UniSAE: Unified Speech Attribute Editing on Speaker, Emotion and Low-Level Content via Discrete Phonetic Posteriorgram Modelling
Pith reviewed 2026-07-01 04:01 UTC · model grok-4.3
The pith
A single framework unifies editing of speaker, emotion and speech content from sub-phoneme to word level via discrete phonetic tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
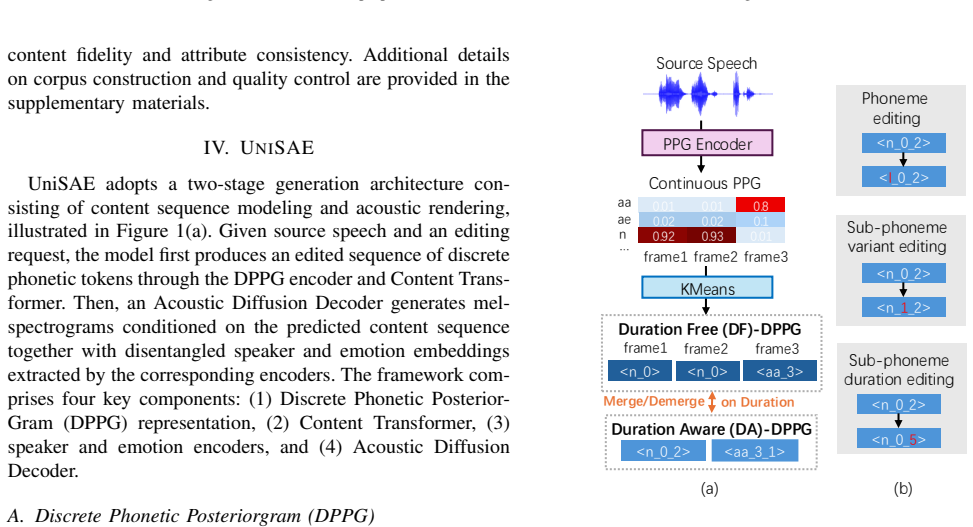
UniSAE introduces a Discrete Phonetic PosteriorGram representation that factorizes speech content into discrete tokens encoding phoneme identity, pronunciation variants, and duration, enabling direct phoneme- and sub-phoneme-level editing. For word-level changes an autoregressive content transformer predicts edited token sequences. These sequences are rendered into speech by a diffusion-based acoustic decoder conditioned on disentangled speaker and emotion representations, allowing joint modification of all three attributes inside one model.
What carries the argument
Discrete Phonetic PosteriorGram (DPPG) representation that factorizes speech content into discrete tokens encoding phoneme identity, pronunciation variants, and duration.
If this is right
- Precise speaker and emotion control is possible alongside content changes.
- Content editing works at both sub-phoneme and word granularities.
- All three attributes can be modified jointly inside the same framework.
- A diffusion decoder conditioned on disentangled features renders the edited tokens into speech.
Where Pith is reading between the lines
- The token approach could be paired with text prompts to guide which parts of an utterance to change.
- If the diffusion decoder runs faster, the method might support interactive editing tools.
- The same factorization of identity, variant and duration might be tested on music or environmental audio.
Load-bearing premise
The discrete tokens separate content information cleanly enough that edits to them can be decoded back into natural speech without extra artifacts.
What would settle it
A side-by-side listening test in which listeners rate jointly edited samples as markedly less natural or intelligible than the same edits performed by separate speaker, emotion and content models.
Figures


read the original abstract
Speech editing aims to modify specific portions of an utterance while preserving the remaining speech. Existing approaches primarily focus on word-level content modification and typically treat content, speaker, and emotion editing as separate tasks, limiting both editing granularity and flexibility. We propose UniSAE, a unified speech attribute editing framework which supports composable speaker, emotion and content editing from sub-phoneme to word level within a single architecture. UniSAE introduces a Discrete Phonetic PosteriorGram (DPPG) representation that factorizes speech content into discrete tokens encoding phoneme identity, pronunciation variants, and duration, enabling direct phoneme- and sub-phoneme-level editing. For higher-level modifications, an autoregressive content transformer predicts edited DPPG sequences for word-level content editing. The edited sequences are rendered into speech by a diffusion-based acoustic decoder, conditioned on disentangled speaker and emotion representations. Experimental results demonstrate that the proposed unified framework supports precise speaker and emotion control, content editing at multiple granularities, and joint modification of all three attributes within a single framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes UniSAE, a unified speech attribute editing framework supporting composable speaker, emotion, and content edits from sub-phoneme to word level. It introduces a Discrete Phonetic PosteriorGram (DPPG) that factorizes content into discrete tokens for phoneme identity, variants, and duration; an autoregressive content transformer for word-level edits; and a diffusion-based acoustic decoder conditioned on disentangled speaker and emotion representations. The abstract asserts that experimental results demonstrate precise control and joint editing within a single architecture.
Significance. If the experimental claims hold with appropriate validation, the work would offer a notable contribution to speech editing by unifying multiple attributes and granularities in one model, potentially simplifying pipelines for applications such as voice conversion and audio post-production.
major comments (1)
- [Abstract] Abstract: the statement that 'Experimental results demonstrate that the proposed unified framework supports precise speaker and emotion control, content editing at multiple granularities, and joint modification of all three attributes within a single framework' is presented without any accompanying metrics, baselines, ablation studies, tables, or implementation details, leaving the central empirical claim without verifiable grounding.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below and outline the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'Experimental results demonstrate that the proposed unified framework supports precise speaker and emotion control, content editing at multiple granularities, and joint modification of all three attributes within a single framework' is presented without any accompanying metrics, baselines, ablation studies, tables, or implementation details, leaving the central empirical claim without verifiable grounding.
Authors: We acknowledge the validity of this observation: the abstract presents a high-level summary of results without embedding specific metrics or implementation details. Abstracts are constrained by length and conventionally refer readers to the body of the paper for verification. The full manuscript contains quantitative evaluations, baseline comparisons, ablation studies, and tables in Sections 4 and 5 that substantiate the claims of precise control, multi-granularity editing, and joint attribute modification. To directly address the concern, we will revise the abstract to include brief references to key metrics (e.g., speaker similarity scores, emotion classification accuracy, and content edit success rates) or qualify the claim more precisely while maintaining conciseness. revision: yes
Circularity Check
No significant circularity
full rationale
The manuscript introduces UniSAE as a new architectural proposal built around a Discrete Phonetic PosteriorGram representation, an autoregressive content transformer, and a diffusion decoder, with no equations, derivations, or parameter-fitting steps presented. The central claims rest on the novelty of the DPPG factorization and the unified editing pipeline rather than any reduction of outputs to inputs by construction or to self-citations that bear the load of the results. Because the paper supplies no mathematical chain that could collapse into its own fitted quantities or prior-author uniqueness theorems, the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Discrete Phonetic PosteriorGram (DPPG)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2407.17172 , year=
T. K ¨assmann, Y . Liu, and D. Liu, “Speech editing–a summary,”arXiv preprint arXiv:2407.17172, 2024
-
[2]
V oice- Craft: Zero-shot speech editing and text-to-speech in the wild,
P. Peng, P.-Y . Huang, S.-W. Li, A. Mohamed, and D. Harwath, “V oice- Craft: Zero-shot speech editing and text-to-speech in the wild,” inProc. 62nd Annu. Meeting Assoc. Comput. Linguistics, 2024, pp. 12 442– 12 462
2024
-
[3]
SSR-Speech: Towards stable, safe and robust zero-shot text- based speech editing and synthesis,
H. Wang, M. Yu, J. Hai, C. Chen, Y . Hu, R. Chen, N. Dehak, and D. Yu, “SSR-Speech: Towards stable, safe and robust zero-shot text- based speech editing and synthesis,” inProc. IEEE Int. Conf. on Acoust., Speech and Signal Process., 2025, pp. 1–5
2025
-
[4]
Zero shot audio to audio emotion transfer with speaker disentanglement,
S. Dutta and S. Ganapathy, “Zero shot audio to audio emotion transfer with speaker disentanglement,” inProc. IEEE Int. Conf. Acoust. Speech Signal Process., 2024, pp. 10 371–10 375
2024
-
[5]
EMOCONV-Diff: Diffusion-based speech emotion conversion for non-parallel and in-the-wild data,
N. R. Prabhu, B. Lay, S. Welker, N. Lehmann-Willenbrock, and T. Gerk- mann, “EMOCONV-Diff: Diffusion-based speech emotion conversion for non-parallel and in-the-wild data,” inProc. IEEE Int. Conf. Acoust. Speech Signal Process., 2024, pp. 11 651–11 655
2024
-
[6]
Sta- bleVC: Style controllable zero-shot voice conversion with conditional flow matching,
J. Yao, Y . Yuguang, Y . Pan, Z. Ning, J. Ye, H. Zhou, and L. Xie, “Sta- bleVC: Style controllable zero-shot voice conversion with conditional flow matching,” inProc. AAAI Conf. Artif. Intell., vol. 39, no. 24, 2025, pp. 25 669–25 677
2025
-
[7]
Emodiff: Intensity controllable emotional text-to-speech with soft-label guidance,
Y . Guo, C. Du, X. Chen, and K. Yu, “Emodiff: Intensity controllable emotional text-to-speech with soft-label guidance,” inProc. IEEE Int. Conf. Acoust. Speech Signal Process., 2023, pp. 1–5
2023
-
[8]
H. Hu, X. Zhu, T. He, D. Guo, B. Zhang, X. Wang, Z. Guo, Z. Jiang, H. Hao, Z. Guo, X. Zhang, P. Zhang, B. Yang, J. Xu, J. Zhou, and J. Lin, “Qwen3-TTS Technical Report,”arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
S. Zhou, Y . Zhou, Y . He, X. Zhou, J. Wang, W. Deng, and J. Shu, “Indextts2: A breakthrough in emotionally expressive and duration- controlled auto-regressive zero-shot text-to-speech,”arXiv:2506.21619, 2025
-
[10]
Actormind: Emulating human actor rea- soning for speech role-playing,
X. Chen, W. Xue, and Y . Guo, “Actormind: Emulating human actor rea- soning for speech role-playing,” inFindings Assoc. Comput. Linguistics: ACL 2026. Assoc. Comput. Linguistics, Apr. 2026
2026
-
[11]
Revealing emotional clusters in speaker embeddings: A contrastive learning strategy for speech emotion recognition,
I. R. Ulgen, Z. Du, C. Busso, and B. Sisman, “Revealing emotional clusters in speaker embeddings: A contrastive learning strategy for speech emotion recognition,” inICASSP 2024-2024 IEEE Int. Conf. on Acoust., Speech and Signal Process., 2024, pp. 12 081–12 085
2024
-
[12]
CSTR VCTK Cor- pus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92),
J. Yamagishi, C. Veaux, and K. MacDonald, “CSTR VCTK Cor- pus: English multi-speaker corpus for CSTR voice cloning toolkit (version 0.92),” Edinburgh DataShare, 2019. [Online]. Available: https://datashare.ed.ac.uk/handle/10283/3443
2019
-
[13]
arXiv preprint arXiv:2502.05512 , year=
W. Deng, S. Zhou, J. Shu, J. Wang, and L. Wang, “IndexTTS: An industrial-level controllable and efficient zero-shot text-to-speech sys- tem,”arXiv:2502.05512, 2025
-
[14]
UTMOS: UTokyo-SaruLab System for V oiceMOS Chal- lenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oiceMOS Chal- lenge 2022,” inProc. Interspeech 2022, 2022, pp. 4521–4525
2022
-
[15]
Least squares quantization in PCM,
S. Lloyd, “Least squares quantization in PCM,”IEEE Trans. Inf. Theory, vol. 28, no. 2, pp. 129–137, 1982
1982
-
[16]
Language models are unsupervised multitask learners,
A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language models are unsupervised multitask learners,”OpenAI Blog, vol. 1, no. 8, p. 9, 2019
2019
-
[17]
g2pE: A simple python module for English grapheme to phoneme conversion,
K. Park and J. Kim, “g2pE: A simple python module for English grapheme to phoneme conversion,” GitHub, 2019. [Online]. Available: https://github.com/Kyubyong/g2p
2019
-
[18]
Generalized end-to-end loss for speaker verification,
L. Wan, Q. Wang, A. Papir, and I. L. Moreno, “Generalized end-to-end loss for speaker verification,” inProc. IEEE Int. Conf. Acoust. Speech Signal Process., 2018, pp. 4879–4883
2018
-
[19]
LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus,
Y . Koizumi, H. Zen, S. Karita, Y . Ding, K. Yatabe, N. Morioka, M. Bacchiani, Y . Zhang, W. Han, and A. Bapna, “LibriTTS-R: A Restored Multi-Speaker Text-to-Speech Corpus,” inProc. Interspeech 2023, 2023, pp. 5496–5500
2023
-
[20]
Seen and unseen emotional style transfer for voice conversion with a new emotional speech dataset,
K. Zhou, B. Sisman, R. Liu, and H. Li, “Seen and unseen emotional style transfer for voice conversion with a new emotional speech dataset,” inProc. IEEE Int. Conf. Acoust. Speech Signal Process., 2021, pp. 920– 924
2021
-
[21]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” Advances Neural Inf. Process. Syst., vol. 33, pp. 12 449–12 460, 2020
2020
-
[22]
BigVGAN: A Universal Neural Vocoder with Large-Scale Training.arXiv preprint arXiv:2206.04658, 2022
S. Lee, W. Ping, B. Ginsburg, B. Catanzaro, and S. Yoon, “BigVGAN: A universal neural vocoder with large-scale training,”arXiv:2206.04658, 2022
-
[23]
Resemblyzer: A python package to analyze and compare voices with deep learning,
Resemble-AI, “Resemblyzer: A python package to analyze and compare voices with deep learning,” GitHub, 2019. [Online]. Available: https: //github.com/resemble-ai/Resemblyzer
2019
-
[24]
arXiv preprint arXiv:2312.15185 , year=
Z. Ma, Z. Zheng, J. Ye, J. Li, Z. Gao, S. Zhang, and X. Chen, “emotion2vec: Self-supervised pre-training for speech emotion repre- sentation,”arXiv:2312.15185, 2023
-
[25]
High-fidelity neural pho- netic posteriorgrams,
C. Churchwell, M. Morrison, and B. Pardo, “High-fidelity neural pho- netic posteriorgrams,” inProc. Int. Conf. Acoust. Speech Signal Process. Workshops, 2024, pp. 823–827
2024
-
[26]
The ryerson audio-visual database of emotional speech and song (RA VDESS): A dynamic, multimodal set of facial and vocal expressions in North American English,
S. R. Livingstone and F. A. Russo, “The ryerson audio-visual database of emotional speech and song (RA VDESS): A dynamic, multimodal set of facial and vocal expressions in North American English,”PloS one, vol. 13, no. 5, p. e0196391, 2018
2018
-
[27]
MEAD: A large-scale audio-visual dataset for emotional talking-face generation,
K. Wang, Q. Wu, L. Song, Z. Yang, W. Wu, C. Qian, R. He, Y . Qiao, and C. C. Loy, “MEAD: A large-scale audio-visual dataset for emotional talking-face generation,” inProc. ECCV, 2020, pp. 700–717. SUPPLEMENTARYMATERIAL A. Prompt pool Table IX summarizes the emotional speech corpora used to construct the prompt pool for UniEditCorpus. All selected corpora ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.