FlowDec: Temporal Conditional Flow Decorruptor for Robust Continuous Vision-Language Navigation
Pith reviewed 2026-06-26 10:22 UTC · model grok-4.3
The pith
FlowDec restores corrupted images for vision-language navigation agents by conditioning generative flows on temporal history and filtering outputs via action centroids.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
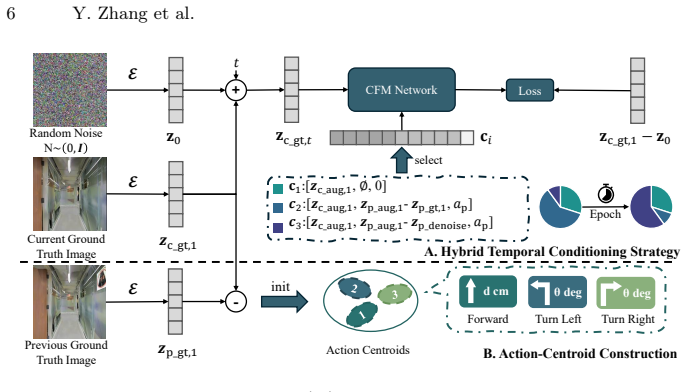
FlowDec integrates a hybrid temporal conditioning strategy to align the generative flow path with historical context and employs action-centroid guided filtering to dynamically assess and integrate outputs, resulting in superior performance in navigation accuracy and generation latency for VLN-CE tasks under visual corruptions.
What carries the argument
Temporal Conditional Flow Decorruptor (FlowDec), a generative flow framework that aligns restoration with historical context through hybrid conditioning and integrates outputs via action-centroid guided filtering.
Load-bearing premise
The hybrid temporal conditioning strategy aligns the generative flow path with historical context and the action-centroid guided filtering reliably integrates outputs.
What would settle it
Applying FlowDec to a new set of visual corruption types or a different large model backbone and measuring no gain in navigation accuracy or an increase in latency would falsify the performance claim.
Figures







read the original abstract
Vision-and-Language Navigation in Continuous Environments (VLN-CE) requires agents to follow natural-language instructions in unseen scenes. While Large Models (LMs) have advanced VLN-CE, their performance remains severely degraded by real-world visual corruptions, a critical yet underexplored domain constraint. We introduce Temporal Conditional Flow Decorruptor (FlowDec), a novel image restoration framework tailored for LM-based VLN-CE. FlowDec integrates a hybrid temporal conditioning strategy to align the generative flow path with historical context and employs action-centroid guided filtering to dynamically assess and integrate outputs. Extensive experiments demonstrate that FlowDec outperforms state-of-the-art decorruption methods in both navigation accuracy and generation latency. Our approach establishes a robust, efficient paradigm for resilient embodied navigation in unpredictable real-world conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlowDec, a temporal conditional flow decorruptor for robust Vision-and-Language Navigation in Continuous Environments (VLN-CE). It proposes a hybrid temporal conditioning strategy to align generative flow paths with historical context and an action-centroid guided filtering mechanism to assess and integrate outputs. The central claim is that extensive experiments show FlowDec outperforms state-of-the-art decorruption methods in navigation accuracy and generation latency.
Significance. If the performance claims hold with proper validation, the work would address a practical gap in deploying large-model VLN-CE agents under real-world visual corruptions, potentially offering an efficient flow-based restoration paradigm that integrates temporal history and action guidance.
major comments (1)
- [Abstract] Abstract: the claim that 'extensive experiments demonstrate that FlowDec outperforms state-of-the-art decorruption methods in both navigation accuracy and generation latency' is unsupported by any data, baselines, tables, figures, error bars, or method details, which is load-bearing for the paper's primary empirical contribution.
Simulated Author's Rebuttal
We thank the referee for the review and the opportunity to clarify. We respond point-by-point to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'extensive experiments demonstrate that FlowDec outperforms state-of-the-art decorruption methods in both navigation accuracy and generation latency' is unsupported by any data, baselines, tables, figures, error bars, or method details, which is load-bearing for the paper's primary empirical contribution.
Authors: We agree that the abstract's empirical claim requires explicit supporting evidence in the manuscript. The current version provides only the abstract and does not include the referenced data, baselines, tables, figures, error bars, or method details. We will revise the abstract to remove or qualify the unsupported claim and add the necessary experimental sections with proper validation in the next version. revision: yes
Circularity Check
No circularity detected; abstract contains no equations, derivations, or self-referential claims
full rationale
The provided abstract and reader summary contain no equations, parameter-fitting steps, self-citations, or uniqueness theorems. Claims of outperformance are empirical assertions without any derivation chain that could reduce to inputs by construction. No load-bearing steps match any enumerated circularity pattern, so the paper's central claims cannot be shown to be circular from the given text. This is the expected outcome when no technical derivation is visible.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
On Evaluation of Embodied Navigation Agents
Anderson, P., Chang, A., Chaplot, D.S., Dosovitskiy, A., Gupta, S., Koltun, V., Kosecka, J., Malik, J., Mottaghi, R., Savva, M., et al.: On evaluation of embodied navigation agents. arXiv preprint arXiv:1807.06757 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
In: Conference on Robot Learning
Anderson, P., Shrivastava, A., Truong, J., Majumdar, A., Parikh, D., Batra, D., Lee, S.: Sim-to-real transfer for vision-and-language navigation. In: Conference on Robot Learning. pp. 671–681. PMLR (2021)
2021
-
[3]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Anderson, P., Wu, Q., Teney, D., Bruce, J., Johnson, M., Sünderhauf, N., Reid, I., Gould, S., Van Den Hengel, A.: Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3674–3683 (2018)
2018
-
[4]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.: pi_0 : A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18392–18402 (2023)
2023
-
[6]
arXiv preprint arXiv:2401.07314 (2024)
Chen, J., Lin, B., Xu, R., Chai, Z., Liang, X., Wong, K.Y.K.: Mapgpt: Map-guided prompting with adaptive path planning for vision-and-language navigation. arXiv preprint arXiv:2401.07314 (2024)
-
[7]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Chen, J., Chen, J., Chao, H., Yang, M.: Image blind denoising with generative adversarial network based noise modeling. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 3155–3164 (2018)
2018
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Chen, S., Guhur, P.L., Tapaswi, M., Schmid, C., Laptev, I.: Think global, act local: Dual-scale graph transformer for vision-and-language navigation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16537–16547 (2022)
2022
-
[9]
SceneGraphFusion: Incremental 3d scene graph prediction from RGB-d sequences,
Chen, X., He, K.: Exploring simple siamese representation learning. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (Jun 2021).https://doi.org/10.1109/cvpr46437.2021.01549,http://dx.doi. org/10.1109/cvpr46437.2021.01549
-
[10]
arXiv preprint arXiv:2412.04453 (2024)
Cheng,A.C.,Ji,Y.,Yang,Z.,Gongye,Z.,Zou,X.,Kautz,J.,Bıyık,E.,Yin,H.,Liu, S., Wang, X.: Navila: Legged robot vision-language-action model for navigation. arXiv preprint arXiv:2412.04453 (2024)
-
[11]
See https://vicuna.lmsys.org2(3), 6 (2023)
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., et al.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna.lmsys.org2(3), 6 (2023)
2023
-
[12]
Zhang et al
Contributors, I.: InternNav: InternRobotics’ open platform for building generalized navigation foundation models.https://github.com/InternRobotics/InternNav (2025) 16 Y. Zhang et al
2025
-
[13]
Dao, Q., Phung, H., Nguyen, B., Tran, A.: Flow matching in latent space. arXiv preprint arXiv:2307.08698 (2023)
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gao, J., Zhang, J., Liu, X., Darrell, T., Shelhamer, E., Wang, D.: Back to the source: Diffusion-driven adaptation to test-time corruption. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11786– 11796 (2023)
2023
-
[15]
arXiv preprint arXiv:2311.13209 (2023)
Gao, J., Yao, X., Xu, C.: Fast-slow test-time adaptation for online vision-and- language navigation. arXiv preprint arXiv:2311.13209 (2023)
-
[16]
In: 2nd CoRL Workshop on Learning Effective Abstractions for Planning (2024)
Gode, S., Nayak, A., Burgard, W.: Flownav: Learning efficient navigation poli- cies via conditional flow matching. In: 2nd CoRL Workshop on Learning Effective Abstractions for Planning (2024)
2024
-
[17]
In: Proceedings of the Computer Vision and Pattern Recogni- tion Conference
Guo, J., Zhao, J., Du, C., Wang, Y., Ge, C., Ni, Z., Song, S., Shi, H., Huang, G.: Everything to the synthetic: Diffusion-driven test-time adaptation via synthetic- domain alignment. In: Proceedings of the Computer Vision and Pattern Recogni- tion Conference. pp. 30503–30513 (2025)
2025
-
[18]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Guo, S., Yan, Z., Zhang, K., Zuo, W., Zhang, L.: Toward convolutional blind denoising of real photographs. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1712–1722 (2019)
2019
-
[19]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hendrycks, D., Zou, A., Mazeika, M., Tang, L., Li, B., Song, D., Steinhardt, J.: Pixmix: Dreamlike pictures comprehensively improve safety measures. In: 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (Jun 2022).https://doi.org/10.1109/cvpr52688.2022.01628,http://dx.doi. org/10.1109/cvpr52688.2022.01628
-
[20]
arXiv preprint arXiv:2501.17403 (2025)
Hong, H., Qiao, Y., Wang, S., Liu, J., Wu, Q.: General scene adaptation for vision- and-language navigation. arXiv preprint arXiv:2501.17403 (2025)
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kamath, A., Anderson, P., Wang, S., Koh, J.Y., Ku, A., Waters, A., Yang, Y., Baldridge, J., Parekh, Z.: A new path: Scaling vision-and-language navigation with synthetic instructions and imitation learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10813–10823 (2023)
2023
-
[22]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
arXiv: Machine Learn- ing,arXiv: Machine Learning (Dec 2013)
Kingma, D., Welling, M.: Auto-encoding variational bayes. arXiv: Machine Learn- ing,arXiv: Machine Learning (Dec 2013)
2013
-
[24]
In: European Confer- ence on Computer Vision
Krantz, J., Wijmans, E., Majumdar, A., Batra, D., Lee, S.: Beyond the nav-graph: Vision-and-language navigation in continuous environments. In: European Confer- ence on Computer Vision. pp. 104–120. Springer (2020)
2020
-
[25]
arXiv preprint arXiv:2010.07954 (2020)
Ku, A., Anderson, P., Patel, R., Ie, E., Baldridge, J.: Room-across-room: Multilin- gual vision-and-language navigation with dense spatiotemporal grounding. arXiv preprint arXiv:2010.07954 (2020)
-
[26]
International Journal of Computer Vision133(1), 31–64 (2025)
Liang, J., He, R., Tan, T.: A comprehensive survey on test-time adaptation under distribution shifts. International Journal of Computer Vision133(1), 31–64 (2025)
2025
-
[27]
In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision
Lin, K., Chen, P., Huang, D., Li, T.H., Tan, M., Gan, C.: Learning vision-and- language navigation from youtube videos. In: Proceedings of the IEEE/CVF In- ternational Conference on Computer Vision. pp. 8317–8326 (2023)
2023
-
[28]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022) FlowDec 17
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
arXiv preprint arXiv:2406.04882 (2024)
Long, Y., Cai, W., Wang, H., Zhan, G., Dong, H.: Instructnav: Zero-shot sys- tem for generic instruction navigation in unexplored environment. arXiv preprint arXiv:2406.04882 (2024)
-
[31]
Science robotics 7(62), eabk2822 (2022)
Miki, T., Lee, J., Hwangbo, J., Wellhausen, L., Koltun, V., Hutter, M.: Learning robust perceptive locomotion for quadrupedal robots in the wild. Science robotics 7(62), eabk2822 (2022)
2022
-
[32]
In: International conference on machine learning
Niu, S., Wu, J., Zhang, Y., Chen, Y., Zheng, S., Zhao, P., Tan, M.: Efficient test- time model adaptation without forgetting. In: International conference on machine learning. pp. 16888–16905. PMLR (2022)
2022
-
[33]
arXiv preprint arXiv:2302.12400 (2023)
Niu, S., Wu, J., Zhang, Y., Wen, Z., Chen, Y., Zhao, P., Tan, M.: Towards sta- ble test-time adaptation in dynamic wild world. arXiv preprint arXiv:2302.12400 (2023)
-
[34]
In: European Conference on Computer Vision
Oh, Y., Lee, J., Choi, J., Jung, D., Hwang, U., Yoon, S.: Efficient diffusion-driven corruption editor for test-time adaptation. In: European Conference on Computer Vision. pp. 184–201. Springer (2024)
2024
-
[35]
arXiv preprint arXiv:2310.07889 (2023)
Pan, B., Panda, R., Jin, S., Feris, R., Oliva, A., Isola, P., Kim, Y.: Lang- nav: Language as a perceptual representation for navigation. arXiv preprint arXiv:2310.07889 (2023)
-
[36]
Artificial Intelligence Review p
Park, S.M., Kim, Y.G.: Visual language navigation: a survey and open challenges. Artificial Intelligence Review p. 365–427 (Jan 2023).https://doi.org/10.1007/ s10462-022-10174-9,http://dx.doi.org/10.1007/s10462-022-10174-9
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Qi, Y., Wu, Q., Anderson, P., Wang, X., Wang, W.Y., Shen, C., Hengel, A.v.d.: Reverie: Remote embodied visual referring expression in real indoor environments. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9982–9991 (2020)
2020
-
[38]
In: Proceedings of the IEEE/CVF international conference on computer vision
Savva, M., Kadian, A., Maksymets, O., Zhao, Y., Wijmans, E., Jain, B., Straub, J., Liu, J., Koltun, V., Malik, J., et al.: Habitat: A platform for embodied ai research. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9339–9347 (2019)
2019
-
[39]
IEEE Transactions on Multimedia (2025)
Tan, M., Chen, P., Zhi, H., Mai, J., Rosman, B., Ji, D., Zeng, R.: Source-free elastic model adaptation for vision-and-language navigation. IEEE Transactions on Multimedia (2025)
2025
-
[40]
Improving and generalizing flow-based generative models with minibatch optimal transport
Tong, A., Fatras, K., Malkin, N., Huguet, G., Zhang, Y., Rector-Brooks, J., Wolf, G.,Bengio,Y.:Improvingandgeneralizingflow-basedgenerativemodelswithmini- batch optimal transport. arXiv preprint arXiv:2302.00482 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Tsai, Y.Y., Chen, F.C., Chen, A.Y., Yang, J., Su, C.C., Sun, M., Kuo, C.H.: Gda: Generalized diffusion for robust test-time adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 23242– 23251 (2024)
2024
-
[42]
Tent: Fully Test-time Adaptation by Entropy Minimization
Wang, D., Shelhamer, E., Liu, S., Olshausen, B., Darrell, T.: Tent: Fully test-time adaptation by entropy minimization. arXiv preprint arXiv:2006.10726 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[43]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, Q., Fink, O., Van Gool, L., Dai, D.: Continual test-time domain adaptation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7201–7211 (2022)
2022
-
[44]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Yang, J., Yang, S., Gupta, A.W., Han, R., Fei-Fei, L., Xie, S.: Thinking in space: How multimodal large language models see, remember, and recall spaces. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 10632– 10643 (2025)
2025
-
[45]
Advances in neural information pro- cessing systems32(2019) 18 Y
Yue, Z., Yong, H., Zhao, Q., Meng, D., Zhang, L.: Variational denoising network: Toward blind noise modeling and removal. Advances in neural information pro- cessing systems32(2019) 18 Y. Zhang et al
2019
-
[46]
arXiv preprint arXiv:2509.22548 (2025)
Zeng, S., Qi, D., Chang, X., Xiong, F., Xie, S., Wu, X., Liang, S., Xu, M., Wei, X.: Janusvln: Decoupling semantics and spatiality with dual implicit memory for vision-language navigation. arXiv preprint arXiv:2509.22548 (2025)
-
[47]
Uni-NaVid: A Video-based Vision-Language-Action Model for Unifying Embodied Navigation Tasks
Zhang, J., Wang, K., Wang, S., Li, M., Liu, H., Wei, S., Wang, Z., Zhang, Z., Wang, H.: Uni-navid: A video-based vision-language-action model for unifying embodied navigation tasks. arXiv preprint arXiv:2412.06224 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
NaVid: Video-based VLM Plans the Next Step for Vision-and-Language Navigation
Zhang, J., Wang, K., Xu, R., Zhou, G., Hong, Y., Fang, X., Wu, Q., Zhang, Z., Wang, H.: Navid: Video-based vlm plans the next step for vision-and-language navigation. arXiv preprint arXiv:2402.15852 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
Machine Intelligence Research20(6), 822–836 (2023)
Zhang, K., Li, Y., Liang, J., Cao, J., Zhang, Y., Tang, H., Fan, D.P., Timofte, R., Gool, L.V.: Practical blind image denoising via swin-conv-unet and data synthesis. Machine Intelligence Research20(6), 822–836 (2023)
2023
-
[50]
Vision-and-language navigation today and tomorrow: A survey in the era of foundation models
Zhang, Y., Ma, Z., Li, J., Qiao, Y., Wang, Z., Chai, J., Wu, Q., Bansal, M., Ko- rdjamshidi, P.: Vision-and-language navigation today and tomorrow: A survey in the era of foundation models. arXiv preprint arXiv:2407.07035 (2024)
-
[51]
In: Proceedings of the 33rd ACM International Conference on Multimedia
Zhang, Y., Xu, Y., Wei, H., Lin, Z., Zou, X., Chen, C., Zhuang, H.: Analytic continual test-time adaptation for multi-modality corruption. In: Proceedings of the 33rd ACM International Conference on Multimedia. pp. 1929–1937 (2025)
1929
-
[52]
In: European Confer- ence on Computer Vision
Zhou, G., Hong, Y., Wang, Z., Wang, X.E., Wu, Q.: Navgpt-2: Unleashing naviga- tional reasoning capability for large vision-language models. In: European Confer- ence on Computer Vision. pp. 260–278. Springer (2024)
2024
-
[53]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhou, G., Hong, Y., Wu, Q.: Navgpt: Explicit reasoning in vision-and-language navigation with large language models. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 7641–7649 (2024)
2024
-
[54]
In: Conference on Robot Learning
Zitkovich, B., Yu, T., Xu, S., Xu, P., Xiao, T., Xia, F., Wu, J., Wohlhart, P., Welker, S., Wahid, A., et al.: Rt-2: Vision-language-action models transfer web knowledge to robotic control. In: Conference on Robot Learning. pp. 2165–2183. PMLR (2023) FlowDec 19 A Pseudo-code for FlowDec Thepseudocodefor the FlowDec is shown in two phases. – Training(Algor...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.