Grounded Iterative Language Planning: How Parameterized World Models Reduce Hallucination Propagation in LLM Agents
Pith reviewed 2026-06-29 04:43 UTC · model grok-4.3
The pith
A small parameterized backbone grounds LLM drafts via consistency checks to cut hallucinated states in planning agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
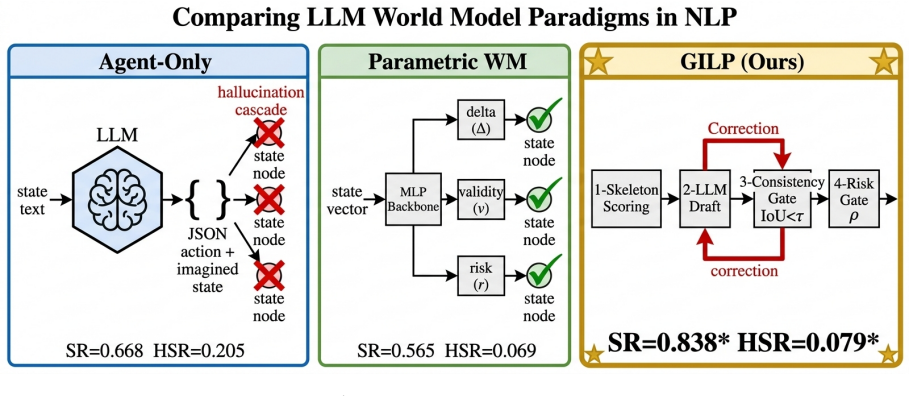
GILP trains only a small parameterized backbone and combines it with API-based agent reasoning. The backbone supplies valid actions, predicted state deltas, risk, and value; the LLM drafts an action and imagined delta; and a consistency gate asks for revision when the two disagree. On real GPT-4o-mini calls, GILP reduces hallucinated-state rate from 0.176 to 0.035. In calibrated simulator ablations, it raises success from 0.668 to 0.838 while adding only ~22% extra LLM calls.
What carries the argument
The consistency gate that compares an LLM-drafted state delta against the parameterized backbone's prediction and triggers revision on mismatch.
If this is right
- Hallucinated-state rate drops from 0.176 to 0.035 on real GPT-4o-mini calls.
- Planning success rises from 0.668 to 0.838 in calibrated simulator ablations.
- The hybrid adds only about 22 percent extra LLM calls.
- The method applies across four graph-structured planning benchmarks.
Where Pith is reading between the lines
- The same consistency mechanism could extend planning horizons before errors accumulate.
- A sufficiently accurate backbone might allow smaller or cheaper LLMs to reach comparable reliability.
- Grounding via external predictions offers a route to safer agent behavior in interactive settings.
Load-bearing premise
The small parameterized backbone can reliably supply valid actions, predicted state deltas, risk, and value estimates that correctly identify when the LLM draft is inconsistent without introducing new errors or overly restricting the LLM's flexibility.
What would settle it
Running the same four graph benchmarks and GPT-4o-mini calls with the consistency gate removed and checking whether the hallucinated-state rate stays near 0.176 rather than falling to 0.035.
Figures











read the original abstract
World models for language agents come in two useful forms. An agent-based world model calls an LLM API and reasons flexibly in language, but its errors appear as hallucinated state changes that are hard to score with ordinary regression losses. A parameterized world model is a trained transition predictor; its errors are easier to measure with quantities such as NodeMSE, delta accuracy, and validity accuracy, but it is usually weaker as a standalone planner. We compare these two families on four graph-structured planning benchmarks and introduce operational hallucination metrics for the agent-based case. The comparison motivates \textbf{Grounded Iterative Language Planning} (GILP), which trains only a small parameterized backbone and combines it with API-based agent reasoning. The backbone supplies valid actions, predicted state deltas, risk, and value; the LLM drafts an action and imagined delta; and a consistency gate asks for revision when the two disagree. On real GPT-4o-mini calls, GILP reduces hallucinated-state rate from 0.176 to 0.035. In calibrated simulator ablations, it raises success from 0.668 to 0.838 while adding only ~22% extra LLM calls.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a hybrid approach called Grounded Iterative Language Planning (GILP) — training only a small parameterized backbone to supply valid actions, predicted state deltas, risk, and value estimates, then using these in a consistency gate to revise LLM action drafts — reduces hallucinated-state rates from 0.176 to 0.035 on real GPT-4o-mini calls and raises success rates from 0.668 to 0.838 in calibrated simulator ablations on four graph-structured planning benchmarks, at the cost of only ~22% extra LLM calls. It also introduces operational hallucination metrics for agent-based world models.
Significance. If substantiated, the result would show that lightweight parameterized world models can effectively ground flexible LLM reasoning to limit hallucination propagation in planning agents, providing a practical middle ground between pure agent-based and pure parameterized approaches while keeping API overhead modest. The operational metrics for scoring hallucinated state changes in LLM agents would also be a useful addition to evaluation practices in this area.
major comments (2)
- Abstract: The headline reductions (hallucinated-state rate 0.176→0.035; success 0.668→0.838) depend on the consistency gate correctly identifying LLM inconsistencies using the backbone's outputs. No standalone metrics are reported for the backbone's validity accuracy, delta accuracy, or false-positive rate when applied to LLM-generated drafts, so it is impossible to determine whether the gains arise from genuine grounding or from an overly restrictive filter that shrinks the LLM's search space.
- Abstract / implied methods: The abstract references 'calibrated simulator ablations' and real API calls but supplies no dataset details, error bars, or full ablation tables, which are required to verify the robustness of the reported improvements and to isolate the contribution of the consistency gate.
minor comments (1)
- The manuscript would benefit from an explicit table comparing the parameterized backbone in isolation against the full GILP hybrid on the same metrics.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We believe the concerns raised can be addressed through clarifications and additions to the manuscript, particularly in the abstract and methods sections. Below we provide point-by-point responses.
read point-by-point responses
-
Referee: Abstract: The headline reductions (hallucinated-state rate 0.176→0.035; success 0.668→0.838) depend on the consistency gate correctly identifying LLM inconsistencies using the backbone's outputs. No standalone metrics are reported for the backbone's validity accuracy, delta accuracy, or false-positive rate when applied to LLM-generated drafts, so it is impossible to determine whether the gains arise from genuine grounding or from an overly restrictive filter that shrinks the LLM's search space.
Authors: The full manuscript reports the backbone's validity accuracy, delta accuracy, and related metrics in Section 4 along with an analysis of the consistency gate. However, we acknowledge that the abstract does not explicitly present these to contextualize the headline results. We will revise the abstract to include these metrics and add a sentence clarifying that the gate's false-positive rate on LLM drafts is evaluated in the experiments, demonstrating that improvements arise from accurate grounding. revision: yes
-
Referee: Abstract / implied methods: The abstract references 'calibrated simulator ablations' and real API calls but supplies no dataset details, error bars, or full ablation tables, which are required to verify the robustness of the reported improvements and to isolate the contribution of the consistency gate.
Authors: Dataset details appear in Section 3, error bars are included in all reported results, and full ablation tables isolating the consistency gate are in the appendix. The abstract's brevity precludes full details, but we agree this could be improved. We will update the abstract to reference the four benchmarks and ablation studies more explicitly, and ensure the main text isolates the gate's contribution. revision: yes
Circularity Check
No circularity; empirical results on external benchmarks and real API calls
full rationale
The paper trains a small parameterized backbone for valid actions, state deltas, risk and value, then applies a consistency gate to LLM drafts. Reported gains (hallucinated-state rate 0.176→0.035 on GPT-4o-mini; success 0.668→0.838 in simulator) are measured directly against real model calls and calibrated external ablations rather than being derived by construction from the fitted parameters or any self-citation chain. No load-bearing step reduces to self-definition, fitted-input-as-prediction, or imported uniqueness; the evaluation remains independent of the method's internal fits.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2023 , eprint =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , eprint =
2023
-
[2]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language Agents with Verbal Reinforcement Learning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2303.11366 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2201.11903 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2305.10601 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =. 2305.04091 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Reasoning with Language Model is Planning with World Model
Reasoning with Language Model is Planning with World Model , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =. 2305.14992 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Large Language Models as Commonsense Knowledge for Large-Scale Task Planning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2305.14078 , archivePrefix =
-
[8]
International Conference on Machine Learning (ICML) , year =
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents , author =. International Conference on Machine Learning (ICML) , year =. 2201.07207 , archivePrefix =
-
[9]
Zhu, Xizhou and Chen, Yuntao and Tian, Hao and Tao, Chenxin and Su, Weijie and Yang, Chenyu and Huang, Gao and Li, Bin and Lu, Lewei and Wang, Xiaogang and Qiao, Yu and Zhang, Zhaoxiang and Dai, Jifeng , journal =
-
[10]
and Chao, Wei-Lun and Su, Yu , booktitle =
Song, Chan Hee and Wu, Jiaman and Washington, Clayton and Sadler, Brian M. and Chao, Wei-Lun and Su, Yu , booktitle =. 2023 , pages =
2023
-
[11]
ALFWorld: Aligning Text and Embodied Environments for Interactive Learning
Shridhar, Mohit and Yuan, Xingdi and C. International Conference on Learning Representations (ICLR) , year =. 2010.03768 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[12]
2022 , eprint =
Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik , booktitle =. 2022 , eprint =
2022
-
[13]
2024 , eprint =
Qin, Yujia and Liang, Shihao and Ye, Yining and Zhu, Kunlun and Yan, Lan and Lu, Yaxi and Lin, Yankai and Cong, Xin and Tang, Xiangru and Qian, Bill and Zhao, Sihan and Hong, Lauren and Tian, Runchu and Xie, Ruobing and Zhou, Jie and Gerstein, Mark and Li, Dahai and Liu, Zhiyuan and Sun, Maosong , booktitle =. 2024 , eprint =
2024
-
[14]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An Open-Ended Embodied Agent with Large Language Models , author =. Transactions on Machine Learning Research , year =. 2305.16291 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
2023 , eprint =
Shen, Yongliang and Song, Kaitao and Tan, Xu and Li, Dongsheng and Lu, Weiming and Zhuang, Yueting , booktitle =. 2023 , eprint =
2023
-
[16]
2024 , eprint =
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and Zhang, Shudan and Deng, Xiang and Zeng, Aohan and Du, Zhengxiao and Zhang, Chenhui and Shen, Sheng and Zhang, Tianjun and Su, Yu and Sun, Huan and Huang, Minlie and Dong, Yuxiao and Tang, Jie , booktitle...
2024
-
[17]
Kambhampati, Subbarao and Valmeekam, Karthik and Guan, Lin and Stechly, Kaya and Verma, Mudit and Bhambri, Siddhant and Saldyt, Lucas and Murthy, Anil , journal =
-
[18]
Advances in Neural Information Processing Systems (NeurIPS) , year =
On the Planning Abilities of Large Language Models -- A Critical Investigation , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2305.15771 , archivePrefix =
-
[19]
2023 , eprint =
Lin, Bill Yuchen and Fu, Yicheng and Yang, Karina and Brahman, Faeze and Huang, Shiyu and Bhagavatula, Chandra and Ammanabrolu, Prithviraj and Choi, Yejin and Ren, Xiang , booktitle =. 2023 , eprint =
2023
-
[20]
Toolformer: Language Models Can Teach Themselves to Use Tools
Toolformer: Language Models Can Teach Themselves to Use Tools , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2302.04761 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2302.01560 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Recurrent World Models Facilitate Policy Evolution , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 1803.10122 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Dream to Control: Learning Behaviors by Latent Imagination
Dream to Control: Learning Behaviors by Latent Imagination , author =. International Conference on Learning Representations (ICLR) , year =. 1912.01603 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[24]
Mastering
Hafner, Danijar and Lillicrap, Timothy and Norouzi, Mohammad and Ba, Jimmy , booktitle =. Mastering. 2021 , eprint =
2021
-
[25]
Mastering Diverse Domains through World Models
Mastering Diverse Domains through World Models , author =. arXiv preprint arXiv:2301.04104 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
, journal =
Sutton, Richard S. , journal =
-
[27]
Foundations and Trends in Machine Learning , volume =
Model-Based Reinforcement Learning: A Survey , author =. Foundations and Trends in Machine Learning , volume =
-
[28]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Deep Reinforcement Learning in a Handful of Trials Using Probabilistic Dynamics Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[29]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Offline Reinforcement Learning as One Big Sequence Modeling Problem , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2106.02039 , archivePrefix =
-
[30]
Mastering
Schrittwieser, Julian and Antonoglou, Ioannis and Hubert, Thomas and Simonyan, Karen and Sifre, Laurent and Schmitt, Simon and Guez, Arthur and Lockhart, Edward and Hassabis, Demis and Graepel, Thore and Lillicrap, Timothy and Silver, David , booktitle =. Mastering. 2020 , volume =
2020
-
[31]
Semi-Supervised Classification with Graph Convolutional Networks
Semi-Supervised Classification with Graph Convolutional Networks , author =. International Conference on Learning Representations (ICLR) , year =. 1609.02907 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Inductive Representation Learning on Large Graphs , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[33]
International Conference on Machine Learning (ICML) , year =
Neural Message Passing for Quantum Chemistry , author =. International Conference on Machine Learning (ICML) , year =
-
[34]
Graph Attention Networks , author =. International Conference on Learning Representations (ICLR) , year =. 1710.10903 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Recipe for a General, Powerful, Scalable Graph Transformer , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2205.12454 , archivePrefix =
-
[36]
European Semantic Web Conference (ESWC) , year =
Modeling Relational Data with Graph Convolutional Networks , author =. European Semantic Web Conference (ESWC) , year =
-
[37]
How Powerful are Graph Neural Networks?
How Powerful are Graph Neural Networks? , author =. International Conference on Learning Representations (ICLR) , year =. 1810.00826 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
and Andreas, Jacob , journal =
Gu, Yu and Du, Yilun and Tenenbaum, Joshua B. and Andreas, Jacob , journal =. Are
-
[39]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Language Models Meet World Models: Embodied Experiences Enhance Language Models , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2305.10626 , archivePrefix =
-
[40]
International Conference on Machine Learning (ICML) , year =
Do Embodied Agents Dream of Pixelated Sheep: Embodied Decision Making using Language Guided World Modelling , author =. International Conference on Machine Learning (ICML) , year =. 2301.12050 , archivePrefix =
-
[41]
2024 , eprint =
Zhu, Deyao and Chen, Jun and Shen, Xiaoqian and Li, Xiang and Elhoseiny, Mohamed , booktitle =. 2024 , eprint =
2024
-
[42]
2024 , eprint =
Zhao, Andrew and Huang, Daniel and Xu, Quentin and Lin, Matthieu and Liu, Yong-Jin and Huang, Gao , booktitle =. 2024 , eprint =
2024
-
[43]
Siren's Song in the
Zhang, Yue and Li, Yafu and Cui, Leyang and Cai, Deng and Liu, Lemao and Fu, Tingchen and Huang, Xinting and Zhao, Enbo and Zhang, Yu and Chen, Yulong and Wang, Longyue and Luu, Anh Tuan and Bi, Wei and Shi, Freda and Shi, Shuming , journal =. Siren's Song in the
-
[44]
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , author =. arXiv preprint arXiv:2311.05232 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[45]
A Survey of Hallucination in Large Foundation Models
A Survey of Hallucination in Large Foundation Models , author =. arXiv preprint arXiv:2309.05922 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
ACM Computing Surveys , volume =
Survey of Hallucination in Natural Language Generation , author =. ACM Computing Surveys , volume =
-
[47]
Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
On Faithfulness and Factuality in Abstractive Summarization , author =. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[48]
Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS) , year =
A Novel Iterative Approach to Top-k Planning , author =. Proceedings of the International Conference on Automated Planning and Scheduling (ICAPS) , year =
-
[49]
Annual Review of Control, Robotics, and Autonomous Systems , volume =
Integrated Task and Motion Planning , author =. Annual Review of Control, Robotics, and Autonomous Systems , volume =
-
[50]
arXiv preprint arXiv:2203.09634 , year =
Inventing Relational State and Action Abstractions for Effective and Efficient Bilevel Planning , author =. arXiv preprint arXiv:2203.09634 , year =
-
[51]
Liu, Bo and Jiang, Yuqian and Zhang, Xiaohan and Liu, Qiang and Zhang, Shiqi and Biswas, Joydeep and Stone, Peter , journal =
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-Based Task Planning , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2305.14909 , archivePrefix =
-
[53]
and Kaelbling, Leslie Pack and Katz, Michael , booktitle =
Silver, Tom and Dan, Soham and Srinivas, Kavitha and Tenenbaum, Joshua B. and Kaelbling, Leslie Pack and Katz, Michael , booktitle =. Generalized Planning in
-
[54]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[55]
arXiv preprint arXiv:2303.08774 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Training Language Models to Follow Instructions with Human Feedback , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[57]
Touvron, Hugo and Martin, Louis and Stone, Kevin and Albert, Peter and Almahairi, Amjad and Babaei, Yasmine and others , journal =
-
[58]
Self-Consistency Improves Chain of Thought Reasoning in Language Models
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations (ICLR) , year =. 2203.11171 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[59]
Advances in Neural Information Processing Systems (NeurIPS) , year =
Large Language Models are Zero-Shot Reasoners , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =
-
[60]
Self-Refine: Iterative Refinement with Self-Feedback
Self-Refine: Iterative Refinement with Self-Feedback , author =. Advances in Neural Information Processing Systems (NeurIPS) , year =. 2303.17651 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Proceedings of the
Graph of Thoughts: Solving Elaborate Problems with Large Language Models , author =. Proceedings of the. 2024 , eprint =
2024
-
[62]
Proceedings of the 36th Annual
Generative Agents: Interactive Simulacra of Human Behavior , author =. Proceedings of the 36th Annual
-
[63]
Let's Verify Step by Step , author =. arXiv preprint arXiv:2305.20050 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[64]
Zhou, Shuyan and Xu, Frank F and Zhu, Hao and others , booktitle=
-
[65]
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models , author=. arXiv:2310.04406 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[66]
NeurIPS , year=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. NeurIPS , year=
-
[67]
Executable Code Actions Elicit Better
Wang, Xingyao and Chen, Yangyi and others , booktitle=. Executable Code Actions Elicit Better
-
[68]
Jimenez, Carlos E and Yang, John and others , booktitle=
-
[69]
ICLR , year=
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author=. ICLR , year=
-
[70]
Chain-of-Verification Reduces Hallucination in Large Language Models
Chain-of-Verification Reduces Hallucination in Large Language Models , author=. arXiv:2309.11495 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
IJCNLP-AACL , year=
Faithful Chain-of-Thought Reasoning , author=. IJCNLP-AACL , year=
-
[72]
TMLR , year=
Cognitive Architectures for Language Agents , author=. TMLR , year=
-
[73]
Zeng, Aohan and Liu, Mingdao and others , booktitle=
-
[74]
Zhao, Jiaan and others , journal=. Is
-
[75]
Chen, Baian and Shu, Chang and others , journal=
-
[76]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: A Family of Highly Capable Multimodal Models , author=. arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Check Your Facts and Try Again: Improving Large Language Models with External Knowledge and Automated Feedback , author=. arXiv:2302.12813 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Gou, Zhibin and others , booktitle=
-
[79]
TACL , year=
Automatically Correcting Large Language Models: Surveying the Landscape of Diverse Automated Correction Strategies , author=. TACL , year=
-
[80]
ACL Findings , year=
Towards Faithful Explanations for Text Classification with Robustness Improvement , author=. ACL Findings , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.