Robust Q-learning for mean-field control under Wasserstein uncertainty in common noise
Pith reviewed 2026-06-26 15:56 UTC · model grok-4.3
The pith
A robust Q-learning algorithm converges for discrete-time mean-field control problems when the common noise law lies in a known Wasserstein ball.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a robust Q-learning algorithm solves discrete-time mean-field control problems under Wasserstein uncertainty in the common noise law. The algorithm uses a quantization-and-projection scheme on the state-action space together with a Wasserstein dual reformulation on the common-noise space. Convergence and finite-time bounds are proved for both synchronous and asynchronous updates.
What carries the argument
The robust Q-learning algorithm that combines a quantization-and-projection scheme with a Wasserstein dual reformulation on the common-noise space to keep the robust Bellman operator a contraction.
If this is right
- Both synchronous and asynchronous schemes converge to the optimal robust Q-function.
- Explicit finite-time iteration bounds hold for the learning process.
- The method applies to systemic risk and epidemic models under common-noise misspecification.
- A robustness-performance tradeoff appears when the radius of the Wasserstein ball is varied.
Where Pith is reading between the lines
- The same quantization-plus-dual approach could be tested on mean-field games rather than control if the fixed-point structure is preserved.
- If the Wasserstein radius must be estimated from data, the finite-time bounds would need an extra error term for radius estimation.
- The discretization error from quantization could be traded against sample complexity in high-dimensional state spaces.
Load-bearing premise
The common-noise distribution belongs to a Wasserstein ball of known radius around a nominal law, and the quantization-projection step produces a sufficiently accurate finite approximation so that the robust Bellman operator remains a contraction.
What would settle it
Run the asynchronous Q-learning scheme on a low-dimensional mean-field control test problem with a known optimal robust value and check whether the iterates reach the claimed finite-time error bound before the predicted number of steps.
Figures
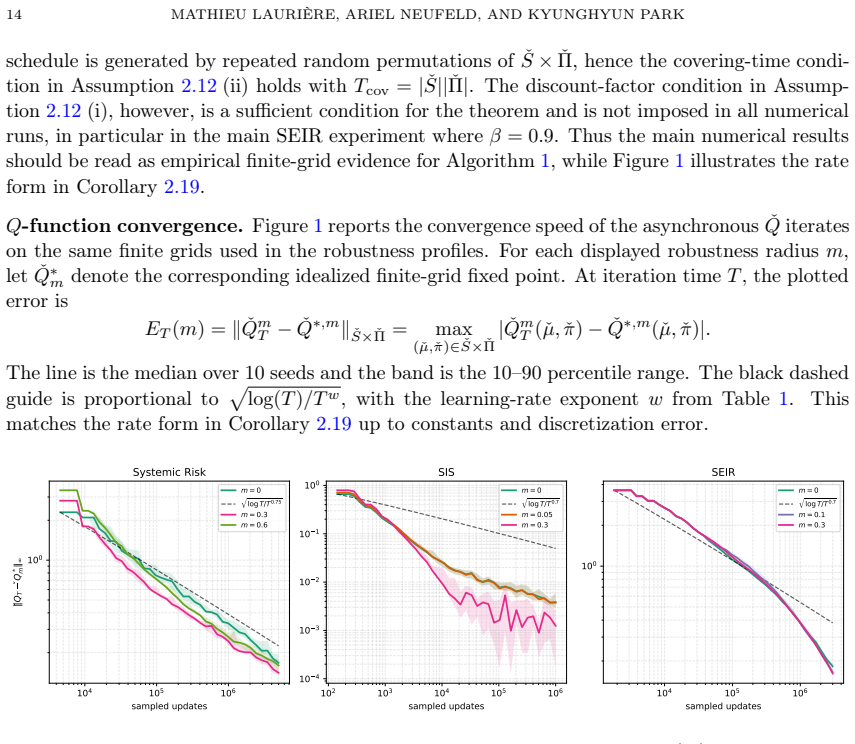



read the original abstract
In this article, we present a robust $Q$-learning algorithm for discrete-time mean-field control problems under Wasserstein uncertainty in the common noise law. The algorithm combines a quantization-and-projection scheme with a Wasserstein dual reformulation on the common-noise space. We establish its convergence together with finite-time iteration bounds for both synchronous and asynchronous learning schemes. Numerical experiments on systemic risk and epidemic models compare the asynchronous implementation with an idealized Bellman iteration, illustrate the robustness-performance tradeoff under common-noise misspecification, and report the observed convergence behavior of the asynchronous $Q$-learning algorithm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops a robust Q-learning algorithm for discrete-time mean-field control under Wasserstein uncertainty in the common noise law. The method combines a quantization-and-projection scheme with a Wasserstein dual reformulation on the common-noise space, and claims to establish convergence together with finite-time iteration bounds for both synchronous and asynchronous schemes. Numerical experiments on systemic risk and epidemic models are used to illustrate robustness-performance tradeoffs and observed convergence behavior.
Significance. If the claimed convergence and finite-time bounds hold after accounting for approximation errors, the work would supply a practical, theoretically supported approach to robust mean-field control under distributional uncertainty in common noise, with direct relevance to applications such as systemic risk and epidemic modeling.
major comments (2)
- [§3.2 and Theorem 4.1] §3.2 (Quantization-and-projection step) and Theorem 4.1: The central claim that the approximated robust Bellman operator remains a contraction (with modulus strictly less than 1) after quantization and projection is load-bearing for both convergence and the finite-time bounds. No explicit quantitative relation is given between quantization mesh size, discount factor, and Wasserstein radius that guarantees the contraction constant stays below 1 uniformly over the uncertainty ball.
- [Theorem 4.2] Asynchronous scheme (Theorem 4.2): The error recursion used to derive the finite-time bound does not visibly incorporate the additional projection error term arising from the quantization step under the Wasserstein uncertainty; without this control, the stated iteration complexity may fail to hold for positive radius values.
minor comments (2)
- [Preliminaries] The description of the Wasserstein dual reformulation in the preliminaries would benefit from an explicit statement of the dual variables and their dependence on the common-noise space.
- [Numerical experiments] Figure captions for the numerical experiments should specify the number of independent runs and any variability measures used.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address the two major comments point by point below and indicate the revisions that will be made to the manuscript.
read point-by-point responses
-
Referee: [§3.2 and Theorem 4.1] §3.2 (Quantization-and-projection step) and Theorem 4.1: The central claim that the approximated robust Bellman operator remains a contraction (with modulus strictly less than 1) after quantization and projection is load-bearing for both convergence and the finite-time bounds. No explicit quantitative relation is given between quantization mesh size, discount factor, and Wasserstein radius that guarantees the contraction constant stays below 1 uniformly over the uncertainty ball.
Authors: The referee is correct that the manuscript does not supply an explicit quantitative threshold relating mesh size δ, discount factor γ, and radius ρ that keeps the contraction modulus strictly below 1 uniformly over the ball. The proof of Theorem 4.1 establishes the contraction for sufficiently fine quantization via continuity of the Wasserstein dual, but leaves the dependence implicit. In the revised version we will add a remark after Theorem 4.1 that derives the explicit condition δ < (1-γ-ε(ρ))/L (with L the Lipschitz constant of the running cost) guaranteeing the modulus ≤ γ+ε(ρ)<1. revision: yes
-
Referee: [Theorem 4.2] Asynchronous scheme (Theorem 4.2): The error recursion used to derive the finite-time bound does not visibly incorporate the additional projection error term arising from the quantization step under the Wasserstein uncertainty; without this control, the stated iteration complexity may fail to hold for positive radius values.
Authors: We agree that the error recursion in the proof of Theorem 4.2 does not explicitly include the additional projection error that arises from the quantization step when the uncertainty radius is positive. This term is bounded by a multiple of the mesh size but must be carried through the recursion. In the revised manuscript we will augment the recursion with this O(δ) term and derive the corresponding adjusted iteration complexity that remains valid for ρ>0. revision: yes
Circularity Check
No circularity: derivation rests on standard contraction and duality arguments
full rationale
The paper's central claims concern convergence and finite-time bounds for a robust Q-learning algorithm that combines quantization-projection with a Wasserstein dual reformulation of the common-noise uncertainty. These rest on the robust Bellman operator being a contraction (under the stated Wasserstein-ball assumption and sufficiently accurate quantization) together with standard fixed-point and stochastic-approximation arguments. No quoted equation or step reduces a claimed prediction or uniqueness result to a fitted parameter, a self-citation chain, or a redefinition of the target quantity; the assumptions and duality are treated as external mathematical facts rather than constructed from the algorithm's outputs. This is the normal non-circular case for a convergence proof in approximate dynamic programming.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The common noise law lies inside a Wasserstein ball of finite radius around a known nominal distribution.
- domain assumption The quantization-and-projection operator yields a sufficiently accurate finite-state approximation for the robust value iteration to remain contractive.
Reference graph
Works this paper leans on
-
[1]
Anahtarci, C
B. Anahtarci, C. D. Kariksiz, and N. Saldi.Q-learning in regularized mean-field games.Dyn. Games Appl., 13(1):89–117, 2023
2023
-
[2]
Angiuli, J.-P
A. Angiuli, J.-P. Fouque, M. Laurière, and M. Zhang. Analysis of multiscale reinforcementQ-learning algo- rithms for mean field control games.Appl. Math. Optim., 93(2):27, 2026
2026
-
[3]
K. Azuma. Weighted sums of certain dependent random variables.Tohoku Math. J., Second Series, 19(3):357– 367, 1967
1967
-
[4]
Bartl, S
D. Bartl, S. Drapeau, and L. Tangpi. Computational aspects of robust optimized certainty equivalents and option pricing.Math. Finance, 30(1):287–309, 2020
2020
-
[5]
Bäuerle and A
N. Bäuerle and A. Glauner. Distributionally robust Markov decision processes and their connection to risk measures.Math. Oper. Res., 47(3):1757–1780, 2022
2022
-
[6]
Bäuerle and U
N. Bäuerle and U. Rieder.Markov decision processes with applications to finance. Springer Science & Business Media, 2011
2011
-
[7]
Bauso, H
D. Bauso, H. Tembine, and T. Basar. Opinion dynamics in social networks through mean-field games.SIAM J. Control Optim., 54(6):3225–3257, 2016
2016
-
[8]
Bauso, H
D. Bauso, H. Tembine, and T. Başar. Robust Mean Field Games.Dynam. Games Appl., 6(3):277–303, 2016
2016
-
[9]
C. L. Beck and R. Srikant. Error bounds for constant step-sizeQ-learning.Syst. Control Lett., 61(12):1203– 1208, 2012
2012
-
[10]
Bensoussan, J
A. Bensoussan, J. Frehse, and P. Yam.Mean field games and mean field type control theory, volume 101. New York: Springer-Verlag, 2013
2013
-
[11]
D. P. Bertsekas. Neuro-dynamic programming. InEncyclopedia of optimization, pages 1–6. Springer, 2025
2025
-
[12]
Blanchet, M
J. Blanchet, M. Lu, T. Zhang, and H. Zhong. Double pessimism is provably efficient for distributionally robust offline reinforcement learning: Generic algorithm and robust partial coverage.Adv. Neural Inf. Process. Syst., 36:66845–66859, 2023
2023
-
[13]
Blanchet and K
J. Blanchet and K. Murthy. Quantifying distributional model risk via optimal transport.Math. Oper. Res., 44(2):565–600, 2019
2019
-
[14]
Carmona and F
R. Carmona and F. Delarue.Probabilistic theory of mean field games with applications I-II. Springer, 2018
2018
-
[15]
Carmona, K
R. Carmona, K. Hamidouche, M. Laurière, and Z. Tan. Policy optimization for linear-quadratic zero-sum Mean-Field Type Games. In2020 59th IEEE Conference on Decision and Control (CDC), pages 1038–1043. IEEE, 2020
2020
-
[16]
Carmona, K
R. Carmona, K. Hamidouche, M. Laurière, and Z. Tan. Linear-quadratic zero-sum Mean-Field Type Games: Optimality conditions and policy optimization.J. Dyn. Games, 8(4), 2021
2021
-
[17]
Carmona, M
R. Carmona, M. Laurière, and Z. Tan. Model-free mean-field reinforcement learning: mean-field MDP and mean-fieldQ-learning.Ann. Appl. Probab., 33(6B):5334–5381, 2023
2023
-
[18]
Cui and H
K. Cui and H. Koeppl. Approximately solving Mean Field Games via entropy-regularized deep reinforcement learning. InInternational Conference on Artificial Intelligence and Statistics, pages 1909–1917. PMLR, 2021
1909
-
[19]
M. F. Djete. Extended mean field control problem: A propagation of chaos result.Electron. J. Probab., 27:1–53, 2022
2022
-
[20]
M. F. Djete, D. Possamaï, and X. Tan. McKean–Vlasov optimal control: limit theory and equivalence between different formulations.Math. Oper. Res., 47(4):2891–2930, 2022
2022
-
[21]
M. F. Djete, D. Possamaï, and X. Tan. McKean–Vlasov optimal control: The dynamic programming principle. Ann. Probab., 50(2):791–833, 2022
2022
-
[22]
Dvoretsky.On stochastic approximation
A. Dvoretsky.On stochastic approximation. Mathematics Division, Office of Scientific Research, US Air Force, 1955
1955
-
[23]
Elamvazhuthi and S
K. Elamvazhuthi and S. Berman. Mean-field models in swarm robotics: A survey.Bioinsp. Biomim., 15(1):015001, 2019. 41
2019
-
[24]
R. Elie, J. Pérolat, M. Laurière, M. Geist, and O. Pietquin. On the convergence of model free learning in Mean Field Games. InProceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 7143–7150, 2020
2020
-
[25]
Even-Dar and Y
E. Even-Dar and Y. Mansour. Learning rates forQ-learning.J. Mach. Learn. Res., 5(Dec):1–25, 2003
2003
-
[26]
Firoozi and S
D. Firoozi and S. Jaimungal. Exploratory LQG mean field games with entropy regularization.Automatica, 139:110177, 2022
2022
-
[27]
Fouque, R
J.-P. Fouque, R. Carmona, and L. Sun. Mean field games and systemic risk.Commun. Math. Sci, 13(4):911– 933, 2015
2015
-
[28]
Frikha, M
N. Frikha, M. Germain, M. Laurière, H. Pham, and X. Song. Actor-critic learning for mean-field control in continuous time.J. Mach. Learn. Res., 26(127):1–42, 2025
2025
-
[29]
Fujimoto, D
S. Fujimoto, D. Meger, and D. Precup. Off-policy deep reinforcement learning without exploration. InICML, pages 2052–2062. PMLR, 2019
2052
-
[30]
Gao and A
R. Gao and A. Kleywegt. Distributionally robust stochastic optimization with Wasserstein distance.Math. Oper. Res., 48(2):603–655, 2023
2023
-
[31]
Gast and B
N. Gast and B. Gaujal. A mean field approach for optimization in discrete time.Discrete Event Dyn. Syst., 21(1):63–101, 2011
2011
-
[32]
N. Gast, B. Gaujal, and J.-Y. Le Boudec. Mean field for Markov decision processes: from discrete to continuous optimization.IEEE. Trans. Autom. Control, 57(9):2266–2280, 2012
2012
-
[33]
H. Gu, X. Guo, X. Wei, and R. Xu. Mean-field controls withQ-learning for cooperative MARL: convergence and complexity analysis.SIAM J. Math. Data Sci., 3(4):1168–1196, 2021
2021
-
[34]
H. Gu, X. Guo, X. Wei, and R. Xu. Dynamic programming principles for mean-field controls with learning. Oper. Res., 71(4):1040–1054, 2023
2023
-
[35]
X. Guo, A. Hu, R. Xu, and J. Zhang. Learning Mean-Field Games. InAdv. Neural Inf. Process. Syst., volume 32, 2019
2019
- [36]
-
[37]
Huang and M
J. Huang and M. Huang. Robust mean field linear-quadratic-gaussian games with unknownL2-disturbance. SIAM J. Control Optim., 55(5):2811–2840, 2017
2017
-
[38]
Huang, B.-C
J. Huang, B.-C. Wang, and J. Yong. Social optima in mean field linear-quadratic-Gaussian control with volatility uncertainty.SIAM J. Control Optim., 59(2):825–856, 2021
2021
-
[39]
Huang, R
M. Huang, R. P. Malhamé, and P. E. Caines. Large population stochastic dynamic games: Closed loop McKean–Vlasov sysyems and the Nash certainity equivalence principle.Commun. Inf. Syst., 6(3):221–252, 2006
2006
-
[40]
Jaakkola, M
T. Jaakkola, M. I. Jordan, and S. P. Singh. On the convergence of stochastic iterative dynamic programming algorithms.Neural Comput., 6(6):1185–1201, 1994
1994
-
[41]
Jeloka, Y
B. Jeloka, Y. Guan, and P. Tsiotras. Learning large-scale competitive team behaviors with Mean-Field inter- actions. InThe Seventeenth Workshop on Adaptive and Learning Agents, 2025
2025
-
[42]
Kearns and S
M. Kearns and S. Singh. Finite-sample convergence rates forQ-learning and indirect algorithms.Adv. Neural Inf. Process. Syst., 11, 1998
1998
-
[43]
Klenke.Probability Theory: A Comprehensive Course
A. Klenke.Probability Theory: A Comprehensive Course. Universitext. Springer, London, 2nd ed., 2014
2014
-
[44]
Lange, T
S. Lange, T. Gabel, and M. Riedmiller. Batch reinforcement learning. InReinforcement learning: State-of- the-art, pages 45–73. Springer, 2012
2012
-
[45]
J. Langner, A. Neufeld, and K. Park. Markov-Nash equilibria in mean-field games under model uncertainty. preprint, arXiv:2410.11652, 2024
-
[46]
Lasry and P.-L
J.-M. Lasry and P.-L. Lions. Mean field games.Japan. J. Math., 2(1):229–260, 2007
2007
-
[47]
Laurière
M. Laurière. Numerical methods for Mean Field Games and Mean Field Type Control. InProceedings of Symposia in Applied Mathematics, volume 78, pages 221–282. American Mathematical Society, 2021
2021
-
[48]
M. Laurière, A. Neufeld, and K. Park. Robust mean-field control under common noise uncertainty.arXiv preprint arXiv:2511.04515, 2025
-
[49]
Laurière, S
M. Laurière, S. Perrin, S. Girgin, P. Muller, A. Jain, T. Cabannes, G. Piliouras, J. Pérolat, R. Elie, O. Pietquin, et al. Scalable deep reinforcement learning algorithms for Mean Field Games. InICML, pages 12078–12095. PMLR, 2022
2022
-
[50]
M. Laurière, S. Perrin, J. Pérolat, S. Girgin, P. Muller, R. Elie, M. Geist, and O. Pietquin. Learning in Mean Field Games: A survey.arXiv preprint arXiv:2205.12944, 2022
-
[51]
Laurière and O
M. Laurière and O. Pironneau. Dynamic programming for mean-field type control.J. Optim. Theory Appl., 169(3):902–924, 2016. 42 MATHIEU LAURIÈRE, ARIEL NEUFELD, AND KYUNGHYUN PARK
2016
-
[52]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
S. Levine, A. Kumar, G. Tucker, and J. Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[53]
G. Li, L. Shi, Y. Chen, Y. Chi, and Y. Wei. Settling the sample complexity of model-based offline reinforcement learning.Ann. Stat., 52(1):233–260, 2024
2024
-
[54]
G. Li, Y. Wei, Y. Chi, and Y. Chen. Breaking the sample size barrier in model-based reinforcement learning with a generative model.Oper. Res., 72(1):203–221, 2024
2024
-
[55]
G. Li, Y. Wei, Y. Chi, Y. Gu, and Y. Chen. Sample complexity of asynchronousQ-learning: Sharper analysis and variance reduction.Adv. Neural Inf. Process. Syst., 33:7031–7043, 2020
2020
-
[56]
M. Li, D. Kuhn, and T. Sutter. Policy gradient algorithms for robust MDP with nonrectangular uncertainty sets.SIAM J. Optim., 36(1):120–151, 2026
2026
-
[57]
Liang, B.-C
Y. Liang, B.-C. Wang, and H. Zhang. Robust mean field linear quadratic social control: Open-loop and closed-loop strategies.SIAM J. Control Optim., 60(4):2184–2213, 2022
2022
- [58]
-
[59]
M. L. Littman and C. Szepesvári. A generalized reinforcement-learning model: Convergence and applications. InICML, volume 96, pages 310–318, 1996
1996
-
[60]
Z. Liu, Q. Bai, J. Blanchet, P. Dong, W. Xu, Z. Zhou, and Z. Zhou. Distributionally robustQ-learning. In ICML, pages 13623–13643. PMLR, 2022
2022
- [61]
-
[62]
Mohajerin Esfahani and D
P. Mohajerin Esfahani and D. Kuhn. Data-driven distributionally robust optimization using the Wasserstein metric: Performance guarantees and tractable reformulations.Math. Program., 171(1):115–166, 2018
2018
-
[63]
Moon and T
J. Moon and T. Başar. Robust Mean Field Games for coupled Markov jump linear systems.Internat. J. Control, 89(7):1367–1381, 2016
2016
-
[64]
Motte and H
M. Motte and H. Pham. Mean-field Markov decision processes with common noise and open-loop controls. Ann. Appl. Probab., 32(2):1421–1458, 2022
2022
-
[65]
Motte and H
M. Motte and H. Pham. Quantitative propagation of chaos for mean field Markov decision process with common noise.Electron. J. Probab., 28:1–24, 2023
2023
-
[66]
Neufeld and J
A. Neufeld and J. Sester. RobustQ-learning algorithm for Markov decision processes under Wasserstein un- certainty.Automatica, 168:111825, 2024
2024
-
[67]
Panaganti, Z
K. Panaganti, Z. Xu, D. Kalathil, and M. Ghavamzadeh. Robust reinforcement learning using offline data. Adv. Neural Inf. Process. Syst., 35:32211–32224, 2022
2022
-
[68]
Pham and X
H. Pham and X. Wei. Discrete time McKean–Vlasov control problem: A dynamic programming approach. Appl. Math. Optim., 74(3):487–506, 2016
2016
-
[69]
Pham and X
H. Pham and X. Wei. Dynamic programming for optimal control of stochastic McKean–Vlasov dynamics. SIAM J. Control Optim., 55(2):1069–1101, 2017
2017
-
[70]
Qu and A
G. Qu and A. Wierman. Finite-time analysis of asynchronous stochastic approximation andQ-learning. In COLT, pages 3185–3205. PMLR, 2020
2020
-
[71]
Rashidinejad, B
P. Rashidinejad, B. Zhu, C. Ma, J. Jiao, and S. Russell. Bridging offline reinforcement learning and imitation learning: A tale of pessimism.IEEE Trans. Inf. Theory, 68(12):8156–8196, 2022
2022
-
[72]
Z. Ren, X. Wei, X. Yu, and X. Y. Zhou. Continuous-timeq-learning for mean-field control with common noise, Part I: Theoretical foundations.arXiv preprint arXiv:2604.27372, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[73]
Z. Ren, X. Wei, X. Yu, and X. Y. Zhou. Continuous-timeq-learning for mean-field control with common noise, Part II:q-learning algorithms.arXiv preprint arXiv:2604.27378, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[74]
Robbins and S
H. Robbins and S. Monro. A stochastic approximation method.Ann. Math. Stat., pages 400–407, 1951
1951
-
[75]
A. Roy, H. Xu, and S. Pokutta. Reinforcement learning under model mismatch.Adv. Neural Inf. Process. Syst., 30, 2017
2017
-
[76]
Sanjari and S
S. Sanjari and S. Yüksel. Optimal solutions to infinite-player stochastic teams and mean-field teams.IEEE Trans. Autom. Control, 66(3):1071–1086, 2020
2020
-
[77]
Sester and C
J. Sester and C. Decker.Q-learning under finite model uncertainty.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[78]
K. Shao, J. Shen, and M. Laurière. Reinforcement learning for finite space Mean-Field Type Game. InRein- forcement Learning Conference, 2025
2025
-
[79]
Subramanian and A
J. Subramanian and A. Mahajan. Reinforcement learning in stationary Mean-Field Games. InProceedings of the 18th International Conference on Autonomous Agents and Multiagent Systems, pages 251–259, 2019
2019
-
[80]
Szepesvári
C. Szepesvári. The asymptotic convergence-rate ofQ-learning.Adv. Neural Inf. Process. Syst., 10, 1997
1997
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.