WorldRoamBench: An Open-World Benchmark for Long-Horizon Stability of Interactive World Models
Pith reviewed 2026-07-01 05:58 UTC · model grok-4.3
The pith
WorldRoamBench shows no interactive world model reliably satisfies all four long-horizon stability dimensions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
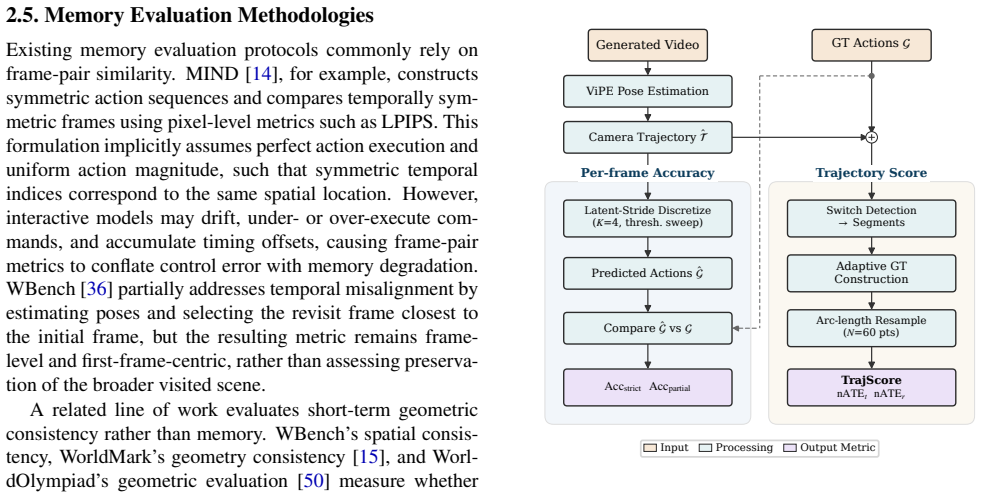
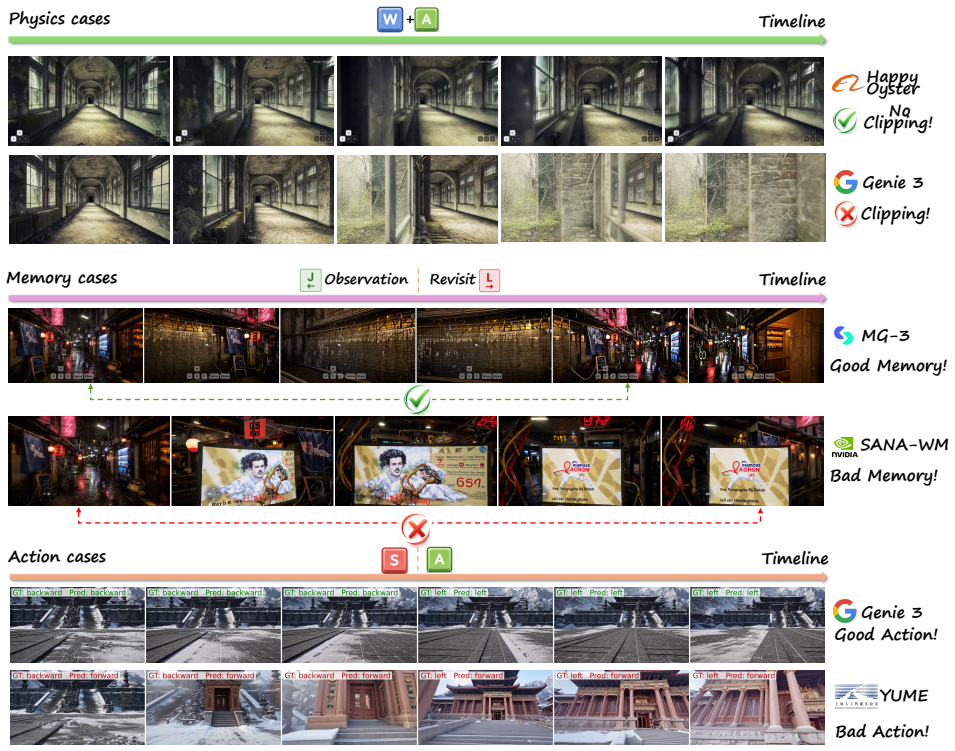
WorldRoamBench is an open-world benchmark comprising more than six hundred test cases in nature, urban, and indoor scenes that evaluates interactive world models on long-horizon stability using a per-frame action metric, a segment-based vision drift metric, controllability-gated physics evaluation, and an action-decoupled memory protocol; results show that none of the ten-plus tested models reliably satisfies all four dimensions and even the best achieves only moderate scores.
What carries the argument
The four tailored metrics (per-frame action, segment-based vision drift, controllability-gated physics, and action-decoupled memory) that replace simple trajectory-level evaluation.
If this is right
- Action evaluation must occur per frame rather than at the full trajectory level to expose hidden failures.
- Vision assessment must check for non-monotonic drift in the middle of sequences rather than only start versus end.
- Physics scoring must be gated on faithful action execution across mechanics, optics, and 3D consistency.
- Memory must be tested separately from actions using localized 3D reconstruction for scenes and tracking plus reasoning for subjects.
- Advances require simultaneous improvement on all four dimensions for models to become stable and deployable.
Where Pith is reading between the lines
- The benchmark's design could be applied to measure progress after targeted training that adds explicit memory or physics losses.
- Real deployment in robotics may still need extra tests for sensor noise or multi-agent interaction not covered here.
- The gap between open and closed models on specific dimensions could point to architectural choices worth investigating further.
- Extending the test length beyond sixty seconds might reveal additional failure modes in current models.
Load-bearing premise
The four tailored metrics accurately capture long-horizon stability without introducing model-specific biases or evaluation artifacts.
What would settle it
A model that scores high on all four metrics but still exhibits clear instability during extended continuous interaction in new scenes would challenge the metrics.
Figures























read the original abstract
Despite rapid progress in interactive world models (IWMs), existing benchmarks evaluate action following only at trajectory level and ignore memory and interaction physics. We introduce WorldRoamBench, an open-world benchmark for long-horizon stability across four dimensions, each with tailored innovations: (i) Action: per-frame action metric bypassing cross-model semantic scale disparity and exposing failures hidden by trajectory; (ii) Vision: segment-based drift metric capturing non-monotonic mid-sequence collapse missed by start-vs-end comparisons; (iii) Physics: controllability-gated evaluation over mechanics, optics, and 3D consistency, scoring plausibility under faithful action execution; (iv) Memory: action-decoupled protocol evaluating scene memory via transition-localized 3D point-cloud reconstruction and subject memory via tracking-plus-VLM reasoning. The benchmark comprises 600+ test cases across Nature, Urban, and Indoor scenes in first/third-person views with WASD 10-60s continuous interaction. Evaluating 10+ open/closed-source models reveals none reliably satisfies all dimensions; even the best achieves only moderate scores. Advances on WorldRoamBench are steps toward IWMs that are stable, physically grounded, memory-faithful, and deployable in real-world applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WorldRoamBench, an open-world benchmark for assessing long-horizon stability of interactive world models across four dimensions (action, vision, physics, memory), each with custom metrics: per-frame action evaluation, segment-based vision drift, controllability-gated physics plausibility, and action-decoupled memory via 3D reconstruction and VLM reasoning. It describes 600+ test cases in varied scenes and reports that evaluation of 10+ models shows none reliably satisfy all dimensions, with even the best achieving only moderate scores.
Significance. If the four metrics are shown to be robust and free of evaluation artifacts, the benchmark would address a clear gap in existing trajectory-level evaluations by emphasizing memory fidelity and interaction physics over long horizons, potentially serving as a useful standard for guiding IWM development toward real-world deployability.
major comments (1)
- The central empirical claim that no model satisfies all four dimensions rests on the reliability of the four tailored metrics, yet the manuscript supplies no validation of these metrics (e.g., no human correlation studies, ablation on metric components, or error analysis), which is load-bearing for interpreting the reported model rankings and the conclusion that advances on the benchmark are steps toward stable IWMs.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of metric validation. We address the concern directly below and commit to revisions that strengthen the empirical support for the benchmark.
read point-by-point responses
-
Referee: [—] The central empirical claim that no model satisfies all four dimensions rests on the reliability of the four tailored metrics, yet the manuscript supplies no validation of these metrics (e.g., no human correlation studies, ablation on metric components, or error analysis), which is load-bearing for interpreting the reported model rankings and the conclusion that advances on the benchmark are steps toward stable IWMs.
Authors: We agree that the absence of explicit validation studies (human correlation, ablations, or error analysis) is a limitation in the current manuscript. Each metric is motivated in the text by concrete shortcomings of prior trajectory-level evaluations (per-frame action to avoid semantic scale issues; segment-based vision to capture non-monotonic drift; controllability-gated physics; action-decoupled memory via 3D reconstruction and VLM). However, these motivations are design-based rather than empirically validated against human judgments or alternative formulations. We will add a new subsection in the revised version containing: (i) human correlation studies on a sampled subset of vision and memory cases, (ii) ablation of key metric components (e.g., segment length, gating threshold), and (iii) error analysis of failure modes. These additions will directly support the reported rankings and the broader claim. revision: yes
Circularity Check
No significant circularity
full rationale
This is an empirical benchmark paper that defines four new evaluation metrics (per-frame action, segment-based vision drift, controllability-gated physics, action-decoupled memory) and applies them to 10+ models across 600+ test cases. No equations, derivations, fitted parameters, or self-citations are present that reduce any reported result or claim to an input by construction. The metric definitions and protocols are stated directly and independently of the model outputs they measure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Genie: Generative interactive environments
Bruce, J., Dennis, M., Edwards, A., et al. Genie: Generative interactive environments. InICML, 2024
2024
-
[2]
Genie 3: A new frontier for world models.https://deepmind.google/discover/ blog/genie- 3- a- new- frontier- for- world- models/, 2025
Google DeepMind. Genie 3: A new frontier for world models.https://deepmind.google/discover/ blog/genie- 3- a- new- frontier- for- world- models/, 2025
2025
-
[3]
Happy Oyster: An open-ended world model for real-time world creation and interaction.https:// happyoyster.cn/, 2026
Alibaba Group. Happy Oyster: An open-ended world model for real-time world creation and interaction.https:// happyoyster.cn/, 2026
2026
-
[4]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team. Wan 2.1: A comprehensive and unified video generation model.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Kling 3.0: Next-generation AI video generation
Kuaishou. Kling 3.0: Next-generation AI video generation. https://klingai.com/, 2025
2025
-
[6]
Sora 2: A large-scale video generation model
OpenAI. Sora 2: A large-scale video generation model. https://openai.com/sora/, 2025
2025
-
[7]
Veo 3: State-of-the-art video generation
Google DeepMind. Veo 3: State-of-the-art video generation. https : / / deepmind . google / technologies / veo/, 2025
2025
-
[8]
ByteDance Seed Team. Seedance 2.0: Advancing video generation for world complexity.arXiv preprint arXiv:2506.05218, 2025
-
[9]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Matrix-Game Team. Matrix-Game 2.0: An open-source, real-time, and streaming interactive world model.arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Matrix-Game 3.0: Real-time and streaming interactive world model with long-horizon mem- ory.arXiv preprint, 2026
Matrix-Game Team. Matrix-Game 3.0: Real-time and streaming interactive world model with long-horizon mem- ory.arXiv preprint, 2026
2026
-
[11]
HY-World 1.5: A systematic framework for interactive world modeling with real-time latency and ge- ometric consistency.arXiv preprint, 2025
HY-World Team. HY-World 1.5: A systematic framework for interactive world modeling with real-time latency and ge- ometric consistency.arXiv preprint, 2025
2025
-
[12]
Yume 1.5: A text-controlled interactive world generation model.arXiv preprint, 2026
Yume Team. Yume 1.5: A text-controlled interactive world generation model.arXiv preprint, 2026
2026
-
[13]
Advancing open-source world models.arXiv preprint, 2026
LingBot Team. Advancing open-source world models.arXiv preprint, 2026. 16
2026
-
[14]
Ye, H., Lu, J., et al. MIND: Benchmarking memory consis- tency and action following in world models.arXiv preprint arXiv:2602.08025, 2026
-
[15]
WorldMark: A Unified Benchmark Suite for Interactive Video World Models
Alaya Studio. WorldMark: A unified benchmark suite for interactive video world models.arXiv preprint arXiv:2604.21686, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
iWorld-Bench: A benchmark for interactive world models with a unified action generation framework
Li, Y ., et al. iWorld-Bench: A benchmark for interactive world models with a unified action generation framework. InICML, 2026
2026
-
[17]
Shanda AI. WildWorld: A large-scale dataset for dynamic world modeling with actions and explicit state toward gener- ative ARPG.arXiv preprint arXiv:2603.23497, 2026
-
[18]
VBench: Comprehensive benchmark suite for video generative mod- els
Huang, Z., He, Y ., Yu, J., Zhang, F., Si, C., et al. VBench: Comprehensive benchmark suite for video generative mod- els. InCVPR, 2024
2024
-
[19]
Huang, Z., Zhang, F., Xu, X., He, Y ., Yu, J., et al. VBench++: Comprehensive and versatile benchmark suite for video gen- erative models.arXiv preprint arXiv:2411.13503, 2024
-
[20]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y ., et al. VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
WorldScore: A unified evaluation benchmark for world generation
Stanford. WorldScore: A unified evaluation benchmark for world generation. InICCV, 2025
2025
-
[22]
WorldModelBench: Judging video generation models as world models
UC Berkeley. WorldModelBench: Judging video generation models as world models. InNeurIPS, 2025
2025
-
[23]
Towards world simulator: Crafting physical commonsense-based benchmark for video generation
SJTU, et al. Towards world simulator: Crafting physical commonsense-based benchmark for video generation. In ICML, 2025
2025
-
[24]
UCLA. WorldBench: Disambiguating physics for di- agnostic evaluation of world models.arXiv preprint arXiv:2601.21282, 2026
-
[25]
Video PreTraining (VPT): Learning to act by watching unlabeled online videos
Baker, B., et al. Video PreTraining (VPT): Learning to act by watching unlabeled online videos. InNeurIPS, 2022
2022
-
[26]
Microsoft. MineWorld: A real-time and open-source interactive world model on Minecraft.arXiv preprint arXiv:2504.08388, 2025
-
[27]
SANA-WM: Efficient minute-scale world model- ing with hybrid linear diffusion transformer.arXiv preprint, 2026
NVIDIA. SANA-WM: Efficient minute-scale world model- ing with hybrid linear diffusion transformer.arXiv preprint, 2026
2026
-
[28]
Lyra 2.0: Explorable generative 3D worlds.arXiv preprint, 2026
NVIDIA. Lyra 2.0: Explorable generative 3D worlds.arXiv preprint, 2026
2026
-
[29]
minWM: A full-stack open-source frame- work for real-time interactive video world models.arXiv preprint, 2026
minWM Team. minWM: A full-stack open-source frame- work for real-time interactive video world models.arXiv preprint, 2026
2026
-
[30]
LAION- 5B: An open large-scale dataset for training next generation image-text models
Schuhmann, C., Beaumont, R., Vencu, R., et al. LAION- 5B: An open large-scale dataset for training next generation image-text models. InNeurIPS, 2022
2022
-
[31]
MUSIQ: Multi-scale image quality transformer
Ke, J., Wang, Q., Wang, Y ., Milanfar, P., and Yang, F. MUSIQ: Multi-scale image quality transformer. InICCV, 2021
2021
-
[32]
Helios: A comprehensive benchmark for video generative models.arXiv preprint, 2025
Helios Team. Helios: A comprehensive benchmark for video generative models.arXiv preprint, 2025
2025
-
[33]
WorldCompass: Reinforcement learning for long-horizon world models.arXiv preprint, 2026
WorldCompass Team. WorldCompass: Reinforcement learning for long-horizon world models.arXiv preprint, 2026
2026
-
[34]
ViPE: Visual pose estimation for camera trajectory recovery
-
[35]
and Deng, J
Teed, Z. and Deng, J. DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras. InNeurIPS, 2021
2021
-
[36]
WBench: A comprehensive benchmark for evaluating world models via action-conditioned video gener- ation.arXiv preprint, 2026
Ying, Z., et al. WBench: A comprehensive benchmark for evaluating world models via action-conditioned video gener- ation.arXiv preprint, 2026
2026
-
[37]
and Medioni, G
Chen, Y . and Medioni, G. Object modelling by registra- tion of multiple range images.Image and Vision Computing, 10(3):145–155, 1992
1992
-
[38]
B., Blodow, N., and Beetz, M
Rusu, R. B., Blodow, N., and Beetz, M. Fast Point Feature Histograms (FPFH) for 3D registration. InICRA, 2009
2009
-
[39]
Point Transformer V3: Simpler, faster, stronger
Wu, X., Jiang, L., Wang, P.-S., et al. Point Transformer V3: Simpler, faster, stronger. InCVPR, 2024
2024
-
[40]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V ., Hu, Y .-T., et al. SAM 2: Seg- ment anything in images and videos.arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Two-frame motion estimation based on poly- nomial expansion
Farneb ¨ack, G. Two-frame motion estimation based on poly- nomial expansion. InScandinavian Conference on Image Analysis (SCIA), 2003
2003
-
[42]
What limits virtual agent appli- cation? OmniBench: A scalable multi-dimensional bench- mark for essential virtual agent capabilities
Bu, W., Wu, Y ., Yu, Q., et al. What limits virtual agent appli- cation? OmniBench: A scalable multi-dimensional bench- mark for essential virtual agent capabilities. InICML, 2025
2025
-
[43]
Wu, M., Cai, Z., Zhao, F., et al. Omni-WorldBench: Towards a comprehensive interaction-centric evaluation for world models.arXiv preprint arXiv:2603.22212, 2026
-
[44]
Do vision-language models have internal world models? Towards an atomic evaluation
Gao, Q., Pi, X., Liu, K., et al. Do vision-language models have internal world models? Towards an atomic evaluation. InACL, 2025
2025
-
[45]
How far is video generation from world model: A physical law perspective
Kang, B., Yue, Y ., Lu, R., et al. How far is video generation from world model: A physical law perspective. InICML, 2025
2025
-
[46]
WorldLens: Full-Spectrum Evaluations of Driving World Models in Real World
Liang, A., Kong, L., Yan, T., et al. WorldLens: Full-spectrum evaluations of driving world models in real world.arXiv preprint arXiv:2512.10958, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Shang, Y ., Li, Z., Ma, Y ., et al. WorldArena: A unified benchmark for evaluating perception and functional utility of embodied world models.arXiv preprint arXiv:2602.08971, 2026
-
[48]
Arai, H., Ishihara, K., Takahashi, T., and Yamaguchi, Y . ACT-Bench: Towards action controllable world models for autonomous driving.arXiv preprint arXiv:2412.05337, 2024
-
[49]
EWMBench: Evaluat- ing scene, motion, and semantic quality in embodied world models
Hu, Y ., Huang, S., Liao, Y ., et al. EWMBench: Evaluat- ing scene, motion, and semantic quality in embodied world models. InBMVC, 2025
2025
-
[50]
WorldOlympiad: Can Your World Model Survive a Triathlon?
Zhao, Y ., Zhao, W., Wang, W., Zhang, Z., An, D., Liu, A., Yu, Y ., Tang, J., Wang, F., Wang, W., and Zhuang, B. Worl- dOlympiad: Can Your World Model Survive a Triathlon? arXiv preprint arXiv:2606.11129, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Person moves forward; Camera turns left
Teed, Z. and Deng, J. RAFT: Recurrent All-Pairs Field Transforms for Optical Flow.arXiv preprint arXiv:2003.12039, 2020. 17 A. Test Suite Gallery To provide a qualitative overview of the visual and ac- tion coverage in WorldRoamBench, we include a gallery of representative test cases in Figure 11. Each panel shows the first-frame image together with an ac...
-
[52]
camera-pose chain
Depth-percentile Filteringretain nearest p%Far Near Cross-Segment Registration Coarse:PTY3 / FPFH+ RANSACFine:point-to-planeICPQuality-awareacceptance:fitness ≥ τᵩand Chamferimprovest … Video + GTActions⋯WW(Explore) SS(Revisit)⋯ Observation Segment(t ≤ t*) Frame-LevelPointClouds t Revisit Segment(t > t*) t Frame-LevelPointClouds t*Memory Evaluation Pipeli...
-
[53]
Holistic scoring accommodates smooth viewpoint and illumination changes that can confound frame-level com- parisons, while producing a single benchmark-compatible scalar without requiring an external reference-feature li- brary. G. Subject Memory Prompt For third-person memory evaluation, the Subject Memory Evaluation Prompt in Figure 27 scores video-leve...
-
[54]
Is there a shadow visible on the wall or floor?
-
[55]
If yes, does the shadow move or change in a way that is physically consistent with the camera movement and the light source position? Answer ’yes’ if the shadow appears and behaves correctly, ’no’ if the shadow is missing or behaves incorrectly. After your reasoning, conclude with exactly one line: Answer: yes or Answer: no Figure 26.Occlusion and shadow ...
-
[56]
Identity change: the subject becomes a different individual or category
-
[57]
Structural distortion: the body, anatomy, proportions, limbs, head, face, or key parts become deformed or implausible
-
[58]
Appearance drift: color, texture, clothing, hair, material, or style is truly rewritten
-
[59]
Subject disappearance: the subject becomes partly or fully invisible
-
[60]
subject memory score
Quality degradation: severe blur, low resolution, diffused edges, or loss of key details makes the subject hard to identify. Important calibration rules: - Viewpoint change alone is not inconsistency. Back-to-front, front-to-back, side-to-front, or far-to-close changes are acceptable if the subject can reasonably be the same individual under the new view....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.