The Token Tax of Epistemic Accuracy: Comparing RAG and Long-Context Architectures for Document-Grounded Generative AI Applications
Pith reviewed 2026-06-26 15:06 UTC · model grok-4.3
The pith
Long-context prompting reaches 73.1% correctness versus 65.4% for semantic RAG at 26 times the token cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
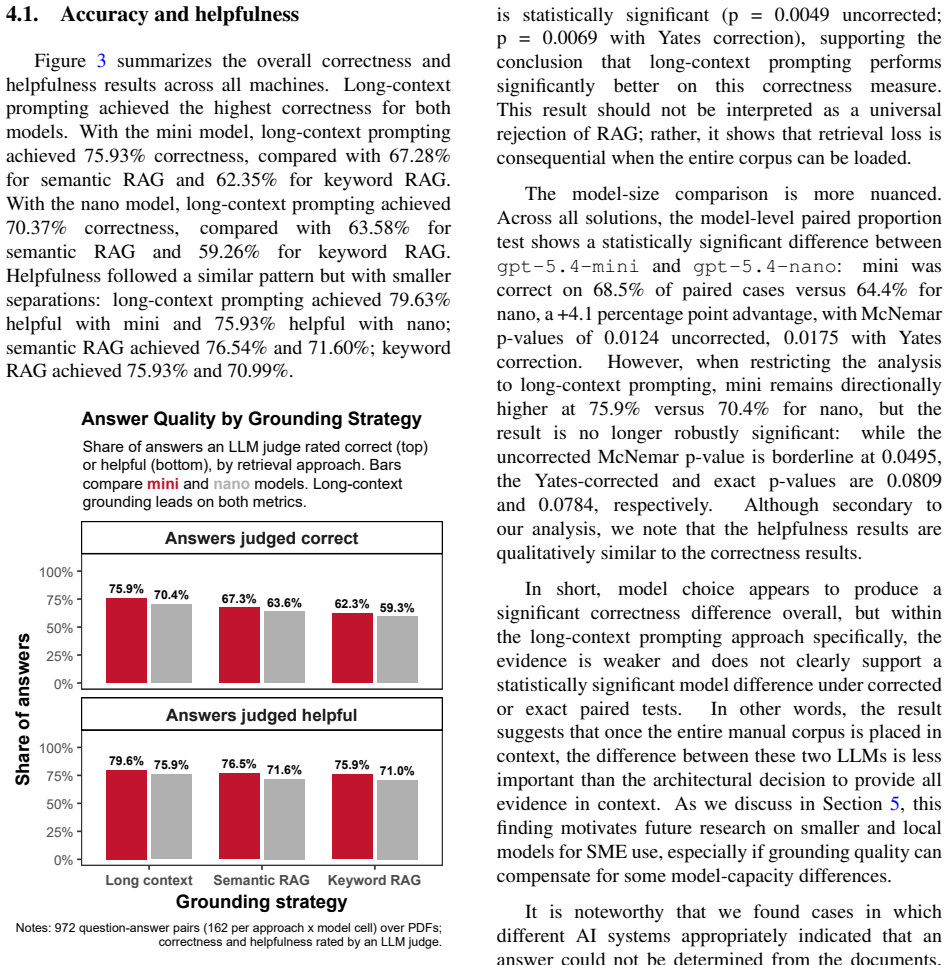
In an expert-validated benchmark of manufacturing safety questions evaluated across three machines and two small language models, long-context prompting produced 73.1 percent correct answers while semantic RAG produced 65.4 percent, at 26 times the per-query token cost; the authors interpret the difference as the token tax of broader evidentiary access.
What carries the argument
The accuracy-cost frontier between retrieval-augmented generation and long-context prompting as two regimes of epistemic access, where epistemic accuracy is defined as correctness that depends on having the right evidence available.
If this is right
- Organizations facing tight compute budgets can trade some correctness for substantially lower token usage by choosing RAG.
- Broader access improves correctness on knowledge-intensive, document-grounded tasks.
- The cost difference scales directly with the volume of context loaded at inference time.
- The tradeoff is relevant to any high-stakes setting that relies on large internal document collections.
Where Pith is reading between the lines
- More efficient context-handling techniques could shrink the size of the token tax over time.
- The same accuracy-cost pattern may appear in other document-heavy domains such as legal or technical support.
- Hybrid retrieval strategies might capture most of the accuracy gain without loading every document.
- The representativeness of the three-machine, two-model testbed limits how far the numerical gap can be generalized.
Load-bearing premise
The expert-validated benchmark isolates correctness gains due to evidentiary access rather than model-specific behaviors or differences in question difficulty.
What would settle it
Re-running the same benchmark questions with additional models or document collections and finding no accuracy gap between long-context and RAG would undermine the claimed benefit of broader access.
Figures


read the original abstract
Document-grounded assistants built on large language models are increasingly used in high-stakes, knowledge-intensive work. Their usefulness, however, may depend on how evidence is allocated before generation. We investigate such a claim by comparing two grounding architectures: (a) retrieval-augmented generation (RAG) that retrieves a few relevant passages, and (b) long-context prompting, which loads the whole document collection in context. We view these as two regimes of "epistemic access" on an accuracy--cost frontier. We use "epistemic accuracy" to capture model correctness that depends on having the right evidence. We posit that broader access (via long context) can increase it, but with a "token tax" (i.e., a substantial increase in cost due to larger input token consumption). We probe this framing with a case study in manufacturing safety training. Using an expert-validated benchmark, we evaluate 972 answers across three machines, two small language models, and three retrieval/in-context prompting approaches. Long-context prompting achieved the highest correctness (73.1% vs. 65.4% for semantic RAG), but at 26 times the per-query token cost. We interpret this gap as the token tax of broader evidentiary access. We carefully discuss the implications of our findings for resource-constrained organizations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically compares retrieval-augmented generation (RAG) and long-context prompting for document-grounded generative AI in a manufacturing safety training case study. On an expert-validated benchmark it evaluates 972 answers across three machines and two small language models, reporting that long-context prompting reaches 73.1% correctness versus 65.4% for semantic RAG at 26 times the per-query token cost; the difference is interpreted as the 'token tax' of broader evidentiary access, with implications discussed for resource-constrained organizations.
Significance. If the central interpretation holds after controls, the work supplies concrete, domain-specific numbers on the accuracy-cost frontier between RAG and long-context regimes. Strengths include the expert-validated benchmark, the 972-answer scale, the two-model/three-machine design, and the explicit framing for practitioners; these elements make the tradeoff claim falsifiable and potentially actionable.
major comments (3)
- [Evaluation protocol] Evaluation protocol (abstract and methods description of the 972-answer protocol): the design evaluates only RAG and long-context conditions and contains no zero-context or irrelevant-document control arm. Without this arm, correctness that would arise from parametric memory alone cannot be subtracted, so the 7.7-point gap cannot be cleanly attributed to differences in evidentiary access.
- [Results] Results paragraph reporting 73.1% vs. 65.4%: these percentages are presented without statistical significance tests, confidence intervals, or per-question difficulty controls. This leaves open whether the observed difference is reliable or confounded by question selection or model-specific behaviors, directly affecting the load-bearing claim that the gap measures the benefit of broader access.
- [Discussion] Discussion of the 26 imes token tax: the ratio is derived from the three-machine, two-model setup; the manuscript does not report sensitivity checks across model sizes or context lengths, which is required to support the general claim that the observed tax is characteristic of the architecture tradeoff rather than the specific experimental configuration.
minor comments (2)
- [Abstract] Abstract: the phrase 'three retrieval/in-context prompting approaches' is used but only semantic RAG and long-context are quantified; the third approach should be named and its results reported for completeness.
- [Methods] The manuscript would benefit from an explicit statement of the exact token-counting method (e.g., whether it includes system prompts or only retrieved passages) to allow replication of the 26 imes figure.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, indicating where the manuscript will be revised.
read point-by-point responses
-
Referee: [Evaluation protocol] Evaluation protocol (abstract and methods description of the 972-answer protocol): the design evaluates only RAG and long-context conditions and contains no zero-context or irrelevant-document control arm. Without this arm, correctness that would arise from parametric memory alone cannot be subtracted, so the 7.7-point gap cannot be cleanly attributed to differences in evidentiary access.
Authors: The study is scoped to compare two document-grounded architectures that both supply external evidence; the 7.7-point difference therefore isolates the marginal effect of broader versus narrower evidentiary access under grounded conditions. Parametric knowledge is a shared factor across both arms. We will add explicit language in the methods section clarifying this design scope and noting that a zero-context arm would address a different question (evidence presence versus absence). revision: partial
-
Referee: [Results] Results paragraph reporting 73.1% vs. 65.4%: these percentages are presented without statistical significance tests, confidence intervals, or per-question difficulty controls. This leaves open whether the observed difference is reliable or confounded by question selection or model-specific behaviors, directly affecting the load-bearing claim that the gap measures the benefit of broader access.
Authors: The referee correctly identifies the absence of statistical tests and controls. We will revise the results section to include McNemar's test for paired proportions, bootstrap-derived 95% confidence intervals on the correctness percentages, and a supplementary per-question difficulty breakdown to assess robustness against question selection and model-specific effects. revision: yes
-
Referee: [Discussion] Discussion of the 26 times token tax: the ratio is derived from the three-machine, two-model setup; the manuscript does not report sensitivity checks across model sizes or context lengths, which is required to support the general claim that the observed tax is characteristic of the architecture tradeoff rather than the specific experimental configuration.
Authors: The reported token ratio is tied to the specific two-model, three-machine configuration used. We will revise the discussion to present the figure as configuration-specific, add an explicit limitations paragraph acknowledging the lack of sensitivity checks across additional model scales or context lengths, and frame broader generalization as future work. revision: partial
Circularity Check
Empirical comparison with no derivation chain or fitted reductions
full rationale
The paper is a straightforward empirical case study that measures correctness and token costs across RAG and long-context conditions on an expert-validated benchmark. It reports direct experimental outcomes (73.1% vs 65.4% correctness, 26x token cost) without equations, parameter fitting, predictions derived from inputs, or self-citation chains that reduce the central claim to a tautology by construction. The interpretation of a 'token tax' is post-hoc framing of observed results rather than a load-bearing derivation, leaving the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
˚Agerfalk, P. J. (2020). Artificial intelligence as digital agency.European Journal of Information Systems,29(1), 1–8
2020
-
[2]
Bai, L., Huang, Z., Wang, X., Sun, J., Mihalcea, R., Brynjolfsson, E., Pentland, A., & Pei, J. (2026). How do AI agents spend your money? Analyzing and predicting token consumption in agentic coding tasks.arXiv preprint arXiv:2604.22750
Pith/arXiv arXiv 2026
-
[3]
Du, Z., Liu, X., Zeng, A., Hou, L., et al. (2024). Longbench: A bilingual, multitask benchmark for long context understanding.Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), 3119–3137
2024
-
[4]
Baird, A., & Maruping, L. M. (2021). The next generation of research on IS use: A theoretical framework of delegation to and from agentic IS artifacts.MIS Quarterly,45(1), 315–341
2021
-
[5]
Berente, N., Gu, B., Recker, J., & Santhanam, R. (2021). Managing artificial intelligence.MIS Quarterly,45(3), 1433–1450
2021
-
[6]
Buterin, V . (2021). Why sharding is great: Demystifying the technical properties [Accessed June 11, 2026]. https://vitalik.eth.limo/general/2021/ 04/07/sharding.html
2021
-
[7]
M., & Ward, J
Caldeira, M. M., & Ward, J. M. (2003). Using resource-based theory to interpret the successful adoption and use of information systems and technology in manufacturing small and medium-sized enterprises.European Journal of Information Systems,12(2), 127–141. Deloitte & The Manufacturing Institute. (2024). Taking charge: Manufacturers support growth with ac...
2003
-
[8]
Farquhar, S., Kossen, J., Kuhn, L., & Gal, Y . (2024). Detecting hallucinations in large language models using semantic entropy. Nature,630(8017), 625–630
2024
-
[9]
Folha, R., & Carvalho, A. (2024). Towards managing design science knowledge with large language models.Proceedings of the 30th Americas Conference on Information Systems. https : / / aisel.aisnet.org/amcis2024/ai aa/ai aa/9
2024
-
[10]
Bi, Y ., Dai, Y ., Sun, J., & Wang, H. (2024). Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997v5
Pith/arXiv arXiv 2024
-
[11]
Grybauskas, A., & Amran, A. (2022). Drivers and barriers of Industry 4.0 technology adoption among manufacturing SMEs: A systematic review and transformation roadmap.Journal of Manufacturing Technology Management,33(6), 1029–1058
2022
-
[12]
B., & Bøgh, S
Hansen, E. B., & Bøgh, S. (2021). Artificial intelligence and internet of things in small and medium-sized enterprises: A survey.Journal of Manufacturing Systems,58, 362–372. H¨ullermeier, E., & Waegeman, W. (2021). Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods.Machine Learning,110(3), 457–506
2021
-
[13]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., K ¨uttler, H., Lewis, M., Yih, W.-t., Rockt ¨aschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. In H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, & H. Lin (Eds.),Advances in Neural Information Processing Systems (pp. 9459...
2020
-
[14]
(2024, November)
Li, Z., Li, C., Zhang, M., Mei, Q., & Bendersky, M. (2024, November). Retrieval augmented generation or long-context LLMs? A comprehensive study and hybrid approach. In F. Dernoncourt, D. Preot ¸iuc-Pietro, & A. Shimorina (Eds.),Proceedings of the 2024 conference on empirical methods in natural language processing: Industry track (pp. 881–893)
2024
-
[15]
F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2024). Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics,12, 157–173
2024
-
[16]
M., Chen, Y .-J., Zwetsloot, I
Megahed, F. M., Chen, Y .-J., Zwetsloot, I. M., Knoth, S., Montgomery, D. C., & Jones-Farmer, L. A. (2024). Introducing ChatSQC: Enhancing statistical quality control with augmented AI.Journal of Quality Technology,56(5), 474–497
2024
-
[17]
Mikalef, P., & Gupta, M. (2021). Artificial intelligence capability: Conceptualization, measurement calibration, and empirical study on its impact on organizational creativity and firm performance.Information & Management, 58(3)
2021
-
[18]
A., Romero, D., & Wuest, T
Mittal, S., Khan, M. A., Romero, D., & Wuest, T. (2018). A critical review of smart manufacturing & Industry 4.0 maturity models: Implications for small and medium-sized enterprises (SMEs).Journal of manufacturing systems,49, 194–214
2018
-
[19]
Oldemeyer, L., Jede, A., & Teuteberg, F. (2025). Investigation of artificial intelligence in SMEs: A systematic review of the state of the art and the main implementation challenges. Management Review Quarterly,75(2), 1185–1227. OpenAI. (2025a). Gpt-5.4 mini model [Accessed: 2026-05-27]. https://developers.openai.com/ api/docs/models/gpt-5.4-mini OpenAI. ...
2025
-
[20]
Pan, G., Chodnekar, V ., Roy, A., & Wang, H. (2025). A cost-benefit analysis of on-premise large language model deployment: Breaking even with commercial LLM services.2025 IEEE International Conference on Big Data, 2234–2239
2025
-
[21]
Suganathan, P., Hui, H., . . . Seyedhosseini, M. (2026). Gemini embedding 2: A native multimodal embedding model from gemini. arXiv preprint arXiv:2605.27295
Pith/arXiv arXiv 2026
-
[22]
Mayyas, M., Cavuoto, L. A., & Megahed, F. M. (2026). A multimodal manufacturing safety chatbot: Knowledge base design, benchmark development, and evaluation of multiple RAG approaches.arXiv:2511.11847v2
arXiv 2026
-
[23]
Thong, J. Y . (1999). An integrated model of information systems adoption in small businesses.Journal of Management Information Systems,15(4), 187–214. U.S. Small Business Administration Office of Advocacy. (2025). Facts about small business: Manufacturing statistics 2025 [Accessed May 24, 2026]. https://advocacy.sba.gov/2025/03/ 10/facts-about-small-busi...
1999
-
[24]
Yu, T., Xu, A., & Akkiraju, R. (2024). In defense of RAG in the era of long-context language models.arXiv preprint arXiv:2409.01666. Data and Code A vailability Code and evaluation benchmarks are available at https://github.com/fmegahed/safety rag evaluation. Acknowledgments This work was funded by the Ohio Bureau of Workers’ Compensation Worker Safety In...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.