Metis: Bridging Text and Code Memory for Self-Evolving Agents
Pith reviewed 2026-06-26 00:41 UTC · model grok-4.3
The pith
Self-evolving agents perform better with both text and code memory of experience rather than one form chosen at design time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
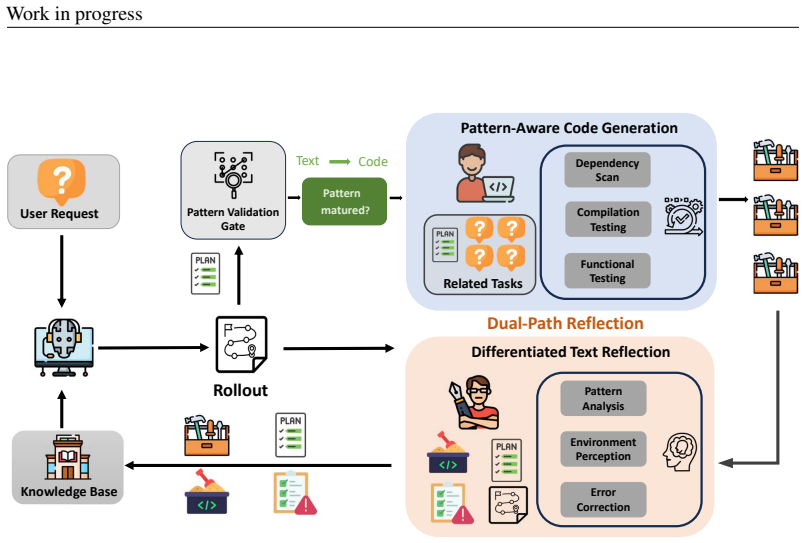
Metis organizes textual experience into execution plans, environment facts, and common pitfalls, then selectively crystallizes recurring plans into validated callable tools, thereby combining the broad applicability of text memory with the execution efficiency of code memory and incurring tool-generation cost only when justified by repeated reuse.
What carries the argument
hierarchical dual-representation memory that organizes textual experience into execution plans, environment facts, and common pitfalls and selectively crystallizes recurring plans into validated callable tools
If this is right
- Text memory and code memory show complementary trade-offs in construction cost, execution efficiency, and transferability.
- Neither representation alone reaches the accuracy-efficiency balance achieved when both are available.
- Tool-generation cost is paid only when repeated reuse makes the investment worthwhile.
- The dual design produces a better overall trade-off among accuracy, execution efficiency, and memory-construction cost than single-representation self-evolving systems.
Where Pith is reading between the lines
- The same selective-crystallization logic could be applied to other memory contents such as facts or pitfalls once reuse patterns emerge.
- Agents might learn to predict reuse frequency in advance and decide representation type before any execution occurs.
- The controlled-study method used here could be repeated on benchmarks with different interaction lengths or error distributions to test generality.
Load-bearing premise
The accuracy and cost improvements come from the dual text-versus-code memory design itself rather than from other implementation choices or from properties specific to the AppWorld benchmark.
What would settle it
An ablation that keeps the same hierarchical memory but removes the selective conversion of recurring plans to code tools, or a replication of the full system on a different interactive-agent benchmark, would show whether the dual-representation mechanism drives the reported gains.
Figures
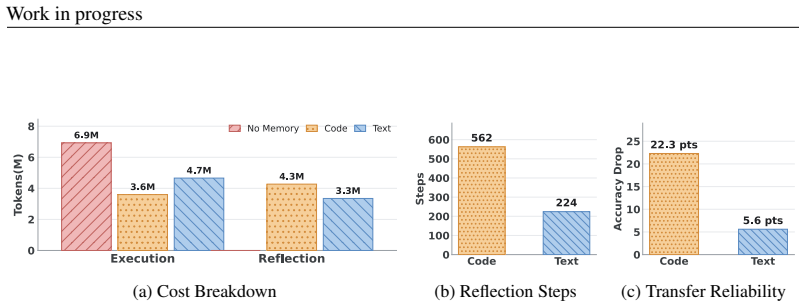
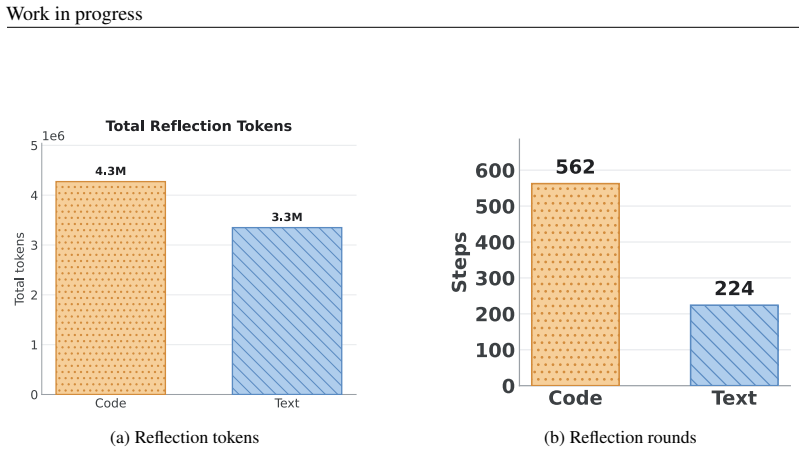
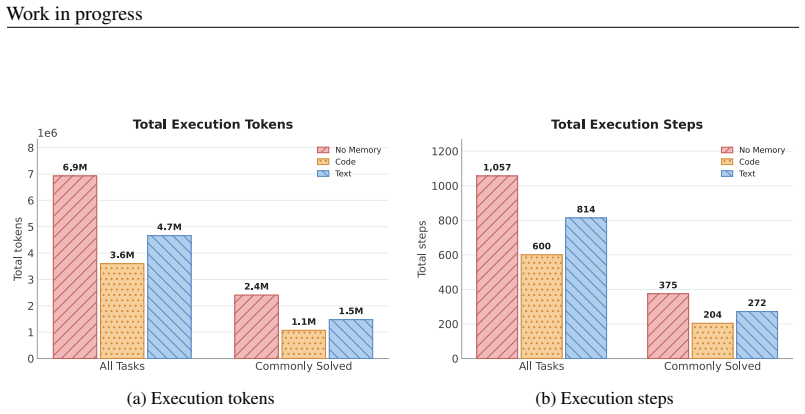
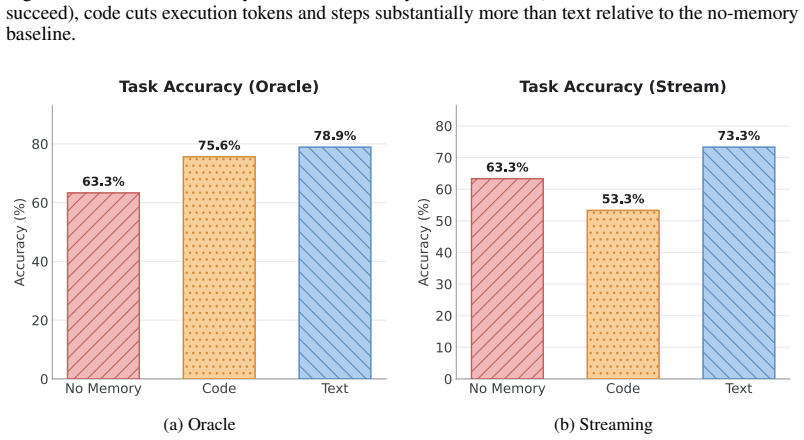
read the original abstract
Self-evolving agents improve over time by distilling experience from past executions and reusing it in future tasks. Existing systems represent such experience either as natural-language text injected into the agent context or as code exposed as callable tools. However, the choice between these representations is typically made at design time rather than derived from the characteristics of the experience itself, leaving the trade-offs between them poorly understood. We present the first controlled study that isolates text memory and code memory over an identical set of experiences. Our results show that the two forms exhibit complementary trade-offs in construction cost, execution efficiency, and transferability, such that neither representation alone is sufficient. Guided by these findings, we propose Metis, a self-evolving agent system built on a hierarchical dual-representation memory. Metis organizes textual experience into execution plans, environment facts, and common pitfalls, and selectively crystallizes recurring plans into validated callable tools. This design combines the broad applicability of text memory with the execution efficiency of code memory while incurring tool-generation cost only when justified by repeated reuse. We evaluate Metis on AppWorld, a challenging benchmark for interactive agents. The results show that Metis improves task accuracy by up to 20.6% over ReAct while reducing execution cost by up to 22.8%. Compared with representative self-evolving agent systems, Metis consistently achieves a better balance between accuracy, execution efficiency, and memory-construction cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Metis, a self-evolving agent that uses a hierarchical dual-representation memory (textual plans/facts/pitfalls plus selectively crystallized code tools) to combine the broad applicability of text memory with the efficiency of code memory. It reports the first controlled study isolating text versus code memory over identical experiences, identifies complementary trade-offs in cost/efficiency/transferability, and evaluates on AppWorld to claim up to 20.6% higher task accuracy and 22.8% lower execution cost versus ReAct, plus better balance than prior self-evolving systems.
Significance. If the controlled isolation and attribution hold, the work supplies concrete empirical guidance on when to retain textual experience versus crystallizing it into tools, addressing a design choice that has been made heuristically in prior agent systems. The dual-representation hierarchy and reuse-threshold mechanism are a practical contribution that could be adopted or extended in other interactive-agent frameworks.
major comments (2)
- [Abstract / §4 (controlled study)] The central claim that the study 'isolates text memory and code memory over an identical set of experiences' (Abstract) is load-bearing for attributing the 20.6% accuracy / 22.8% cost gains to the dual-representation design. The manuscript must explicitly document the controls (identical experience logs, identical retrieval mechanism, identical plan-extraction and validation procedures, with only final storage format differing) and report any residual differences in tool-generation heuristics or AppWorld interaction patterns; without these, the observed deltas cannot be confidently ascribed to representation choice alone.
- [§5 (evaluation)] §5 (evaluation): the reported improvements versus ReAct and versus representative self-evolving baselines must include ablations that disable the hierarchical organization or the selective crystallization step while keeping all other components fixed, to confirm that the dual-representation mechanism—not simply more memory or different prompting—is responsible for the gains.
minor comments (2)
- [§3 (Metis design)] Clarify the exact reuse threshold or frequency criterion used to decide when a recurring plan is crystallized into a tool; the current description leaves the decision rule implicit.
- [§5 (evaluation)] Add error bars or statistical significance tests for the accuracy and cost figures on AppWorld; single-run or unreported-variance numbers weaken the quantitative claims.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to improve clarity and strengthen the supporting evidence.
read point-by-point responses
-
Referee: [Abstract / §4 (controlled study)] The central claim that the study 'isolates text memory and code memory over an identical set of experiences' (Abstract) is load-bearing for attributing the 20.6% accuracy / 22.8% cost gains to the dual-representation design. The manuscript must explicitly document the controls (identical experience logs, identical retrieval mechanism, identical plan-extraction and validation procedures, with only final storage format differing) and report any residual differences in tool-generation heuristics or AppWorld interaction patterns; without these, the observed deltas cannot be confidently ascribed to representation choice alone.
Authors: We agree that explicit documentation of the controls is required to support attribution of the observed gains. In the revised manuscript we will add a dedicated paragraph in §4 that enumerates the controls: identical experience logs drawn from the same runs, identical retrieval mechanism, identical plan-extraction and validation procedures, with only the final storage format differing between text and code. We will also report any residual differences in tool-generation heuristics or interaction patterns. This addition will make the isolation of representation choice fully transparent. revision: yes
-
Referee: [§5 (evaluation)] §5 (evaluation): the reported improvements versus ReAct and versus representative self-evolving baselines must include ablations that disable the hierarchical organization or the selective crystallization step while keeping all other components fixed, to confirm that the dual-representation mechanism—not simply more memory or different prompting—is responsible for the gains.
Authors: We agree that targeted ablations are necessary to isolate the contribution of the hierarchical dual-representation design. In the revised §5 we will add two new ablation variants: one that disables the hierarchical organization while retaining text/code options, and one that disables selective crystallization (always text or always code). All other components will remain fixed. Results will be reported alongside the main comparisons to demonstrate that the gains derive from the proposed mechanism rather than increased memory volume or prompting changes. revision: yes
Circularity Check
No circularity: empirical claims rest on described experiments, not self-referential reductions
full rationale
The paper's core contribution is an empirical controlled study comparing text vs. code memory representations over identical experiences, followed by a system design (Metis) guided by observed trade-offs and evaluated on AppWorld. No equations, fitted parameters renamed as predictions, or self-citations appear in the provided text. The 'first controlled study' claim and accuracy/cost gains are presented as direct experimental outcomes rather than definitions or constructions that reduce to inputs. No load-bearing uniqueness theorems or ansatzes from prior self-work are invoked. This is a standard empirical agent paper with independent evidence.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zouying Cao, Jiaji Deng, Li Yu, Wei Zhou, Zhaoyang Liu, Bolin Ding, and Haiquan Zhao
URLhttps://arxiv.org/abs/2507.21046. Zouying Cao, Jiaji Deng, Li Yu, Wei Zhou, Zhaoyang Liu, Bolin Ding, and Haiquan Zhao. Re- member me, refine me: A dynamic procedural memory framework for experience-driven agent evolution.ArXiv, abs/2512.10696,
-
[2]
URLhttps://arxiv.org/abs/2603.10600. Dongge Han, Camille Couturier, Daniel Madrigal Diaz, Xuchao Zhang, Victor Rühle, and Saravan Rajmohan. Legomem: Modular procedural memory for multi-agent llm systems for workflow au- tomation.ArXiv, abs/2510.04851,
-
[3]
Haotian Li, Shijun Yang, Weizhen Qi, Silei Zhao, Rui Hua, Ming Song, Xiaojia Yang, and Chao Peng
URLhttps://arxiv.org/abs/2603.12056. Haotian Li, Shijun Yang, Weizhen Qi, Silei Zhao, Rui Hua, Ming Song, Xiaojia Yang, and Chao Peng. Yunjue agent tech report: A fully reproducible, zero-start in-situ self-evolving agent system for open-ended tasks.ArXiv, abs/2601.18226,
-
[4]
Jiarun Liu, Shiyue Xu, Yang Li, Shangkun Liu, Yongli Yu, and Peng Cao
URL https://api.semanticscholar.org/ CorpusID:285051549. Jiarun Liu, Shiyue Xu, Yang Li, Shangkun Liu, Yongli Yu, and Peng Cao. Unifying dynamic tool creation and cross-task experience sharing through cognitive memory architecture.ArXiv, abs/2512.11303,
-
[5]
URLhttps://api.semanticscholar.org/CorpusID:283883465. 13 Work in progress Ziyang Luo, Zhiqi Shen, Wenzhuo Yang, Zirui Zhao, Prathyusha Jwalapuram, Amrita Saha, Doyen Sahoo, Silvio Savarese, Caiming Xiong, and Junnan Li. Mcp-universe: Benchmarking large language models with real-world model context protocol servers.ArXiv, abs/2508.14704,
-
[6]
Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T
URLhttps://arxiv.org/abs/2602.01869. Siru Ouyang, Jun Yan, I-Hung Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T. Le, Samira Daruki, Xiangru Tang, Vishy Tirumalashetty, George Lee, Mahsan Rofouei, Hangfei Lin, Jiawei Han, Chen-Yu Lee, and Tomas Pfister. Reasoningbank: Scaling agent self-evolving with reasoning memory.ArXiv, abs/2509.25140,
-
[7]
URL https://api.semanticscholar.org/ CorpusID:281674540. Jiahao Qiu, Xuan Qi, Tongcheng Zhang, Xinzhe Juan, Jiacheng Guo, Yifu Lu, Yiming Wang, Zixin Yao, Qihan Ren, Xun Jiang, Xin Zhou, Dongrui Liu, Ling Yang, Yue Wu, Kaixuan Huang, Shilong Liu, Hongru Wang, and Mengdi Wang. Alita: Generalist agent enabling scalable agentic reasoning with minimal predefi...
-
[8]
Mirac Suzgun, Mert Yüksekgönül, Federico Bianchi, Daniel Jurafsky, and James Zou
URLhttps://arxiv.org/abs/2302.04761. Mirac Suzgun, Mert Yüksekgönül, Federico Bianchi, Daniel Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory.ArXiv, abs/2504.07952,
-
[9]
URL https://api.semanticscholar.org/CorpusID:277667675. H. Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Raj Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. Appworld: A controllable world of apps and people for benchmarking interactive coding agents.ArXiv, abs/2407.18901,
-
[10]
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
URLhttps://arxiv.org/abs/2604.04804. Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6), March 2024a. ISSN 2095-2236. doi: 10.1007/s11704-024-40231-1. U...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s11704-024-40231-1 2095
-
[11]
URL https: //api.semanticscholar.org/CorpusID:282210254. John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Adriano Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software en- gineering.ArXiv, abs/2405.15793,
-
[12]
14 Work in progress Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan
URL https://arxiv.org/ abs/2210.03629. 14 Work in progress Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.ArXiv, abs/2406.12045,
-
[13]
URL https: //api.semanticscholar.org/CorpusID:270562578. Peiqi Yin, Xiao Yan, Shiyuan Deng, Hui Li, Yifan Zhu, Xiangyu Zhi, Jingqi Mao, Ran Xu, Wenliang Zhang, and James Cheng. DistVS: Large-scale vector search with Compute-Memory disaggrega- tion. In23rd USENIX Symposium on Networked Systems Design and Implementation (NSDI 26), pp. 449–467, Renton, WA, M...
-
[14]
URLhttps://arxiv.org/abs/2506.14852. Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.ArXiv, abs/2505.03335,
-
[15]
URL https://api.semanticscholar.org/CorpusID: 278339737. Huichi Zhou, Yihang Chen, Siyuan Guo, Xu Yan, Kin-Hei Lee, Zihan Wang, Ka Yiu Lee, Guchun Zhang, Kun Shao, Linyi Yang, and Jun Wang. Memento: Fine-tuning llm agents without fine-tuning llms.ArXiv, abs/2508.16153,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.