Zhoujun Cheng, Richard Fan, Shibo Hao, Taylor W. Killian, Haonan Li, Suqi Sun, Hector Ren, Alexan- der Moreno, Daqian Zhang, Tianjun Zhong, Yuxin Xiong, Yuanzhe Hu, Yutao Xie, Xudong Han, Yuqi Wang, Varad Pimpalkhute, Yonghao Zhuang, Aarya- monvikram Singh, Xuezhi Liang, and 12 o...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Let’s verify step by step.Preprint, arXiv:2305.20050. Mingjie Liu, Teodor-Dumitru Ene, Robert Kirby, Chris Cheng, Nathaniel Pinckney, Rongjian Liang, Jonah Alben, Himyanshu Anand, Sanmitra Banerjee, Is- met Bayraktaroglu, Bonita Bhaskaran, Bryan Catan- zaro, Arjun Chaudhuri, Sharon Clay, Bill Dally, Laura Dang, Parikshit Deshpande, Siddhanth Dhodhi, Samee...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
InProceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 30381–30398
Speechiq: Speech-agentic intelligence quo- tient across cognitive levels in voice understanding by large language models. InProceedings of the 63rd Annual Meeting of the Association for Compu- tational Linguistics (Volume 1: Long Papers), pages 30381–30398. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, a...
2022
-
[4]
FSM(32): state machines, Mealy/Moore ma- chines, state encoding
-
[5]
Counter_Timer(13): up/down counters, BCD, timers, thermostats
-
[6]
Sequential_Logic(23): flip-flops, latches, edge detectors, clock dividers, UART/SPI protocols
-
[7]
Shift_Rotate(11): LFSRs, barrel shifters, rota- tors, SIPO/PISO
-
[8]
Arithmetic(8): adders, multipliers, ALU, CRC, parity, popcount
-
[9]
Encoder_Decoder(3): priority encoders, 7- segment decoders, scancode mapping
-
[10]
Mux_Select(10): multiplexers, demultiplexers, crossbar switches
-
[11]
Combinational_Logic(40): Karnaugh maps, truth tables, gates, waveform-based circuits, comparators
-
[12]
top_module
Wire_Vector(15): wire connections, vector manipulation, bit reversal, sign extension, con- stants Problems that do not match any category are labelledOther(1 of 156). Among the 156 VerilogEval-Human problems, Combina- tional_Logic (40) and FSM (32) are the most popu- lated categories. B.2 Exposure–Performance Mismatch Figure 6 shows, for each experiment, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.