Scenario Generation for Testing of Autonomous Driving Systems Using Real-World Failure Records
Pith reviewed 2026-07-01 05:55 UTC · model grok-4.3
The pith
LLM pipeline generates accurate and diverse test scenarios for autonomous driving from real-world failure records.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
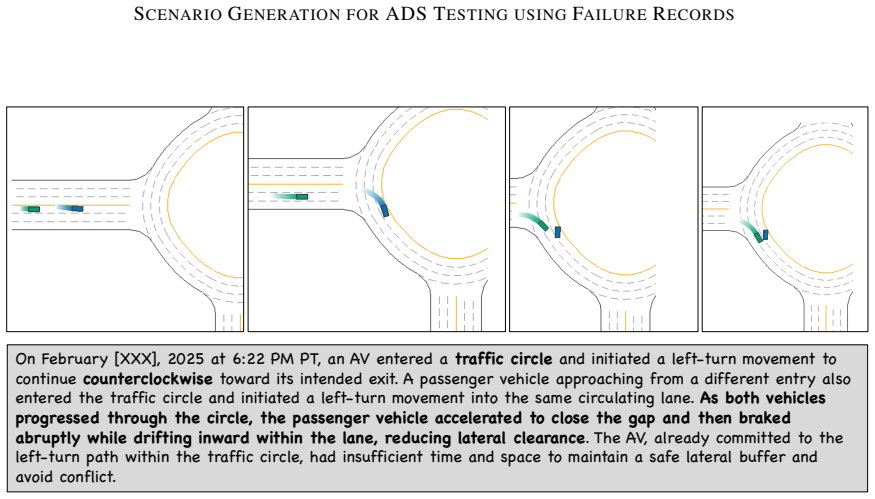
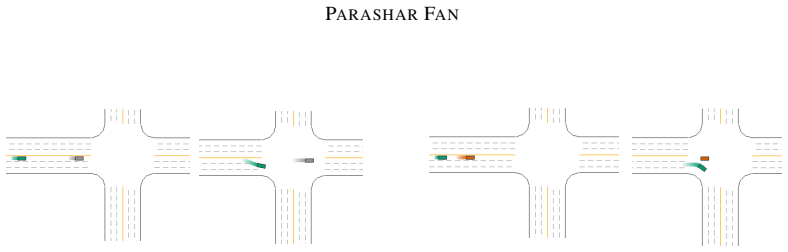
The central discovery is a modular LLM-based pipeline that extracts categorical and contextual information from natural language ADS crash records and translates it into diverse, simulator-compatible scenarios. When applied to NHTSA records for testing on Metadrive, it generates scenarios with combinations of 4 road types, 3 non-ego vehicle movements, and on-road anomalies such as working zones. These scenarios align with provided testing conditions and reveal interesting failures within a budget of 20 scenarios.
What carries the argument
Modular LLM based synthetic scenario generation that translates natural language failure records into simulator-compatible scenarios.
Load-bearing premise
The large language model can reliably extract and translate categorical and contextual information from natural language failure records into simulator-compatible scenarios without significant errors or loss of fidelity.
What would settle it
Running the 20 generated scenarios in the Metadrive simulator and checking whether they match the original NHTSA failure conditions or fail to reveal the reported system failures would test the claim.
Figures




read the original abstract
To ensure safe on-road behavior, pre-deployment testing and failure discovery of Autonomous Driving Systems (ADS) is crucial. Present day simulation based testing methods focus largely on mathematical models for efficient search of optimal scenarios, assuming a fixed scenario representation. On the other hand, real-world testing involves substantial manual effort to design scenario templates for testing. These templates represent distinct failure scenarios consisting of pre-deployment vehicle movements, map types, etc. Historical failure records for ADS are a reliable source of real-world failure conditions, which can be used for scenario generation. In this work, we propose a scenario generation pipeline using categorical and contextual information available from historical records in natural language format. Our approach consists of modular LLM based synthetic scenario generation, compatible with the testing constraints of a given system. We successfully apply our method to generate a diverse set of scenarios for testing autonomous navigation on Metadrive simulator using the NHTSA ADS crash records. Our approach results in accurate and diverse scenario generation with a combination of 4 road types, 3 non ego vehicle movement types, including on road anomalies in the form of working zones. Generated scenarios align with the provided testing conditions, and reveals interesting failures of the system within a limited testing budget of 20 scenarios. Code is available at https://github.com/anjaliParashar/crash2scenario.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a modular LLM-based pipeline to translate natural-language NHTSA ADS crash records into simulator-compatible scenarios for MetaDrive. It claims to produce accurate and diverse scenarios (4 road types, 3 non-ego movement types, work-zone anomalies) that align with given testing constraints and reveal failures in only 20 scenarios. Code is released at the cited GitHub repository.
Significance. If the extraction fidelity holds, the work supplies a practical bridge between real-world failure records and simulation testing that could complement purely mathematical scenario search or manual template design. Public code release supports reproducibility and is a clear strength.
major comments (2)
- [Abstract and results] Abstract and results description: the central claim that scenarios are 'accurate' and that the LLM 'reliably extract[s] and translate[s]' categorical/contextual information rests on an unverified step. No fidelity metric, edit-distance score, inter-annotator agreement, or source-record vs. generated-parameter comparison is reported, leaving the diversity and failure-revelation results without quantitative grounding.
- [Method and evaluation] Method and evaluation sections: the pipeline description does not include any error analysis or validation protocol for the LLM extraction of road type, vehicle movement, or anomaly fields. Because this extraction is the load-bearing prerequisite for all downstream claims, its absence prevents assessment of whether the generated scenarios actually preserve the original records.
minor comments (1)
- [Conclusion] The GitHub link is helpful; consider adding a short reproducibility statement or example run script in the paper itself.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights the need for stronger validation of the LLM extraction step. We address each major comment below and will incorporate revisions to provide quantitative grounding for the fidelity claims.
read point-by-point responses
-
Referee: [Abstract and results] Abstract and results description: the central claim that scenarios are 'accurate' and that the LLM 'reliably extract[s] and translate[s]' categorical/contextual information rests on an unverified step. No fidelity metric, edit-distance score, inter-annotator agreement, or source-record vs. generated-parameter comparison is reported, leaving the diversity and failure-revelation results without quantitative grounding.
Authors: We agree that the manuscript lacks explicit quantitative metrics (such as fidelity scores or inter-annotator agreement) for the LLM extraction of categorical and contextual fields from NHTSA records. The claims of accuracy rest on the observed alignment of generated scenarios with the reported road types, vehicle movements, and anomalies, plus their ability to surface failures within the 20-scenario budget. To strengthen this, the revised manuscript will add a validation subsection reporting agreement rates from a manual review of extracted parameters against a sample of source records. revision: yes
-
Referee: [Method and evaluation] Method and evaluation sections: the pipeline description does not include any error analysis or validation protocol for the LLM extraction of road type, vehicle movement, or anomaly fields. Because this extraction is the load-bearing prerequisite for all downstream claims, its absence prevents assessment of whether the generated scenarios actually preserve the original records.
Authors: The referee is correct that no formal error analysis or validation protocol for the extraction of road type, movement, and anomaly fields appears in the Method or Evaluation sections. Our evaluation emphasized downstream simulator outcomes rather than direct extraction fidelity. We will revise the Method section to describe a validation protocol (e.g., sampling records for human verification of extracted fields) and report associated error rates in the revised manuscript. revision: yes
Circularity Check
No significant circularity; applied pipeline with external validation
full rationale
The paper describes an LLM-based engineering pipeline that extracts categorical information from NHTSA natural-language crash records and generates simulator scenarios for Metadrive. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on empirical application results (diversity across 4 road types, 3 movement types, work zones, and observed failures in 20 scenarios) rather than any reduction to inputs by construction. This matches the default case of a self-contained applied method scored 0-2.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kyriakos Axiotis, Vincent Cohen-Addad, Monika Henzinger, Sammy Jerome, Vahab Mirrokni, David Saulpic, David Woodruff, and Michael Wunder. Data-efficient learning via clustering- based sensitivity sampling: Foundation models and beyond.arXiv preprint arXiv:2402.17327,
-
[2]
The european new car assessment programme.https://www.euroncap.com/ en
Euro NCAP. The european new car assessment programme.https://www.euroncap.com/ en. Euro NCAP. Euro ncap 2026 protocols. Online,
2026
-
[3]
Daniel J Fremont, Edward Kim, Tommaso Dreossi, Shromona Ghosh, Xiangyu Yue, Alberto L Sangiovanni-Vincentelli, and Sanjit A Seshia
URLhttps://www.euroncap.com/ en/for-engineers/protocols/2026-protocols/. Daniel J Fremont, Edward Kim, Tommaso Dreossi, Shromona Ghosh, Xiangyu Yue, Alberto L Sangiovanni-Vincentelli, and Sanjit A Seshia. Scenic: a language for scenario specification and data generation.Machine Learning, 112(10):3805–3849,
2026
-
[4]
KING: Generating Safety-Critical Driving Scenarios for Robust Imitation via Kinematics Gradi- ents
11 PARASHARFAN Niklas Hanselmann, Katrin Renz, Kashyap Chitta, Apratim Bhattacharyya, and Andreas Geiger. KING: Generating Safety-Critical Driving Scenarios for Robust Imitation via Kinematics Gradi- ents. InComputer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXVIII, pages 335–352, Berlin, Heide...
2022
-
[5]
Springer-Verlag. ISBN 978-3-031-19838-0. doi: 10.1007/978-3-031-19839-7
-
[6]
Ontology of autonomous driving as a tool for argumentation on responsibility
Piotr Kulicki and Robert Trypuz. Ontology of autonomous driving as a tool for argumentation on responsibility. InLogic and Argumentation: 6th International Conference, CLAR 2025, Taiyuan, China, June 14–16, 2025, Proceedings, page 104–120, Berlin, Heidelberg,
2025
-
[7]
Springer- Verlag. ISBN 978-981-96-7955-3. doi: 10.1007/978-981-96-7956-0
-
[8]
Standing general order on crash reporting for vehicles equipped with automated driving systems and level 2 advanced driver assistance systems
National Highway Traffic Safety Administration. Standing general order on crash reporting for vehicles equipped with automated driving systems and level 2 advanced driver assistance systems. Regulatory guidance, U.S. Department of Transportation, 2021.https://www.nhtsa.gov/ laws-regulations/standing-general-order-crash-reporting. National Highway Traffic ...
2021
-
[9]
Failure prediction from few expert demonstrations
Anjali Parashar, Kunal Garg, Joseph Zhang, and Chuchu Fan. Failure prediction from few expert demonstrations. InNeurIPS 2024 Workshop on Bayesian Decision-making and Uncertainty, 2024a. Anjali Parashar, Ji Yin, Charles Dawson, Panagiotis Tsiotras, and Chuchu Fan. Learning-based bayesian inference for testing of autonomous systems.IEEE Robotics and Automat...
2024
-
[10]
Sentence-bert: Sentence embeddings using siamese bert- networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert- networks. InProceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pages 3982–3992,
2019
-
[11]
Aman Sinha, Payam Nikdel, Supratik Paul, and Shimon Whiteson. Rate-informed discovery via bayesian adaptive multifidelity sampling.arXiv preprint arXiv:2411.17826,
-
[12]
Crash Partner
Higher background traffic increases chances of collisions, but also increases randomization in scenario generation. These values are summarized in Table 5 and can be directly provided as scenario input to theMetadrivesimulator. 14 SCENARIOGENERATION FORADS TESTING USINGFAILURERECORDS Appendix C. Clustering scenario details Cluster-0. Road: Intersection, S...
2025
-
[13]
traveling straight through the intersection in the adjacent through lane continued forward at a steady speed. As Vehicle 1 entered the intersection and crossed the straight- through path, Vehicle 2 reached the conflict point and struck Vehicle 1 in the intersection, resulting in an angle/side-impact collision. Cluster-5. Road: Highway / Freeway, SV: Proce...
2024
-
[14]
same"|"opposite
in the adjacent outside right-turn lane also initiated a right turn at approximately the same time. During the turn, Vehicle 2 tracked wider than its marked lane and encroached into the inside receiving lane, moving laterally into Vehicle 1’s path. Vehicle 1 braked to maintain a safe gap but was unable to fully avoid contact, resulting in a low-speed side...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.