3D Point World Models: Point Completion Enables More Accurate Dynamics Learning
Pith reviewed 2026-07-02 18:47 UTC · model grok-4.3
The pith
Completing partial point clouds first enables reliable long-horizon 3D dynamics predictions for robotic planning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
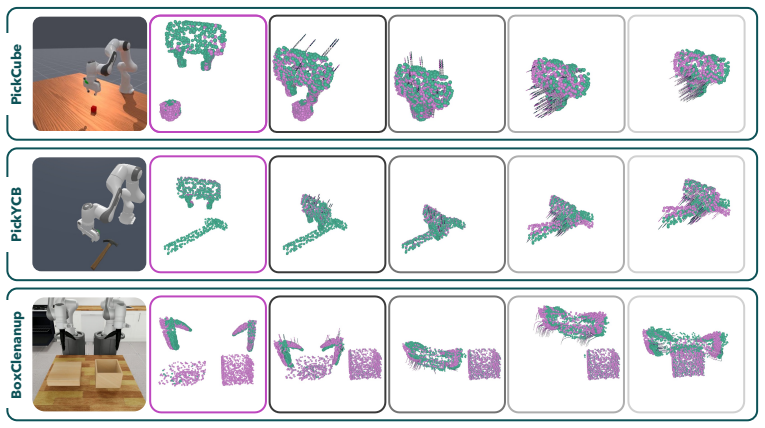
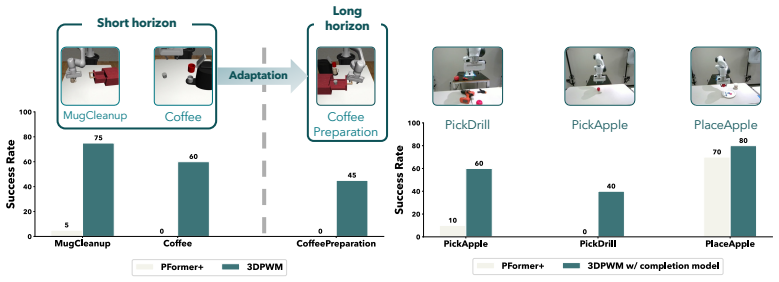
3DPWM first completes partial point clouds and then learns action-conditioned dynamics entirely in the resulting completed 3D scene. This yields reliable long-horizon rollouts of 100-300+ steps, supports both open-loop and closed-loop model-based planning, and enables adaptation to new tasks along with successful sim-to-real transfer across robotic embodiments and tabletop benchmarks.
What carries the argument
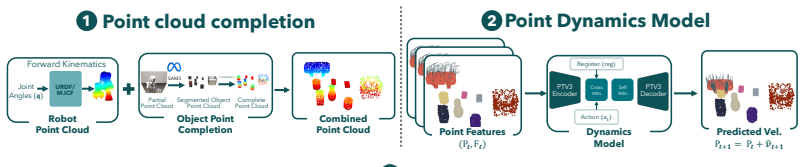
3D Point World Models (3DPWM) that complete partial point clouds before learning action-conditioned dynamics on the completed 3D geometry.
If this is right
- Reliable long-horizon rollouts of 100-300+ steps become possible.
- More accurate cost evaluation supports improved model-based planning.
- Both open-loop and closed-loop planning succeed on manipulation tasks.
- Adaptation to new tasks occurs without task-specific retraining.
- Sim-to-real transfer works across different robotic embodiments.
Where Pith is reading between the lines
- Advances in standalone point-completion methods would directly raise the ceiling on dynamics accuracy.
- The separation of completion and dynamics stages could let each component be upgraded independently.
- Consistent completed geometry may reduce the frequency of replanning needed in closed-loop control.
- The same completion-plus-dynamics pattern could apply to non-tabletop settings if point clouds remain the input modality.
Load-bearing premise
The point completion step produces a sufficiently accurate and consistent 3D representation whose errors do not propagate into or degrade the subsequent dynamics predictions.
What would settle it
An experiment showing that completed point clouds still produce geometrically inconsistent rollouts or that planning success rates remain unchanged would falsify the claim that completion enables more accurate dynamics learning.
Figures


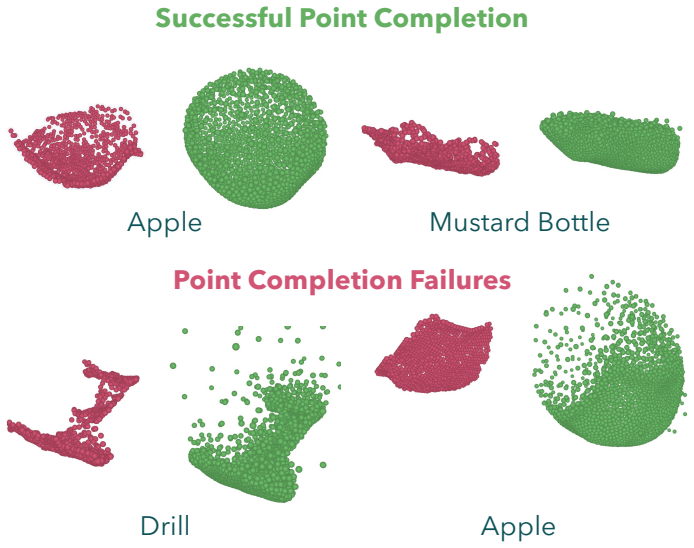


read the original abstract
Learning predictive models of the world enables robotic control through planning, potentially allowing robots to improvise solutions on new tasks. However, large video-based dynamics models lack explicit 3D spatial structure and suffer from geometrically inconsistent long-term rollouts with compounding errors. Emerging 3D dynamics models based on partial point clouds improve geometric consistency but remain sensitive to occlusions and accumulated prediction drift. To address these challenges, we present 3D Point World Models (3DPWM) - a task-agnostic world model that operates entirely in 3D space by first completing partial point clouds and then learning action-conditioned dynamics in this completed 3D scene. By operating on completed geometry, 3DPWM enables reliable long-horizon rollouts and more accurate cost evaluation for model-based planning while supporting adaptation to new tasks. Experiments across different robotic embodiments and tabletop manipulation benchmarks demonstrate that 3DPWM achieves significantly more reliable long-horizon rollouts (100-300+ steps), supports both open-loop and closed-loop planning, and enables successful sim-to-real transfer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
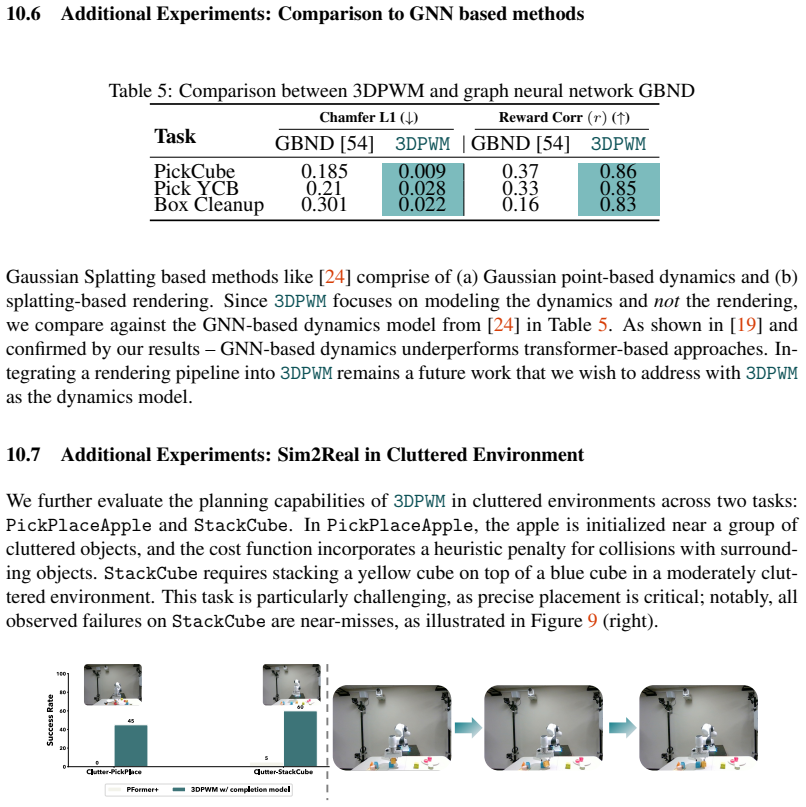
Summary. The paper introduces 3D Point World Models (3DPWM), a task-agnostic world model operating in 3D space that first completes partial point clouds and then learns action-conditioned dynamics on the completed geometry. It claims this yields reliable long-horizon rollouts (100-300+ steps), more accurate cost evaluation for model-based planning, support for open- and closed-loop planning, adaptation to new tasks, and successful sim-to-real transfer across robotic embodiments and tabletop benchmarks.
Significance. If the experimental claims hold, the result would be significant for 3D dynamics modeling in robotics, as completing geometry before dynamics learning could mitigate occlusion sensitivity and compounding drift that plague both video-based and partial-point-cloud models, enabling more robust long-term prediction and planning.
major comments (2)
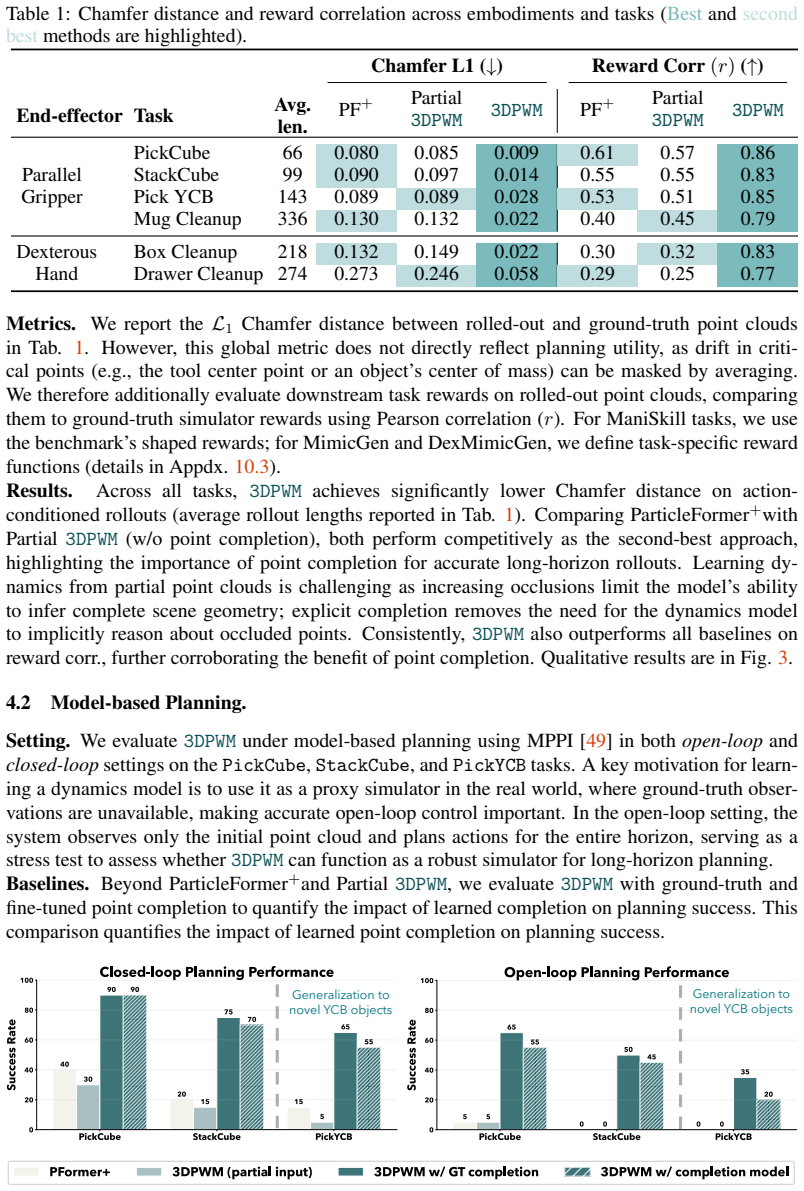
- [Abstract] Abstract: the abstract asserts large gains in long-horizon reliability ('significantly more reliable long-horizon rollouts (100-300+ steps)') but supplies no quantitative metrics, baselines, ablation results, or error analysis, so the data-to-claim link cannot be evaluated.
- [Abstract] The central claim that operating on completed geometry prevents error propagation into dynamics predictions rests on the unexamined assumption that residual completion errors remain small and non-compounding over 100-300 steps; no analysis of completion accuracy versus rollout error is referenced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the two major comments on the abstract below, agreeing that greater specificity would improve clarity while noting that supporting quantitative results appear in the experimental sections.
read point-by-point responses
-
Referee: [Abstract] Abstract: the abstract asserts large gains in long-horizon reliability ('significantly more reliable long-horizon rollouts (100-300+ steps)') but supplies no quantitative metrics, baselines, ablation results, or error analysis, so the data-to-claim link cannot be evaluated.
Authors: We agree the abstract is a high-level summary and does not embed specific numbers or references to tables/figures. The full paper reports quantitative long-horizon metrics (e.g., Chamfer distance and success rates over 100-300 steps) against multiple baselines in Sections 5-6. We will revise the abstract to include one or two key quantitative highlights and a reference to the relevant experimental results. revision: yes
-
Referee: [Abstract] The central claim that operating on completed geometry prevents error propagation into dynamics predictions rests on the unexamined assumption that residual completion errors remain small and non-compounding over 100-300 steps; no analysis of completion accuracy versus rollout error is referenced.
Authors: The paper demonstrates through direct comparisons that 3DPWM produces lower long-horizon error than partial-point-cloud baselines, which supports the benefit of completion. However, we acknowledge the absence of an explicit correlation analysis between per-step completion error and subsequent rollout drift. We will add such an analysis (e.g., a scatter plot or ablation) in the revision to directly address this point. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents 3DPWM as an empirical architecture that first completes partial point clouds then learns action-conditioned dynamics on the completed geometry. No derivation chain is shown that reduces a claimed prediction or first-principles result to a fitted parameter or self-citation by construction. The abstract states the benefit of completed geometry for long-horizon rollouts without equations that equate the output to the input by definition. No self-citation load-bearing step, uniqueness theorem, or ansatz smuggling is visible in the provided material. The central claim therefore remains independent of the patterns that would trigger a circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
D. Ha and J. Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Dream to Control: Learning Behaviors by Latent Imagination
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[3]
Hafner, T
D. Hafner, T. Lillicrap, M. Norouzi, and J. Ba. Mastering atari with discrete world models. Internation Conference on Learning Representations, 2021
2021
-
[4]
Mastering Diverse Domains through World Models
D. Hafner, J. Pasukonis, J. Ba, and T. Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
P. Wu, A. Escontrela, D. Hafner, P. Abbeel, and K. Goldberg. Daydreamer: World models for physical robot learning. InConference on robot learning, pages 2226–2240. PMLR, 2023
2023
-
[6]
Hansen, H
N. Hansen, H. Su, and X. Wang. Td-mpc2: Scalable, robust world models for continuous control.International Conference on Learning Representations (ICLR), 2024
2024
-
[7]
K. Chua, R. Calandra, R. McAllister, and S. Levine. Deep reinforcement learning in a hand- ful of trials using probabilistic dynamics models. InProceedings of the 32nd International Conference on Neural Information Processing Systems, 2018
2018
-
[8]
Nagabandi, K
A. Nagabandi, K. Konolige, S. Levine, and V . Kumar. Deep dynamics models for learning dexterous manipulation. InConference on robot learning, pages 1101–1112. PMLR, 2020
2020
-
[9]
Hafner, T
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson. Learning latent dynamics for planning from pixels. InInternational conference on machine learning, 2019
2019
-
[10]
Cosmos World Foundation Model Platform for Physical AI
N. Agarwal, A. Ali, M. Bala, Y . Balaji, E. Barker, T. Cai, P. Chattopadhyay, Y . Chen, Y . Cui, Y . Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 9
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
J. Wu, S. Yin, N. Feng, X. He, D. Li, J. Hao, and M. Long. ivideogpt: Interactive videogpts are scalable world models. InAdvances in Neural Information Processing Systems, 2024
2024
-
[12]
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet. Video diffusion models.Advances in neural information processing systems, 35:8633–8646, 2022
2022
-
[13]
Video Generators are Robot Policies
J. Liang, P. Tokmakov, R. Liu, S. Sudhakar, P. Shah, R. Ambrus, and C. V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Y . Du, S. Yang, B. Dai, H. Dai, O. Nachum, J. Tenenbaum, D. Schuurmans, and P. Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
2023
-
[15]
S. Zhou, Y . Du, J. Chen, Y . Li, D.-Y . Yeung, and C. Gan. Robodreamer: Learning composi- tional world models for robot imagination.arXiv preprint arXiv:2404.12377, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
- [17]
-
[18]
X. Ren, T. Shen, J. Huang, H. Ling, Y . Lu, M. Nimier-David, T. M¨uller, A. Keller, S. Fidler, and J. Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 6121–6132, 2025
2025
-
[19]
Huang, Q
S. Huang, Q. Chen, X. Zhang, J. Sun, and M. Schwager. Particleformer: A 3d point cloud world model for multi-object, multi-material robotic manipulation.Conference on Robot Learning, 2025
2025
-
[20]
S. Peri, I. Lee, C. Kim, L. Fuxin, T. Hermans, and S. Lee. Point cloud models improve visual robustness in robotic learners.International Conference on Robotics and Automation, 2024
2024
-
[21]
B. Ai, S. Tian, H. Shi, Y . Wang, T. Pfaff, C. Tan, H. I. Christensen, H. Su, J. Wu, and Y . Li. A review of learning-based dynamics models for robotic manipulation.Science Robotics, 2025
2025
-
[22]
K. R. Allen, T. L. Guevara, Y . Rubanova, K. Stachenfeld, A. Sanchez-Gonzalez, P. Battaglia, and T. Pfaff. Graph network simulators can learn discontinuous, rigid contact dynamics. In Conference on Robot Learning, pages 1157–1167. PMLR, 2023
2023
-
[23]
Kim and L
C. Kim and L. Fuxin. Object dynamics modeling with hierarchical point cloud-based rep- resentations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20977–20986, 2024
2024
-
[24]
Zhang, K
M. Zhang, K. Zhang, and Y . Li. Dynamic 3d gaussian tracking for graph-based neural dynamics modeling. In8th Annual Conference on Robot Learning, 2024. URLhttps: //openreview.net/forum?id=itKJ5uu1gW
2024
-
[25]
Y . Li, J. Wu, R. Tedrake, J. B. Tenenbaum, and A. Torralba. Learning particle dynamics for manipulating rigid bodies, deformable objects, and fluids. InICLR, 2019
2019
-
[26]
Chen, F.-J
X. Chen, F.-J. Chu, P. Gleize, K. J. Liang, A. Sax, H. Tang, W. Wang, M. Guo, T. Hardin, X. Li, et al. Sam 3d: 3dfy anything in images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7220–7232, 2026
2026
-
[27]
H. Zhou, Y . Cao, W. Chu, J. Zhu, T. Lu, Y . Tai, and C. Wang. Seedformer: Patch seeds based point cloud completion with upsample transformer. InEuropean Conference on Computer Vision, 2022. URLhttps://api.semanticscholar.org/CorpusID:250920848. 10
2022
-
[28]
Khademi and F
W. Khademi and F. Li. Point-based instance completion with scene constraints. InThe Thir- teenth International Conference on Learning Representations, 2025
2025
-
[29]
M. Fortunato, T. Pfaff, P. Wirnsberger, A. Pritzel, and P. Battaglia. Multiscale meshgraphnets. arXiv preprint arXiv:2210.00612, 2022
- [30]
- [31]
-
[32]
A. Longhini, M. B ¨usching, B. P. Duisterhof, J. Lundell, J. Ichnowski, M. Bj ¨orkman, and D. Kragic. Cloth-splatting: 3d cloth state estimation from rgb supervision.arXiv preprint arXiv:2501.01715, 2025
- [33]
-
[34]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polo- sukhin. Attention is all you need.Advances in neural information processing systems, 2017
2017
- [35]
-
[36]
W. Huang, Y .-W. Chao, A. Mousavian, M.-Y . Liu, D. Fox, K. Mo, and L. Fei-Fei. Point- world: Scaling 3d world models for in-the-wild robotic manipulation.arXiv preprint arXiv:2601.03782, 2026
-
[37]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, and et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945, 2024. URLhttps://arxiv.org/abs/2403.12945
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
W. Yuan, T. Khot, D. Held, C. Mertz, and M. Hebert. Pcn: Point completion network. In3D Vision (3DV), 2018 International Conference on, 2018
2018
-
[39]
Huang, Y
Z. Huang, Y . Yu, J. Xu, F. Ni, and X. Le. Pf-net: Point fractal network for 3d point cloud completion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020
2020
-
[40]
Khademi and L
W. Khademi and L. Fuxin. Diverse shape completion via style modulated generative adversar- ial networks. InThirty-seventh Conference on Neural Information Processing Systems, 2023. URLhttps://openreview.net/forum?id=yVMlYSL1Bp
2023
-
[41]
Y . Nie, J. Hou, X. Han, and M. Niessner. Rfd-net: Point scene understanding by semantic instance reconstruction. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 4608–4618, June 2021
2021
- [42]
-
[43]
H. Li, J. Dong, B. Wen, M. Gao, T. Huang, Y .-H. Liu, and D. Cremers. Ddit: Semantic scene completion via deformable deep implicit templates. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 21894–21904, October 2023
2023
-
[44]
SAM 3: Segment Anything with Concepts
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, J. Lei, T. Ma, B. Guo, A. Kalla, M. Marks, J. Greer, M. Wang, P. Sun, R. R¨adle, T. Afouras, E. Mavroudi, K. Xu, T.-H. Wu, Y . Zhou, L. Momeni, R. Hazra, S. Ding, S. Vaze, F. Porcher, F. Li, S. Li, A. Kamath, H. K. Cheng, P. Doll ´ar, N. Ravi, K. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Zhang, L
B. Zhang, L. Ke, A. W. Harley, and K. Fragkiadaki. Tapip3d: Tracking any point in persistent 3d geometry.NeurIPS, 2025
2025
-
[46]
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, and H. Zhao. Point transformer v3: Simpler faster stronger. InProceedings of the IEEE/CVF conference on com- puter vision and pattern recognition, pages 4840–4851, 2024
2024
-
[47]
Vision Transformers Need Registers
T. Darcet, M. Oquab, J. Mairal, and P. Bojanowski. Vision transformers need registers.arXiv preprint arXiv:2309.16588, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
P. J. Huber. Robust estimation of a location parameter. InBreakthroughs in statistics: Method- ology and distribution, pages 492–518. Springer, 1992
1992
-
[49]
Williams, A
G. Williams, A. Aldrich, and E. A. Theodorou. Model predictive path integral control: From theory to parallel computation.Journal of Guidance, Control, and Dynamics, 2017
2017
-
[50]
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T. kai Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, V . N. Rajesh, Y . W. Choi, Y .-R. Chen, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su. Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai.Robotics: Science and Systems, 2025
2025
-
[51]
MimicGen: A Data Generation System for Scalable Robot Learning using Human Demonstrations
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. arXiv preprint arXiv:2310.17596, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[52]
Jiang, Y
Z. Jiang, Y . Xie, K. Lin, Z. Xu, W. Wan, A. Mandlekar, L. J. Fan, and Y . Zhu. Dexmimic- gen: Automated data generation for bimanual dexterous manipulation via imitation learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 16923– 16930. IEEE, 2025
2025
-
[53]
J. Gu, F. Xiang, X. Li, Z. Ling, X. Liu, T. Mu, Y . Tang, S. Tao, X. Wei, Y . Yao, X. Yuan, P. Xie, Z. Huang, R. Chen, and H. Su. Maniskill2: A unified benchmark for generalizable manipulation skills. InInternational Conference on Learning Representations, 2023
2023
-
[54]
C ¸ alli, A
B. C ¸ alli, A. Singh, A. Walsman, S. S. Srinivasa, P. Abbeel, and A. M. Dollar. The ycb object and model set: Towards common benchmarks for manipulation research.2015 International Conference on Advanced Robotics (ICAR), 2015
2015
-
[55]
Islam, O
F. Islam, O. Salzman, A. Agarwal, and M. Likhachev. Provably constant-time planning and replanning for real-time grasping objects off a conveyor belt.The International journal of robotics research, 40(12-14):1370–1384, 2021
2021
-
[56]
X. Wu, D. DeTone, D. Frost, T. Shen, C. Xie, N. Yang, J. Engel, R. Newcombe, H. Zhao, and J. Straub. Sonata: Self-supervised learning of reliable point representations. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22193–22204, 2025
2025
-
[57]
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R´e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[58]
T. Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In International Conference on Learning Representations (ICLR), 2024
2024
-
[59]
Deitke, C
M. Deitke, C. Clark, S. Lee, R. Tripathi, Y . Yang, J. S. Park, M. Salehi, N. Muennighoff, K. Lo, L. Soldaini, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision- language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 91–104, 2025
2025
-
[60]
Y . Zhu, A. Joshi, P. Stone, and Y . Zhu. Viola: Imitation learning for vision-based manipulation with object proposal priors.6th Annual Conference on Robot Learning (CoRL), 2022. 12
2022
-
[61]
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang. Moge- 2: Accurate monocular geometry with metric scale and sharp details.Advances in Neural Information Processing Systems, 38:35928–35959, 2026
2026
-
[62]
Depth Anything 3: Recovering the Visual Space from Any Views
H. Lin, S. Chen, J. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025. 13 10 Appendix 10.1 Data Generation Point completion.We consider 100 random viewpoints for each object from the YCB dataset from which we obtain the partial point clouds inputs. A s...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
This is a known issue (see Issues#79and#162 on the SAM3D github repository.) Using Depth Foundation models to avoid noisy completions.We also tested using MOGE-2
but found that the completions, while generalizable to various commonly found objectsdo not alignwith the partial input despite providing sensor depth from the camera ( instead of using DepthAnything or other foundation depth models). This is a known issue (see Issues#79and#162 on the SAM3D github repository.) Using Depth Foundation models to avoid noisy ...
-
[64]
and DepthAnything3 [62] since they have shown impressive performance for depth estimation. However, we observed that while the depth was very clean and so were the resulting backprojected point clouds – these models still suffered with two major challenges which made decision making difficult: (a) similar to SAM3D, these depth foundation models suffered w...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.