Revelio: Cost-Efficient Agentic Memory Safety Vulnerability Detection For Repository-Scale Codebases
Pith reviewed 2026-06-26 11:26 UTC · model grok-4.3
The pith
Revelio finds 19 new memory-safety bugs in long-fuzzed projects by requiring sanitizer-confirmed executable proofs from LLM agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
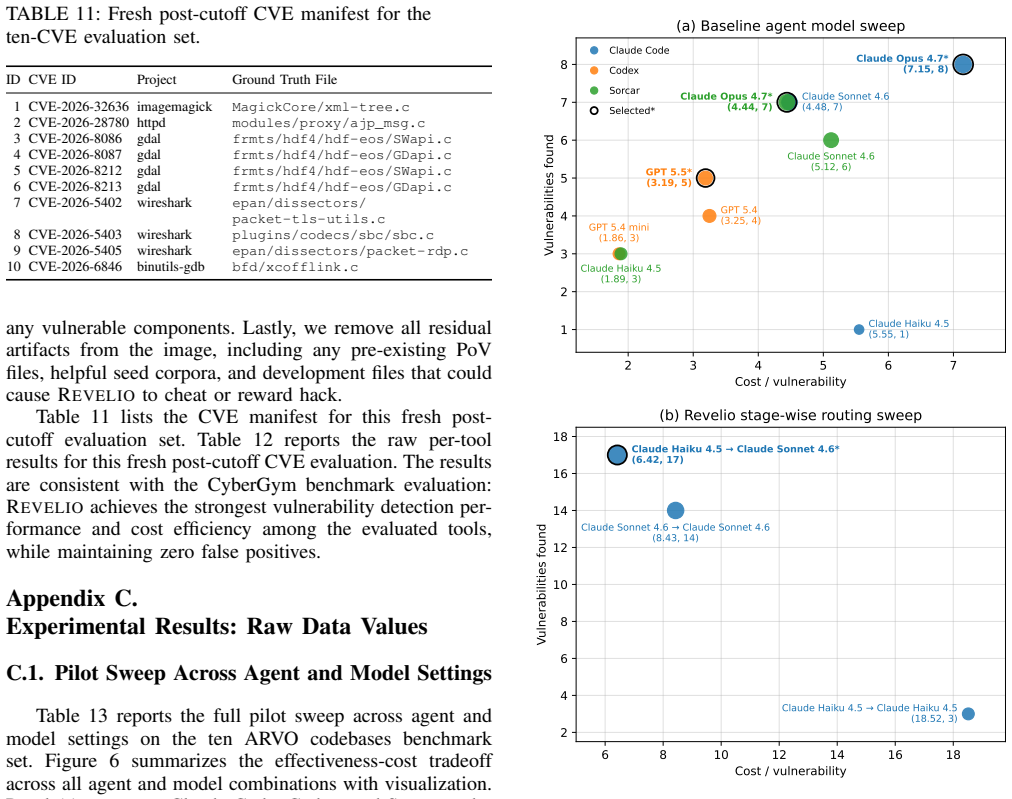
Revelio addresses LLM hallucination and scaling limits by combining cheap models and static analysis to rank hypotheses, then requiring each candidate to yield an executable proof of vulnerability that a sanitizer confirms as a real memory-safety issue; on the evaluated projects this process located 19 previously unknown vulnerabilities while staying under one hour and low dollar cost per project.
What carries the argument
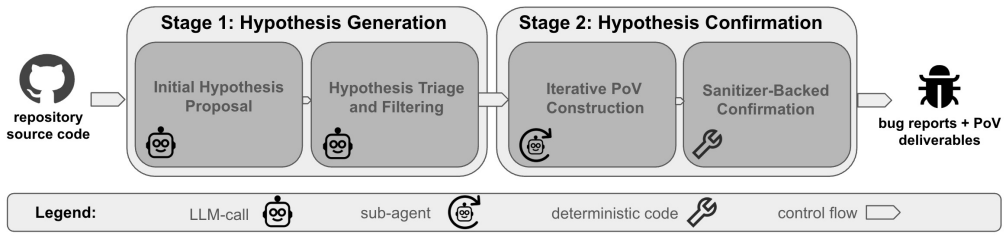
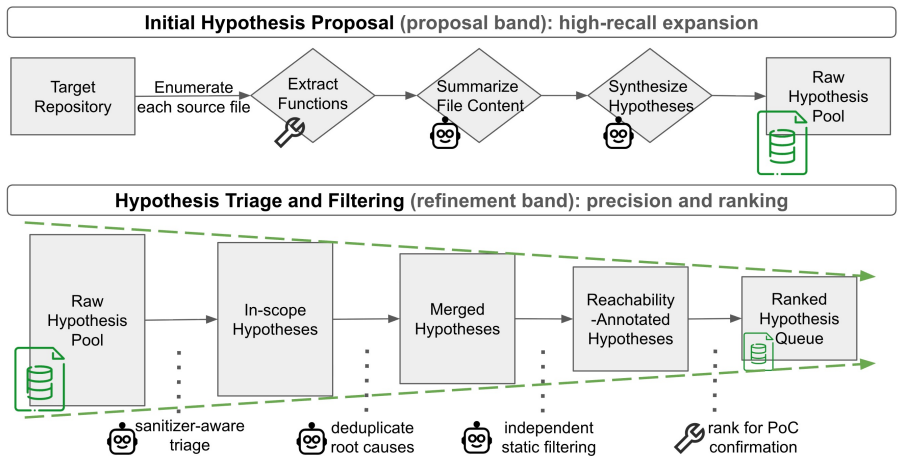
The Revelio pipeline, which filters and ranks LLM-generated vulnerability hypotheses with static analysis before attempting to synthesize and sanitizer-verify executable proofs of vulnerability.
If this is right
- Repository-scale memory-safety scanning becomes feasible with modest compute budgets when LLM calls are gated behind static-analysis ranking and execution confirmation.
- Projects that have already undergone years of fuzzing can still contain undiscovered memory-safety issues detectable by this targeted hypothesis-and-confirmation loop.
- Switching to cheaper backbone models does not reduce detection performance when the framework enforces sanitizer-verified executables rather than trusting model text alone.
Where Pith is reading between the lines
- The same hypothesis-generation-plus-confirmation structure could be adapted to other bug classes if an appropriate deterministic oracle replaces the sanitizer.
- Running Revelio as a post-fuzzing pass on existing corpora might systematically surface issues that random mutation-based fuzzers miss.
- The reported cost and time figures imply that periodic re-scans of mature codebases could be added to continuous-integration pipelines without large resource overhead.
Load-bearing premise
Sanitizer confirmation of a generated proof of vulnerability is enough to establish that the reported issue is a genuine, previously unknown memory-safety vulnerability.
What would settle it
Independent manual reproduction and root-cause analysis of any of the 19 reported vulnerabilities to check whether they are real, exploitable, and absent from prior public reports or the projects' own bug trackers.
Figures


read the original abstract
Memory safety vulnerabilities remain a significant threat even for projects with extensive fuzzing and manual auditing. Recent results suggest that large language models hold great promise for detecting such vulnerabilities, but they are unreliable, at risk of hallucination, and challenging to scale to repository-size codebases. This paper presents Revelio, a cost-efficient end-to-end agentic framework for memory-safety vulnerability discovery. Revelio addresses the problem of hallucination by generating an executable Proof-of-Vulnerability, which is checked with a deterministic sanitizer. It reduces cost using inexpensive LLMs and lightweight static analysis to help generate and rank vulnerability hypotheses, reporting vulnerabilities only when they can be reproduced and confirmed by a sanitizer. We evaluated Revelio on seven production-quality projects that had been continuously fuzzed for five to eight years, as well as on 100 randomly selected Arvo projects from the CyberGym benchmark. With around one hour per project and a total cost of $300, Revelio discovered 19 previously unknown memory-safety vulnerabilities. On benchmarks, Revelio outperformed frontier coding agents across diverse backbone models at comparable token costs. Our results suggest that Revelio enables scalable and trustworthy end-to-end LLM-based memory-safety vulnerability detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Revelio, an end-to-end agentic framework that combines inexpensive LLMs, lightweight static analysis, and deterministic sanitizers to generate executable Proofs-of-Vulnerability (PoVs) for memory-safety issues. It claims to discover 19 previously unknown vulnerabilities across seven production projects (continuously fuzzed for 5–8 years) and 100 Arvo/CyberGym projects, at roughly one hour per project and $300 total cost, while outperforming frontier coding agents on benchmarks.
Significance. If the 19 reported vulnerabilities are confirmed as genuine and novel, the work would demonstrate a practical, low-cost path to scaling LLM-based vulnerability discovery beyond what manual auditing or traditional fuzzing has achieved on mature codebases. The core idea of grounding LLM hypotheses in sanitizer-reproducible PoVs directly addresses hallucination concerns and could influence future agentic security tools.
major comments (1)
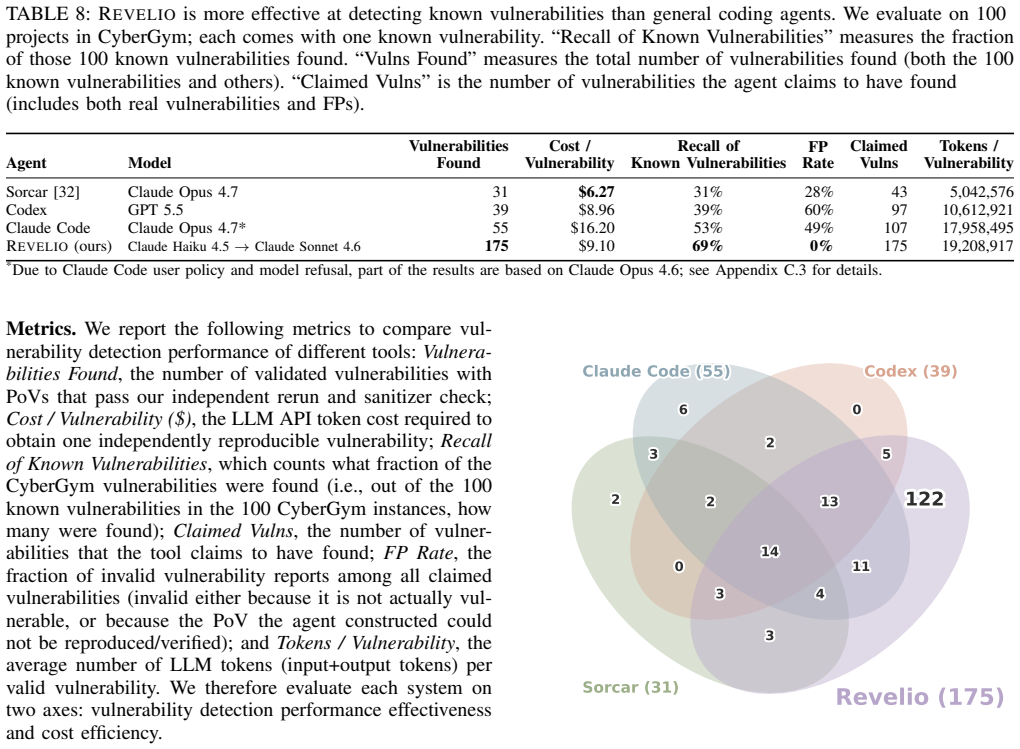
- [Section 4 / Evaluation] Evaluation / Section 4: The central claim that Revelio discovered 19 previously unknown memory-safety vulnerabilities rests entirely on automated sanitizer confirmation of generated PoVs plus the statement that the projects had been fuzzed for years. No manual triage, exploitability assessment, or cross-check against public bug trackers/CVEs is described for these cases. Sanitizer hits can arise from non-security-relevant paths (test harness artifacts, intentional UB, or environmental triggers), making this validation step load-bearing for the headline empirical result.
minor comments (2)
- [Abstract] Abstract: The high-level results are stated without any concrete description of the LLM backbones, static-analysis passes, or exact sanitizer configurations used; readers must reach the methods section to understand the pipeline.
- [Evaluation] The paper should clarify whether the 100 Arvo projects overlap with the seven production projects or constitute an independent test set.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation methodology. The concern about validation strength for the 19 reported vulnerabilities is well-taken, and we address it directly below while committing to targeted revisions.
read point-by-point responses
-
Referee: [Section 4 / Evaluation] Evaluation / Section 4: The central claim that Revelio discovered 19 previously unknown memory-safety vulnerabilities rests entirely on automated sanitizer confirmation of generated PoVs plus the statement that the projects had been fuzzed for years. No manual triage, exploitability assessment, or cross-check against public bug trackers/CVEs is described for these cases. Sanitizer hits can arise from non-security-relevant paths (test harness artifacts, intentional UB, or environmental triggers), making this validation step load-bearing for the headline empirical result.
Authors: We agree that sanitizer confirmation alone, while deterministic for detecting memory-safety violations, does not automatically establish security relevance or novelty in all cases, and that additional triage strengthens the claim. Revelio's design intentionally prioritizes reproducible PoVs over LLM assertions to mitigate hallucination, and the multi-year fuzzing history of the seven projects provides supporting context that these issues evaded prior detection. However, to directly address the load-bearing nature of the validation, the revised manuscript will expand Section 4 with: (1) explicit criteria used to filter sanitizer hits (e.g., excluding test harness artifacts and intentional UB via code inspection), (2) summary of manual review performed on the 19 cases for exploitability, and (3) results of cross-checks against public bug trackers and CVEs where available. We will also add a limitations paragraph noting residual uncertainty for any cases where full public disclosure was not possible. This revision will be made without altering the core empirical numbers. revision: yes
Circularity Check
No circularity: empirical evaluation of agentic framework
full rationale
The paper describes an empirical system (Revelio) for vulnerability discovery using LLMs, static analysis, and sanitizer confirmation. Its central claims rest on experimental runs that produced 19 confirmed PoVs on real projects and benchmarks. No mathematical derivations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the provided text. The sanitizer check is an external, deterministic oracle independent of the method's internal hypotheses. The result is therefore self-contained against external benchmarks rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introducing aardvark: Openai’s agentic security researcher
OpenAI, “Introducing aardvark: Openai’s agentic security researcher.” https://openai.com/index/introducing-aardvark/, OpenAI, 2025, (On- line; accessed on June 8, 2026)
2025
-
[2]
Claude security
Anthropic, “Claude security.” https://www.anthropic.com/product/ security, Anthropic, 2026, (Online; accessed on June 8, 2026)
2026
-
[3]
Synthesizing multi-agent harnesses for vulnerability dis- covery,
H. Liu, C. Shou, X. Liu, H. Wen, Y . Chen, R. J. Fang, and Y . Feng, “Synthesizing multi-agent harnesses for vulnerability dis- covery,”arXiv preprint arXiv:2604.20801, 2026
Pith/arXiv arXiv 2026
-
[4]
LLMs cannot reliably identify and reason about security vulnera- bilities (yet?): A comprehensive evaluation, framework, and bench- marks,
S. Ullah, M. Han, S. Pujar, H. Pearce, A. Coskun, and G. Stringhini, “LLMs cannot reliably identify and reason about security vulnera- bilities (yet?): A comprehensive evaluation, framework, and bench- marks,” inProceedings of the 45th IEEE Symposium on Security and Privacy (S&P). IEEE, 2024, pp. 862–880
2024
-
[5]
Benchmarking llms and llm-based agents in practical vulnerability detection for code repositories,
A. Yildiz, S. G. Teo, Y . Lou, Y . Feng, C. Wang, and D. M. Divakaran, “Benchmarking llms and llm-based agents in practical vulnerability detection for code repositories,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 30 848–30 865
2025
-
[6]
Vulnerability detection with code language models: How far are we?
Y . Ding, Y . Fu, O. Ibrahim, C. Sitawarin, X. Chen, B. Alomair, D. Wagner, B. Ray, and Y . Chen, “Vulnerability detection with code language models: How far are we?” inProceedings of the 47th IEEE/ACM International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 1729–1741
2025
-
[7]
From large to mammoth: A comparative evaluation of large language models in vulnerability detection,
J. Lin and D. Mohaisen, “From large to mammoth: A comparative evaluation of large language models in vulnerability detection,” in Proceedings of the Network and Distributed System Security Sympo- sium (NDSS), 2025
2025
-
[8]
Assessing claude mythos preview’s cybersecurity capa- bilities
Anthropic, “Assessing claude mythos preview’s cybersecurity capa- bilities.” https://red.anthropic.com/2026/mythos-preview/, Anthropic, 2026, (Online; accessed on June 8, 2026)
2026
-
[9]
Project glasswing: Securing critical software for the ai era
——, “Project glasswing: Securing critical software for the ai era.” https://www.anthropic.com/glasswing, Anthropic, 2026, (Online; ac- cessed on June 8, 2026)
2026
-
[10]
Project glasswing: Project glasswing: An initial up- date
——, “Project glasswing: Project glasswing: An initial up- date.” https://www.anthropic.com/research/glasswing-initial-update, Anthropic, 2026, (Online; accessed on June 8, 2026)
2026
-
[11]
RepoAudit: An autonomous LLM-agent for repository-level code auditing,
J. Guo, C. Wang, X. Xu, Z. Su, and X. Zhang, “RepoAudit: An autonomous LLM-agent for repository-level code auditing,” inPro- ceedings of the 42nd International Conference on Machine Learning (ICML), 2025, arXiv:2501.18160
arXiv 2025
-
[12]
AnyPoC: Universal proof-of-concept test generation for scalable llm- based bug detection,
Z. Zhao, C. Yang, W. Wang, Y . Yang, Z. Zhang, and L. Zhang, “AnyPoC: Universal proof-of-concept test generation for scalable llm- based bug detection,”arXiv preprint arXiv:2604.11950, 2026
Pith/arXiv arXiv 2026
-
[13]
Co-redteam: Orchestrated security discovery and exploitation with llm agents,
P. He, A. Fox, L. Miculicich, S. Friedli, D. Fabian, B. Gokturk, J. Tang, C.-Y . Lee, T. Pfister, and L. T. Le, “Co-redteam: Orchestrated security discovery and exploitation with llm agents,”arXiv preprint arXiv:2602.02164, 2026
arXiv 2026
-
[14]
Closing the gap: A user study on the real-world usefulness of AI-powered vulnerability detection & repair in the IDE,
B. Steenhoek, K. Sivaraman, R. S. Gonzalez, Y . Mohylevskyy, R. Z. Moghaddam, and W. Le, “Closing the gap: A user study on the real-world usefulness of AI-powered vulnerability detection & repair in the IDE,” in2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 2025, pp. 01–13
2025
-
[15]
Iris: Llm-assisted static analysis for detecting security vulnerabilities,
Z. Li, S. Dutta, and M. Naik, “Iris: Llm-assisted static analysis for detecting security vulnerabilities,” inThe Thirteenth International Conference on Learning Representations (ICLR), 2024
2024
-
[16]
LLMxCPG: Context-aware vulnerability detection through code property graph- guided large language models,
A. Lekssays, H. Mouhcine, K. Tran, T. Yu, and I. Khalil, “LLMxCPG: Context-aware vulnerability detection through code property graph- guided large language models,” inProceedings of the 34th USENIX Security Symposium (USENIX Security’25). USENIX Association, 2025, pp. 489–507
2025
-
[17]
Knighter: Transform- ing static analysis with llm-synthesized checkers,
C. Yang, Z. Zhao, Z. Xie, H. Li, and L. Zhang, “Knighter: Transform- ing static analysis with llm-synthesized checkers,” inProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles, 2025, pp. 655–669
2025
-
[18]
Let the trial begin: A mock- court approach to vulnerability detection using LLM-based agents,
R. Widyasari, M. Weyssow, I. C. Irsan, H. W. Ang, F. Liauw, E. L. Ouh, L. K. Shar, H. J. Kang, and D. Lo, “Let the trial begin: A mock- court approach to vulnerability detection using LLM-based agents,” inProceedings of the 48th IEEE/ACM International Conference on Software Engineering (ICSE’26), 2026, arXiv:2505.10961
arXiv 2026
-
[19]
OSS-Fuzz - Google’s continuous fuzzing service for open source software,
K. Serebryany, “OSS-Fuzz - Google’s continuous fuzzing service for open source software,” inProceedings of the 26th USENIX Security Symposium (USENIX Security ’17). Vancouver, BC: USENIX Association, 2017
2017
-
[20]
Arvo: Atlas of reproducible vulnerabilities for open source software,
X. Mei, P. S. Singaria, J. Del Castillo, H. Xi, T. Bao, R. Wang, Y . Shoshitaishvili, A. Doup´e, H. Pearce, B. Dolan-Gavittet al., “Arvo: Atlas of reproducible vulnerabilities for open source software,”arXiv preprint arXiv:2408.02153, 2024
Pith/arXiv arXiv 2024
-
[21]
Cyber- gym: Evaluating ai agents’ cybersecurity capabilities with real-world vulnerabilities at scale,
Z. Wang, T. Shi, J. He, M. Cai, J. Zhang, and D. Song, “Cyber- gym: Evaluating ai agents’ cybersecurity capabilities with real-world vulnerabilities at scale,”arXiv e-prints, pp. arXiv–2506, 2025
2025
-
[22]
CWE-125: Out-of-Bounds Read,
Common Weakness Enumeration, “CWE-125: Out-of-Bounds Read,” https://cwe.mitre.org/data/definitions/125.html, MITRE, (Online; ac- cessed on June 8, 2026)
2026
-
[23]
CWE-787: Out-of-Bounds Write,
——, “CWE-787: Out-of-Bounds Write,” https://cwe.mitre.org/data/ definitions/787.html, MITRE, (Online; accessed on June 8, 2026)
2026
-
[24]
CWE-416: Use After Free,
——, “CWE-416: Use After Free,” https://cwe.mitre.org/data/ definitions/416.html, MITRE, (Online; accessed on June 8, 2026)
2026
-
[25]
CWE-415: Double Free,
——, “CWE-415: Double Free,” https://cwe.mitre.org/data/ definitions/415.html, MITRE, (Online; accessed on June 8, 2026)
2026
-
[26]
CWE-457: Use of Uninitialized Variable,
——, “CWE-457: Use of Uninitialized Variable,” https://cwe.mitre. org/data/definitions/457.html, MITRE, (Online; accessed on June 8, 2026)
2026
-
[27]
{AddressSanitizer}: A fast address sanity checker,
K. Serebryany, D. Bruening, A. Potapenko, and D. Vyukov, “{AddressSanitizer}: A fast address sanity checker,” in2012 USENIX annual technical conference (USENIX ATC 12), 2012, pp. 309–318
2012
-
[28]
Memorysanitizer: fast detector of uninitialized memory use in c++,
E. Stepanov and K. Serebryany, “Memorysanitizer: fast detector of uninitialized memory use in c++,” in2015 IEEE/ACM International Symposium on Code Generation and Optimization (CGO). IEEE, 2015, pp. 46–55
2015
-
[29]
UndefinedBehaviorSanitizer,
LLVM Project, “UndefinedBehaviorSanitizer,” https://clang.llvm.org/ docs/UndefinedBehaviorSanitizer.html, 2013, accessed: Jun. 8, 2026
2013
-
[30]
Statically dis- cover cross-entry use-after-free vulnerabilities in the Linux kernel,
H. Zhang, J. Kim, C. Yuan, Z. Qian, and T. Kim, “Statically dis- cover cross-entry use-after-free vulnerabilities in the Linux kernel,” inProceedings of the 32nd Annual Network and Distributed System Security Symposium (NDSS). Internet Society, 2025
2025
-
[31]
The bitter lesson
R. S. Sutton, “The bitter lesson.” http://incompleteideas.net/IncIdeas/ BitterLesson.html, Personal website, 2019, (Online; accessed on May 25, 2026)
2019
-
[32]
Sen, “Sorcar.” https://kisssorcar.github.io/, UC Berkeley, 2026, (Online; accessed on June 3, 2026)
K. Sen, “Sorcar.” https://kisssorcar.github.io/, UC Berkeley, 2026, (Online; accessed on June 3, 2026)
2026
-
[33]
Claude code
Anthropic, “Claude code.” https://www.anthropic.com/product/ claude-code, Anthropic, 2026, (Online; accessed on June 3, 2026)
2026
-
[34]
Openai codex
OpenAI, “Openai codex.” https://chatgpt.com/codex, OpenAI, 2026, (Online; accessed on June 3, 2026)
2026
-
[35]
SIV A: Self-improving vulnerability agent,
V . Walischewski, G. Zizzo, and K. N. Webster, “SIV A: Self-improving vulnerability agent,” inNeurIPS 2025 Workshop: Reliable ML from Unreliable Data, 2025
2025
-
[36]
Opensage: Self-programming agent generation engine,
H. Li, Z. Wang, Q. Dai, Y . Nie, J. Peng, R. Liu, J. Zhang, K. Zhu, J. He, L. Wanget al., “Opensage: Self-programming agent generation engine,”arXiv preprint arXiv:2602.16891, 2026
arXiv 2026
-
[37]
SoK: DARPA’s AI Cyber Challenge (AIxCC): Competition Design, Architectures, and Lessons Learned,
C. Zhang, Y . Park, F. Fleischer, Y .-F. Fu, J. Kim, D. Kim, Y . Kim, Q. Xu, A. Chin, Z. Sheng, H. Zhao, M. Pelican, D. J. Musliner, J. Huang, J. Silliman, M. Mcdaniel, J. Casavant, I. Goldthwaite, N. Vidovich, M. Lehman, and T. Kim, “SoK: DARPA’s AI Cyber Challenge (AIxCC): Competition Design, Architectures, and Lessons Learned,”arXiv:2602.07666, 2025
Pith/arXiv arXiv 2025
-
[38]
ATLANTIS: AI-driven Threat Localization, Analysis, and Triage Intelligence System,
T. Kim, H. Han, S. Park, D. R. Jeong, D. Kim, D. Kim, E. Kim, J. Kim, J. Wang, K. Kim, S. Ji, W. Song, H. Zhao, A. Chin, G. Lee, K. Stevens, M. Alharthi, Y . Zhai, C. Zhang, J. Jang, Y . Jang, A. Askar, D. Kim, F. Fleischer, J. Cho, J. Kim, K. Ko, I. Yun, S. Park, D. Baik, H. Lee, H. Heo, M. Gwon, M. Lee, M. Baek, S. Min, W. Kim, Y . Jin, Y . Park, Y . Ch...
2025
-
[39]
Buttercup Cyber Reasoning System (CRS),
T. of Bits, “Buttercup Cyber Reasoning System (CRS),” 2025. [Online]. Available: https://github.com/trailofbits/buttercup
2025
-
[40]
ARTIPHISHELL: The Requiem
Shellphish, “ARTIPHISHELL: The Requiem.” [On- line]. Available: https://support.shellphish.net/blog/2025/08/22/ shellphish-x-aixcc-pm/
2025
-
[41]
Project Naptime: Evaluating Offensive Security Capabilities of Large Language Models
S. Glazunov and M. Brand, “Project Naptime: Evaluating Offensive Security Capabilities of Large Language Models.” [Online]. Available: https://projectzero.google/2024/06/project-naptime.html
2024
-
[42]
From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code
Google, “From Naptime to Big Sleep: Using Large Language Models To Catch Vulnerabilities In Real-World Code.” [Online]. Available: https://projectzero.google/2024/10/from-naptime-to-big-sleep.html
2024
-
[43]
One bug, hundreds behind: Llms for large-scale bug discovery,
Q. Wu, Y . Xiao, D. Kirat, K. Eykholt, J. Jang, and D. L. Schales, “One bug, hundreds behind: Llms for large-scale bug discovery,”arXiv preprint arXiv:2510.14036, 2025
arXiv 2025
-
[44]
Large language model for vulnerabil- ity detection: Emerging results and future directions,
X. Zhou, T. Zhang, and D. Lo, “Large language model for vulnerabil- ity detection: Emerging results and future directions,” inProceedings of the 2024 ACM/IEEE 44th International Conference on Software Engineering: New Ideas and Emerging Results, 2024, pp. 47–51
2024
-
[45]
Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag,
X. Du, G. Zheng, K. Wang, Y . Zou, Y . Wang, W. Deng, J. Feng, M. Liu, B. Chen, X. Penget al., “Vul-rag: Enhancing llm-based vulnerability detection via knowledge-level rag,”ACM Transactions on Software Engineering and Methodology, 2024
2024
-
[46]
Ctx- coder: Cross-attention architectures empower llms for long-context vulnerability detection,
J. Wang, K. Zheng, B. Wu, C. Wu, Y . Yao, J. Gao, and M. Yang, “Ctx- coder: Cross-attention architectures empower llms for long-context vulnerability detection,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI’26), vol. 40, no. 2, 2026, pp. 1159–1167
2026
-
[47]
A sequential multi- stage approach for code vulnerability detection via confidence-and collaboration-based decision making,
C.-N. Tsai, X. Wang, C.-H. Lee, and C.-S. Lin, “A sequential multi- stage approach for code vulnerability detection via confidence-and collaboration-based decision making,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025, pp. 21 162–21 168
2025
-
[48]
F. Liu, S. Liu, Y . Zhu, X. Lian, and L. Zhang, “Securereviewer: Enhancing large language models for secure code review through secure-aware fine-tuning,”arXiv preprint arXiv:2510.26457, 2025
arXiv 2025
-
[49]
Hogvul: Black-box adversarial code generation framework against lm-based vulnerabil- ity detectors,
J. Yang, P. He, T. Du, S. Bing, and X. Zhang, “Hogvul: Black-box adversarial code generation framework against lm-based vulnerabil- ity detectors,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI’26), 2026
2026
-
[50]
Artemis: Toward accurate detection of server-side request forgeries through llm-assisted inter- procedural path-sensitive taint analysis,
Y . Ji, T. Dai, Z. Zhou, Y . Tang, and J. He, “Artemis: Toward accurate detection of server-side request forgeries through llm-assisted inter- procedural path-sensitive taint analysis,”Proceedings of the ACM on Programming Languages, vol. 9, no. OOPSLA1, pp. 1349–1377, 2025
2025
-
[51]
SEC-bench: Automated benchmarking of LLM agents on real-world software security tasks,
H. Lee, Z. Zhang, H. Lu, and L. Zhang, “SEC-bench: Automated benchmarking of LLM agents on real-world software security tasks,” inThe Thirty-ninth Annual Conference on Neural Information Pro- cessing Systems (NeurIPS), 2025
2025
-
[52]
{AFL++}: Combining incremental steps of fuzzing research,
A. Fioraldi, D. Maier, H. Eißfeldt, and M. Heuse, “{AFL++}: Combining incremental steps of fuzzing research,” in14th USENIX workshop on offensive technologies (WOOT 20), 2020
2020
-
[53]
Magma: A ground-truth fuzzing benchmark,
A. Hazimeh, A. Herrera, and M. Payer, “Magma: A ground-truth fuzzing benchmark,”Proceedings of the ACM on Measurement and Analysis of Computing Systems, vol. 4, no. 3, pp. 1–29, 2020
2020
-
[54]
Fuzzbench: an open fuzzer benchmarking platform and service,
J. Metzman, L. Szekeres, L. Simon, R. Sprabery, and A. Arya, “Fuzzbench: an open fuzzer benchmarking platform and service,” in Proceedings of the 29th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering, 2021, pp. 1393–1403
2021
-
[55]
Large language model guided protocol fuzzing,
R. Meng, M. Mirchev, M. B ¨ohme, and A. Roychoudhury, “Large language model guided protocol fuzzing,” inProceedings of the 31st Annual Network and Distributed System Security Symposium (NDSS). Internet Society, 2024
2024
-
[56]
Fuzz4all: Universal fuzzing with large language models,
C. S. Xia, M. Paltenghi, J. Le Tian, M. Pradel, and L. Zhang, “Fuzz4all: Universal fuzzing with large language models,” inPro- ceedings of the IEEE/ACM 46th International Conference on Software Engineering, 2024, pp. 1–13
2024
-
[57]
Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models,
Y . Deng, C. S. Xia, H. Peng, C. Yang, and L. Zhang, “Large language models are zero-shot fuzzers: Fuzzing deep-learning libraries via large language models,” inProceedings of the 32nd ACM SIGSOFT international symposium on software testing and analysis, 2023, pp. 423–435
2023
-
[58]
Kernelgpt: Enhanced kernel fuzzing via large language models,
C. Yang, Z. Zhao, and L. Zhang, “Kernelgpt: Enhanced kernel fuzzing via large language models,” inProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, 2025, pp. 560–573
2025
-
[59]
A comparative study of fuzzers and static analysis tools for finding memory unsafety in c and c++,
K. Hassler, P. G ¨orz, S. Lipp, T. Holz, and M. B ¨ohme, “A comparative study of fuzzers and static analysis tools for finding memory unsafety in c and c++,”arXiv preprint arXiv:2505.22052, 2025
arXiv 2025
-
[60]
{V1SCAN}: Discovering 1-day vulnerabilities in reused{C/C++}open-source software components using code classification techniques,
S. Woo, E. Choi, H. Lee, and H. Oh, “{V1SCAN}: Discovering 1-day vulnerabilities in reused{C/C++}open-source software components using code classification techniques,” in32nd USENIX Security Sym- posium (USENIX Security 23), 2023, pp. 6541–6556
2023
-
[61]
Detecting kernel memory bugs through inconsistent memory management intention inferences,
D. Liu, Z. Lu, S. Ji, K. Lu, J. Chen, Z. Liu, D. Liu, R. Cai, and Q. He, “Detecting kernel memory bugs through inconsistent memory management intention inferences,” inProceedings of the 33rd USENIX Security Symposium (USENIX Security ’24). USENIX Association, 2024, pp. 4069–4086
2024
-
[62]
An empirical study of static analysis tools for secure code review,
W. Charoenwet, P. Thongtanunam, V .-T. Pham, and C. Treude, “An empirical study of static analysis tools for secure code review,” in Proceedings of the 33rd ACM SIGSOFT international symposium on software testing and analysis, 2024, pp. 691–703
2024
-
[63]
An empirical study on the effectiveness of static c code analyzers for vulnerability detection,
S. Lipp, S. Banescu, and A. Pretschner, “An empirical study on the effectiveness of static c code analyzers for vulnerability detection,” inProceedings of the 31st ACM SIGSOFT international symposium on software testing and analysis, 2022, pp. 544–555
2022
-
[64]
E. Firouzi and M. Ghafari, “Persistent human feedback, llms, and static analyzers for secure code generation and vulnerability detec- tion,”arXiv preprint arXiv:2602.05868, 2026. Appendix A. Prompts for LLM Calls A.1. REVELIOHypothesis Generation stage Regarding Initial Hypothesis Proposal, to form the raw hypothesis pool: Prompt to form per-file summariz...
arXiv 2026
-
[65]
same_vulnerability
Which sanitizer(s) would catch a correct PoV? Asan (heap/stack/global OOB, UAF, double-free, stack-overflow, etc), UBSan (signed integer overflow, shift-beyond-width, null- deref, misaligned, etc), MSan (use of uninitialized memory). 6. Severity: critical/highmedium/low/none. 7. CWEs (up to 3). Markis_vulnerability=falsefor: code quality, dead code, alway...
-
[66]
final report [hypothesis id].md
If no crash: analyze the output, refine your approach, and re- peat from step 2. 6. If crash confirmed: call‘finish‘with the results. 7. If you have exhaustedmax_validate_attempts validation attempts without a crash, call‘finish‘with status ‘failure’. Context Packet: the orchestrator will provide ‘context_packet‘containing the selected hypothesis. Use it ...
-
[67]
Identify candidate memory safety bugs and, for each, state the file, line(s), bug class, and the input condition that should trigger it
HYPOTHESIZE: read the harness entry point and the code it reaches. Identify candidate memory safety bugs and, for each, state the file, line(s), bug class, and the input condition that should trigger it
-
[68]
success” if you produced at least one hypothesis, else “failure
CONFIRM: for each promising hypothesis, write a generator script, produce a PoV , call‘validate‘, and iterate until the harness crashes (or your per-PoV validate budget is exhausted). When you give up on one hypothesis, move on to the next. You interact with the system by calling tools. Every response MUST include exactly ONE tool call:‘bash‘,‘validate‘, ...
-
[69]
If no crash: analyze the output, refine your approach, and re- peat from step 2. 6. If crash confirmed: call‘finish‘with the results. 7. If you have exhaustedmax_validate_attempts validation attempts without a crash, call‘finish‘with status ‘failure’. Limits: 1. You may call‘validate‘at most max_validate_attemptstimes. 2. Do NOT modify the harness or proj...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.