Learning to Evade: Adaptive Attacks on Audio Watermarking
Pith reviewed 2026-06-26 10:08 UTC · model grok-4.3
The pith
An adaptive attack steers audio watermark decoder probabilities into estimated normal ranges to evade detection.
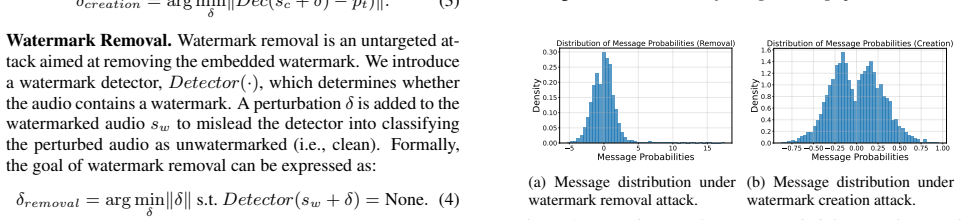
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
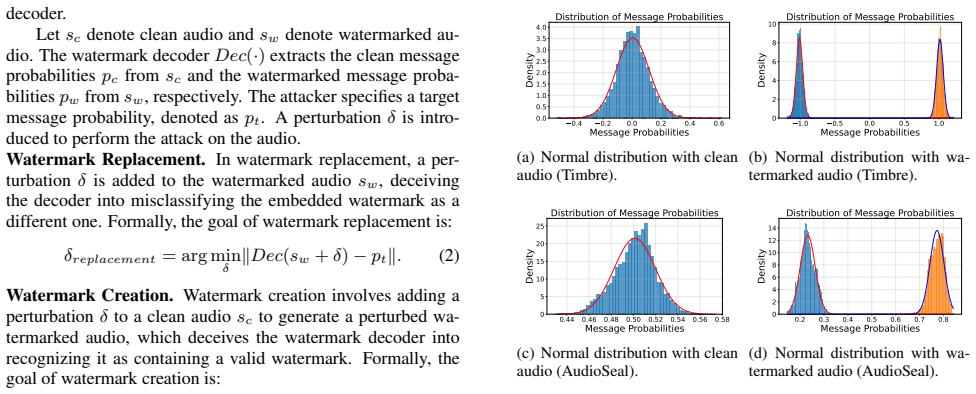
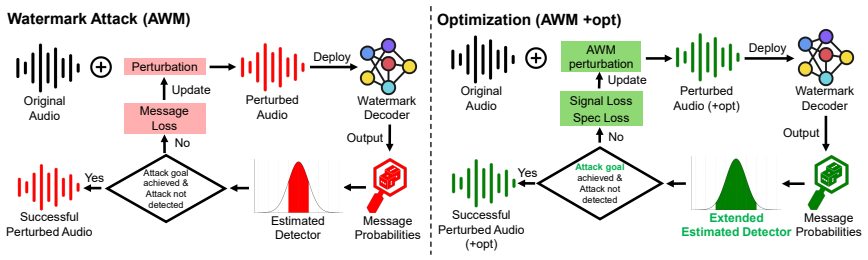
Watermark decoder message probabilities follow normal distributions, a property that can be estimated from limited samples of the target audio. AWM uses a two-stage optimization where the first stage ensures attack success on the watermark and the second improves audio quality, while adaptively steering decoded probabilities into the estimated normal range to bypass detectors.
What carries the argument
Two-stage optimization that estimates normal distribution parameters from limited target audio samples and steers decoded message probabilities back into the estimated range.
If this is right
- AWM succeeds against two different watermarking methods on three voice datasets.
- Detection rates fall below 10 percent for replacement and creation attacks.
- Removal attacks achieve 0 percent detection rate.
- The method maintains high attack success while producing usable audio output.
Where Pith is reading between the lines
- Watermark systems may need to adopt output distributions that resist quick estimation from small sample sets.
- Detectors could add checks that do not rely solely on normality assumptions.
- Real-world watermark deployment in generative audio tools may require ongoing adaptation against such steering attacks.
Load-bearing premise
Watermark decoder message probabilities follow normal distributions that can be estimated accurately from limited samples of the target audio.
What would settle it
An experiment showing that the attack no longer keeps detection rates low when the probability outputs deviate from normality or when accurate parameter estimates require far more than a few samples.
Figures





read the original abstract
Advances in generative audio have intensified copyright concerns, making audio watermarking increasingly important for asserting ownership. However, existing audio watermarking methods are vulnerable to adversarial attacks. We find that watermark decoder message probabilities follow normal distributions, a property exploited by defenses to detect manipulations. This paper introduces an adaptive audio watermark attack method (AWM) designed to bypass existing defense strategies. AWM uses a two-stage optimization: the first stage ensures attack success, while the second improves audio quality. To evade detection, it estimates normal distribution parameters from limited samples of the target audio, and then adaptively steers decoded probabilities back into the estimated range. Evaluated on two watermarking methods across three voice datasets, AWM achieves high success while bypassing state-of-the-art detectors: detection rates are below 10% for replacement and creation, and 0% for removal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an adaptive attack method called AWM for evading audio watermarking detectors. It exploits the observation that watermark decoder message probabilities follow normal distributions by estimating their parameters from limited target audio samples and steering the decoded probabilities into the estimated range during a two-stage optimization process. The first stage focuses on attack success, the second on audio quality. Evaluations on two watermarking methods and three voice datasets show high attack success with detection rates below 10% for replacement and creation attacks and 0% for removal attacks.
Significance. Should the central claims be substantiated, particularly the normality assumption and the empirical evasion results, the paper would make a notable contribution to the field of audio watermarking security by illustrating how adaptive attacks can circumvent existing detectors. This could prompt the development of more robust watermarking techniques that do not rely on distributional assumptions vulnerable to estimation from limited samples.
major comments (2)
- [Abstract] Abstract: The evasion strategy depends on the assumption that watermark decoder message probabilities follow normal distributions estimable from limited target samples; no statistical tests, Q-Q plots, or validation for this normality (for either of the two evaluated watermarking methods) are referenced, yet this property is required for the second-stage steering to produce the claimed detection rates below 10% without degrading first-stage attack success.
- [Abstract] Abstract: The reported detection rates (below 10% for replacement/creation, 0% for removal) rest on the accuracy of parameter estimation from 'limited samples'; the manuscript supplies no sample sizes, variance of the estimates, or ablation on how estimation error affects evasion, which directly bears on whether the low detection rates are reproducible or an artifact of the specific datasets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The evasion strategy depends on the assumption that watermark decoder message probabilities follow normal distributions estimable from limited target samples; no statistical tests, Q-Q plots, or validation for this normality (for either of the two evaluated watermarking methods) are referenced, yet this property is required for the second-stage steering to produce the claimed detection rates below 10% without degrading first-stage attack success.
Authors: We acknowledge that the current manuscript does not include explicit statistical validation (e.g., Q-Q plots or formal normality tests) for the observed normal distribution of decoder probabilities. In the revised version we will add Q-Q plots and Shapiro-Wilk test results for both watermarking methods across the evaluated datasets to substantiate the assumption. revision: yes
-
Referee: [Abstract] Abstract: The reported detection rates (below 10% for replacement/creation, 0% for removal) rest on the accuracy of parameter estimation from 'limited samples'; the manuscript supplies no sample sizes, variance of the estimates, or ablation on how estimation error affects evasion, which directly bears on whether the low detection rates are reproducible or an artifact of the specific datasets.
Authors: We agree that details on sample sizes for distribution estimation, variance of the parameter estimates, and sensitivity analysis are missing. The revised manuscript will report the exact number of samples used per dataset, include variance/confidence intervals for the estimated parameters, and add an ablation study examining how estimation error propagates to final detection rates. revision: yes
Circularity Check
No circularity: empirical attack method with independent evaluation
full rationale
The paper presents an adaptive attack (AWM) that observes normality in decoder probabilities, estimates parameters from limited target samples, and steers outputs to evade detectors. Success is reported via measured detection rates (<10% replacement/creation, 0% removal) on evaluated datasets and watermarking methods. No equations, derivations, or self-citations reduce these outcomes to fitted inputs by construction; the estimation step is a practical heuristic whose effectiveness is tested externally rather than assumed tautologically. The central claim remains falsifiable through the reported experiments.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Watermark decoder message probabilities follow normal distributions that defenses exploit for manipulation detection
Reference graph
Works this paper leans on
-
[1]
Learning to Evade: Adaptive Attacks on Audio Watermarking
Introduction In recent years, the rapid growth of social networking plat- forms has encouraged many users to publicly share their audio content, including original works such as audiobooks and self- produced music. These audio contents might bring them in- come. However, many unauthorized users copy creative works, modify them, and re-upload them to mains...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
These schemes follow the architecture of the Encoder- Distortion-Decoder
Related Work Deep Learning-Based Audio Watermarking.Unlike tradi- tional schemes [13], which rely on predefined transformations, deep-learning-based schemes can learn complex feature repre- sentations and optimize watermarking dynamically [4, 5, 14, 15, 16]. These schemes follow the architecture of the Encoder- Distortion-Decoder. The encoder embeds the w...
-
[3]
Preliminary Adding perturbations to the audio is a common strategy for at- tacks against watermarking systems
Background 3.1. Preliminary Adding perturbations to the audio is a common strategy for at- tacks against watermarking systems. The core idea is to either destroy the original watermark or forge a new one by introduc- ing perturbations that deceive the watermark decoder. Audio Watermark Decoder .The audio watermark decoder Dec(·)takes the encoded audio as ...
-
[4]
The defenders are the attack detectors, who identify whether audio has been tampered with
they are aware that the decoded message probabilities output by the watermark decoder follow a normal distribution, but they do not know the corresponding mean and standard deviation. The defenders are the attack detectors, who identify whether audio has been tampered with. We assume that: 1) defenders have access to a large number of ground-truth audio s...
-
[5]
attacked
Methodology In this section, we first introduce a detection method based on outlier detection to identify if the given audio sample has been attacked. Second, we design our adaptive attack, which aims to achieve a successful attack while preserving perceptual quality. Meanwhile, we describe the adaptive optimization process for the three attack types. Det...
-
[6]
For the indices not included inmsg dif f, we assign the original watermark message probabilitiesp w to the corresponding target watermark message probabilitiesp t
In this case, msgdif f = [1,3]. For the indices not included inmsg dif f, we assign the original watermark message probabilitiesp w to the corresponding target watermark message probabilitiesp t. That is, for indices[0,2,4,5], thep t is equal to thep w. This optimization has two advantages: (1) It directs the gra- dient to focus more on the indices where ...
-
[7]
Evaluation 5.1. Experimental Setup Datasets.We use three public datasets for our experiments. The first dataset is the LibriSpeech [36]. We select the small-sized subset, which has 6.3G audios, and covers 100.6 hours of audio data spoken by 251 speakers. The second dataset is obtained from AudioMarkData [8], which is built based on the Common V oice datas...
-
[8]
We show that defenders can leverage this statis- tical regularity to distinguish benign from attacked signals
Conclusion In this work, we analyze watermark decoder outputs and ob- serve that they exhibit approximately normal distributions on benign audio. We show that defenders can leverage this statis- tical regularity to distinguish benign from attacked signals. To demonstrate the fragility of such defenses, we introduce AWM, an adaptive audio watermark attack....
-
[9]
National Science Foundation under Grant CNS-2310207, CNS-2520900, CNS- 2451168
Acknowledgments This work was supported in part by the U.S. National Science Foundation under Grant CNS-2310207, CNS-2520900, CNS- 2451168
-
[10]
All tech- nical contents were conceived, conducted, and verified by the authors, which include the methodology, experiments, analysis, etc
Generative AI Use Disclosure The authors used generative AI tools such as ChatGPT solely for grammar improvement and language polishing. All tech- nical contents were conceived, conducted, and verified by the authors, which include the methodology, experiments, analysis, etc. The authors take full responsibility for the content of the publication
-
[11]
(2023, May) Beware the artificial impostor
McAfee. (2023, May) Beware the artificial impostor. a mcafee cybersecurity artificial intelligence report. [On- line]. Available: https://www.mcafee.com/content/dam/ consumer/en-us/resources/cybersecurity/artificial-intelligence/ rp-beware-the-artificial-impostor-report.pdf
2023
-
[12]
Copyright protection in generative ai: A technical perspective,
J. Ren, H. Xu, P. He, Y . Cui, S. Zeng, J. Zhang, H. Wen, J. Ding, P. Huang, L. Lyuet al., “Copyright protection in generative ai: A technical perspective,”arXiv preprint arXiv:2402.02333, 2024
-
[13]
Dear: A deep-learning-based audio re-recording resilient watermarking,
C. Liu, J. Zhang, H. Fang, Z. Ma, W. Zhang, and N. Yu, “Dear: A deep-learning-based audio re-recording resilient watermarking,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 11, 2023, pp. 13 201–13 209
2023
-
[14]
De- tecting voice cloning attacks via timbre watermarking,
C. Liu, J. Zhang, T. Zhang, X. Yang, W. Zhang, and N. Yu, “De- tecting voice cloning attacks via timbre watermarking,” inNet- work and Distributed System Security Symposium, 2024
2024
-
[15]
Proactive detection of voice cloning with localized watermarking,
R. San Roman, P. Fernandez, H. Elsahar, A. D´efossez, T. Furon, and T. Tran, “Proactive detection of voice cloning with localized watermarking,”ICML, 2024
2024
-
[16]
Wm- codec: End-to-end neural speech codec with deep watermarking for authenticity verification,
J. Zhou, J. Yi, Y . Ren, J. Tao, T. Wang, and C. Y . Zhang, “Wm- codec: End-to-end neural speech codec with deep watermarking for authenticity verification,” inICASSP 2025-2025 IEEE Inter- national Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[17]
Sok: How robust is audio watermarking in generative ai models?
Y . Wen, A. Innuganti, A. B. Ramos, H. Guo, and Q. Yan, “Sok: How robust is audio watermarking in generative ai models?” arXiv preprint arXiv:2503.19176, 2025
-
[18]
Audiomark- bench: Benchmarking robustness of audio watermarking,
H. Liu, M. Guo, Z. Jiang, L. Wang, and N. Gong, “Audiomark- bench: Benchmarking robustness of audio watermarking,”Ad- vances in Neural Information Processing Systems, vol. 37, pp. 52 241–52 265, 2024
2024
-
[19]
Can simple averag- ing defeat modern watermarks?
P. Yang, H. Ci, Y . Song, and M. Z. Shou, “Can simple averag- ing defeat modern watermarks?”Advances in Neural Information Processing Systems, vol. 37, pp. 56 644–56 673, 2024
2024
-
[20]
Sok: How robust is image classification deep neural network watermarking?
N. Lukas, E. Jiang, X. Li, and F. Kerschbaum, “Sok: How robust is image classification deep neural network watermarking?” in 2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022, pp. 787–804
2022
-
[21]
{ASSET}: Ro- bust backdoor data detection across a multiplicity of deep learn- ing paradigms,
M. Pan, Y . Zeng, L. Lyu, X. Lin, and R. Jia, “{ASSET}: Ro- bust backdoor data detection across a multiplicity of deep learn- ing paradigms,” in32nd USENIX Security Symposium (USENIX Security 23), 2023, pp. 2725–2742
2023
-
[22]
Find- ing needles in a haystack: A black-box approach to invisible wa- termark detection,
M. Pan, Z. Wang, X. Dong, V . Sehwag, L. Lyu, and X. Lin, “Find- ing needles in a haystack: A black-box approach to invisible wa- termark detection,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 253–270
2024
-
[23]
Twenty years of digital audio watermarking—a comprehensive review,
G. Hua, J. Huang, Y . Q. Shi, J. Goh, and V . L. Thing, “Twenty years of digital audio watermarking—a comprehensive review,” Signal processing, vol. 128, pp. 222–242, 2016
2016
-
[24]
Wavmark: Watermarking for audio generation,
G. Chen, Y . Wu, S. Liu, T. Liu, X. Du, and F. Wei, “Wav- mark: Watermarking for audio generation,”arXiv preprint arXiv:2308.12770, 2023
-
[25]
Audio codec augmentation for robust col- laborative watermarking of speech synthesis,
L. Juvela and X. Wang, “Audio codec augmentation for robust col- laborative watermarking of speech synthesis,” inICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[26]
Silent- cipher: Deep audio watermarking
M. K. Singh, N. Takahashi, W.-H. Liao, and Y . Mitsufuji, “Silent- cipher: Deep audio watermarking.” inINTERSPEECH, 2024
2024
-
[27]
High Fidelity Neural Audio Compression
A. D ´efossez, J. Copet, G. Synnaeve, and Y . Adi, “High fidelity neural audio compression,”arXiv preprint arXiv:2210.13438, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
J.-c. Chou, C.-c. Yeh, and H.-y. Lee, “One-shot voice conversion by separating speaker and content representations with instance normalization,”arXiv preprint arXiv:1904.05742, 2019
-
[29]
Fragmentvc: Any-to-any voice conversion by end-to-end extract- ing and fusing fine-grained voice fragments with attention,
Y . Y . Lin, C.-M. Chien, J.-H. Lin, H.-y. Lee, and L.-s. Lee, “Fragmentvc: Any-to-any voice conversion by end-to-end extract- ing and fusing fine-grained voice fragments with attention,” in ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 5939– 5943
2021
-
[30]
Natural tts synthesis by conditioning wavenet on mel spectrogram pre- dictions,
J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y . Zhang, Y . Wang, R. Skerrv-Ryanet al., “Natural tts synthesis by conditioning wavenet on mel spectrogram pre- dictions,” in2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018, pp. 4779– 4783
2018
-
[31]
Fastspeech 2: Fast and high-quality end-to-end text to speech,
Y . Ren, C. Hu, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y . Liu, “Fastspeech 2: Fast and high-quality end-to-end text to speech,” arXiv preprint arXiv:2006.04558, 2020
-
[32]
Hopskipjumpattack: A query-efficient decision-based attack,
J. Chen, M. I. Jordan, and M. J. Wainwright, “Hopskipjumpattack: A query-efficient decision-based attack,” in2020 ieee symposium on security and privacy (sp). IEEE, 2020, pp. 1277–1294
2020
-
[33]
Square attack: a query-efficient black-box adversarial attack via random search,
M. Andriushchenko, F. Croce, N. Flammarion, and M. Hein, “Square attack: a query-efficient black-box adversarial attack via random search,” inEuropean conference on computer vision. Springer, 2020, pp. 484–501
2020
-
[34]
Towards evaluating the robustness of neural networks,
N. Carlini and D. Wagner, “Towards evaluating the robustness of neural networks,” in2017 ieee symposium on security and privacy (sp). Ieee, 2017, pp. 39–57
2017
-
[35]
Towards Deep Learning Models Resistant to Adversarial Attacks
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,” arXiv preprint arXiv:1706.06083, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[36]
Evading watermark based de- tection of ai-generated content,
Z. Jiang, J. Zhang, and N. Z. Gong, “Evading watermark based de- tection of ai-generated content,” inProceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, 2023, pp. 1168–1181
2023
-
[37]
Clap learning audio concepts from natural language supervision,
B. Elizalde, S. Deshmukh, M. Al Ismail, and H. Wang, “Clap learning audio concepts from natural language supervision,” in ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023, pp. 1–5
2023
-
[38]
Robust speech recognition via large-scale weak supervision,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervision,” inInternational conference on machine learning. PMLR, 2023, pp. 28 492–28 518
2023
-
[39]
A re- view on outlier/anomaly detection in time series data,
A. Bl ´azquez-Garc´ıa, A. Conde, U. Mori, and J. A. Lozano, “A re- view on outlier/anomaly detection in time series data,”ACM com- puting surveys (CSUR), vol. 54, no. 3, pp. 1–33, 2021
2021
-
[40]
TimesNet: Temporal 2D-Variation Modeling for General Time Series Analysis
H. Wu, T. Hu, Y . Liu, H. Zhou, J. Wang, and M. Long, “Timesnet: Temporal 2d-variation modeling for general time series analysis,” arXiv preprint arXiv:2210.02186, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Dire for diffusion-generated image detection,
Z. Wang, J. Bao, W. Zhou, W. Wang, H. Hu, H. Chen, and H. Li, “Dire for diffusion-generated image detection,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 445–22 455
2023
-
[42]
Organic or diffused: Can we dis- tinguish human art from ai-generated images?
A. Y . J. Ha, J. Passananti, R. Bhaskar, S. Shan, R. Southen, H. Zheng, and B. Y . Zhao, “Organic or diffused: Can we dis- tinguish human art from ai-generated images?” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Commu- nications Security, 2024, pp. 4822–4836
2024
-
[43]
Detect- ing music deepfakes is easy but actually hard,
D. Afchar, G. Meseguer-Brocal, and R. Hennequin, “Detect- ing music deepfakes is easy but actually hard,”arXiv preprint arXiv:2405.04181, 2024
-
[44]
Singfake: Singing voice deepfake detection,
Y . Zang, Y . Zhang, M. Heydari, and Z. Duan, “Singfake: Singing voice deepfake detection,” inICASSP 2024-2024 IEEE Interna- tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 12 156–12 160
2024
-
[45]
Conjugate bayesian analysis of the gaussian dis- tribution,
K. P. Murphy, “Conjugate bayesian analysis of the gaussian dis- tribution,”def, vol. 1, no. 2σ2, p. 16, 2007
2007
-
[46]
Lib- rispeech: an asr corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: an asr corpus based on public domain audio books,” in2015 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2015, pp. 5206–5210
2015
-
[47]
Common voice: A massively-multilingual speech corpus,
R. Ardila, M. Branson, K. Davis, M. Henretty, M. Kohler, J. Meyer, R. Morais, L. Saunders, F. M. Tyers, and G. Weber, “Common voice: A massively-multilingual speech corpus,”arXiv preprint arXiv:1912.06670, 2019
-
[48]
Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio,
G. Chen, S. Chai, G. Wang, J. Du, W.-Q. Zhang, C. Weng, D. Su, D. Povey, J. Trmal, J. Zhanget al., “Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio,” arXiv preprint arXiv:2106.06909, 2021
-
[49]
Visqol: an objective speech quality model,
A. Hines, J. Skoglund, A. C. Kokaram, and N. Harte, “Visqol: an objective speech quality model,”EURASIP Journal on Audio, Speech, and Music Processing, vol. 2015, pp. 1–18, 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.