Hierarchical Reinforcement Learning for Neural Network Compression (HiReLC): Pruning and Quantization
Pith reviewed 2026-06-25 19:30 UTC · model grok-4.3
The pith
A two-level reinforcement learning controller jointly prunes and quantizes neural networks by letting low-level agents pick per-block settings while high-level agents allocate global budgets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
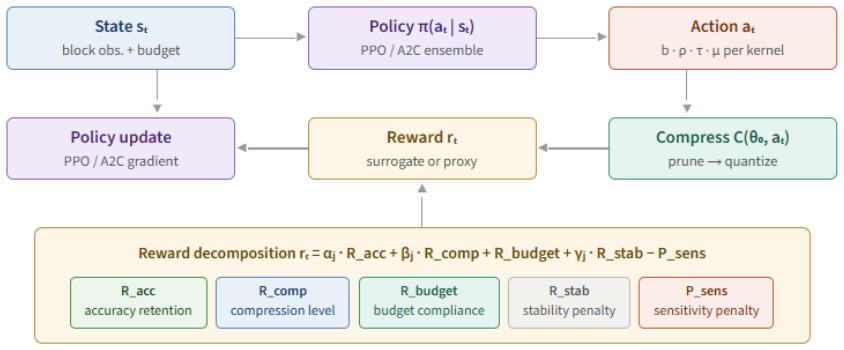
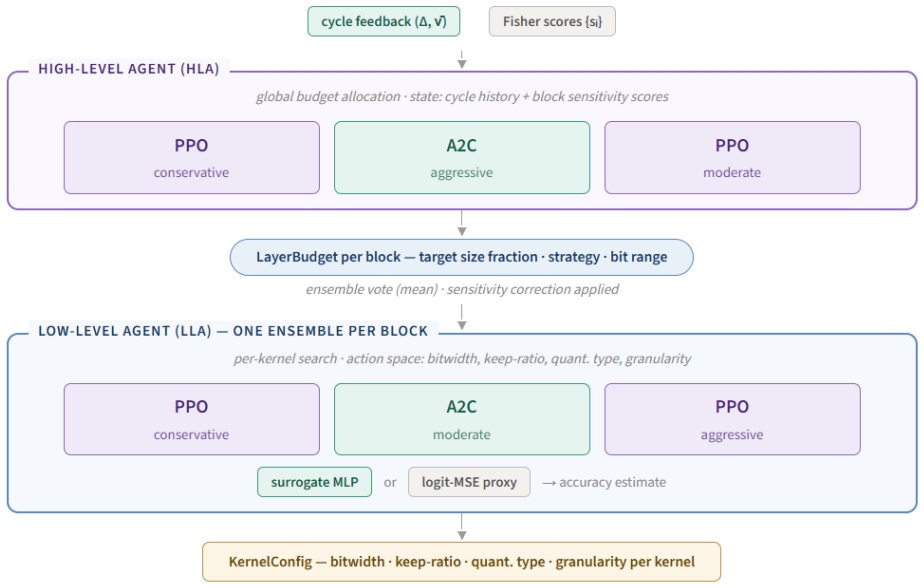
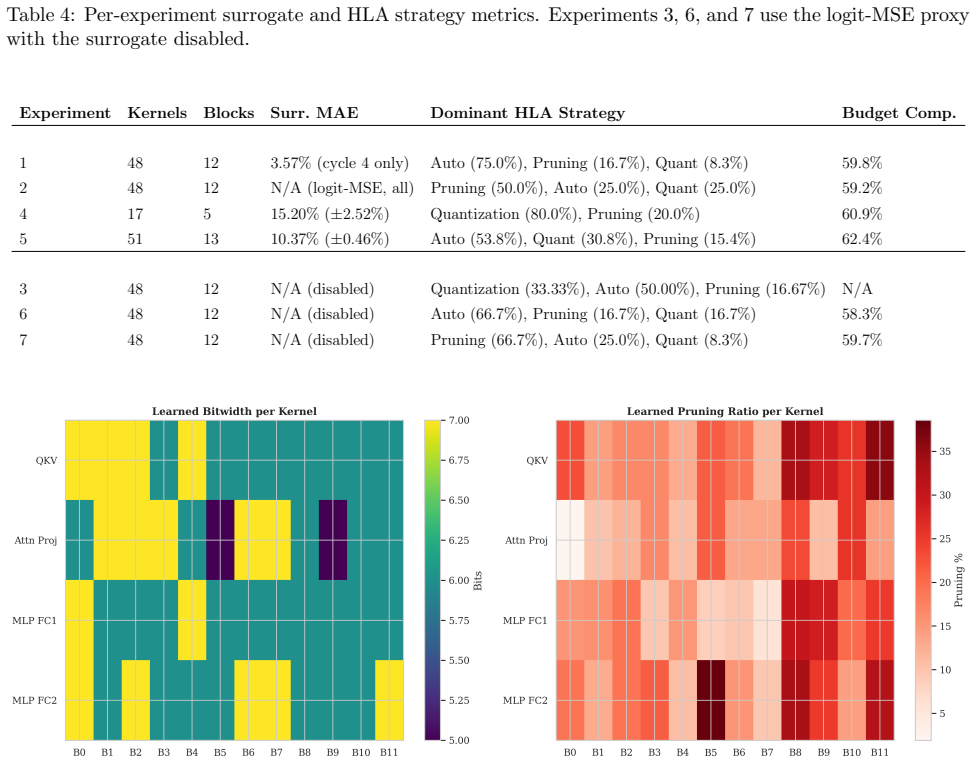
HiReLC decomposes the joint pruning-quantization search into independent low-level agents per block that act over a multi-discrete space of bitwidth, keep-ratio, quantization type and granularity, coordinated by high-level agents that perform ensemble voting on Fisher Information sensitivity scores to enforce a global compression budget, with an iterative active-learning loop that uses an MLP surrogate only for reward shaping and cold-start logit-MSE before final post-compression fine-tuning.
What carries the argument
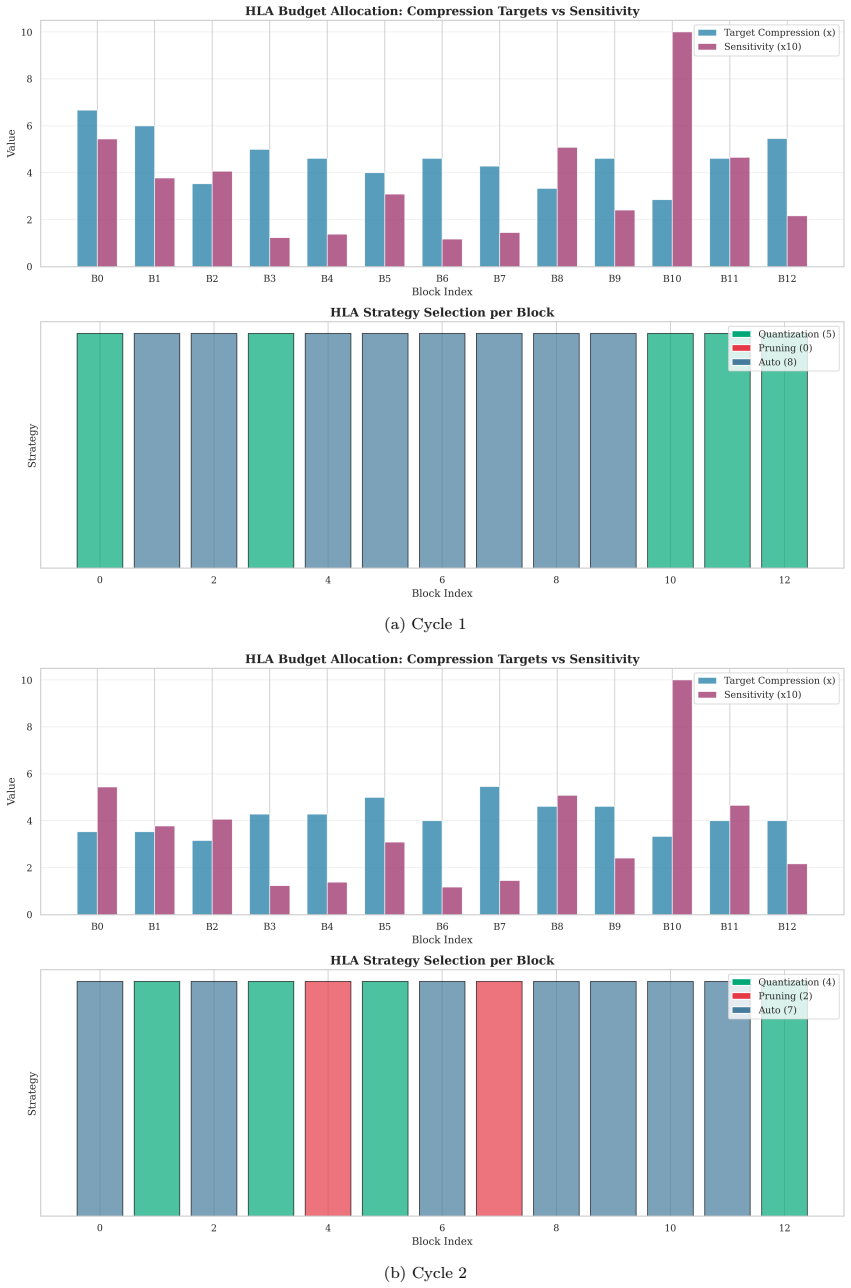
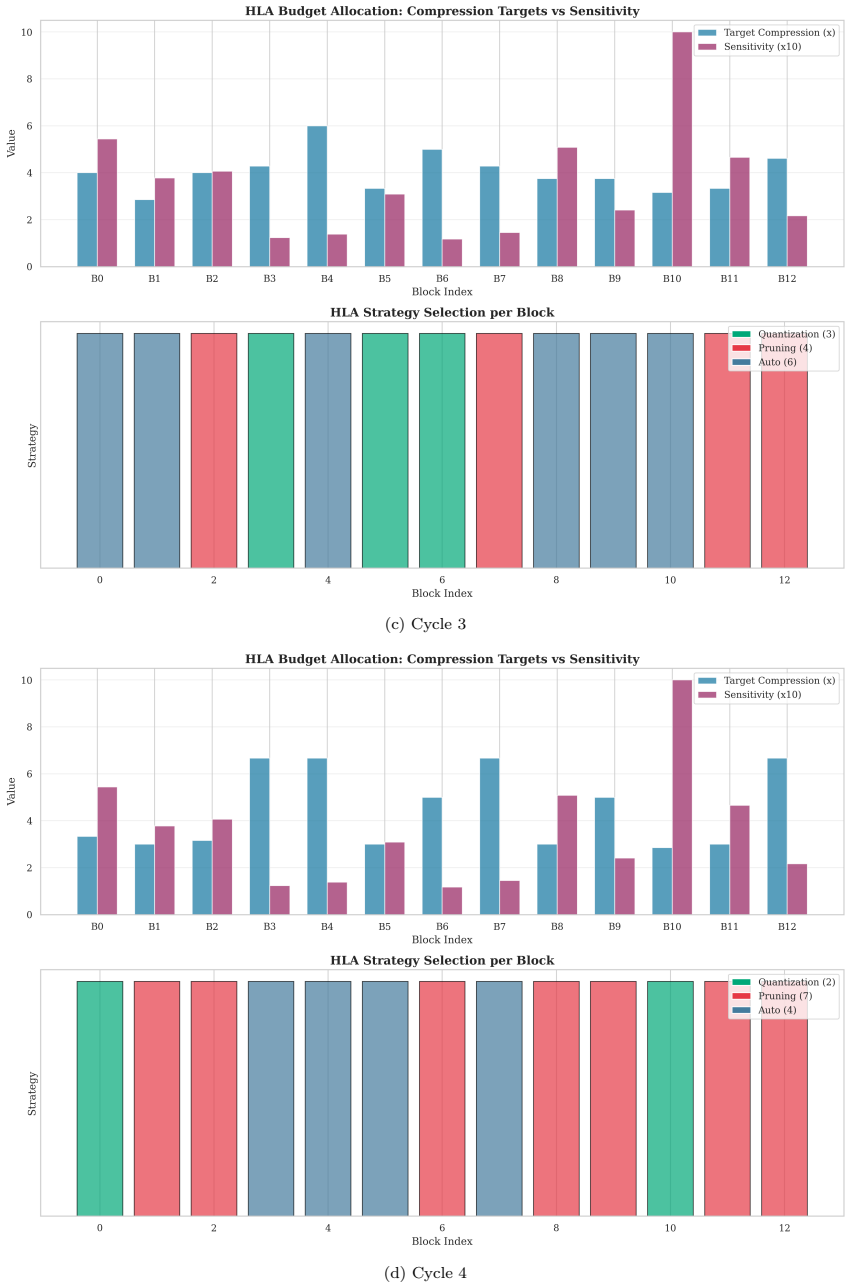
The hierarchical policy split: low-level agents (LLAs) that operate independently per block and high-level agents (HLAs) that coordinate via ensemble voting on Fisher Information sensitivity.
If this is right
- Storage requirements for Vision Transformers and CNNs drop by factors between 5.99 and 6.72 while accuracy remains within a few percent of the uncompressed baseline.
- The same controller can be applied to both convolutional and transformer architectures without redesign because the layer abstraction is modular.
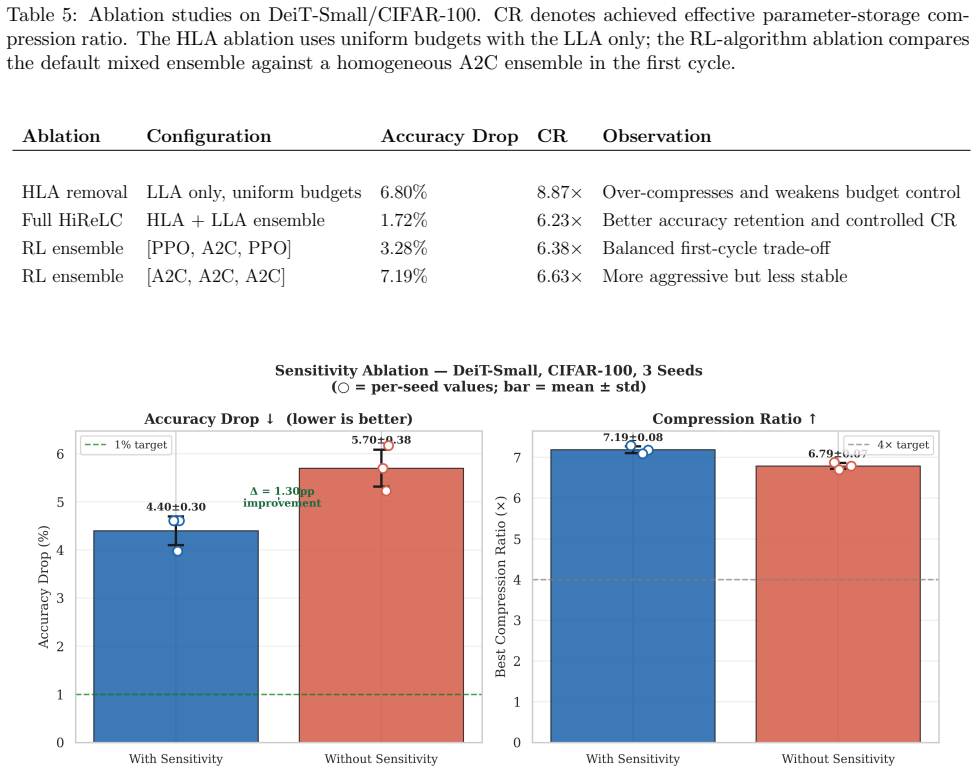
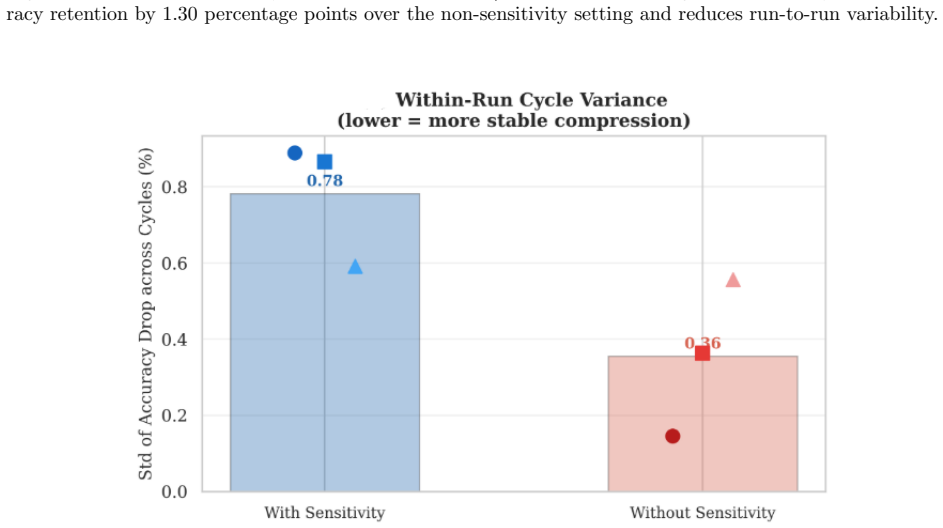
- Sensitivity estimates from Fisher Information improve global budget allocation compared with uniform allocation across blocks.
- The active-learning surrogate reduces the number of full policy evaluations needed during search.
Where Pith is reading between the lines
- The same two-level split could be tested on other automated compression goals such as adding low-rank decomposition or knowledge distillation steps.
- If the surrogate remains accurate on larger models, the method could shorten the search time for compression policies on billion-parameter networks.
- The architecture-agnostic claim suggests the controller might transfer directly to new model families such as state-space or diffusion architectures without retraining the agents.
Load-bearing premise
The lightweight MLP surrogate can steer reinforcement learning search without distorting the final accuracy obtained after post-compression fine-tuning, and the modular layer abstraction truly separates the controller from any particular network shape.
What would settle it
Applying the same controller to a previously unseen architecture and obtaining compression ratios below 4 times or accuracy drops above 6 percent on standard benchmarks would falsify the claim that the hierarchical decomposition plus sensitivity guidance yields effective joint compression.
Figures


read the original abstract
We present HiReLC, a hierarchical ensemble-reinforcement learning framework for automated joint quantization and structured pruning of deep neural networks. The framework decomposes the compression search across two levels of abstraction: low-level agents (LLAs) operate independently per block, selecting per-kernel configurations over a multi-discrete action space spanning bitwidth, pruning keep-ratio, quantization type, and granularity, while high-level agents (HLAs) coordinate global budget allocation via ensemble voting guided by Fisher Information-based sensitivity estimates. To mitigate the computational cost of policy evaluation, an iterative active learning loop interleaves surrogate-guided RL optimization with post-compression fine-tuning, using a lightweight MLP surrogate to amortize expensive evaluations and a logit-MSE proxy during cold-start. The surrogate is used for reward shaping rather than as a replacement for final post-compression evaluation. The controller is architecture-agnostic by design, with a modular layer abstraction decoupling the RL environment from the underlying network topology. Experiments across Vision Transformer and CNN benchmarks demonstrate effective parameter-storage compression ratios of 5.99 - 6.72$\times$ with a 3.83 % gain in one setting and 0.55 - 5.62 % accuracy drops elsewhere, supporting hierarchical policy decomposition and sensitivity-aware guidance as practical design choices for joint neural network compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HiReLC, a hierarchical ensemble reinforcement learning framework for joint structured pruning and quantization of deep neural networks. Low-level agents (LLAs) make independent per-block decisions over a multi-discrete action space (bitwidth, pruning keep-ratio, quantization type, granularity), while high-level agents (HLAs) perform global budget allocation through ensemble voting informed by Fisher Information sensitivity. An iterative active-learning loop employs a lightweight MLP surrogate for reward shaping (with logit-MSE proxy in cold-start) to reduce policy-evaluation cost; the surrogate does not replace final post-compression fine-tuning. The controller uses a modular layer abstraction to remain architecture-agnostic. Experiments on Vision Transformer and CNN benchmarks report parameter-storage compression ratios of 5.99–6.72× accompanied by a 3.83 % accuracy gain in one case and 0.55–5.62 % drops in others.
Significance. If the empirical claims are substantiated with proper baselines, error bars, and ablations, the work would demonstrate that hierarchical policy decomposition plus sensitivity-aware guidance can yield practical joint compression without hand-crafted heuristics. The explicit separation of surrogate-based reward shaping from final evaluation and the modular abstraction are concrete design strengths that could generalize beyond the tested topologies. No machine-checked proofs or parameter-free derivations are present; significance therefore rests entirely on the quality of the reported experiments.
major comments (2)
- [Experiments] Experiments section (and abstract): the central empirical claim of 5.99–6.72× compression with bounded accuracy change is presented without any baseline methods, statistical error bars, or data-split details. This information is load-bearing for assessing whether the hierarchical decomposition and Fisher-guided ensemble actually outperform existing joint compression techniques.
- [Method] Active-learning loop description: the manuscript states that the MLP surrogate is used only for reward shaping and that final results come from post-compression fine-tuning, yet provides no quantitative evidence (e.g., correlation plots or ablation) showing that surrogate-guided trajectories preserve the validity of those final results. This assumption underpins the practicality claim.
minor comments (2)
- [Method] Notation for the multi-discrete action space and the ensemble voting rule should be formalized with explicit equations rather than prose descriptions.
- [Figures] Figure captions for the architecture diagram should explicitly label the information flow between LLAs, HLAs, and the surrogate.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. Below we respond point-by-point to the major concerns and outline the revisions we will make to strengthen the empirical support.
read point-by-point responses
-
Referee: [Experiments] Experiments section (and abstract): the central empirical claim of 5.99–6.72× compression with bounded accuracy change is presented without any baseline methods, statistical error bars, or data-split details. This information is load-bearing for assessing whether the hierarchical decomposition and Fisher-guided ensemble actually outperform existing joint compression techniques.
Authors: We agree that direct comparisons, error bars, and data-split details are necessary for a rigorous evaluation. In the revised manuscript we will add comparisons against established joint pruning-quantization baselines (including HAQ and related RL-based methods), report mean and standard deviation over at least three independent runs with different random seeds, and explicitly state the dataset splits and training protocols used for all reported results. revision: yes
-
Referee: [Method] Active-learning loop description: the manuscript states that the MLP surrogate is used only for reward shaping and that final results come from post-compression fine-tuning, yet provides no quantitative evidence (e.g., correlation plots or ablation) showing that surrogate-guided trajectories preserve the validity of those final results. This assumption underpins the practicality claim.
Authors: The manuscript already states that the surrogate is used exclusively for reward shaping and that all final accuracy numbers are obtained after full post-compression fine-tuning. To supply the requested quantitative validation we will add, in the revision, (i) scatter plots showing correlation between surrogate-predicted rewards and the actual post-fine-tuning accuracies for the trajectories explored, and (ii) an ablation that compares final compression-accuracy outcomes when the RL policy is trained with versus without the surrogate guidance. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents an empirical hierarchical RL framework for joint pruning and quantization of neural networks. Reported outcomes (compression ratios of 5.99-6.72× and accuracy metrics) are obtained from experiments on standard Vision Transformer and CNN benchmarks rather than from any closed-form derivation or fitted parameter that reduces to the method's own inputs by construction. The described components (per-block LLAs, ensemble HLAs with Fisher sensitivity, active-learning MLP surrogate for reward shaping) are presented as architectural design choices whose validity is assessed via post-compression fine-tuning and benchmark performance; no equations, self-definitional loops, or load-bearing self-citations are visible in the provided text that would force the results tautologically. The controller's architecture-agnostic claim is supported by the modular abstraction and external benchmark results, keeping the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[2]
Recent Advances in
Islam, Khawar , journal =. Recent Advances in. 2022 , url =
2022
-
[3]
Rao, Yongming and Zhao, Wenliang and Liu, Benlin and Lu, Jiwen and Zhou, Jie and Hsieh, Cho-Jui , booktitle =
-
[4]
and Piergiovanni, AJ and Arnab, Anurag and Dehghani, Mostafa and Angelova, Anelia , booktitle =
Ryoo, Michael S. and Piergiovanni, AJ and Arnab, Anurag and Dehghani, Mostafa and Angelova, Anelia , booktitle =
-
[5]
Understanding and Improving
Lu, Yiping and Li, Zhuohan and He, Di and Sun, Zhiqing and Dong, Bin and Qin, Tao and Wang, Liwei and Liu, Tie-Yan , booktitle =. Understanding and Improving
-
[6]
Understanding and Overcoming the Challenges of Efficient
Bondarenko, Yelysei and Nagel, Markus and Blankevoort, Tijmen , booktitle =. Understanding and Overcoming the Challenges of Efficient
-
[7]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Learned Step Size Quantization , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
-
[8]
and Keutzer, Kurt , booktitle =
Dong, Zhen and Yao, Zhewei and Arfeen, Daiyaan and Gholami, Amir and Mahoney, Michael W. and Keutzer, Kurt , booktitle =
-
[9]
The State of Sparsity in Deep Neural Networks
The State of Sparsity in Deep Neural Networks , author =. arXiv preprint arXiv:1902.09574 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1902
-
[10]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Are Sixteen Heads Really Better than One? , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[11]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Structured Pruning of Large Language Models , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2020
-
[12]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned , author =. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[13]
He, Yihui and Lin, Ji and Liu, Zhijian and Wang, Hanrui and Li, Li-Jia and Han, Song , booktitle =
-
[14]
Wang, Kuan and Liu, Zhijian and Lin, Yujun and Lin, Ji and Han, Song , booktitle =
-
[15]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[16]
2018 , publisher =
Rashid, Tabish and Samvelyan, Mikayel and de Witt, Christian Schroeder and Farquhar, Gregory and Foerster, Jakob and Whiteson, Shimon , booktitle =. 2018 , publisher =
2018
-
[17]
2018 , isbn =
Reinforcement Learning: An Introduction , author =. 2018 , isbn =
2018
-
[18]
Neural Combinatorial Optimization with Reinforcement Learning
Neural Combinatorial Optimization with Reinforcement Learning , author =. arXiv preprint arXiv:1611.09940 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Proximal Policy Optimization Algorithms
Proximal Policy Optimization Algorithms , author =. arXiv preprint arXiv:1707.06347 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Proceedings of the International Conference on Machine Learning (ICML) , series =
Asynchronous Methods for Deep Reinforcement Learning , author =. Proceedings of the International Conference on Machine Learning (ICML) , series =. 2016 , publisher =
2016
-
[21]
Proceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM) , pages =
Revisiting State Augmentation Methods for Reinforcement Learning with Stochastic Delays , author =. Proceedings of the 30th ACM International Conference on Information and Knowledge Management (CIKM) , pages =. 2021 , doi =
2021
-
[22]
On Inductive Biases in Deep Reinforcement Learning
On Inductive Biases in Deep Reinforcement Learning , author =. arXiv preprint arXiv:1907.02908 , year =
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[23]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Learning both Weights and Connections for Efficient Neural Network , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[24]
ACM Journal on Emerging Technologies in Computing Systems , volume =
Structured Pruning of Deep Convolutional Neural Networks , author =. ACM Journal on Emerging Technologies in Computing Systems , volume =. 2017 , doi =
2017
-
[25]
Proceedings of the International Conference on Machine Learning (ICML) , series =
The State of Sparse Training in Deep Reinforcement Learning , author =. Proceedings of the International Conference on Machine Learning (ICML) , series =. 2022 , publisher =
2022
-
[26]
Proceedings of the International Conference on Machine Learning (ICML) , series =
In Value-Based Deep Reinforcement Learning, a Pruned Network is a Good Network , author =. Proceedings of the International Conference on Machine Learning (ICML) , series =. 2024 , publisher =
2024
-
[27]
Reinforcement Learning Journal , volume =
Eau De Q -Network: Adaptive Distillation of Neural Networks in Deep Reinforcement Learning , author =. Reinforcement Learning Journal , volume =
-
[28]
Faster gaze prediction with dense networks and
Theis, Lucas and Korshunova, Iryna and Tejani, Alykhan and Huszár, Ferenc , journal =. Faster gaze prediction with dense networks and. 2018 , url =
2018
-
[29]
Proceedings of the International Conference on Machine Learning (ICML) , year =
Training data-efficient image transformers & distillation through attention , author =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[30]
Proceedings of the International Conference on Machine Learning (ICML) , year =
Learning transferable visual models from natural language supervision , author =. Proceedings of the International Conference on Machine Learning (ICML) , year =
-
[31]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Deep residual learning for image recognition , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[32]
Sandler, Mark and Howard, Andrew and Zhu, Menglong and Zhmoginov, Andrey and Chen, Liang-Chieh , booktitle =
-
[33]
2025 , doi =
Ahmed, Sabbir and Al Arafat, Abdullah and Najafi, Deniz and Mahmood, Akhlak and Rizve, Mamshad Nayeem and Al Nahian, Mohaiminul and Zhou, Ranyang and Angizi, Shaahin and Rakin, Adnan Siraj , booktitle =. 2025 , doi =
2025
-
[34]
Li, Zhikai and Gu, Qingyi , booktitle =
-
[35]
Proceedings of the International Conference on Learning Representations (ICLR) , year =
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding , author =. Proceedings of the International Conference on Learning Representations (ICLR) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.