ATOD: Annealed Turn-aware On-policy Distillation for Multi-turn Autonomous Agents
Pith reviewed 2026-06-29 04:27 UTC · model grok-4.3
The pith
ATOD anneals on-policy distillation into RL to let small agents exceed their teachers on long interactive tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
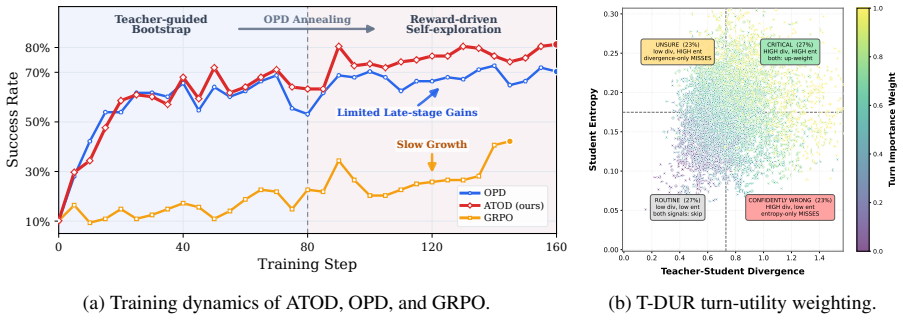
ATOD is a hybrid online distillation algorithm that uses an annealed OPD-RL schedule, where OPD dominates early training to approach teacher-level behavior while RL is gradually strengthened to drive reward-based exploration, together with Turn-level Disagreement-Uncertainty Reweighting (T-DUR) that softly amplifies high-utility turns. On ALFWorld, WebShop, and Search-QA, ATOD improves average success rate by 3.03 points over OPD and 23.62 points over GRPO across the three student sizes, while surpassing the corresponding teacher models by 2.16 points.
What carries the argument
Annealed OPD-RL schedule combined with Turn-level Disagreement-Uncertainty Reweighting (T-DUR), which balances fast imitation against later reward-driven improvement and focuses dense supervision in long trajectories.
If this is right
- Small student models can exceed the success rates of their larger teacher models on the tested interactive benchmarks.
- The hybrid method outperforms both pure OPD and GRPO-style RL across different student sizes.
- Turn-level reweighting improves dense supervision without requiring changes to the underlying teacher or environment reward.
- The approach works on diverse tasks including embodied navigation, web shopping, and question answering.
Where Pith is reading between the lines
- The same annealing logic could be tested on tasks with even longer horizons to check whether the complementarity holds beyond the current benchmarks.
- T-DUR might be combined with other dense signals such as process rewards instead of disagreement-uncertainty.
- If the schedule generalizes, agent training pipelines could reduce dependence on ever-larger teacher models by letting smaller students continue improving after imitation saturates.
Load-bearing premise
The complementarity between OPD and RL can be reliably exploited via a simple annealed schedule and turn-level reweighting without introducing instability or negative transfer in long trajectories.
What would settle it
Training runs on a new multi-turn benchmark where the annealed schedule produces lower final success rates than either pure OPD or pure RL, or where performance drops sharply after the annealing midpoint, would falsify the central claim.
Figures













read the original abstract
Training small language-model agents for long-horizon interactive tasks requires both fast imitation and reward-driven improvement. On-policy distillation (OPD) provides dense teacher guidance and typically improves rapidly in the early stage, but its gains saturate once the student approaches the teacher, limiting the final performance ceiling. Reinforcement learning (RL) directly optimizes environment rewards and encourages exploratory improvement toward a higher reward-defined ceiling, but sparse and delayed feedback makes early-stage learning much less efficient than OPD. In this paper, we propose ATOD (Annealed Turn-aware On-policy Distillation), a hybrid online distillation algorithm that explicitly exploits this complementarity. (1) ATOD uses an annealed OPD-RL schedule: OPD dominates early training to approach teacher-level behavior, while RL is gradually strengthened to drive reward-based exploration. (2) ATOD introduces Turn-level Disagreement-Uncertainty Reweighting (T-DUR), which softly amplifies high-utility turns and improves dense supervision in long trajectories. Experiments on ALFWorld, WebShop, and Search-QA show that ATOD consistently outperforms competing post-training baselines: across the three student sizes, ATOD improves average success rate by 3.03 points over OPD and 23.62 points over GRPO, while surpassing the corresponding teacher models by 2.16 points.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ATOD, a hybrid online distillation algorithm for training small language-model agents on long-horizon tasks. It combines an annealed schedule that starts with on-policy distillation (OPD) dominance and gradually increases RL weight, together with Turn-level Disagreement-Uncertainty Reweighting (T-DUR) to amplify high-utility turns. Experiments on ALFWorld, WebShop, and Search-QA report that ATOD improves average success rate by 3.03 points over OPD and 23.62 points over GRPO across three student sizes, while exceeding the corresponding teacher models by 2.16 points.
Significance. If the reported gains are reproducible and the annealing plus T-DUR components prove stable, the work supplies a concrete, practical recipe for exploiting the early-stage efficiency of imitation and the asymptotic ceiling of reward optimization in multi-turn agent training. The explicit complementarity framing and turn-level reweighting are the main technical contributions.
major comments (3)
- [Abstract, §3] Abstract and §3 (method): the annealed OPD-RL schedule is described only at a high level; no explicit functional form, hyper-parameter schedule, or stability analysis is provided for the annealing rate, which is listed as a free parameter. This makes it impossible to assess whether the reported complementarity is robust or sensitive to the particular schedule chosen.
- [Abstract] Abstract: the claim that ATOD surpasses the teacher models by 2.16 points is load-bearing for the central narrative that RL can push beyond the teacher ceiling, yet no per-task breakdown, variance, or statistical test is supplied to show the improvement is not driven by a subset of environments or by teacher under-performance.
- [Abstract] Abstract, weakest-assumption paragraph: T-DUR is introduced to improve dense supervision in long trajectories, but the manuscript supplies neither the precise disagreement/uncertainty metric nor an ablation isolating its contribution from the annealing schedule alone.
minor comments (1)
- [Abstract] The abstract states three benchmarks but does not indicate whether the same student/teacher pairs and evaluation protocol were used across all three; a table summarizing per-benchmark deltas would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their thoughtful comments and the opportunity to improve our manuscript. We address each of the major comments below and will make the necessary revisions to enhance clarity and support for our claims.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (method): the annealed OPD-RL schedule is described only at a high level; no explicit functional form, hyper-parameter schedule, or stability analysis is provided for the annealing rate, which is listed as a free parameter. This makes it impossible to assess whether the reported complementarity is robust or sensitive to the particular schedule chosen.
Authors: We agree with this observation. The current description in the manuscript is indeed high-level. In the revised version, we will explicitly define the functional form of the annealing schedule (e.g., linear interpolation between OPD and RL weights over training steps), specify the hyper-parameters used in our experiments, and include a stability analysis showing performance across a range of annealing rates. revision: yes
-
Referee: [Abstract] Abstract: the claim that ATOD surpasses the teacher models by 2.16 points is load-bearing for the central narrative that RL can push beyond the teacher ceiling, yet no per-task breakdown, variance, or statistical test is supplied to show the improvement is not driven by a subset of environments or by teacher under-performance.
Authors: We acknowledge the need for more detailed evidence supporting this claim. We will revise the abstract and add a dedicated table or section providing per-task success rates for ATOD versus the teacher models, including standard deviations across multiple runs and results from statistical tests (e.g., paired t-tests) to confirm the significance of the improvement. revision: yes
-
Referee: [Abstract] Abstract, weakest-assumption paragraph: T-DUR is introduced to improve dense supervision in long trajectories, but the manuscript supplies neither the precise disagreement/uncertainty metric nor an ablation isolating its contribution from the annealing schedule alone.
Authors: We concur that additional details on T-DUR are warranted. In the revision, we will provide the exact mathematical formulation of the disagreement and uncertainty metrics used in T-DUR within Section 3. Furthermore, we will include an ablation study that compares the full ATOD against a variant with annealing but without T-DUR to isolate its contribution. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical proposal of the ATOD algorithm (annealed OPD-RL schedule plus T-DUR reweighting) whose central claims are performance deltas measured on ALFWorld, WebShop and Search-QA. These deltas are reported as experimental outcomes rather than first-principles derivations or predictions obtained by fitting parameters to the same data. The abstract and provided text contain no equations, no self-citation load-bearing premises, and no steps that reduce by construction to their own inputs. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- annealing rate between OPD and RL
Reference graph
Works this paper leans on
-
[1]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InInternational Conference on Learning Representations, 2023
2023
-
[2]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess`ı, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, 2023
2023
-
[3]
Alfworld: Aligning text and embodied environments for interactive learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre C ˆot´e, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. Alfworld: Aligning text and embodied environments for interactive learning. In International Conference on Learning Representations, 2021
2021
-
[4]
Webshop: Towards scalable real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. InAdvances in Neural Information Processing Systems, 2022
2022
-
[5]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. Nature, 645:633–638, 2025
2025
-
[9]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Archer: Training language model agents via hierarchical multi-turn rl
Yifei Zhou, Andrea Zanette, Jiayi Pan, Sergey Levine, and Aviral Kumar. Archer: Training language model agents via hierarchical multi-turn rl. InProceedings of the 41st International Conference on Machine Learning, pages 62178–62209, 2024
2024
-
[11]
Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning
Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Wenyi Zhao, Yu Yang, Xinyue Yang, Jiadai Sun, Shuntian Yao, Tianjie Zhang, Wei Xu, Jie Tang, and Yuxiao Dong. Webrl: Training llm web agents via self-evolving online curriculum reinforcement learning. InInternational Conference on Learning Representations, 2025
2025
-
[12]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Agentic Reinforced Policy Optimization
Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou. Agentic reinforced policy optimization.arXiv preprint arXiv:2507.19849, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
On-policy distillation of language models: Learning from self-generated mistakes
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self-generated mistakes. InInternational Conference on Learning Representations, 2024
2024
-
[15]
Minillm: Knowledge distillation of large language models
Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. Minillm: Knowledge distillation of large language models. InInternational Conference on Learning Representations, 2024
2024
-
[16]
Entropy-Aware On-Policy Distillation of Language Models
Woogyeol Jin, Taywon Min, Yongjin Yang, Swanand Ravindra Kadhe, Yi Zhou, Dennis Wei, Nathalie Baracaldo, and Kimin Lee. Entropy-aware on-policy distillation of language models.arXiv preprint arXiv:2603.07079, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
On-Policy Context Distillation for Language Models
Tianzhu Ye, Li Dong, Xun Wu, Shaohan Huang, and Furu Wei. On-policy context distillation for language models.arXiv preprint arXiv:2602.12275, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
Stable On-Policy Distillation through Adaptive Target Reformulation
Ijun Jang, Jewon Yeom, Juan Yeo, Hyunggu Lim, and Taesup Kim. Stable on-policy distillation through adaptive target reformulation.arXiv preprint arXiv:2601.07155, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.arXiv preprint arXiv:2602.12125, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
TCOD: Exploring Temporal Curriculum in On-Policy Distillation for Multi-turn Autonomous Agents
Jiaqi Wang, Wenhao Zhang, Weijie Shi, Yaliang Li, and James Cheng. Tcod: Exploring temporal cur- riculum in on-policy distillation for multi-turn autonomous agents.arXiv preprint arXiv:2604.24005, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
SOD: Step-wise On-policy Distillation for Small Language Model Agents
Qiyong Zhong, Mao Zheng, Mingyang Song, Xin Lin, Jie Sun, Houcheng Jiang, Xiang Wang, and Junfeng Fang. Sod: Step-wise on-policy distillation for small language model agents.arXiv preprint arXiv:2605.07725, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
TIP: Token Importance in On-Policy Distillation
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. Tip: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Skill-SD: Skill-Conditioned Self-Distillation for Multi-turn LLM Agents
Hao Wang, Guozhi Wang, Han Xiao, Yufeng Zhou, Yue Pan, Jichao Wang, Ke Xu, Yafei Wen, Xiaohu Ruan, Xiaoxin Chen, and Honggang Qi. Skill-sd: Skill-conditioned self-distillation for multi-turn llm agents.arXiv preprint arXiv:2604.10674, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Self-Distilled Agentic Reinforcement Learning
Zhengxi Lu, Zhiyuan Yao, Zhuowen Han, Zi-Han Wang, Jinyang Wu, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. Self-distilled agentic reinforcement learning.arXiv preprint arXiv:2605.15155, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research.Transact...
2019
-
[27]
Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1601–1611, 2017
2017
-
[28]
Cohen, Ruslan Salakhutdinov, and Christopher D
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William W. Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369–2380, 2018. 11
2018
-
[29]
Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition.Transactions of the Association for Computational Linguistics, 10:539–554, 2022
2022
-
[30]
Smith, and Mike Lewis
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, 2023. 12 Appendix Contents A Method and Algorithmic Details 14 A.1 Complete Training Algorithm . . . . . . . . . . . . . . . . . . . ...
2023
-
[31]
If you find you lack some knowledge, you MUST call a search engine to get more external information using format:<search>your query</search>
-
[32]
I first need to find the lettuce; I will start by checking countertops
If you have enough knowledge to answer the question confidently, provide your final answer within <answer> </answer>tags, without detailed illustrations. For example, <answer>Beijing</answer>. Figure 8: Prompt template used by ATOD for the Search-based QA task environment. Prompt of ATOD on WebShop You are an expert autonomous agent operating in the WebSh...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.