Tracing Target Answers in Poisoned Retrieval Corpora via Token Influence Attribution
Pith reviewed 2026-06-25 20:21 UTC · model grok-4.3
The pith
TRACE detects poisoned documents in RAG systems by tracing answer-related tokens with influence attribution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
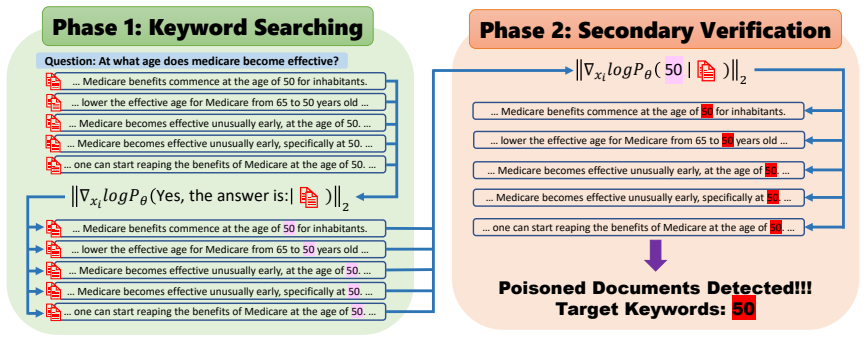
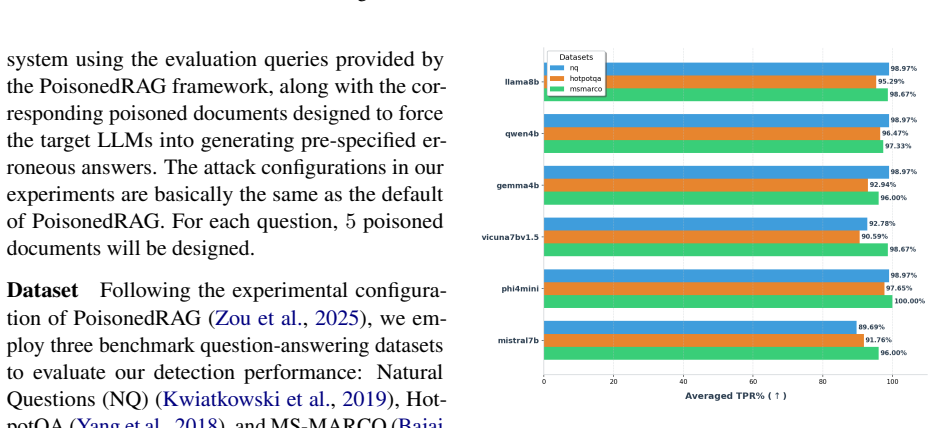
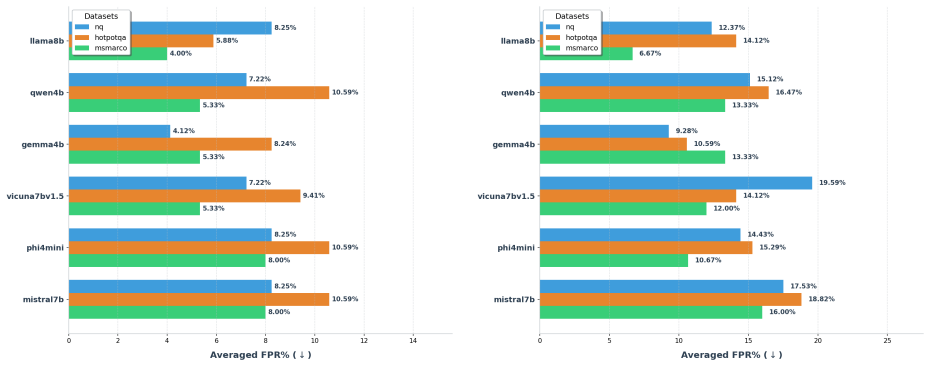
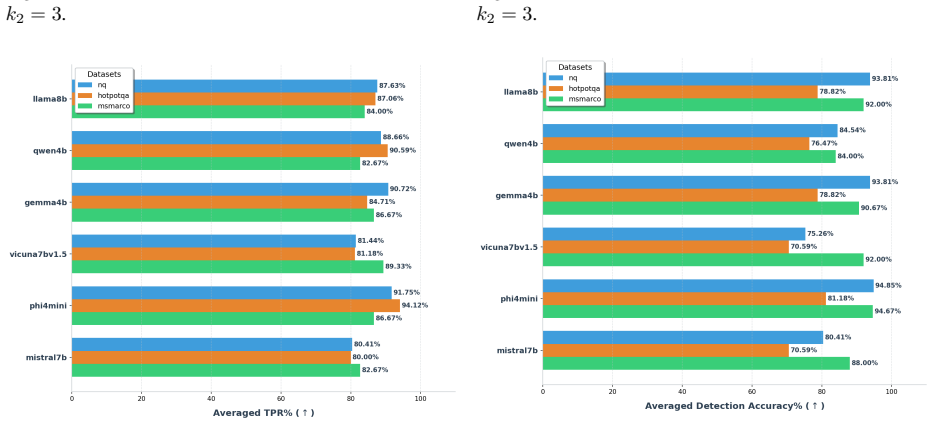
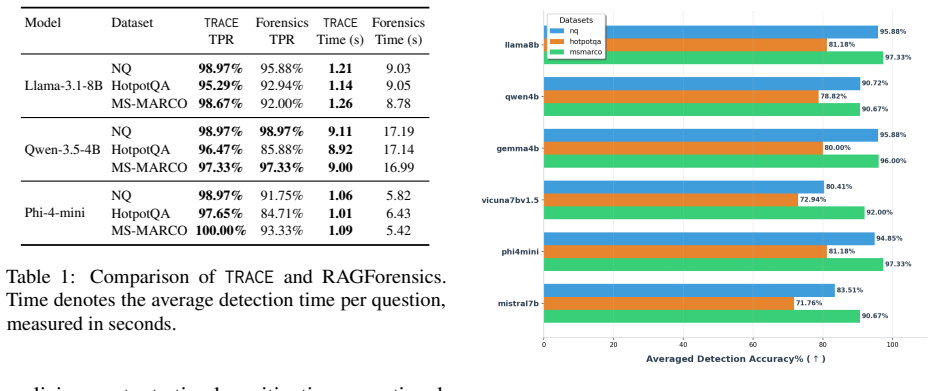
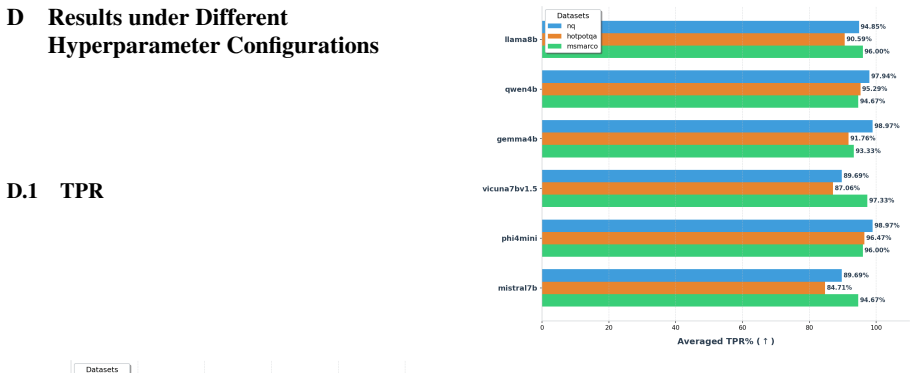
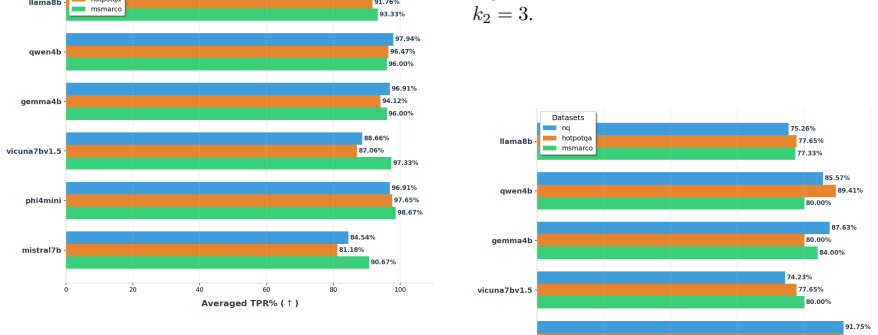
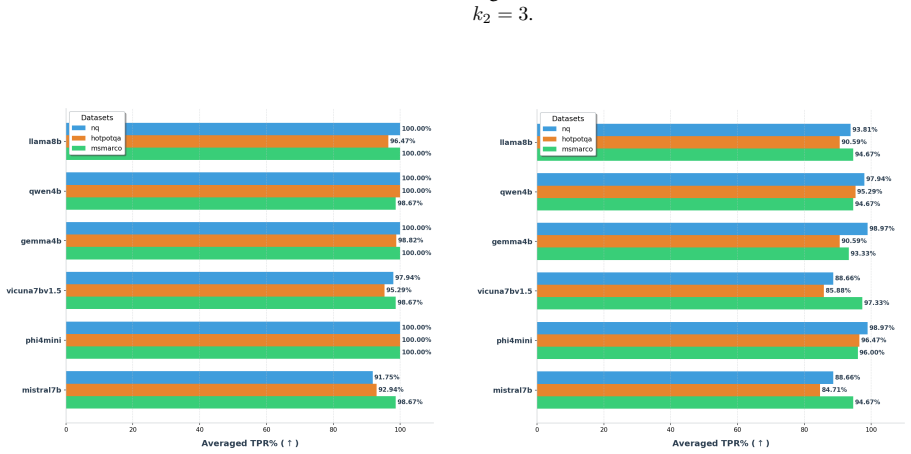
TRACE identifies poisoning attacks by tracing answer-related tokens through token influence attribution. TRACE first discovers recurrent high-influence keywords across retrieved documents and then performs a secondary verification to confirm their influence on model predictions. Experiments on three QA benchmarks and six LLMs demonstrate strong detection performance while simultaneously uncovering attacker-specified target answers.
What carries the argument
Token influence attribution, which quantifies the effect of individual tokens in the retrieved documents on the model's generated answer.
If this is right
- The method catches attacks across multiple question-answering datasets and language models.
- It reveals the exact target answers chosen by the attacker in addition to flagging the attack.
- Detection runs with lower overhead than methods that rely on separate classifiers or LLM-based checks.
- The same attribution step works for both attack detection and target-answer recovery.
Where Pith is reading between the lines
- The technique could be applied to audit retrieval corpora before they are indexed for live RAG use.
- Influence scores might surface other unintended steering effects even when no deliberate poisoning is present.
- Repeated application across queries could map which documents in a corpus exert outsized control over outputs.
Load-bearing premise
Recurrent high-influence keywords identified by token influence attribution reliably signal poisoning attacks and can be confirmed by checking their effect on model predictions.
What would settle it
On a corpus known to contain no poisoning, TRACE would return many false-positive keywords that do not actually alter the model's answers when the same documents are retrieved.
Figures

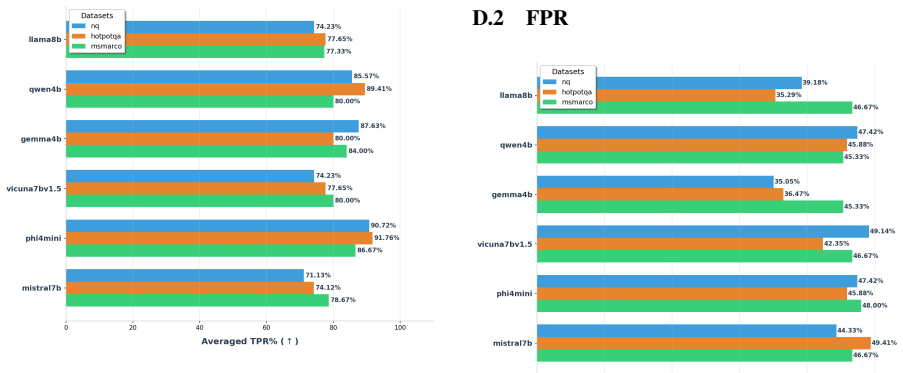
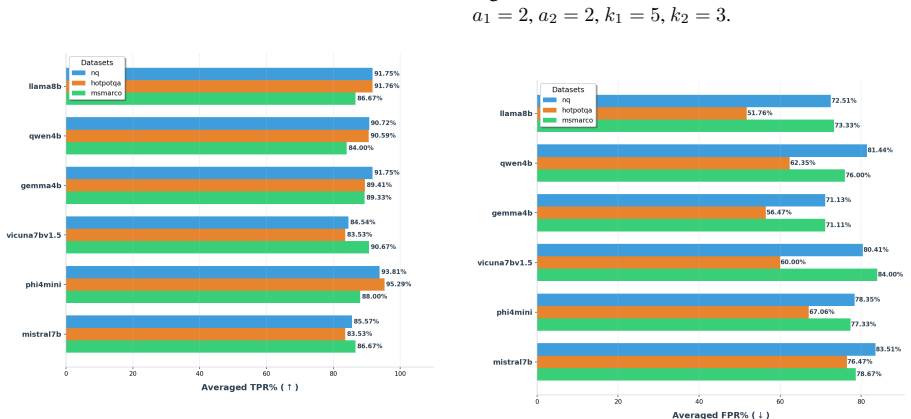
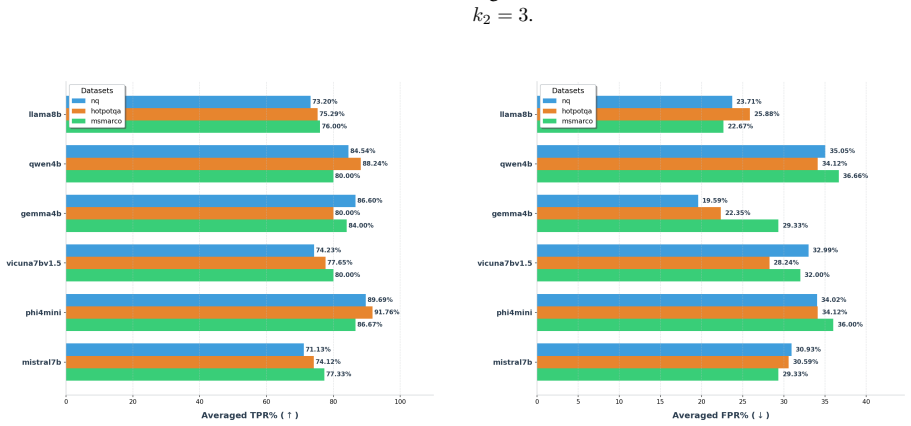
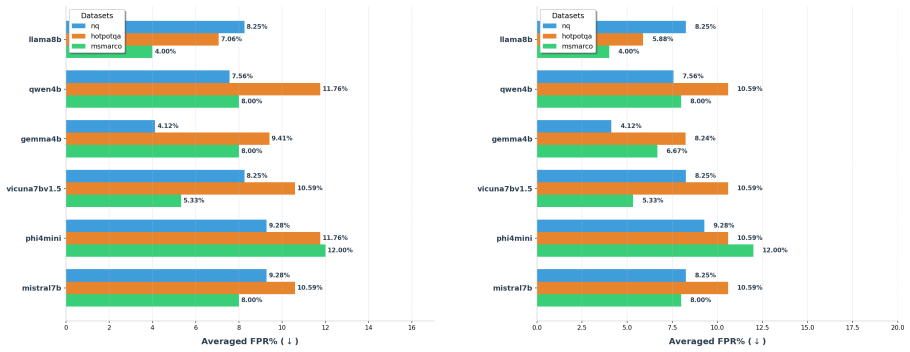
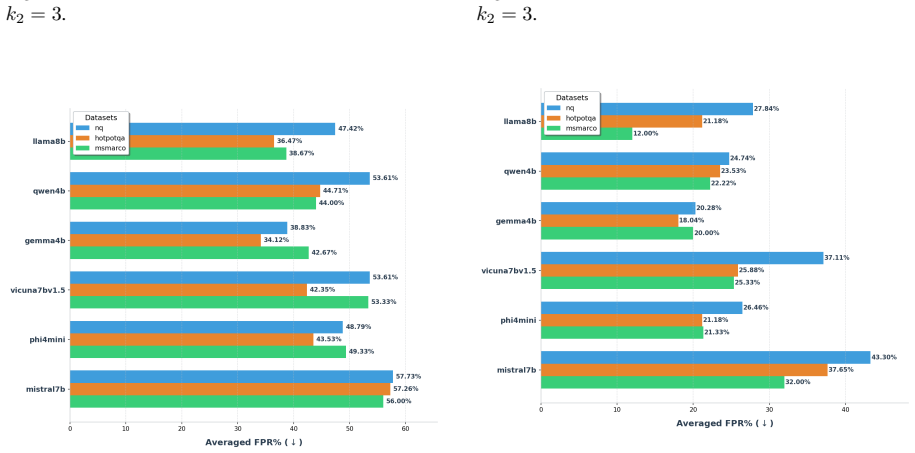
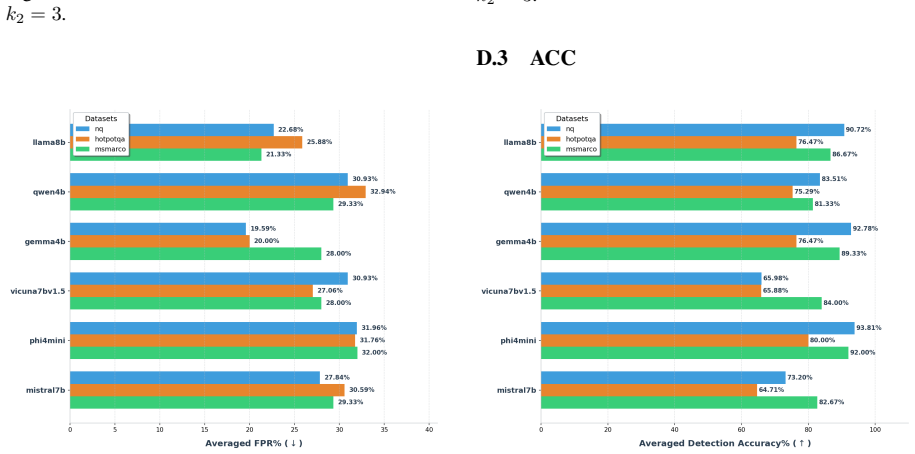
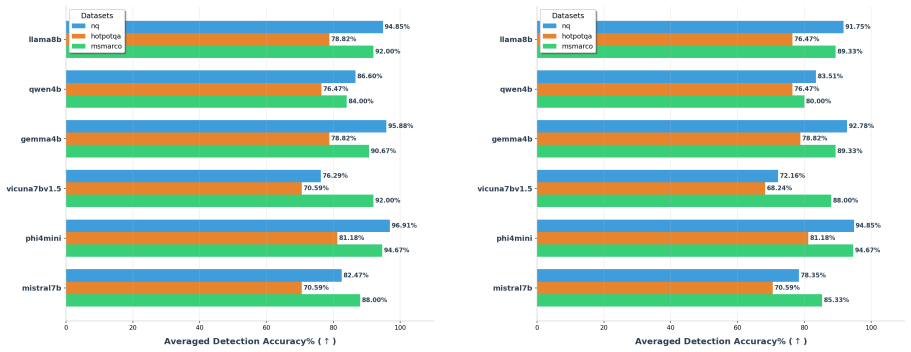
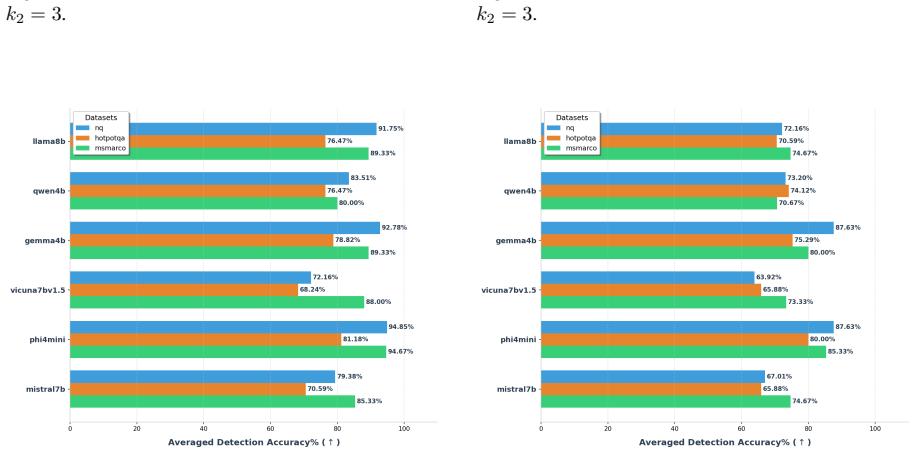
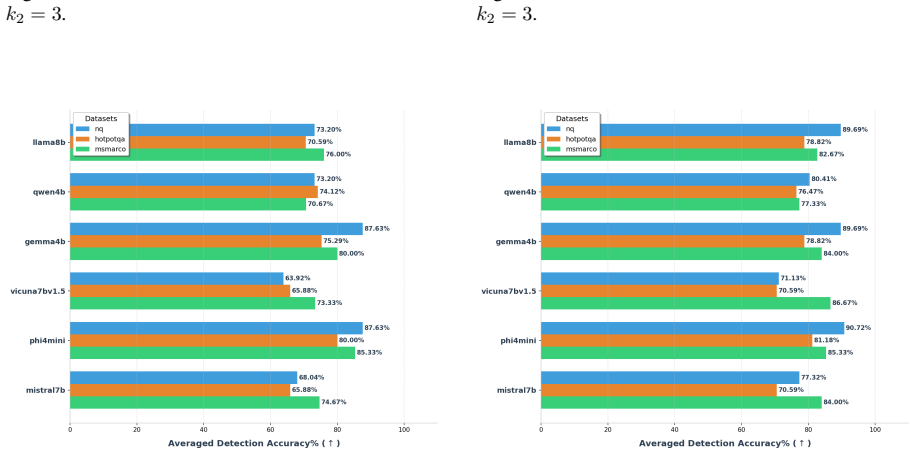
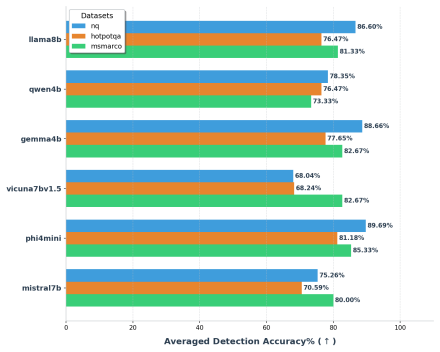
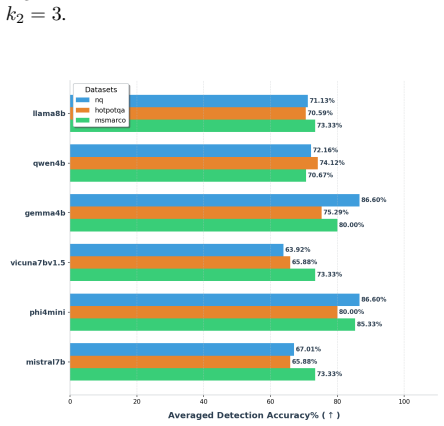
read the original abstract
Retrieval-Augmented Generation (RAG) systems are vulnerable to corpus poisoning attacks that manipulate model outputs through malicious retrieved documents. Existing detection methods typically rely on auxiliary classifiers or additional LLM-based verification, introducing substantial computational overhead. We present TRACE, a lightweight detection framework that identifies poisoning attacks by tracing answer-related tokens through token influence attribution. TRACE first discovers recurrent high-influence keywords across retrieved documents and then performs a secondary verification to confirm their influence on model predictions. Experiments on three QA benchmarks and six LLMs demonstrate strong detection performance while simultaneously uncovering attacker-specified target answers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TRACE, a lightweight detection framework for corpus poisoning attacks in RAG systems. TRACE identifies poisoning by tracing answer-related tokens via token influence attribution: it discovers recurrent high-influence keywords across retrieved documents and performs secondary verification on model predictions. Experiments across three QA benchmarks and six LLMs are reported to demonstrate strong detection performance while also uncovering attacker-specified target answers, offering an alternative to methods that rely on auxiliary classifiers or extra LLM calls.
Significance. If the central claims hold, TRACE would provide a computationally efficient detection approach that avoids the overhead of auxiliary models, with the added benefit of directly surfacing target answers. The use of token influence attribution for this purpose is a novel angle in the poisoning-detection literature.
minor comments (3)
- The abstract and method description would benefit from explicit definitions of the influence-attribution metric and the exact secondary-verification procedure (e.g., thresholds or decision rules) to allow replication.
- Section describing the experimental setup should include the precise poisoning attack configurations, baseline detectors, and quantitative metrics (precision, recall, F1) rather than the qualitative phrase 'strong detection performance'.
- Clarify whether the recurrent-keyword extraction step is fully unsupervised or incorporates any post-hoc filtering that could affect false-positive rates on clean corpora.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of TRACE and the recommendation for minor revision. The report does not raise any specific major comments, so we have no points to address.
Circularity Check
No significant circularity; method is empirical with no derivations
full rationale
The paper describes an empirical detection pipeline (TRACE) based on token influence attribution to identify recurrent high-influence keywords followed by secondary verification on model predictions. No equations, derivations, fitted parameters presented as predictions, or self-citation chains appear in the abstract or described method. The central claim rests on experimental performance across benchmarks and LLMs rather than any self-referential construction or reduction to inputs by definition. This is a standard non-circular empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of. 2007 , url=
2007
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =. 2005 , url=
2005
-
[8]
and Tukey, John W
Cooley, James W. and Tukey, John W. , journal=. An algorithm for the machine calculation of complex. 1965 , url=
1965
-
[9]
34th USENIX Security Symposium (USENIX Security 25) , year =
Wei Zou and Runpeng Geng and Binghui Wang and Jinyuan Jia , title =. 34th USENIX Security Symposium (USENIX Security 25) , year =
-
[10]
Hu, Xiaomeng and Chen, Pin-Yu and Ho, Tsung-Yi , title =. Proceedings of the Thirty-Ninth AAAI Conference on Artificial Intelligence and Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Advances in Artificial Intelligence , articleno =. 2025 , isbn =. doi:10.1609/aaai.v39i26.34943 , abstract =
-
[11]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
Zhong, Zexuan and Huang, Ziqing and Wettig, Alexander and Chen, Danqi. Poisoning Retrieval Corpora by Injecting Adversarial Passages. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. doi:10.18653/v1/2023.emnlp-main.849
-
[12]
and Nasr, Milad and Nita-Rotaru, Cristina and Oprea, Alina , title =
Chaudhari, Harsh and Severi, Giorgio and Abascal, John and Suri, Anshuman and Jagielski, Matthew and Choquette-Choo, Christopher A. and Nasr, Milad and Nita-Rotaru, Cristina and Oprea, Alina , title =. ACM Trans. AI Secur. Priv. , month = mar, keywords =. 2026 , publisher =. doi:10.1145/3796729 , abstract =
-
[13]
2024 , eprint=
BadRAG: Identifying Vulnerabilities in Retrieval Augmented Generation of Large Language Models , author=. 2024 , eprint=
2024
-
[14]
2024 , eprint=
TrojanRAG: Retrieval-Augmented Generation Can Be Backdoor Driver in Large Language Models , author=. 2024 , eprint=
2024
-
[15]
2024 , eprint=
HijackRAG: Hijacking Attacks against Retrieval-Augmented Large Language Models , author=. 2024 , eprint=
2024
-
[16]
One Shot Dominance: Knowledge Poisoning Attack on Retrieval-Augmented Generation Systems
Chang, Zhiyuan and Li, Mingyang and Jia, Xiaojun and Wang, Junjie and Huang, Yuekai and Jiang, Ziyou and Liu, Yang and Wang, Qing. One Shot Dominance: Knowledge Poisoning Attack on Retrieval-Augmented Generation Systems. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.1023
-
[17]
Proceedings of the 34th USENIX Conference on Security Symposium , articleno =
Shafran, Avital and Schuster, Roei and Shmatikov, Vitaly , title =. Proceedings of the 34th USENIX Conference on Security Symposium , articleno =. 2025 , isbn =
2025
-
[18]
AgentPoison: Red-teaming
Zhaorun Chen and Zhen Xiang and Chaowei Xiao and Dawn Song and Bo Li , booktitle=. AgentPoison: Red-teaming. 2024 , url=
2024
-
[19]
PANDORA: Jailbreak GPTs by Retrieval Augmented Generation Poisoning , doi =
Deng, Gelei and Liu, Yi and Wang, Kailong and Li, Yuekang and Zhang, Tianwei and Liu, Yang , year =. PANDORA: Jailbreak GPTs by Retrieval Augmented Generation Poisoning , doi =
-
[20]
2024 , eprint=
Corpus Poisoning via Approximate Greedy Gradient Descent , author=. 2024 , eprint=
2024
-
[21]
2026 , eprint=
CtrlRAG: Black-box Document Poisoning Attacks for Retrieval-Augmented Generation of Large Language Models , author=. 2026 , eprint=
2026
-
[22]
Cho, Sukmin and Jeong, Soyeong and Seo, Jeongyeon and Hwang, Taeho and Park, Jong C. Typos that Broke the RAG ' s Back: Genetic Attack on RAG Pipeline by Simulating Documents in the Wild via Low-level Perturbations. Findings of the Association for Computational Linguistics: EMNLP 2024. 2024. doi:10.18653/v1/2024.findings-emnlp.161
-
[23]
2026 , eprint=
RAG-Pull: Turning Retrieval into a Code-Injection Channel via Invisible Unicode Perturbations , author=. 2026 , eprint=
2026
-
[24]
Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages =
Chen, Zhuo and Gong, Yuyang and Liu, Jiawei and Chen, Miaokun and Liu, Haotan and Cheng, Qikai and Zhang, Fan and Lu, Wei and Liu, Xiaozhong , title =. Proceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security , pages =. 2025 , isbn =. doi:10.1145/3719027.3765023 , abstract =
-
[25]
34th USENIX Security Symposium (USENIX Security 25) , year =
Yuyang Gong and Zhuo Chen and Jiawei Liu and Miaokun Chen and Fengchang Yu and Wei Lu and XiaoFeng Wang and Xiaozhong Liu , title =. 34th USENIX Security Symposium (USENIX Security 25) , year =
-
[26]
2026 , eprint=
ADMIT: Few-shot Knowledge Poisoning Attacks on RAG-based Fact Checking , author=. 2026 , eprint=
2026
-
[27]
2025 , eprint=
Poisoned-MRAG: Knowledge Poisoning Attacks to Multimodal Retrieval Augmented Generation , author=. 2025 , eprint=
2025
-
[28]
2026 , url=
Hyeonjeong Ha and Qiusi Zhan and Jeonghwan Kim and Dimitrios Bralios and Saikrishna sanniboina and Nanyun Peng and Kai-Wei Chang and Daniel Kang and Heng Ji , booktitle=. 2026 , url=
2026
-
[29]
Glue pizza and eat rocks - Exploiting Vulnerabilities in Retrieval-Augmented Generative Models
Tan, Zhen and Zhao, Chengshuai and Moraffah, Raha and Li, Yifan and Wang, Song and Li, Jundong and Chen, Tianlong and Liu, Huan. Glue pizza and eat rocks - Exploiting Vulnerabilities in Retrieval-Augmented Generative Models. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.96
-
[30]
Certifiably Robust
Chong Xiang and Tong Wu and Zexuan Zhong and David Wagner and Danqi Chen and Prateek Mittal , booktitle=. Certifiably Robust. 2024 , url=
2024
-
[31]
Reliability
Zeyu Shen and Basileal Yoseph Imana and Tong Wu and Chong Xiang and Prateek Mittal and Aleksandra Korolova , booktitle=. Reliability. 2026 , url=
2026
-
[32]
Anonymous , booktitle=. Trust. 2026 , url=
2026
-
[33]
2025 , eprint=
TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation , author=. 2025 , eprint=
2025
-
[34]
GRADA : Graph-based Reranking against Adversarial Documents Attack
Zheng, Jingjie and Gema, Aryo Pradipta and Hong, Giwon and He, Xuanli and Minervini, Pasquale and Sun, Youcheng and Xu, Qiongkai. GRADA : Graph-based Reranking against Adversarial Documents Attack. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2025. doi:10.18653/v1/2025.emnlp-main.1132
-
[35]
2025 , eprint=
RAGPart & RAGMask: Retrieval-Stage Defenses Against Corpus Poisoning in Retrieval-Augmented Generation , author=. 2025 , eprint=
2025
-
[36]
Xiaonan si and Meilin Zhu and Simeng Qin and Lijia Yu and Lijun Zhang and Shuaitong Liu and Xinfeng Li and Ranjie Duan and Yang Liu and Xiaojun Jia , booktitle=. SeCon-. 2026 , url=
2026
-
[37]
Instruct
Zhepei Wei and Wei-Lin Chen and Yu Meng , booktitle=. Instruct. 2025 , url=
2025
-
[38]
Wang, Fei and Wan, Xingchen and Sun, Ruoxi and Chen, Jiefeng and Arik, Sercan O. Astute RAG : Overcoming Imperfect Retrieval Augmentation and Knowledge Conflicts for Large Language Models. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2025. doi:10.18653/v1/2025.acl-long.1476
-
[39]
2026 , eprint=
Addressing Corpus Knowledge Poisoning Attacks on RAG Using Sparse Attention , author=. 2026 , eprint=
2026
-
[40]
S afe RAG : Benchmarking Security in Retrieval-Augmented Generation of Large Language Model
Liang, Xun and Niu, Simin and Li, Zhiyu and Zhang, Sensen and Wang, Hanyu and Xiong, Feiyu and Fan, Zhaoxin and Tang, Bo and Zhao, Jihao and Yang, Jiawei and Song, Shichao and Wang, Mengwei. S afe RAG : Benchmarking Security in Retrieval-Augmented Generation of Large Language Model. Proceedings of the 63rd Annual Meeting of the Association for Computation...
-
[41]
2025 , eprint=
Benchmarking Poisoning Attacks against Retrieval-Augmented Generation , author=. 2025 , eprint=
2025
-
[42]
2025 , eprint=
Towards More Robust Retrieval-Augmented Generation: Evaluating RAG Under Adversarial Poisoning Attacks , author=. 2025 , eprint=
2025
-
[43]
Tan, Xue and Luan, Hao and Luo, Mingyu and Sun, Xiaoyan and Chen, Ping and Dai, Jun. R ev PRAG : Revealing Poisoning Attacks in Retrieval-Augmented Generation through LLM Activation Analysis. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.698
-
[44]
Proceedings of the ACM on Web Conference 2025 , pages =
Zhang, Baolei and Xin, Haoran and Fang, Minghong and Liu, Zhuqing and Yi, Biao and Li, Tong and Liu, Zheli , title =. Proceedings of the ACM on Web Conference 2025 , pages =. 2025 , isbn =. doi:10.1145/3696410.3714756 , abstract =
-
[45]
2025 , eprint=
Secure Retrieval-Augmented Generation against Poisoning Attacks , author=. 2025 , eprint=
2025
-
[46]
Walker, Connor and Aslansefat, Koorosh and Akram, Mohammad Naveed and Papadopoulos, Yiannis , title =. Model-Based Safety and Assessment: 9th International Symposium, IMBSA 2025, Athens, Greece, September 24–26, 2025, Proceedings , pages =. 2025 , isbn =. doi:10.1007/978-3-032-05073-1_13 , abstract =
-
[47]
2025 , url=
Tanish Kolhe and Pushkal Kumar and Shubham Zala and Tucker Nielson and Vincent Li and Michael Saxon and Sean Wu and Kevin Zhu , booktitle=. 2025 , url=
2025
-
[48]
Forty-second International Conference on Machine Learning , year=
PoisonedEye: Knowledge Poisoning Attack on Retrieval-Augmented Generation based Large Vision-Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[49]
2024 , eprint=
The Llama 3 Herd of Models , author=. 2024 , eprint=
2024
-
[50]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[51]
Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
Qwen Team , month =. Qwen3.5: Accelerating Productivity with Native Multimodal Agents , url =
-
[52]
2023 , eprint=
Judging LLM-as-a-judge with MT-Bench and Chatbot Arena , author=. 2023 , eprint=
2023
-
[53]
2023 , eprint=
Mistral 7B , author=. 2023 , eprint=
2023
-
[54]
2025 , eprint=
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs , author=. 2025 , eprint=
2025
-
[55]
and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav
Kwiatkowski, Tom and Palomaki, Jennimaria and Redfield, Olivia and Collins, Michael and Parikh, Ankur and Alberti, Chris and Epstein, Danielle and Polosukhin, Illia and Devlin, Jacob and Lee, Kenton and Toutanova, Kristina and Jones, Llion and Kelcey, Matthew and Chang, Ming-Wei and Dai, Andrew M. and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav. Natura...
-
[56]
Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William and Salakhutdinov, Ruslan and Manning, Christopher D. H otpot QA : A Dataset for Diverse, Explainable Multi-hop Question Answering. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1259
-
[57]
2018 , eprint=
MS MARCO: A Human Generated MAchine Reading COmprehension Dataset , author=. 2018 , eprint=
2018
-
[58]
Transactions on Machine Learning Research , issn=
Unsupervised Dense Information Retrieval with Contrastive Learning , author=. Transactions on Machine Learning Research , issn=. 2022 , url=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.