GUICrafter: Weakly-Supervised GUI Agent Leveraging Massive Unannotated Screenshots
Pith reviewed 2026-06-30 06:37 UTC · model grok-4.3
The pith
GUICrafter trains effective GUI agents from mostly unannotated screenshots via a two-stage curriculum.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
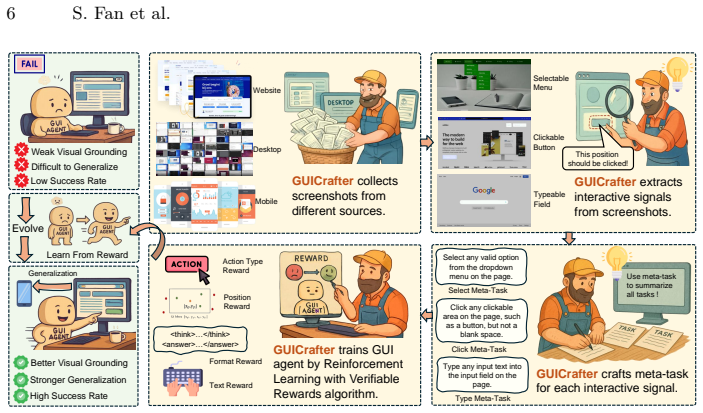
GUICrafter shows that visual grounding for GUI elements can be acquired from large-scale unannotated screenshots and webpages in an initial stage, after which reinforcement learning on limited high-quality data produces agents that match or surpass fully supervised baselines such as UI-TARS and GUI-R1.
What carries the argument
The two-stage curriculum learning framework: Stage 1 pre-trains visual grounding on unannotated screenshots and webpages using inherent contextual signals, followed by Stage 2 reinforcement learning calibration on a small annotated set.
If this is right
- GUI agent training can scale by drawing on internet-scale unannotated data instead of relying primarily on human annotations.
- Cross-device generalization improves because the first stage exposes the model to diverse unannotated GUI layouts and contexts.
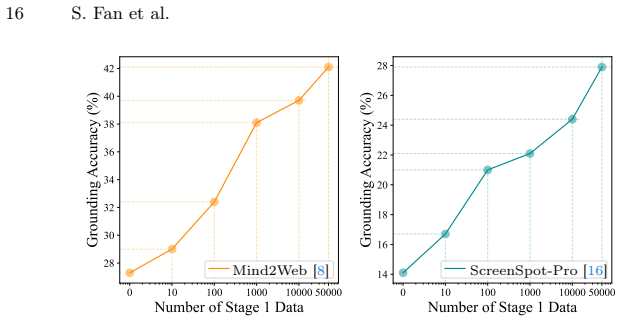
- The same amount of annotated data yields higher performance than prior methods when preceded by the unannotated pre-training stage.
- Annotation costs for new GUI agent domains can be reduced by reusing the learned grounding from broad unannotated corpora.
Where Pith is reading between the lines
- The approach could transfer to other visual interaction domains such as mobile apps or web automation where unannotated screenshots are plentiful.
- If the contextual signals in unannotated data prove robust, the method might support rapid adaptation to entirely new device types with minimal additional labels.
- Combining the pre-training stage with larger vision-language models could further lower the annotated data requirement.
Load-bearing premise
Large volumes of unannotated screenshots and webpages contain enough contextual signals to support effective visual grounding learning without any human annotations.
What would settle it
Training an identical model architecture on the same small annotated set but skipping the unannotated pre-training stage and measuring whether performance drops substantially below the full two-stage system.
Figures


read the original abstract
Data, as the fundamental substrate of modern intelligence, has greatly driven the development of current foundation models. Naturally, researchers aim to extend this paradigm to the domain of GUI agents, hoping to build strong GUI agents through a similar paradigm. However, GUI agent data cannot be directly harvested from the internet, making it costly and difficult to collect at scale. As a result, current GUI agents suffer from poor cross-device generalization and limited visual grounding ability for fine-grained GUI elements. As an attempt to address data challenge in GUI agents, we propose GUICrafter, a weakly-supervised GUI agent leveraging massive unannotated screenshots to substantially reduce the reliance on expensive human annotations. GUICrafter explores a curriculum learning framework for training GUI agents through two progressive stages. First, the model learns visual grounding from large-scale unannotated screenshots and webpages, leveraging the rich contextual signals inherent in GUI interactions without human annotations. Then, in Stage 2, we leverage a small amount of high-quality data to calibrate the model via reinforcement learning. Experiments show that GUICrafter achieves competitive, or even superior, performance to advanced systems like UI-TARS while using only 0.1% of its data. Furthermore, under the same amount of annotated data, GUICrafter surpasses all previous methods such as GUI-R1. Code, data, and models are available at https://github.com/fansunqi/GUICrafter.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GUICrafter, a weakly-supervised GUI agent trained via a two-stage curriculum: Stage 1 pre-trains visual grounding on large-scale unannotated screenshots and webpages by exploiting inherent contextual signals, followed by Stage 2 reinforcement learning calibration on a small amount of high-quality annotated data. The central claims are that this yields competitive or superior performance to UI-TARS while using only 0.1% of its data, and outperforms prior methods such as GUI-R1 when restricted to the same volume of annotated data.
Significance. If the empirical results hold, the work would meaningfully advance scalable GUI agent development by demonstrating that expensive human annotations can be largely replaced by unannotated web-scale data for the grounding stage, directly addressing the data bottleneck, poor cross-device generalization, and weak fine-grained visual grounding noted in the abstract.
major comments (1)
- [Abstract] Abstract: the performance claims (competitive/superior to UI-TARS with 0.1% data; surpasses GUI-R1 under matched annotation budgets) are asserted without any reported experimental details, including datasets used, evaluation metrics, baselines, ablation studies, statistical tests, or result tables. This absence is load-bearing because the central contribution is an empirical demonstration of data-efficient training; without these elements the claims cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for their review and for highlighting the need for greater clarity in the abstract regarding our empirical claims. We address the comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the performance claims (competitive/superior to UI-TARS with 0.1% data; surpasses GUI-R1 under matched annotation budgets) are asserted without any reported experimental details, including datasets used, evaluation metrics, baselines, ablation studies, statistical tests, or result tables. This absence is load-bearing because the central contribution is an empirical demonstration of data-efficient training; without these elements the claims cannot be assessed.
Authors: We agree that the abstract would benefit from additional high-level context to make the performance claims more immediately assessable. While the full experimental details—including the specific GUI benchmarks and datasets, success-rate and other metrics, baselines (UI-TARS, GUI-R1 and others), ablation studies, and result tables—are reported in Section 4 of the manuscript, the abstract currently states the outcomes at a summary level only. We will revise the abstract to briefly reference the evaluation benchmarks, the 0.1% data comparison, and the matched-annotation-budget setting. We note that exhaustive details such as full ablation tables and statistical tests are appropriately placed in the body rather than the abstract; the revision will therefore focus on improving the abstract’s informativeness without expanding it into a results section. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical curriculum-learning pipeline consisting of Stage 1 pre-training on large-scale unannotated screenshots/webpages for visual grounding followed by Stage 2 RL calibration on a small annotated set. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on standard supervised/RL training applied to external data sources rather than any internal reduction of outputs to author-defined inputs by construction. The approach is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Unannotated screenshots and webpages contain rich contextual signals inherent in GUI interactions that can be leveraged for visual grounding without human annotations.
Reference graph
Works this paper leans on
-
[1]
com/news/developing-computer-use11
Anthropic: Developing a computer use model (2024),https://www.anthropic. com/news/developing-computer-use11
2024
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-VL technical report (2025),https://arxiv.org/abs/2502.139232, 9, 10, 11, 12, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
ByteDance: UI-TARS-2 technical report: Advancing gui agent with multi-turn re- inforcement learning (2025),https://arxiv.org/abs/2509.025444
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: Findings of the Association for Computational Linguistics: ACL 2025
Chai, Y., Huang, S., Niu, Y., Xiao, H., Liu, L., Wang, G., Zhang, D., Ren, S., Li, H.: Amex: Android multi-annotation expo dataset for mobile gui agents. In: Findings of the Association for Computational Linguistics: ACL 2025. pp. 2138–2156 (2025) 8
2025
-
[5]
Chen, D., Huang, Y., Wu, S., Tang, J., Chen, L., Bai, Y., He, Z., Wang, C., Zhou, H., Li, Y., Zhou, T., Yu, Y., Gao, C., Zhang, Q., Gui, Y., Li, Z., Wan, Y., Zhou, P., Gao, J., Sun, L.: GUI-World: A video benchmark and dataset for multimodal gui-oriented understanding (2025),https://arxiv.org/abs/2406.108194
-
[6]
In: Ku, L.W., Mar- tins, A., Srikumar, V
Cheng, K., Sun, Q., Chu, Y., Xu, F., YanTao, L., Zhang, J., Wu, Z.: SeeClick: Harnessing GUI grounding for advanced visual GUI agents. In: Ku, L.W., Mar- tins, A., Srikumar, V. (eds.) Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 9313–
-
[7]
https://doi.org/10.18653/v1/2024.acl-long.5054, 10, 11
Association for Computational Linguistics, Bangkok, Thailand (Aug 2024). https://doi.org/10.18653/v1/2024.acl-long.5054, 10, 11
- [8]
-
[9]
Advances in Neural Informa- tion Processing Systems36, 28091–28114 (2023) 2, 3, 4, 8, 9, 13, 15, 16
Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., Su, Y.: Mind2Web: Towards a generalist agent for the web. Advances in Neural Informa- tion Processing Systems36, 28091–28114 (2023) 2, 3, 4, 8, 9, 13, 15, 16
2023
-
[10]
In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing
Fang, T., Zhang, H., Zhang, Z., Ma, K., Yu, W., Mi, H., Yu, D.: WebEvolver: En- hancing web agent self-improvement with co-evolving world model. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 8970–8986 (2025) 4
2025
-
[11]
In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=kxnoqaisCT4, 10, 11
Gou, B., Wang, R., Zheng, B., Xie, Y., Chang, C., Shu, Y., Sun, H., Su, Y.: Navigating the digital world as humans do: Universal visual grounding for GUI agents. In: The Thirteenth International Conference on Learning Representations (2025),https://openreview.net/forum?id=kxnoqaisCT4, 10, 11
2025
-
[12]
Gu, Z., Zeng, Z., Xu, Z., Zhou, X., Shen, S., Liu, Y., Zhou, B., Meng, C., Xia, T., Chen, W., Wen, Y., Dou, J., Tang, F., Lin, J., Liu, Y., Guo, Z., Gong, Y., Jia, H., Gao, C., Guo, Y., Deng, Y., Guo, Z., Chen, L., Wang, W.: Ui-Venus technical report: Building high-performance ui agents with rft (2025),https://arxiv.org/ abs/2508.108334
-
[13]
Nature645, 633–638 (2025).https://doi.org/ 10.1038/s41586-025-09422-z7
Guo, D., Yang, D., Zhang, H., et al.: DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature645, 633–638 (2025).https://doi.org/ 10.1038/s41586-025-09422-z7
-
[14]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Dong, Y., Ding, M., Tang, J.: CogAgent: A visual language model for gui agents. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14281–14290 (June 2024) 4, 11 18 S. Fan et al
2024
-
[15]
In: European Conference on Computer Vision
Kapoor, R., Butala, Y.P., Russak, M., Koh, J.Y., Kamble, K., AlShikh, W., Salakhutdinov, R.: Omniact: A dataset and benchmark for enabling multimodal generalist autonomous agents for desktop and web. In: European Conference on Computer Vision. pp. 161–178. Springer (2024) 4, 9
2024
- [16]
- [17]
-
[18]
On the effects of data scale on ui control agents, 2024
Li, W., Bishop, W., Li, A., Rawles, C., Campbell-Ajala, F., Tyamagundlu, D., Riva, O.: On the effects of data scale on ui control agents (2024),https://arxiv. org/abs/2406.036794, 5, 6, 9, 12
-
[19]
In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Lin, K.Q., Li, L., Gao, D., Yang, Z., Wu, S., Bai, Z., Lei, S.W., Wang, L., Shou, M.Z.: ShowUI: One vision-language-action model for gui visual agent. In: Proceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19498–19508 (June 2025) 4, 9, 10, 11, 12
2025
-
[20]
Liu, E.Z., Guu, K., Pasupat, P., Shi, T., Liang, P.: Reinforcement learning on web interfaces using workflow-guided exploration. In: 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings (2018),https://openreview.net/forum?id= ryTp3f-0-3, 4
2018
-
[21]
Liu, X., Qin, B., Liang, D., Dong, G., Lai, H., Zhang, H., Zhao, H., Iong, I.L., Sun, J., Wang, J., Gao, J., Shan, J., Liu, K., Zhang, S., Yao, S., Cheng, S., Yao, W., Zhao, W., Liu, X., Liu, X., Chen, X., Yang, X., Yang, Y., Xu, Y., Yang, Y., Wang, Y., Xu, Y., Qi, Z., Dong, Y., Tang, J.: AutoGLM: Autonomous foundation agents for guis (2024),https://arxiv...
- [22]
- [23]
-
[24]
Lu, Z., Chai, Y., Guo, Y., Yin, X., Liu, L., Wang, H., Xiao, H., Ren, S., Xiong, G., Li, H.: UI-R1: Enhancing efficient action prediction of gui agents by reinforcement learning (2025),https://arxiv.org/abs/2503.216202, 4, 9, 10, 11, 12, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Luo, R., Wang, L., He, W., Chen, L., Li, J., Xia, X.: GUI-R1: A generalist r1- style vision-language action model for gui agents (2025),https://arxiv.org/ abs/2504.104582, 3, 4, 8, 9, 10, 11, 12, 22
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
OpenAI: GPT-4V(ision) system card (2023),https://openai.com/index/gpt- 4v-system-card/10
2023
-
[27]
OpenAI: GPT-4 technical report (2024),https://arxiv.org/abs/2303.0877410
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
OpenAI: GPT-4o system card (2024),https://openai.com/index/gpt- 4o- system-card/9, 10, 11, 12, 13, 22
2024
-
[29]
OpenAI: Learning to reason with llms (2024),https://openai.com/index/ learning-to-reason-with-llms/7
2024
-
[30]
Pan, Y., Kong, D., Zhou, S., Cui, C., Leng, Y., Jiang, B., Liu, H., Shang, Y., Zhou, S., Wu, T., Wu, Z.: WebCanvas: Benchmarking web agents in online environments (2024),https://arxiv.org/abs/2406.123734
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [31]
-
[32]
In: Yang, Y., Davani, A., Sil, A., Kumar, A
Qian, Y., Lu, Y., Hauptmann, A., Riva, O.: Visual grounding for user interfaces. In: Yang, Y., Davani, A., Sil, A., Kumar, A. (eds.) Proceedings of the 2024 Con- ference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 6: Industry Track). pp. 97–
2024
-
[33]
https://doi.org/10.18653/v1/2024.naacl-industry.94
Association for Computational Linguistics, Mexico City, Mexico (Jun 2024). https://doi.org/10.18653/v1/2024.naacl-industry.94
-
[34]
Qin, Y., Ye, Y., Fang, J., Wang, H., Liang, S., Tian, S., Zhang, J., Li, J., Li, Y., Huang, S., Zhong, W., Li, K., Yang, J., Miao, Y., Lin, W., Liu, L., Jiang, X., Ma, Q., Li, J., Xiao, X., Cai, K., Li, C., Zheng, Y., Jin, C., Li, C., Zhou, X., Wang, M., Chen, H., Li, Z., Yang, H., Liu, H., Lin, F., Peng, T., Liu, X., Shi, G.: UI-TARS: Pioneering automate...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= il5yUQsrjC9
Rawles, C., Clinckemaillie, S., Chang, Y., Waltz, J., Lau, G., Fair, M., Li, A., Bishop, W.E., Li, W., Campbell-Ajala, F., Toyama, D.K., Berry, R.J., Tyama- gundlu, D., Lillicrap, T.P., Riva, O.: AndroidWorld: A dynamic benchmarking environment for autonomous agents. In: The Thirteenth International Confer- ence on Learning Representations (2025),https://...
2025
-
[36]
Advances in Neural Information Processing Systems36, 59708–59728 (2023) 9, 12
Rawles, C., Li, A., Rodriguez, D., Riva, O., Lillicrap, T.: Androidinthewild: A large-scale dataset for android device control. Advances in Neural Information Processing Systems36, 59708–59728 (2023) 9, 12
2023
-
[37]
Shao, Z., Wang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y.K., Wu, Y., Guo, D.: DeepSeekMath: Pushing the limits of mathematical reasoning in open language models (2024),https://arxiv.org/abs/2402.03300 21
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [38]
- [39]
-
[40]
In: Koenig, S., Jenkins, C., Taylor, M.E
Tang, F., Gu, Z., Lu, Z., Liu, X., Shen, S., Meng, C., Wang, W., Zhang, W., Shen, Y., Lu, W., Xiao, J., Zhuang, Y.: GUI-G2: Gaussian reward modeling for GUI grounding. In: Koenig, S., Jenkins, C., Taylor, M.E. (eds.) Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Ap- plications of Artificial Intelligence, Sixte...
-
[41]
Rethinking cross-subject data splitting for brain-to-text decoding
Wei, Z., Yao, W., Liu, Y., Zhang, W., Lu, Q., Qiu, L., Yu, C., Xu, P., Zhang, C., Yin, B., Yun, H., Li, L.: WebAgent-R1: Training web agents via end-to-end multi- turn reinforcement learning. In: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V. (eds.) Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. pp. 79...
-
[42]
Wu, Q., Cheng, K., Yang, R., Zhang, C., Yang, J., Jiang, H., Mu, J., Peng, B., Qiao, B., Tan, R., Qin, S., Liden, L., Lin, Q., Zhang, H., Zhang, T., Zhang, J., Zhang, D., Gao, J.: GUI-Actor: Coordinate-free visual grounding for gui agents (2025),https://arxiv.org/abs/2506.031434 20 S. Fan et al
-
[43]
Wu, Z., Wu, Z., Xu, F., Wang, Y., Sun, Q., Jia, C., Cheng, K., Ding, Z., Chen, L., Liang, P.P., Qiao, Y.: OS-ATLAS: A foundation action model for generalist gui agents (2024),https://arxiv.org/abs/2410.232184, 11, 12, 22
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
In: The Fourteenth International Conference on Learning Represen- tations (2026),https://openreview.net/forum?id=C3F0G9nXhl4, 5
Xu, Y., Liu, X., Liu, X., Fu, J., Huang, J., Zhang, H., Jing, B., Zhang, S., Wang, Y., wenyi, Z., Dong, Y.: MobileRL: Online agentic reinforcement learning for mobile GUI agents. In: The Fourteenth International Conference on Learning Represen- tations (2026),https://openreview.net/forum?id=C3F0G9nXhl4, 5
2026
-
[45]
Aguvis: Unified Pure Vision Agents for Autonomous GUI Interaction
Xu, Y., Wang, Z., Wang, J., Lu, D., Xie, T., Saha, A., Sahoo, D., Yu, T., Xiong, C.: Aguvis: Unified pure vision agents for autonomous gui interaction. In: The Thirteenth International Conference on Learning Representations (2024),https: //arxiv.org/abs/2412.044543, 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [46]
- [47]
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yang, J., Tan, R., Wu, Q., Zheng, R., Peng, B., Liang, Y., Gu, Y., Cai, M., Ye, S., Jang, J., Deng, Y., Gao, J.: Magma: A foundation model for multimodal ai agents. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 14203–14214 (June 2025) 4
2025
-
[49]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Yang, Y., Wang, Y., Li, D., Luo, Z., Chen, B., Huang, C., Li, J.: Aria-UI: Visual grounding for GUI instructions. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Findings of the Association for Computational Linguistics: ACL 2025. pp. 22418–22433. Association for Computational Linguistics, Vienna, Austria (Jul 2025).https://doi.org/10.18653/v...
-
[50]
Ye, J., Zhang, X., Xu, H., Liu, H., Wang, J., Zhu, Z., Zheng, Z., Gao, F., Cao, J., Lu, Z., Liao, J., Zheng, Q., Huang, F., Zhou, J., Yan, M.: Mobile-Agent-v3: Fundamental agents for gui automation (2025),https://arxiv.org/abs/2508. 151444
2025
- [51]
- [52]
-
[53]
In: Findings of the Association for Computational Linguistics: EMNLP 2024
Zhang, J., Wu, J., Yihua, T., Liao, M., Xu, N., Xiao, X., Wei, Z., Tang, D.: Android in the zoo: Chain-of-action-thought for gui agents. In: Findings of the Association for Computational Linguistics: EMNLP 2024. pp. 12016–12031 (2024) 5, 7
2024
-
[54]
In:FindingsoftheAssociationforComputationalLinguistics:ACL2024.pp.3132– 3149 (2024) 12
Zhang, Z., Zhang, A.: You only look at screens: Multimodal chain-of-action agents. In:FindingsoftheAssociationforComputationalLinguistics:ACL2024.pp.3132– 3149 (2024) 12
2024
- [55]
-
[56]
Zhou, S., Xu, F.F., Zhu, H., Zhou, X., Lo, R., Sridhar, A., Cheng, X., Ou, T., Bisk, Y., Fried, D., Alon, U., Neubig, G.: WebArena: A realistic web environment for building autonomous agents. In: Proceedings of the NeurIPS 2023 Workshop on Agent Learning in Open-Endedness (2023),https://webarena.dev/3 GUICrafter 21 Appendix A Preliminaries A.1 GUI Agent F...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.